【用户画像】用户画像简介、用户画像的架构、搭建用户画像管理平台
文章目录
- 一 用户画像简介
-
- 1 用户画像
- 2 定位
- 2 应用
- 3 用户标签
-
- (1)标签分级
- (2)标签分类
- 二 用户画像的架构
-
- 1 画像处理流程
- 2 画像标签数据应用
- 3 用户画像管理平台
- 三 搭建用户画像管理平台
-
- 1 一些问题
- 2 启动服务
-
- (1)数据库建表脚本
- (2)配置修改
一 用户画像简介
1 用户画像
数据仓库是大数据体系的基石,用户画像是建立在数仓之上的一种应用,类似的应用还有商业智能,推荐系统等。
用户画像,英文: User Profile,( 也有少数称: User Portrait 或User Persona)。
一句话概念就是将用户信息标签化(Tag或者Label),以用户为中心,将各种各样的标签对应到其身上,一般表现为《人 – 标签 – 标签值》。
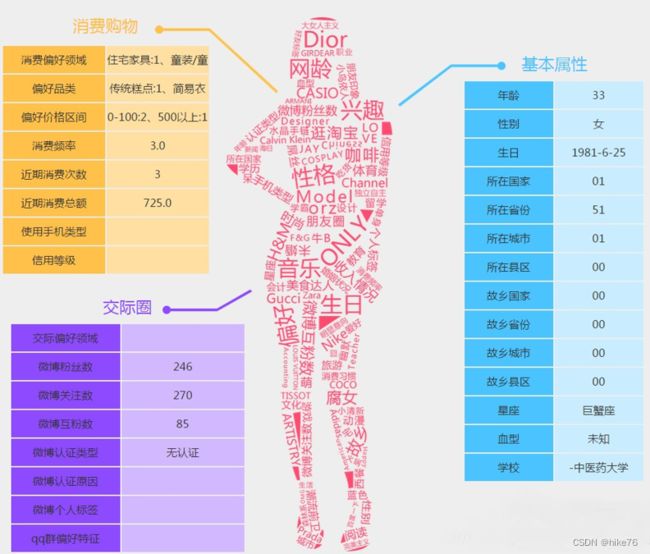
通过收集用户的社会属性、消费习惯、偏好特征等各个维度的数据,进而对用户或者产品特征属性进行刻画,并对这些特征进行分析、统计,挖掘潜在价值信息,从而抽象出用户的信息全貌。
2 定位

相对于数据仓库而言,用户画像属于“上层建筑”,以数据仓库沉淀的数据为基础,提炼出更有价值的信息。
同时用户画像也是一种数据服务,在它之上还有“更高的建筑”,比如推荐系统,营销系统、风控系统、用于广告投放的DMP系统等等。这些系统往往需要对用户进行识别定位,那么用户画像就是最重要的数据来源。
画像中心的数据全部来源于数仓,但是其又不能直接使用数仓,所以需要按照画像的标准,以用户为单位,将数据再次进行提炼、加工组合,形成以用户标签为中心的数据。
2 应用
画像数据的主要应用类型:
- 运营决策:了解用户群体,聚焦目标用户,定位产品方向。
- 精准营销:营销活动推送、广告投放、个性化推荐。
- 用户分群:寻找高价值用户,挽留待流失用户,提升用户活跃。
3 用户标签
(1)标签分级
不同公司分级不同,最常见的为以下四级标签,又可以分为三种:
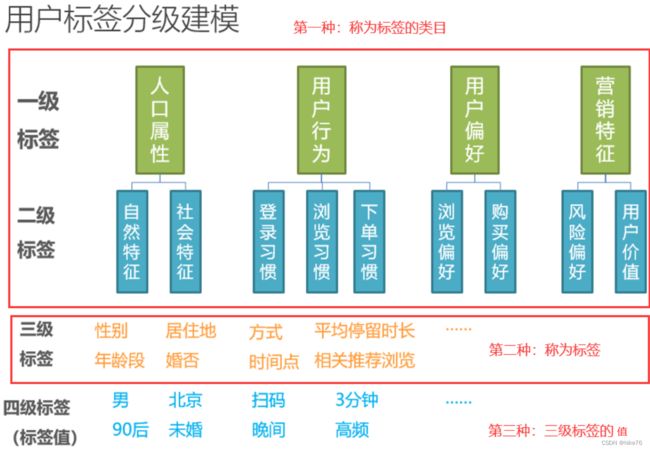
有的公司分为5级标签或者6级标签,不同在类目,5/6级标签的类目更加详细。
少数公司不分级,第一种称为标签的分类,第二种称为标签,第三种称为值
(2)标签分类
各个公司的标签分类都大差不差,分为以下三类:
-
统计类标签
统计类标签的规则放之四海皆准,每个公司的定义都差不多,如性别指的就是人的性别,不会有歧义,偏客观。
直接提取的标签,又叫事实标签。
比如:性别,年龄,最近一次登录时间,月均消费。
有非常通用且明确的定义,是最为常见的标签。
-
规则类标签
规则类标签与统计类标签不同在于概念上的差别,技术上差不多,往往各个公司的业务人员根据公司的需求灵活定义,偏主观。
从程序员角度来说,统计类标签与规则类标签没有本质差别。
需要自定义规则。
比如:高价值用户、意见领袖、电子产品爱好者、黄牛党。
需要运营、产品、业务人员,根据企业自身的业务特征,设计适合自身的规则定义。往往同一个名称的标签,在不同企业的规则不同。
-
挖掘类标签
挖掘类标签是企业做用户画像的分水岭,通常来说,这个标签不是由人来制定规则,因为有些规则没有办法通过人类语言描述清楚,或者人类语言描述的不准确,尤其是预测相关的规则,规则随着时间的变化也在不停的变化。
一般通过机器学习算法进行预测的标签。又叫预测类标签。
比如:预测性别、预测年龄、潜在流失用户。
通常是很难根据某一个规则得到的标签。需要机器学习通过系统现有的数据,反复迭代获得一个模型算法,再根据算法得到标签。
开发周期长,难度大,准确度不能保证。但是往往也是最有价值的标签,因为从数据得到的数据,有时往往比定死的规则更反映真实情况。
二 用户画像的架构
用户画像架构如图:

1 画像处理流程
画像处理流程主要是根据标签及整个流程的规则计算标签,把数据仓库中的数据进行重组。
一般统计类和规则类标签使用spark-sql即可,复杂的规则类标签和挖掘类标签可以使用spark-core和spark-mllib完成。
是一个标准的ETL(清洗、转移、提取)流程,将数仓中的数据提取为以用户和标签为结构的数据,流程类似于数仓中的由ODS – DWD – DWS – DWT – ADS 逐层计算的过程,与数仓不同的是,画像处理中不全是SQL,并且不只是用一个数据库。
一般这个流程使用shell + 定时调度(Azkaban)就可以完成。
数仓计算的最终结果如果数据量小一般存放在MySQL中,数据量大一般存放在Kylin,Presto,HBase等容器中。
2 画像标签数据应用
用户画像最终的计算结果一般存放在ClickHouse中,目的主要有两个。
