新技术前沿-2023-ChatGPT基于人工智能技术的聊天机器人
chatgpt镜像网站
一文带你了解爆火的Chat GPT
ChatGPT系列文章
为什么ChatGPT这么强?—— 一文读懂ChatGPT原理!
1 简介
1.1 ChatGPT是什么
ChatGPT是一种基于人工智能技术的聊天机器人,它可以模拟人类对话,回答用户的问题和提供相关信息。ChatGPT使用自然语言处理技术,可以与用户进行语音或文本交互,并根据用户的输入提供个性化的回复。ChatGPT的应用范围广泛,包括客户服务、教育、娱乐、健康等领域。
ChatGPT火爆的背后,是终于有一款应用,能满足用户去搜索并一次性得到一个接近于满意的答案的需求。
1.2 ChatGPT的功能和优势
(1)自然语言处理能力:ChatGPT拥有强大的自然语言处理能力,可以理解人类语言中的语法和语义。这使得ChatGPT可以读懂用户的输入并做出适当的回应。
(2)多领域知识:ChatGPT被训练使用大量的数据来学习各种主题和领域的知识。因此,它可以回答关于不同主题的问题,并提供相关信息。
(3)个性化体验:ChatGPT可以根据用户的输入和反馈来调整其回答。这意味着对于同一问题,ChatGPT可能会针对不同用户以不同的方式回答。这种个性化体验使ChatGPT更加容易使用和可靠。
(4)智能搜索:ChatGPT可以利用互联网上的资源来寻找答案。当ChatGPT无法回答某个问题时,它会尝试在网络上搜索相关信息,并将结果传递给用户。
(5)学习能力:ChatGPT是一个机器学习模型,它可以通过受到越来越多的输入和反馈来不断改进自己的回答和表现。

1.3 ChatGPT的技术原理
ChatGPT其背后的技术原理主要包括以下几个方面:
(1)自然语言处理(NLP)
ChatGPT使用自然语言处理技术来理解用户输入的文本,并生成响应。这涉及到词汇分析、句法分析、语义分析等技术。
(2)机器学习(ML)
ChatGPT使用机器学习算法来训练模型,使其能够更好地理解和回答用户的问题。这包括监督学习、无监督学习和强化学习等技术。
(3)深度学习(DL)
ChatGPT使用深度学习技术来训练模型,使其能够更好地理解和回答用户的问题。这包括神经网络、卷积神经网络和循环神经网络等技术。
(4)语言模型(LM)
ChatGPT使用语言模型来预测下一个单词或句子。这包括n-gram模型、神经语言模型和transformer模型等技术。
(5)数据库(DB)
ChatGPT使用数据库来存储和管理用户的历史信息和聊天记录。这包括关系型数据库和非关系型数据库等技术。
1.4 OpenAI家族

我们首先了解下OpenAI是哪路大神。
OpenAI总部位于旧金山,由特斯拉的马斯克、Sam Altman及其他投资者在2015年共同创立,目标是开发造福全人类的AI技术。而马斯克则在2018年时因公司发展方向分歧而离开。
此前,OpenAI 因推出 GPT系列自然语言处理模型而闻名。从2018年起,OpenAI就开始发布生成式预训练语言模型GPT(Generative Pre-trained Transformer),可用于生成文章、代码、机器翻译、问答等各类内容。
每一代GPT模型的参数量都爆炸式增长,堪称“越大越好”。2019年2月发布的GPT-2参数量为15亿,而2020年5月的GPT-3,参数量达到了1750亿。

1.5 商业化
ChatGPT目前还尚处于发展的早期阶段,存在关键核心技术发展不成熟、算法模型不完善、理解能力不足、回答问题不够灵活和对语料库依赖过多等突出问题,距离大规模的商业化应用还需要很长一段时间。
