后端开发实践系列之四——简单可用的CQRS编码实践
本文只讲了一件事情:软件模型中存在读模型和写模型之分,CQRS便为此而生。
20多年前,Bertrand Meyer在他的《Object-Oriented Software Construction》一书中提出了CQS(Command Query Seperation,命令查询分离)的概念,指出:
Every method should either be a command that performs an action, or a query that returns data to the caller, but never both. (一个方法要么作为一个“命令”执行一个操作,要么作为一次“查询”向调用方返回数据,但两者不能共存。)
这里的“命令”可以理解为更新软件状态的写操作,Martin Fowler将此称为“Modifier”;而“查询”即为读操作,是无副作用的。这种分离的好处在于使程序变得更容易推理与维护,由于查询操作不会更新软件状态,在编码时我们将更加有信心。试想,如果程序中出了一个bug,如果这个bug出现在查询过程中,那么我们至少可以消除这个bug可能给软件带来脏数据的恐惧。
后来,Greg Young在此基础上提出了CQRS(Command Query Resposibility Segregation,命令查询职责分离),将CQS的概念从方法层面提升到了模型层面,即“命令”和“查询”分别使用不同的对象模型来表示。
采用CQRS的驱动力除了从CQS那里继承来的好处之外,还旨在解决软件中日益复杂的查询问题,比如有时我们希望从不同的维度查询数据,或者需要将各种数据进行组合后返回给调用方。此时,将查询逻辑与业务逻辑糅合在一起会使软件迅速腐化,诸如逻辑混乱、可读性变差以及可扩展性降低等等一些列问题。
一个例子
设想电商系统中的订单(Order)对象,一开始其对应的OrderRepository类可以简单到只包含2个方法:
public interface OrderRepository {
void save(Order order);
Order byId(String id);
}
在项目的演进中,你可能需要依次实现以下需求:
- 查询某个Order详情,详情中不用包含Order的某些字段;
- 查询Order列表,列表中所展示的数据比Order详情更少;
- 根据时间、类别和金额等多种筛选条件查询Order列表;
- 展示Order中的产品(Product)概要信息,而Product属于另一个业务实体;
- 展示Order下单人的昵称,下单人信息属于另一个单独的账户系统,用户修改昵称之后,Order下单人昵称也需要相应更新;
- …
当这些需求实现完后,你可能会发现OrderRepository和领域模型已经被各种“查询”功能淹没了。什么?OrderRepository不是给领域模型提供Order聚合根对象的吗,为什么却充斥着如此多的查询逻辑?
CQRS通过单独的读模型解决上述问题,其大致的架构图如下:

对于Command侧,主要的讲究是将业务用例建模成对应的Command对象,然后在对Command的处理流程中应用核心的业务逻辑,其中最重要的是领域模型的建模,关于此的内容请参考笔者的《领域驱动设计(DDD)编码实践》文章,本文着重介绍Query侧的编码实践。
在本文中,查询模型(Query Model)也被表达为读模型(Read Model);命令模型(Command Model)也被表达为写模型(Write Model)。
CQRS实现模式概览
常见误解
在网上搜索一番,你会发现很多关于CQRS的文章都将CQRS与Event Sourcing(事件溯源)结合起来使用,这容易让人觉得采用CQRS就一定需要同时使用Event Sourcing,事实上这是一种误解。CQRS究其本意只是要求“读写模型的分离”,并未要求使用Event Sourcing;再者,Event Sourcing会极大地增加软件的复杂度,而本文追求的是“简单可用的CQRS”,因此本文将不会涉及Event Sourcing相关内容。更多内容,请参考简化版CQRS的文章。
另外需要指出的是,读写模型的分离并不一定意味着数据存储的分离,不过在实际应用中,数据存储分离是一种常见的CQRS实践模式,在这种模式中,写模型的数据会同步到读模型数据存储中,同步过程通常通过消息机制完成,在DDD场景下,消息通常承载的是领域事件(Domain Event)。
查询模型的数据来源
无论是单体还是微服务,所读数据的唯一正确来源(Single Source of Truth)最终都来自于业务实体(Entity)对象(比如DDD中的聚合根),基于此,所读数据的来源形式大致分为以下几种:
- 所读数据来源于同一个进程空间的单个实体(后文简称“单进程单实体”),这里的进程空间指某个单体应用或者单个微服务;
- 所读数据来源于同一个进程空间中的多个实体(后文简称“单进程跨实体”);
- 所读数据来源于不同进程空间中的多个实体(后文简称“跨进程跨实体”)。

读写模型的分离形式
CQRS中的读写分离存在2个层次,一层是代码中的模型是否需要分离,另一层是数据存储是否需要分离,总结下来有以下几种:
- **共享存储/共享模型:**读写模型共享数据存储(即同一个数据库),同时也共享代码模型,数查询据通过模型转换后返回给调用方,事实上这不能算CQRS,但是对于很多中小型项目而言已经足够;
- **共享存储/分离模型:**共享数据存储,代码中分别建立写模型和读模型,读模型通过最适合于查询的方式进行建模;
- **分离存储/分离模型:**数据存储和代码模型都是分离的,这种方式通常用于需要聚合查询多个子系统的情况,比如微服务系统。
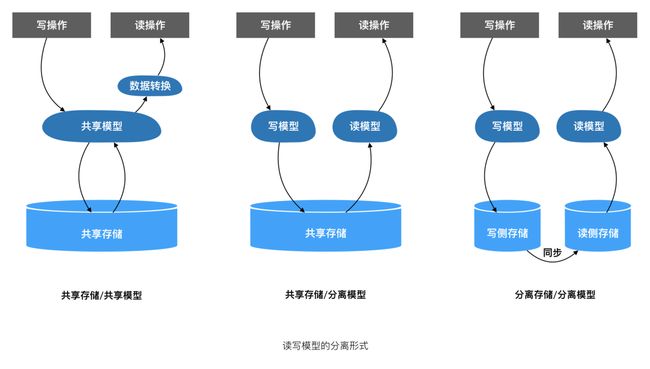