- 用户标签明细及分析:以用户的维度对数据进行统计分析。
- 用户分群:是画像最核心的需求,使用各种标签,通过标签的筛选,快速定位到目标群体,通过在数据库中编写配置文件可以完成。
画像提供了分群操作所以要操作支持即席查询的OLAP,对标签及人群进行操作。
根据实际需要一般选择性能较好,支持即席查询的OLAP数据库。用于组合和多个条件来筛选用户,比如Clickhouse或者Elasticsearch。同时也会使用K-V数据库用于精确查询用户和人群,比如Redis、Hbase 、Pika。
以上1 2 两个过程除用户标签明细及分析,其余过程均可以实现无界面化。
3 用户画像管理平台
在画像管理平台提供可视化页面,对标签及标签产生的规则进行定义,甚至直接提供可视化开发页面。
提供后台调度系统,根据标签定义的规则,从数仓中抽取计算。
计算后的用户画像标签也由平台管理,通过标签的组合,把用户分成不同的群体。为其他业务系统提供支持。
技术实现:
用户画像系统本质上是一个内部的管理系统,方便用户画像开发团队,搭建标签管理任务的。基于标准的Web应用的技术。
- Vue.js:负责前端页面。
- Springboot :负责后台应用,数据保存在Mysql数据库中,相关的技术框架还包括MybatisPlus、StringTask。因为还需要把spark程序任务提交到Yarn,所以还用到SparkLauncher插件。
各个模块任务:
-
标签规则定义:计算哪些标签,标签任务的定义。
-
标签任务调度:标签何时执行,如计算性别,机器学习的预测。
-
任务监控:调度配置好后,到达运行条件,可以对任务进行观察,哪些标签计算成功哪些计算失败。
-
分群管理:标签全部运行成功之后,可以对标签进行筛选,分组管理,需要提供一个界面,这个界面可以供数据分析、营销等人员进行使用。对人群的定义,称为人群包。分群又称人圈(人群圈选)。
画像处理流程都是批处理(夜里计算),人圈则一般是即时产生的(白天计算),即筛选完几个条件,当场把目标群体圈出来,要求及时性更强。
-
标签数据支撑:标签数据计算完成之后,供其他部门查询这些标签,做一些数据支持或者是接口。
三 搭建用户画像管理平台
gitee仓库地址
1 一些问题
-
导入代码之后,初始化完成之后,project一栏只出现pom.xml 和 external libraries原因是idea没有将项目识别为一个Maven工程或SpringBoot工程,解决办法点击file – new – Module from Existing Sources… 重新选择该项目,一路next。
-
如果src – main – java 不是蓝色目录,说明idea没有找到对应的源码目录,需要手动设置,在java上右键 – Mark Directory as – Source Root。
-
搭建平台时,代码中可能会有getter、setter方法飘红,不影响运行,修复飘红方法,Settings – Plugins – 搜索栏搜索lombok – 安装 – 重启idea。lombok能在编译时给实体Bean自动生成getter、setter方法。
-
忘记MySQL密码
# 1.修改配置文件 my.ini,在配置文件 [mysqld] 下添加 skip-grant-tables,重启MySQL服务即可免密码登录 # 其中 --skip-grant-tables 选项的意思是启动 MySQL 服务的时候跳过权限表认证。 启动后,连接到 MySQL 的 root 将不需要口令(危险)。 # 用空密码的 root 用户连接到 MySQL,并且更改 root 口令 # 免密码登录MySQL数据库: mysql -u root # 重置密码: use mysql; update user set password=password('你的密码') where user='root'; # 3.到 my.ini 中删除 skip-grant-tables 选项,然后重启MySQL服务。
2 启动服务
(1)数据库建表脚本
创建数据库 – utf8 – utf8_general_ci
建表语句
/*
SQLyog
MySQL - 5.7.16 : Database - user_profile_manager
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
/*Table structure for table `file_info` */
CREATE TABLE `file_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`file_name` varchar(200) DEFAULT NULL COMMENT '文件名',
