和鲸社区 Pandas进阶修炼120题——第一期 Pandas基础、第二期 Pandas数据处理
目录
第一期 Pandas基础
1.将下面的字典创建为DataFrame
2.提取含有字符串"Python"的行
3.输出df的所有列名
4.修改第二列列名为'popularity'
5.统计grammer列中每种编程语言出现的次数
6.将空值用上下值的平均值填充
7.提取popularity列中值大于3的行
8.按照grammer列进行去除重复值
9.计算popularity列平均值
10.将grammer列转换为list
11.将DataFrame保存为EXCEL
12.查看数据行列数
13.提取popularity列值大于3小于7的行¶
14.交换两列位置
15.提取popularity列最大值所在行
16.查看最后5行数据
17.删除最后一行数据
18.添加一行数据['Perl',6.6]
19.对数据按照"popularity"列值的大小进行排序
20.统计grammer列每个字符串的长度
第二期 Pandas数据处理
21.读取本地EXCEL数据
22.查看dff数据前5行
23.将salary列数据转换为最大值与最小值的平均值 (不理解)
24.将数据根据学历进行分组并计算平均薪资
25.将createTime列时间转换为月-日
26.查看索引、数据类型和内存信息
27.查看数值型列的汇总统计
28.新增一列根据salary将数据分为三组
29.按照salary列对数据降序排列
30.取出第33行数据
31.计算salary列的中位数
32.绘制薪资水平频率分布直方图
33.绘制薪资水平密度曲线
34.删除最后一列categories
35.将dff的第一列与第二列合并为新的一列
36.将education列与salary列合并为新的一列
37.计算salary最大值与最小值之差
38.将第一行与最后一行拼接
39.将第8行数据添加至末尾
40.查看每列的数据类型
41.将createTime列设置为索引
42.生成一个和dff长度相同的随机数dataframe
43.将上一题生成的dataframe与dff合并
44.生成新的一列new为salary列减去之前生成随机数列
45.检查数据中是否含有任何缺失值
46.将salary列类型转换为浮点数
47.计算salary大于10000的次数
48查看每种学历出现的次数
49.查看education列共有几种学历
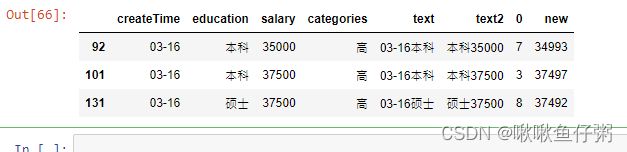
50.提取salary与new列的和大于60000的最后3行
链接:工作台 - Heywhale.com
第一期 Pandas基础
导入必要的库
import pandas as pd
import numpy as np1.将下面的字典创建为DataFrame
data={'grammer':["Python","C","Java","GO",np.nan,"SQL","PHP","Python"],'score':[1,2,np.nan,4,5,6,7,10]}df=pd.DataFrame(data)
df
2.提取含有字符串"Python"的行
df[df['grammer']=='Python']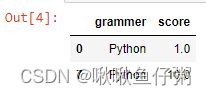
3.输出df的所有列名
df.columns![]()
4.修改第二列列名为'popularity'
df.rename(columns={'score':'popularity'},inplace=True)
df
5.统计grammer列中每种编程语言出现的次数
df['grammer'].value_counts()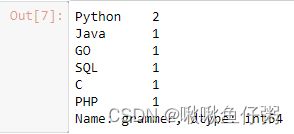