据统计,从ChatGPT-1进化到ChatGPT-3的过程相当烧钱——参数量从1.17亿增加到1750亿,预训练数据量从5GB增加到45TB,其中GPT-3训练一次的费用是460万美元,总训练成本达1200万美元。
2 ChatGPT原理
2018年前,NLP
2018年,语言模型Bert和GPT
2022年5月,GPT-3
NLP技术发生跨越式发展的标志并不是ChatGPT本身,而应该是2017年-2018年间相继被提出的Transformer[和GPT。ChatGPT是Transformer和GPT等相关技术发展的集大成者。总体来说,ChatGPT的性能卓越的主要原因可以概括为三点:
(1)使用的机器学习模型表达能力强。
(2)训练所使用的数据量巨大。
(3)训练方法的先进性。
在步入正题之前,我们可以先梳理一下NLP发展的历史。
2.1 基于文法的模型
这个阶段,大家处理自然语言的主要思路就是利用语言学家的智慧尝试总结出一套自然语言文法,并编写出基于规则的处理算法进行自然语言处理。这个方法是不是乍听起来还行?其实我们熟悉的编译器也是通过这种方法将高级语言编译成机器语言的。可惜的是,自然语言是极其复杂的,基本上不太可能编写出一个完备的语法来处理所有的情况,所以这套方法一般只能处理自然语言一个子集,距离通用的自然语言处理还是差很远。
2.2 基于统计的模型
在这个阶段,大家开始尝试通过对大量已存在的自然语言文本(我们称之为语料库)进行统计,来试图得到一个基于统计的语言模型。比如通过统计,肯定可以确定“吃”后面接“饭”的概率肯定高于接其他词如“牛”的概率,即P(饭|吃)>P(牛|吃)。
虽然这个阶段有很多模型被使用,但是本质上,都是对语料库中的语料进行统计,并得出一个概率模型。一般来说,用途不同,概率模型也不一样。不过,为了行文方便,我们接下来统一以最常见的语言模型为例,即建模“一个上下文后面接某一个词的概率“。刚才说的一个词后面接另一个词的概率其实就是一元语言模型。
2.3 模型的表达能力
模型表达能力简单来说就是模型建模数据的能力,比如上文中的一元语言模型就无法建模“牛吃草”和“我吃饭”的区别,因为它建模的本质统计一个词后面跟另一个词的概率,在计算是选“草”还是选“饭”的时候,是根据“吃”这个词来的,而“牛”和“我”这个上下文对于一元语言模型已经丢失。你用再多的数据让一元语言模型学习,它也学不到这个牛跟草的关系。
2.3.1 模型参数数量
有人说,既然如此,为啥我们不基于更多的上下文来计算下一个词的概率,而仅仅基于前一个词呢?OK,这个其实就是所谓的n元语言模型。总体来说,n越大,模型参数越多,表达能力越强。当然训练模型所需要的数据量越大(显然嘛,因为需要统计的概率的数量变多了)。
2.3.2 模型结构
然而,模型表达能力还有另一个制约因素,那就是模型本身的结构。
对于基于统计的n元语言模型来说,它只是简单地统计一个词出现在一些词后面的概率,并不理解其中的各类文法、词法关系,那它还是无法建模一些复杂的语句。比如,“我白天一直在打游戏”和“我在天黑之前一直在玩游戏“两者语义很相似,但是基于统计的模型却无法理解两者的相似性。因此,就算你把海量的数据喂给基于统计的模型,它也不可能学到ChatGPT这种程度。
2.4 基于神经网络的模型
上文提到,统计语言模型的主要缺点是无法理解语言的深层次结构。曾有一段时间,科学家们尝试将基于文法的模型和基于统计的模型相结合。不过很快,风头就被神经网络抢了过去。
2.4.1 RNN & LSTM
刚开始,流行的神经网络语言模型主要是循环神经网络(RNN)以及它的改良版本LSTM。
RNN的主要结构如下, x是输入,o是输出,s是状态。