`file_ex_name` varchar(20) DEFAULT NULL COMMENT '扩展名',
`file_path` varchar(200) DEFAULT NULL COMMENT '文件路径',
`file_system` varchar(20) DEFAULT NULL COMMENT '文件系统',
`file_status` bigint(20) DEFAULT NULL COMMENT '文件状态 1 正常 2 弃用',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
/*Table structure for table `tag_common_task` */
CREATE TABLE `tag_common_task` (
`id` bigint(20) NOT NULL,
`task_file_id` bigint(20) DEFAULT NULL,
`main_class` varchar(200) DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
/*Table structure for table `tag_info` */
CREATE TABLE `tag_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`tag_code` varchar(200) DEFAULT NULL,
`tag_name` varchar(200) DEFAULT NULL,
`tag_level` bigint(20) DEFAULT NULL,
`parent_tag_id` bigint(20) DEFAULT NULL,
`tag_type` varchar(20) DEFAULT NULL,
`tag_value_type` varchar(20) DEFAULT NULL COMMENT '1 整数 2 浮点 3 文本 4 日期',
`tag_value_limit` decimal(16,2) DEFAULT NULL COMMENT '数值预估上限 数字型填写',
`tag_value_step` bigint(20) DEFAULT NULL COMMENT '1,10,100,1000',
`tag_task_id` bigint(20) DEFAULT NULL,
`tag_comment` varchar(2000) DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_tag_level_id` (`tag_level`,`id`)
) ENGINE=InnoDB ;
/*Table structure for table `task_info` */
CREATE TABLE `task_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`task_name` varchar(200) DEFAULT NULL COMMENT '任务名称',
`task_status` varchar(20) DEFAULT NULL COMMENT '任务状态',
`task_comment` varchar(2000) DEFAULT NULL COMMENT '任务说明',
`task_time` varchar(10) DEFAULT NULL COMMENT '任务作业时间(小时分)',
`task_type` varchar(20) DEFAULT NULL COMMENT '任务类型(标签,流程)',
`exec_type` varchar(20) DEFAULT NULL COMMENT '执行方式(jar,sparksql)',
`main_class` varchar(200) DEFAULT NULL COMMENT '启动执行的主类',
`file_id` bigint(200) DEFAULT NULL COMMENT '程序jar文件id',
`task_args` varchar(500) DEFAULT NULL COMMENT '启动任务的参数',
`task_sql` varchar(5000) DEFAULT NULL COMMENT '启动的执行的sql',
`task_exec_level` bigint(20) DEFAULT NULL COMMENT '执行层级',
`create_time` date DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `idx_task_time` (`task_time`)