6.将空值用上下值的平均值填充
interpolate函数方法的使用:Pandas函数interpolate的使用_Ricool_go的博客-CSDN博客_interpolate函数用法
df['popularity']=df['popularity'].fillna(df['popularity'].interpolate())
df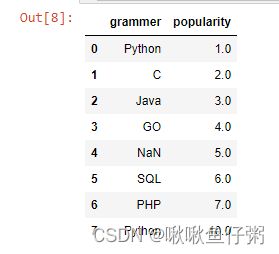
7.提取popularity列中值大于3的行
-方法1
df[df['popularity']>3]
-方法2 loc实现条件查询
df.loc[df['popularity']>3]
8.按照grammer列进行去除重复值

df.drop_duplicates('grammer',keep='first')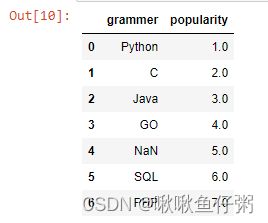
9.计算popularity列平均值
df['popularity'].mean()![]()
10.将grammer列转换为list
df['grammer'].to_list()![]()
11.将DataFrame保存为EXCEL
df.to_excel('df.xlsx')12.查看数据行列数
df.shape![]()
13.提取popularity列值大于3小于7的行¶
-方法1
df[(df['popularity']>3)&(df['popularity']<7)]
-方法2 loc方式
df.loc[(df['popularity']>3)&(df['popularity']<7),:]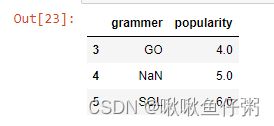
14.交换两列位置
# 使用df[]交换,最方便直接
df[['grammer','popularity']]=df[['popularity','grammer']]
df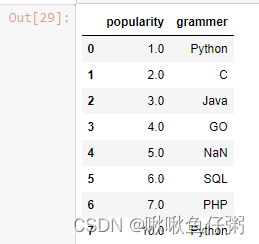
15.提取popularity列最大值所在行
df[df['popularity']==df['popularity'].max()]
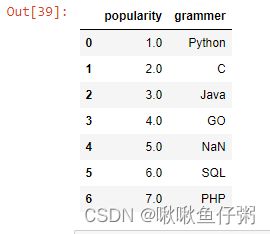
16.查看最后5行数据
df.tail(5)17.删除最后一行数据
df.drop([len(df)-1],inplace=True)
df
18.添加一行数据['Perl',6.6]
row={'grammer':'Perl','popularity':6.6}
df=df.append(row,ignore_index=True)
dfignore_index用法:默认False为忽略原index
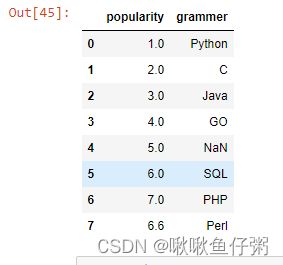
19.对数据按照"popularity"列值的大小进行排序
df.sort_values('popularity',inplace=True)
df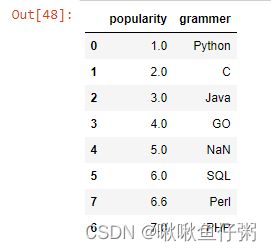
20.统计grammer列每个字符串的长度
df['grammer']=df['grammer'].fillna('R')
df['len_str']=df['grammer'].map(lambda x:len(x))
df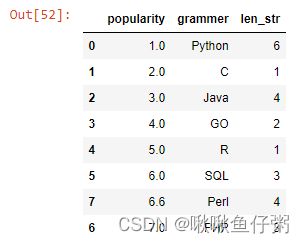
第二期 Pandas数据处理
导入必要的库
import pandas as pd
import numpy as np21.读取本地EXCEL数据
dff=pd.read_excel('pandas120.xlsx')