将以上“查询模型的数据来源”与“读写模型的分离形式”相组合,我们可以得到以下不同的CQRS模式及其适用范围:
| 数据来源形式 | 模型分离形式 | 适用范围 |
|---|---|---|
| 单进程单实体 | 共享存储/共享模型 | 其实算不上CQRS,但对于很多中小型项目已经足够 |
| 单进程单实体 | 共享存储/分离模型 | 适用于单实体查询比较复杂或者对查询效率要求较高的场景 |
| 单进程单实体 | 不同存储/分离模型 | 适用于对单个实体的查询非常复杂的场景 |
| 单进程跨实体 | 共享存储/共享模型 | 不适用 |
| 单进程跨实体 | 共享存储/分离模型 | 适用于查询比较复杂的场景,比如需要做多表join操作 |
| 单进程跨实体 | 分离存储/分离模型 | 适用于复杂查询或者对查询效率要求较高的情况 |
| 跨进程跨实体 | 共享存储/共享模型 | 不适用 |
| 跨进程跨实体 | 共享存储/分离模型 | 不适用 |
| 跨进程跨实体 | 分离存储/分离模型 | 主要用于微服务中需要对多个服务进行聚合查询的场景 |
总结下来,有以下几种常见做法:
- 单进程单实体 + 共享存储/共享模型
- 单进程单实体 + 共享存储/分离模型
- 单进程跨实体 + 共享存储/分离模型
- 单进程跨实体 + 分离存储/分离模型
- 跨进程跨实体 + 分离存储/分离模型
接下来,针对以上几种常见做法,本文将依次给出编码示例。
CQRS编码实践
本文的示例是一个简单的电商系统,其中包含以下微服务:
| 服务 | 用途 | 所含实体 | Git地址 |
|---|---|---|---|
| 订单服务 | 用于用户下单 | Order | ecommerce-order-service |
| 订单查询服务 | 用于订单的CQRS查询操作 | 无 | ecommerce-order-query-service |
| 产品服务 | 用于管理/展示产品信息 | Product Category(产品目录) |
ecommerce-product-service |
| 库存服务 | 用于管理产品对应的库存 | Inventory | ecommerce-inventory-service |
示例代码请参考:
https://github.com/e-commerce-sample
请注意,本文的示例电商项目只是一个虚构出来的简单项目,仅仅用于演示CQRS的各种编码模式,并不具备实际参考价值。
针对以上各种CQRS模式组合,本文将使用电商系统中的以下业务用例进行演示:
| CQRS模式 | 业务查询用例 | 所属服务 |
|---|---|---|
| 单进程单实体 + 共享存储/共享模型 | Inventory详情查询 | 库存服务 |
| 单进程单实体 + 共享存储/分离模型 | Product摘要查询 | 产品服务 |
| 单进程跨实体 + 共享存储/分离模型 | Product详情查询(包含Category信息) | 产品服务 |
| 单进程跨实体 + 分离存储/分离模型 | Product详情查询(包含Category信息) | 产品服务 |
| 跨进程跨实体 + 分离存储/分离模型 | Order详情查询(包含Product信息) | 订单查询服务 |
1. 单进程单实体 + 共享存储/共享模型
对于简单的单体或者微服务应用,这种方式是最自然最直接的方式,事实上我们并不需要太多设计上的思考便能想到这种方式。在这种方式中,存在单个领域实体模型同时用于读写操作,在向调用方返回查询数据时,需要针对性地对领域模型进行转换,转换的目的在于:
- 调用方所需的数据模型与领域模型可能不一致;
- 有些敏感信息是不能返回给调用方的,需要屏蔽;
- 从设计上讲,领域模型不能直接返回给调用方,否则会产生领域模型的泄露
- 将领域模型直接返回给调用方会在领域模型与对外接口间产生强耦合,不利于领域模型自身的演进。
这里,我们以“库存(Inventory)详情查询”为例进行演示,Inventory领域模型定义如下:
public class Inventory{
private String id;
private String productId;
private String productName;
private int remains;
private Instant createdAt;
}
在获取Inventory详情时,我们并不需要返回领域模型中的productId和createdAt字段,于是在Inventory中创建相应的转换方法如下:
public InventoryRepresentation toRepresentation() {
return new InventoryRepresentation(this.id,
this.productName,
this.remains);
}
这里的InventoryRepresentation即表示读模型,后缀Representation取自REST中的“R”,表示读模型是一种数据展现,下文将沿用这种命名形式。在InventoryApplicationService服务中返回InventoryRepresentation:
public InventoryRepresentation byId(String inventoryId) {
return repository
.byId(inventoryId)
.toRepresentation();
}
值得一提的是,在查询Inventory时,我们使用了应用服务(ApplicationService)-InventoryApplicationService,此时的InventoryApplicationService同时承担了读操作和写操作的业务入口,在实践中也可以将此二者分离开来,即让InventoryApplicationService只负责写操作,而另行创建InventoryRepresentationService专门用于读操作。
