CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
深度学习大热以后各种模型层出不穷,很多朋友都在问到底什么是CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络),这么多个网络到底有什么不同,作用各是什么?
在详细的介绍各种网络前,首先说明:
大部分神经网络都可以用深度(depth)和连接结构(connection)来定义,下面会具体情况具体分析。
笼统的说,神经网络也可以分为有监督的神经网络和无/半监督学习,但其实往往是你中有我我中有你,不必死抠字眼。
有鉴于篇幅,只能粗略的科普一下这些非常相似的网络以及应用场景,具体的细节无法展开详谈,有机会在专栏中深入解析。
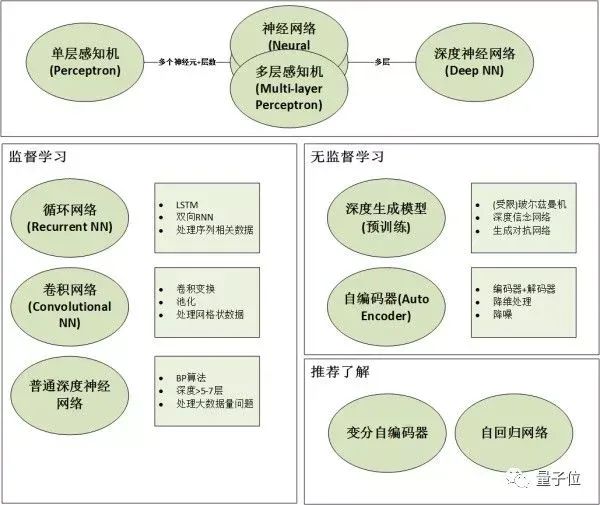
文章中介绍的网络包括:
整理了最新保姆级入门到进阶人工智能Z料包免费获取关注威x公众号:咕泡AI 回复123 |
还有CV+NLP+pytorch+深度学习资料+论文/学习/就业/竞赛指导+大牛技术解答 |
①人工智能课程及项目【含课件源码】 |
②人工智能必看优质书籍电子书汇总 |
③国内外知名精华资源 |
④优质人工智能大纲 |
⑤人工智能行业报告 |
⑥人工智能论文合集 |
1. 有监督的神经网络(Supervised Neural Networks)
1.1. 神经网络(Artificial Neural Networks)和深度神经网络(Deep Neural Networks)
追根溯源的话,神经网络的基础模型是感知机(Perceptron),因此神经网络也可以叫做多层感知机(Multi-layer Perceptron),简称MLP。单层感知机叫做感知机,多层感知机(MLP)≈人工神经网络(ANN)。
那么多层到底是几层?一般来说有1-2个隐藏层的神经网络就可以叫做多层,准确的说是(浅层)神经网络(Shallow Neural Networks)。随着隐藏层的增多,更深的神经网络(一般来说超过5层)就都叫做深度学习(DNN)。
然而,“深度”只是一个商业概念,很多时候工业界把3层隐藏层也叫做“深度学习”,所以不要在层数上太较真。在机器学习领域的约定俗成是,名字中有深度(Deep)的网络仅代表其有超过5-7层的隐藏层。
神经网络的结构指的是“神经元”之间如何连接,它可以是任意深度。以下图的3种不同结构为例,我们可以看到连接结构是非常灵活多样的。
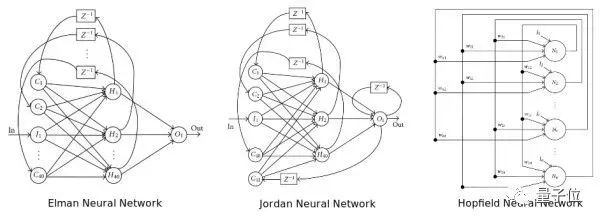
需要特别指出的是,卷积网络(CNN)和循环网络(RNN)一般不加Deep在名字中的原因是:它们的结构一般都较深,因此不需要特别指明深度。想对比的,自编码器(Auto Encoder)可以是很浅的网络,也可以很深。所以你会看到人们用Deep Auto Encoder来特别指明其深度。
应用场景:全连接的前馈深度神经网络(Fully Connected Feed Forward Neural Networks),也就是DNN适用于大部分分类(Classification)任务,比如数字识别等。但一般的现实场景中我们很少有那么大的数据量来支持DNN,所以纯粹的全连接网络应用性并不是很强。
1. 2. 循环神经网络(Recurrent Neural Networks)和递归神经网络(Recursive Neural Networks)
虽然很多时候我们把这两种网络都叫做RNN,但事实上这两种网路的结构事实上是不同的。而我们常常把两个网络放在一起的原因是:它们都可以处理有序列的问题,比如时间序列等。
举个最简单的例子,我们预测股票走势用RNN就比普通的DNN效果要好,原因是股票走势和时间相关,今天的价格和昨天、上周、上个月都有关系。而RNN有“记忆”能力,可以“模拟”数据间的依赖关系(Dependency)。
为了加强这种“记忆能力”,人们开发各种各样的变形体,如非常著名的Long Short-term Memory(LSTM),用于解决“长期及远距离的依赖关系”。如下图所示,左边的小图是最简单版本的循环网络,而右边是人们为了增强记忆能力而开发的LSTM。