) ENGINE=InnoDB ;
/*Table structure for table `task_process` */
CREATE TABLE `task_process` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`task_id` bigint(20) DEFAULT NULL COMMENT '任务id',
`task_name` varchar(100) DEFAULT NULL COMMENT '任务名称',
`task_exec_time` varchar(10) DEFAULT NULL COMMENT '任务触发时间',
`task_busi_date` varchar(10) DEFAULT NULL COMMENT '任务执行日期',
`task_exec_status` varchar(100) DEFAULT NULL COMMENT '任务阶段 TODO ,START,SUBMITTED,RUNNING,FAILED,FINISHED',
`task_exec_level` bigint(20) DEFAULT NULL COMMENT '任务执行层级',
`yarn_app_id` varchar(100) DEFAULT NULL COMMENT 'yarn的application_id',
`batch_id` varchar(100) DEFAULT NULL COMMENT '批次id',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`start_time` datetime DEFAULT NULL COMMENT '启动时间',
`end_time` datetime DEFAULT NULL COMMENT '结束时间(包括完成和失败)',
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
/*Table structure for table `task_tag_rule` */
CREATE TABLE `task_tag_rule` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`tag_id` bigint(20) DEFAULT NULL COMMENT '标签主键',
`task_id` bigint(20) DEFAULT NULL COMMENT '任务id',
`query_value` varchar(200) DEFAULT NULL COMMENT '查询值',
`sub_tag_id` bigint(20) DEFAULT NULL COMMENT '对应子标签id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
/*Table structure for table `user_group` */
CREATE TABLE `user_group` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`user_group_name` varchar(200) DEFAULT NULL COMMENT '分群名称',
`condition_json_str` varchar(2000) DEFAULT NULL COMMENT '分群条件(json)',
`condition_comment` varchar(2000) DEFAULT NULL COMMENT '分群条件(描述)',
`user_group_num` bigint(20) DEFAULT NULL COMMENT '分群人数',
`update_type` varchar(20) DEFAULT NULL COMMENT '更新类型(手动,自动按天)',
`user_group_comment` varchar(2000) DEFAULT NULL COMMENT '分群说明',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
(2)配置修改
在idea中修改application.properties配置文件中的mysql相关配置(地址、用户名、密码)
在UserProfileManagerApplication中启动
将hadoop101地址与 userprofile.gmall.com进行映射(C:\Windows\System32\drivers\etc目录下的host文件中进行修改)
现在就可以在浏览器中进行访问了(输入userprofile.gmall.com 或者 hadoop101地址 )