dff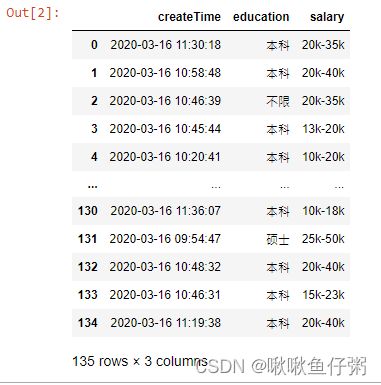
22.查看dff数据前5行
dff.head(5)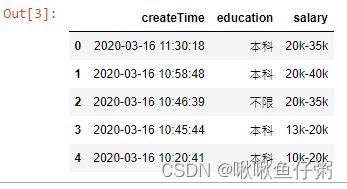
23.将salary列数据转换为最大值与最小值的平均值 (不理解)
# 方法一:apply + 自定义函数
import re
def func(df):
lst = df['salary'].split('-')
smin = int(lst[0].strip('k'))
smax = int(lst[1].strip('k'))
df['salary'] = int((smin + smax) / 2 * 1000)
return df
dff = dff.apply(func,axis=1)
dff
24.将数据根据学历进行分组并计算平均薪资
dff.groupby('education').mean()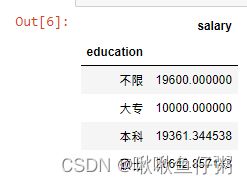
25.将createTime列时间转换为月-日
for i in range(len(dff)):
dff.iloc[i,0] = dff.iloc[i,0].to_pydatetime().strftime('%m-%d')
dff.head()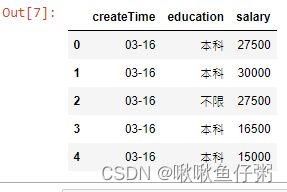
26.查看索引、数据类型和内存信息
dff.info()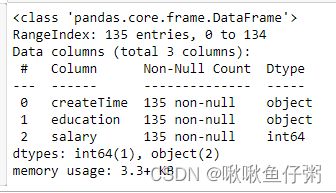
27.查看数值型列的汇总统计
dff.describe()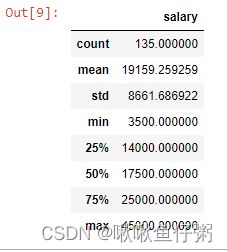
28.新增一列根据salary将数据分为三组

bins=[0,5000,20000,50000]
group_name=['低','中','高']
dff['categories']=pd.cut(dff['salary'],bins,labels=group_name)
dff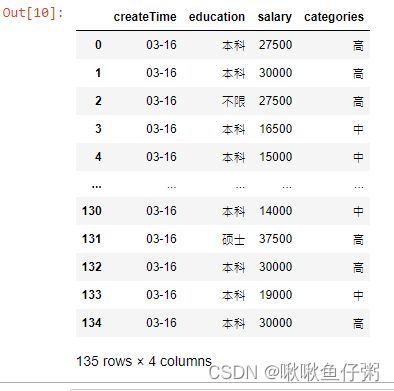
29.按照salary列对数据降序排列
dff.sort_values('salary',ascending=False)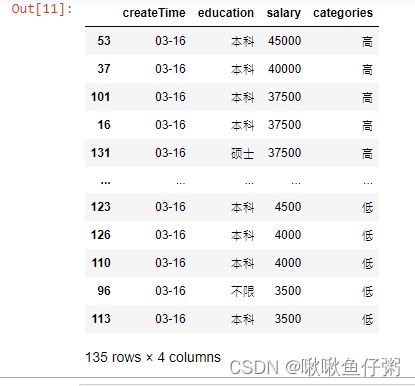
30.取出第33行数据
dff.iloc[32,:]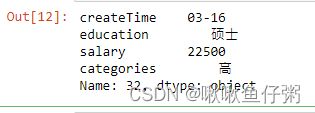


31.计算salary列的中位数
dff['salary'].median()32.绘制薪资水平频率分布直方图
dff.salary.plot(kind='hist')
33.绘制薪资水平密度曲线
dff.salary.plot(kind='kde',xlim=(0,80000))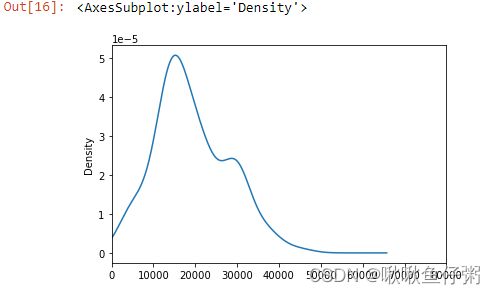
34.删除最后一列categories
dff.drop('categories',axis=1)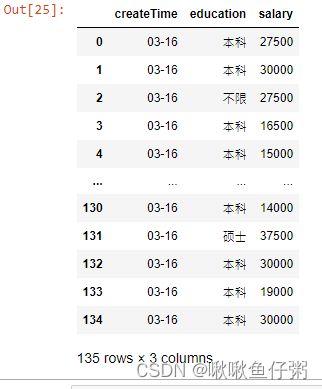
35.将dff的第一列与第二列合并为新的一列
dff['text']=dff['createTime']+dff['education']
dff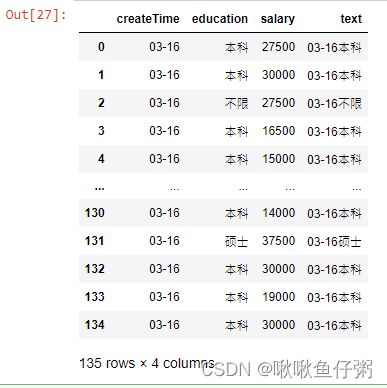
36.将education列与salary列合并为新的一列
dff['text2']=dff['education']+dff['salary'].map(str)
dff