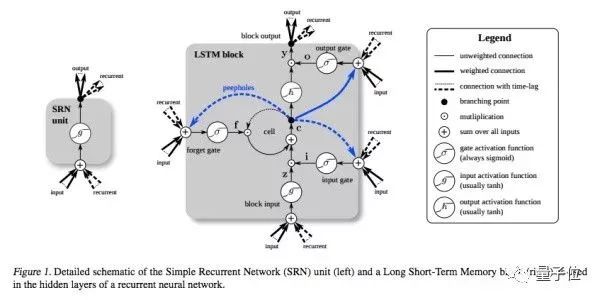
同理,另一个循环网络的变种 - 双向循环网络(Bi-directional RNN)也是现阶段自然语言处理和语音分析中的重要模型。开发双向循环网络的原因是语言/语音的构成取决于上下文,即“现在”依托于“过去”和“未来”。单向的循环网络仅着重于从“过去”推出“现在”,而无法对“未来”的依赖性有效的建模。
递归神经网络和循环神经网络不同,它的计算图结构是树状结构而不是网状结构。递归循环网络的目标和循环网络相似,也是希望解决数据之间的长期依赖问题。而且其比较好的特点是用树状可以降低序列的长度,从O(n)降低到O(log(n)),熟悉数据结构的朋友都不陌生。但和其他树状数据结构一样,如何构造最佳的树状结构如平衡树/平衡二叉树并不容易。
应用场景:语音分析,文字分析,时间序列分析。主要的重点就是数据之间存在前后依赖关系,有序列关系。一般首选LSTM,如果预测对象同时取决于过去和未来,可以选择双向结构,如双向LSTM。
1.3. 卷积网络(Convolutional Neural Networks)
卷积网络早已大名鼎鼎,从某种意义上也是为深度学习打下良好口碑的功臣。不仅如此,卷积网络也是一个很好的计算机科学借鉴神经科学的例子。卷积网络的精髓其实就是在多个空间位置上共享参数,据说我们的视觉系统也有相类似的模式。
首先简单说什么是卷积。卷积运算是一种数学计算,和矩阵相乘不同,卷积运算可以实现稀疏相乘和参数共享,可以压缩输入端的维度。和普通DNN不同,CNN并不需要为每一个神经元所对应的每一个输入数据提供单独的权重。
与池化(pooling)相结合,CNN可以被理解为一种公共特征的提取过程,不仅是CNN大部分神经网络都可以近似的认为大部分神经元都被用于特征提取。
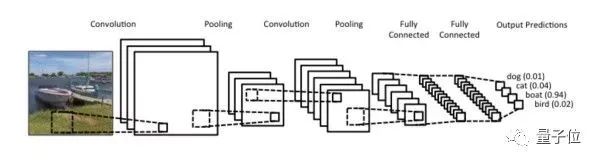
以上图为例,卷积、池化的过程将一张图片的维度进行了压缩。从图示上我们不难看出卷积网络的精髓就是适合处理结构化数据,而该数据在跨区域上依然有关联。
应用场景:虽然我们一般都把CNN和图片联系在一起,但事实上CNN可以处理大部分格状结构化数据(Grid-like Data)。举个例子,图片的像素是二维的格状数据,时间序列在等时间上抽取相当于一维的的格状数据,而视频数据可以理解为对应视频帧宽度、高度、时间的三维数据。
2. 无监督的预训练网络(Unsupervised Pre-trained Neural Networks)
2.1. 深度生成模型(Deep Generative Models)
说到生成模型,大家一般想到的无监督学习中的很多建模方法,比如拟合一个高斯混合模型或者使用贝叶斯模型。深度学习中的生成模型主要还是集中于想使用无监督学习来帮助监督学习,毕竟监督学习所需的标签代价往往很高…所以请大家不要较真我把这些方法放在了无监督学习中。
2.1.1. 玻尔兹曼机(Boltzmann Machines)和受限玻尔兹曼机(Restricted Boltzmann Machines)
每次一提到玻尔兹曼机和受限玻尔兹曼机我其实都很头疼。简单的说,玻尔兹曼机是一个很漂亮的基于能量的模型,一般用最大似然法进行学习,而且还符合Hebb’s Rule这个生物规律。但更多的是适合理论推演,有相当多的实际操作难度。
而受限玻尔兹曼机更加实际,它限定了其结构必须是二分图(Biparitite Graph)且隐藏层和可观测层之间不可以相连接。此处提及RBM的原因是因为它是深度信念网络的构成要素之一。
应用场景:实际工作中一般不推荐单独使用RBM…
2.1.2. 深度信念网络(Deep Belief Neural Networks)
DBN是祖师爷Hinton在06年提出的,主要有两个部分: 1. 堆叠的受限玻尔兹曼机(Stacked RBM) 2. 一层普通的前馈网络。
DBN最主要的特色可以理解为两阶段学习,阶段1用堆叠的RBM通过无监督学习进行预训练(Pre-train),阶段2用普通的前馈网络进行微调。