如果RNN作为语言模型的话,那x可以作为顺序输入进去的词汇,而o就可以作为输出的词汇,而s就是通过x计算o的过程中生成的状态变量,这个状态变量可以理解为上下文,是对计算当前词汇时前文所有出现过的所有单词的浓缩并在一次次的计算中不断迭代更新。这也是为啥RNN可以建模词与词关系的根本原理。
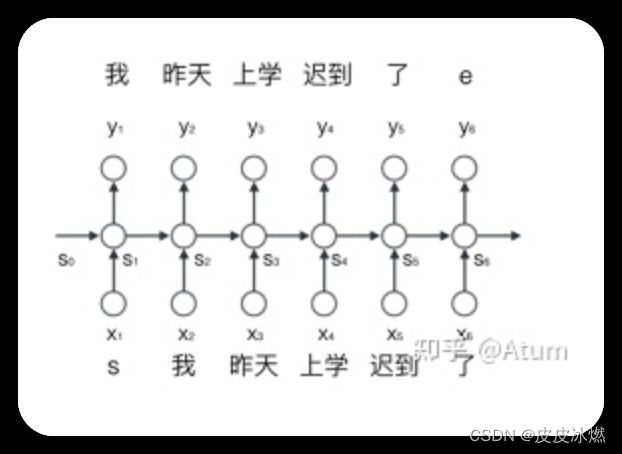
与简单的基于统计的模型相比,循环神经网络的主要亮点就是能够对一段文字中不同词之间的关系进行建模,这种能力在一定程度上解决了基于统计的模型无法理解深层次的问题。
2.4.2 Attention Mechanisms
在更进一步之前,我们不得不提一下注意力(Attention)机制。
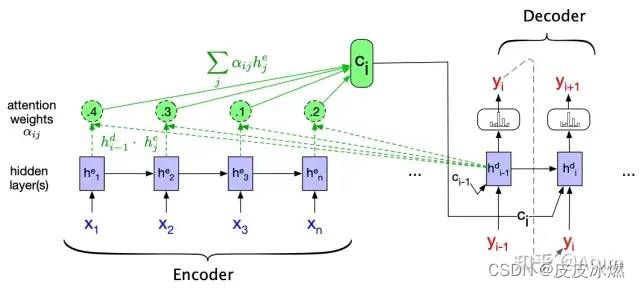
这个机制主要针对RNN语言模型中状态S作为上下文这一机制进行改进。。在RNN中计算当前词后的状态Si主要是通过计算上一个词时的状态Si-1迭代出来的。它的主要缺点就是它假设了距离较近的词汇之间的关系更密切。但是我们都知道,在自然语言中,这一假设并不是一直成立的。
引入Attention之后,计算第i个词后的状态从单纯的Si变成了S0,S1…Si的组合,而具体“如何组合”,即哪个状态比较重要,也是通过数据拟合出来的。在这样的情况下,模型的表达能力又得到了进一步的提高,它可以理解一些距离较远但是又非常密切的词汇之间的关系,比如说代词和被指代的名词之间的关系。
2.4.3 Transformer
接下来,我们终于可以祭出之前提过的NLP跨越式发展的标志之一,Transformer的提出!其实在有了Attention之后,Transformer的提出已经是顺理成章了。
Transformer的主要贡献在于:
(1)将Multi-Head Self-Attention直接内建到网络中。所谓Multi-Head Self-Attention其实就是多套并行的Self-Attention,可以用于建模的词与词之间的多类不同地关系。
(2)利用专用位置编码来替代之前RNN用输入顺序作为次序,使得并行计算成为了可能。
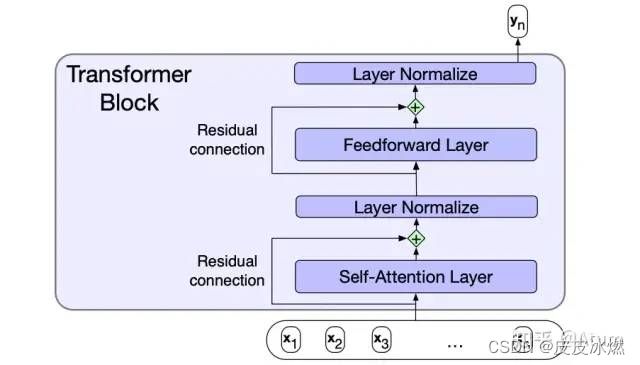
举一个形象但不准确的例子,对于句子I often play skating board which is my favorite sport. 如果使用Multi-Head Self-Attention,那就可以有一套Attention专门用来建模play和skating board的谓宾关系,有一套Attention用来建模skating board与favorite的修饰关系。从而使得模型的表达能力又得到了提高。
ChatGPT所依赖GPT3.5语言模型的的底层正是Transformer。
2.5 训练数据
OK,我们现在有一个名为Transformer模型了,这个模型通过Multi-head Self-Attention,使得建立词与词之间的复杂关系成为了可能。因此可以说是一个表达力很强的语言模型了。然而,单有语言模型没有数据就是巧妇难为无米之炊。
GPT-3.5的相关数据并未被公开,我们就只说说它的上一代GPT-3。GPT-3整个神经网络就已经有1750亿个参数了。这不难理解,想一想Attention凭什么确定在当前上下文下哪些词比较重要?而网络又怎样通过Attention和输入生成输出?这些都是由模型里面的参数决定的。这也是为啥模型结构一样的情况下参数越多表达能力越强。那这些模型的参数怎么拿到?从数据中学习!其实大多数所谓的神经网络的学习就是在学参数。
好家伙,要训练1750亿个参数的神经网络要喂多少数据呢?这么多!