知识点:这里的salary是int型,要将之转化为字符串型。如果某一列是非str类型的数据,那么我们需要用到map(str)将那一列数据类型做转换。
python实现多列合并为一列的方法总结:https://blog.csdn.net/weixin_42782150/article/details/103668814?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%90%88%E5%B9%B6%E5%88%97python&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-103668814.142^v56^control,201^v3^control_1&spm=1018.2226.3001.4187
37.计算salary最大值与最小值之差
#方法一
dff['salary'].max()-dff['salary'].min()
#方法二
dff[['salary']].apply(lambda x:x.max()-x.min())![]()
38.将第一行与最后一行拼接
pd.concat([dff[0:1],dff[-2:-1]])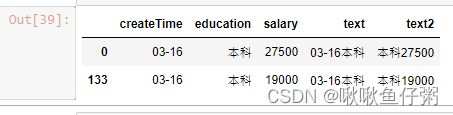
39.将第8行数据添加至末尾
dff.append(dff.iloc[7])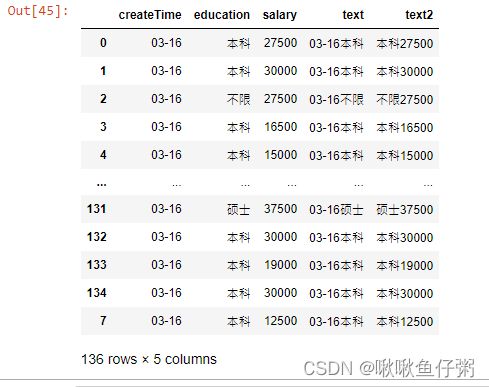
40.查看每列的数据类型
dff.info()
or
dff.dtypes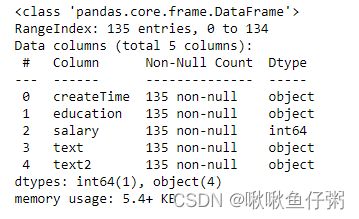
41.将createTime列设置为索引
dff.set_index('createTime')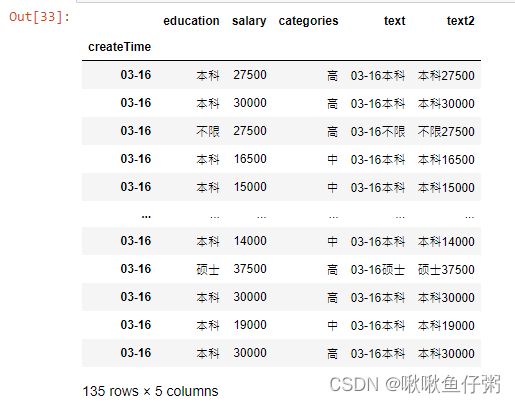
42.生成一个和dff长度相同的随机数dataframe
知识点:np.random.randint(1,10,135) 指随机1至10之间的整数,取135个
dff1=pd.DataFrame(pd.Series(np.random.randint(1,10,135)))
dff1
43.将上一题生成的dataframe与dff合并
知识点:concat

#将dff1中的列添加到dff的尾部
dff=pd.concat([dff,dff1],axis=1)
dff
44.生成新的一列new为salary列减去之前生成随机数列
dff['new']=dff['salary']-dff[0]
dff45.检查数据中是否含有任何缺失值
--方法1
dff.isnull()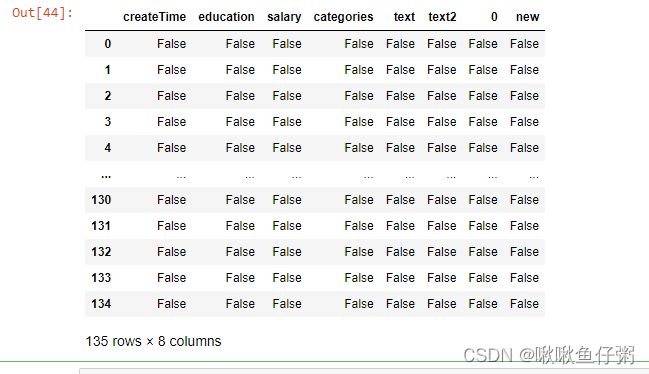
--方法2
#df.isnull().any()则会判断哪些”列”存在缺失值
dff.isnull().any()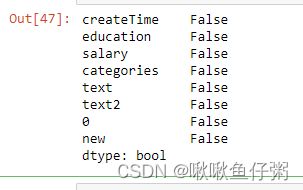
46.将salary列类型转换为浮点数
--方法1
dff['salary'].map(float)
--方法2
dff['salary'].astype(np.float64)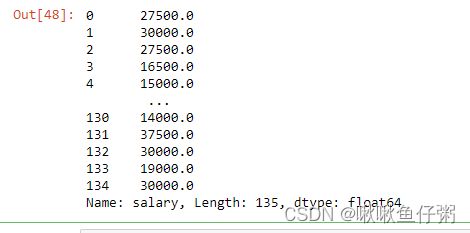
47.计算salary大于10000的次数
len(dff[dff['salary']>10000])![]()
48查看每种学历出现的次数
dff['education'].value_counts()
49.查看education列共有几种学历
dff['education'].nunique()![]()
50.提取salary与new列的和大于60000的最后3行
dff[dff['salary']+dff['new']> 60000].tail(3)