就像我上文提到的,神经网络的精髓就是进行特征提取。和后文将提到的自动编码器相似,我们期待堆叠的RBF有数据重建能力,及输入一些数据经过RBF我们还可以重建这些数据,这代表我们学到了这些数据的重要特征。
整理了最新保姆级入门到进阶人工智能Z料包免费获取关注威x公众号:咕泡AI 回复123 |
还有CV+NLP+pytorch+深度学习资料+论文/学习/就业/竞赛指导+大牛技术解答 |
①人工智能课程及项目【含课件源码】 |
②人工智能必看优质书籍电子书汇总 |
③国内外知名精华资源 |
④优质人工智能大纲 |
⑤人工智能行业报告 |
⑥人工智能论文合集 |
将RBF堆叠的原因就是将底层RBF学到的特征逐渐传递的上层的RBF上,逐渐抽取复杂的特征。比如下图从左到右就可以是低层RBF学到的特征到高层RBF学到的复杂特征。在得到这些良好的特征后就可以用第二部分的传统神经网络进行学习。

多说一句,特征抽取并重建的过程不仅可以用堆叠的RBM,也可以用后文介绍的自编码器。
应用场景:现在来说DBN更多是了解深度学习“哲学”和“思维模式”的一个手段,在实际应用中还是推荐CNN/RNN等,类似的深度玻尔兹曼机也有类似的特性但工业界使用较少。
2.1.3. 生成式对抗网络(Generative Adversarial Networks)
生成式对抗网络用无监督学习同时训练两个模型,内核哲学取自于博弈论…
简单的说,GAN训练两个网络:1. 生成网络用于生成图片使其与训练数据相似 2. 判别式网络用于判断生成网络中得到的图片是否是真的是训练数据还是伪装的数据。生成网络一般有逆卷积层(deconvolutional layer)而判别网络一般就是上文介绍的CNN。自古红蓝出CP,下图左边是生成网络,右边是判别网络,相爱相杀。
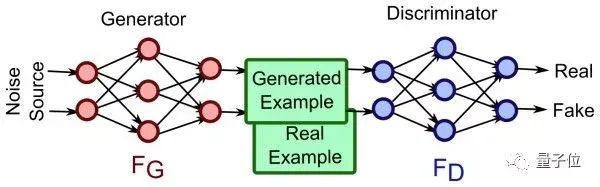
熟悉博弈论的朋友都知道零和游戏(zero-sum game)会很难得到优化方程,或很难优化,GAN也不可避免这个问题。但有趣的是,GAN的实际表现比我们预期的要好,而且所需的参数也远远按照正常方法训练神经网络,可以更加有效率的学到数据的分布。
另一个常常被放在GAN一起讨论的模型叫做变分自编码器(Variational Auto-encoder),有兴趣的读者可以自己搜索。
应用场景:现阶段的GAN还主要是在图像领域比较流行,但很多人都认为它有很大的潜力大规模推广到声音、视频领域。
2.2. 自编码器(Auto-encoder)
自编码器是一种从名字上完全看不出和神经网络有什么关系的无监督神经网络,而且从名字上看也很难猜测其作用。让我们看一幅图了解它的工作原理…
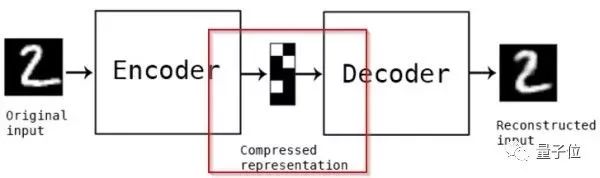
如上图所示,Autoencoder主要有2个部分:1. 编码器(Encoder) 2. 解码器(Decoder)。我们将输入(图片2)从左端输入后,经过了编码器和解码器,我们得到了输出….一个2。但事实上我们真正学习到是中间的用红色标注的部分,即数在低维度的压缩表示。评估自编码器的方法是重建误差,即输出的那个数字2和原始输入的数字2之间的差别,当然越小越好。
和主成分分析(PCA)类似,自编码器也可以用来进行数据压缩(Data Compression),从原始数据中提取最重要的特征。认真的读者应该已经发现输入的那个数字2和输出的数字2略有不同,这是因为数据压缩中的损失,非常正常。
应用场景:主要用于降维(Dimension Reduction),这点和PCA比较类似。同时也有专门用于去除噪音还原原始数据的去噪编码器(Denoising Auto-encoder)。
整理了最新保姆级入门到进阶人工智能Z料包免费获取关注威x公众号:咕泡AI 回复123 |
||||
还有CV+NLP+pytorch+深度学习资料+论文/学习/就业/竞赛指导+大牛技术解答 |
||||
①人工智能课程及项目【含课件源码】 |
||||
②人工智能必看优质书籍电子书汇总 |
||||
③国内外知名精华资源 |
||||
④优质人工智能大纲 |
||||
⑤人工智能行业报告 |
||||
⑥人工智能论文合集 |