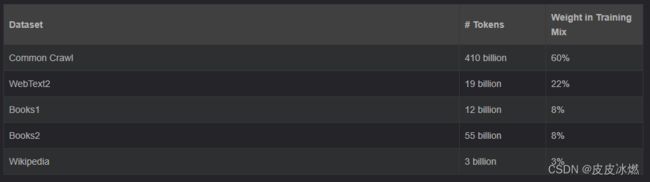
可以预想的是,表达能力如此之强的模型,在喂入万亿级的数据之后,其对语言本身的理解已经开始接近人类了。比如它处理句子的时候,会通过训练Attention参数理解到句子中哪些词之间存在关系的?哪些词和哪些词之间是同义的?等一系列比较深度的语言问题。
这还只是2020年的GPT-3。如今已经2022年了,相信GPT-3.5的模型表达能力比GPT-3又有相当大地提升。
2.6 训练方法
2.6.1 监督学习vs无监督学习
简单来说,监督学习就是在“有答案”的数据集上学习。如果我们要用监督学习(supervised learning)训练一个中文到英文的机器翻译模型,我们就需要有中文以及其对应的英文。整个训练过程就是不断地将中文送入到模型中,模型会给出一个英文的输出,这个时候我们对比一下英文的输出与标准答案的差距远不远(Measured by Loss Function),如果差距比较大,那我们就调整模型参数。这也成为早期针对机器翻译模型的主要训练方法。
2.6.2 迁移学习
然而,“有答案”的数据终究是有限的。这也是限制之前很多自然语言学习的模型设计复杂度的原因。不是不想提高模型的表达能力,而是提上去之后,参数太多,我们没有足量的“有答案”的数据来训练这个模型。
2018年,另一个我认为NLP跨越式发展的标志来了,那就是GPT的提出。
GPT的主要贡献在于,它提出了自然语言的一种新的训练范式。即现通过海量的数据的无监督学习来训练一个语言模型。正如我们之前提到过的,所谓语言模型即是在一个上下文中预测下一个词,这个显然是不需要带有标注的数据的,现有的任何语料都可以作为训练数据的。由于GPT的底层借用了表达能力很强的Transformer,互联网经过长时间的发展,海量的无标记的自然语言数据也并不再是稀缺的事物。导致了训练出来的模型其实对语言有了相当深入地理解。
这个时候,如果你想让这个语言模型能够陪你聊天,那在一个已经理解语言的模型的基础上,你只需要喂一些聊天的对话数据,使用监督学习来对模型进行针对性的微调(fine-tune),就可以使它学会如何聊天了。这个操作也叫做迁移学习(Transfer Learning)。
在迁移学习的过程中,微调一般是通过简单的监督学习来进行。简单来说,ChatGPT通过构建一些聊天的Prompt,让人类标注一些想要的回复,并用这些数据进行监督学习来微调。
2.6.3 强化学习
ChatGPT在使用进行微调之外,还使用了一种叫做reinforcement learning from human feedback (RLHF)的技术。这个技术在ChatGPT的主要作用是将预训练的模型的目标对齐到聊天这一具体的下游应用上。它也较大地提升了ChatGPT的聊天能力。
其总体原理如下图所示,在完成模型微调之后,先在人类的帮助下训练一个奖赏网络,这个奖赏网络具有对多个聊天回复好坏进行排序的能力。接着,利用这个奖赏网络,进一步通过强化学习(reinforcement learning)优化了聊天模型。

在这一通操作之后,ChatGPT就变成了我们现在看到的这样子。
2.7 总结
至此,我们基本上就已经能明白为什么ChatGPT这么强了,但是我相信很多同学肯定会表示“就这?我不信,它都会改bug了,给他一段代码他都知道代码是干什么的了。”
Okay,我们可以首先解释一下为什么它可以做到修改代码中的bug,根据OpenAI提供的信息 :“GPT-3.5 series is a series of models that was trained on a blend of text and code from before Q4 2021.”,我们可以知道GPT-3.5中的训练数据其实是包含了海量的代码数据。所以说GPT-3.5对代码的理解也是相当强的。将代码放入语言模型中进行训练后,训练出的语言模型已经可以做到代码语义级的搜索。
而ChatGPT又是怎么知道代码的功能的呢?可以参考一下OpenAI在GPT-3上做的代码训练的工作,大概就是将代码和其功能docstring注释放在一起做对比预训练(contrastive pretrain),这样可以让语言模型理解代码和其功能的关系。
总之,ChatGPT并没有那么神秘,它本质上就是将海量的数据结合表达能力很强的Transformer模型结合,从而对自然语言进行了一个非常深度的建模。对于一个输入的句子,ChatGPT是在这个模型参数的作用下生成一个回复。
有人会发现ChatGPT也经常会一本正经胡说八道,这也是这一类方法难以避免的弊端。因为它本质上只是通过概率最大化不断生成数据而已,而不是通过逻辑推理来生成回复。