另外,抛开CQRS,为了保证每一个聚合根实体自身的完备性,即便在没有调用方查询的情况下,笔者也建议为每一个聚合根提供一个Representation并对外暴露查询接口。因此每一个聚合根中都会有一个toRepresentation()方法,该方法仅仅返回当前聚合根的状态,而不会关联其他实体对象(比如下文提到的“单进程跨实体”)。
2. 单进程单实体 + 共享存储/分离模型
有时,即便是对于单个实体,其查询也会变得复杂,为了维护读写过程彼此的清晰性,我们可以对读模型和写模型分别建模,事实上这也是CQRS的本意。
在Product服务中,需要返回Product的摘要信息,并对返回列表进行分页处理,为此独立于ApplicationService创建ProductRepresentationService,直接从数据库读取数据构建ProductSummaryRepresentation。
@Transactional(readOnly = true)
public PagedResource listProducts(int pageIndex, int pageSize) {
MapSqlParameterSource parameters = new MapSqlParameterSource();
parameters.addValue("limit", pageSize);
parameters.addValue("offset", (pageIndex - 1) * pageSize);
List products = jdbcTemplate.query(SELECT_SQL, parameters,
(rs, rowNum) -> new ProductSummaryRepresentation(rs.getString("ID"),
rs.getString("NAME"),
rs.getBigDecimal("PRICE")));
int total = jdbcTemplate.queryForObject(COUNT_SQL, newHashMap(), Integer.class);
return PagedResource.of(total, pageIndex, products);
}
这里,我们绕过了领域模型Product,也绕过了其对应的ProductRepository,以最快速的方式从数据库中直接获取数据。
3. 单进程跨实体 + 共享存储/分离模型
既然单个实体都有必要使用分离模型,那么在同一个进程空间中的跨实体查询更有理由使用分离模型的形式。对于简单形式跨实体查询,还用不着使用分离的存储,只需要做一些join联合查询即可。
在Product服务中,存在Product和Category两个聚合根对象, 在查询Product时,我们希望一并带上Category的信息,为此创建ProductWithCategoryRepresentation如下:
@Value
public class ProductWithCategoryRepresentation {
private String id;
private String name;
private String categoryId;
private String categoryName;
}
在ProductRepresentationService中,直接从数据库获取Product和Category数据,此时需要对PRODUCT和CATEGORY两张表做join操作:
@Transactional(readOnly = true)
public ProductWithCategoryRepresentation productWithCategory(String id) {
String sql = "SELECT PRODUCT.ID, PRODUCT.NAME, CATEGORY.ID AS CATEGORY_ID, CATEGORY.NAME AS CATEGORY_NAME FROM PRODUCT JOIN CATEGORY ON PRODUCT.CATEGORY_ID=CATEGORY.ID WHERE PRODUCT.ID=:productId;";
return jdbcTemplate.queryForObject(sql, of("productId", id),
(rs, rowNum) -> new ProductWithCategoryRepresentation(rs.getString("ID"),
rs.getString("NAME"),
rs.getString("CATEGORY_ID"),
rs.getString("CATEGORY_NAME")));
}
需要注意的是,如果join的级联太多,那么会大大影响查询的效率,并且使程序变得更加复杂。一般来讲,如果join次数达到了3次及其以上,建议考虑采用分离存储的形式。
4. 单进程跨实体 + 分离存储/分离模型
依然以返回ProductWithCategoryRepresentation为例,假设我们认为先前的join操作太复杂或者太低效了,需要采用专门的数据库来简化查询提升效率。
为此创建单独的读模型数据库表PRODUCT_WITH_CATEGORY:
CREATE TABLE PRODUCT_WITH_CATEGORY
(
PRODUCT_ID VARCHAR(32) NOT NULL,
PRODUCT_NAME VARCHAR(100) NOT NULL,
CATEGORY_ID VARCHAR(32) NOT NULL,
CATEGORY_NAME VARCHAR(100) NOT NULL,
PRIMARY KEY (PRODUCT_ID)
) CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
读写同步通常通过领域事件的形式完成,由于是在同一个进程空间中,因此读写同步相比于跨进程的同步来说,可以有更多的选择:
- 使用进程内事件机制(比如Guava的EventBus),在与写操作相同的事务中同步,这种方式的好处是可以保证写操作与同步操作的原子性进而确保读写间的数据一致性,缺点是在写操作过程中存在额外的数据库同步开销进而增加了写操作的延迟时间;
- 使用进程内事件机制,独立事务同步(比如Guava的AsyncEventBus),这种方式的好处是写操作和同步操作彼此独立互不影响,缺点是无法保证二者的原子性进而可能使系统产生脏数据;
- 使用独立的消息机制(比如RabbitMQ/Kafka等),独立事务同步,可以将查询功能分离为单独的子系统,事实上这种方式已经与“跨进程跨实体 + 分离存储/分离模型”相似,因此请参考“5. 跨进程跨实体 + 分离存储/分离模型”小节。
5. 跨进程跨实体 + 分离存储/分离模型
这种方式在微服务中最常见,因为微服务系统首先是多进程的,每个服务都内聚性地管理自身的聚合根对象,另外,微服务的数据存储通常也是独占式的,意味着在微服务系统中数据存储一定是分离的,在这种场景下,跨微服务之间的查询通常采用“API Compositon”模式或者本文的CQRS模式。
在"跨进程跨实体 + 分离存储/分离模型"中,存在一个单独的查询服务用于CQRS的读操作,查询所需数据通常通过事件机制从不同的其他业务服务中同步而来,读操作所返回的数据通过API Gateway或者BFF向外暴露,示意图如下:
在本文的示例电商项目中,需要在查询Order的时候同时带上Product的信息,但是由于Order和Product分别属于不同的服务,为此创建ecommerce-order-query-service查询服务,该服务负责接收Order和Product服务发布的领域事件以同步其自身的读模型OrderWithProductRepresentation。
在ecommerce-order-query-service服务中,在接收到OrderEvent事件后,OrderQueryRepresentationService负责分别调用Order和Product的接口完成数据同步:
public void cqrsSync(OrderEvent event) {
String orderUrl = "http://localhost:8080/orders/{id}";
String productUrl = "http://localhost:8082/products/{id}";
OrderRepresentation orderRepresentation = restTemplate.getForObject(orderUrl, OrderRepresentation.class, event.getOrderId());
List products = orderRepresentation.getItems().stream().map(orderItem -> {
ProductRepresentation productRepresentation = restTemplate.getForObject(productUrl,
ProductRepresentation.class,
orderItem.getProductId());
return new Product(productRepresentation.getId(),
productRepresentation.getName(),
productRepresentation.getDescription());
}).collect(Collectors.toList());
OrderWithProductRepresentation order = new OrderWithProductRepresentation(
orderRepresentation.getId(),
orderRepresentation.getTotalPrice(),
orderRepresentation.getStatus(),
orderRepresentation.getCreatedAt(),
orderRepresentation.getAddress(),
products
);
dao.save(order);
log.info("CQRS synced order {}.",orderId);
}
在本例中,ecommerce-order-query-service查询服务使用了关系型数据库,但在实际应用中应该根据项目所需选择适当的数据存储机制。例如,对于海量数据的查询,可以选择诸如MongoDB或者Cassandra之类的NoSQL数据库;而对于需要进行全文搜索的场景,可以采用Elasticsearch等。
事实上,在接收并处理事件时,存在2中风格,一种是本例中的仅将事件作为消息通知,然后调用其他服务的API接口完成同步,另一种是直接使用事件所携带的数据进行同步,更多关于这2种风格的比较,请参考笔者的《事件驱动架构(EDA)编码实践》文章。
事件驱动架构总是意味着异步,它将给软件带来以下方面的影响:
- 读模型和写模型之间不再是强事务一致性,而是最终一致性。
- 从用户体验上讲,用户发起操作之后将不再立即返回结果数据,此时要么需要调用方(比如前端)进行轮询查询,要么需要在用户体验上做些权衡,比如使用确认页面延迟用户对查询数据的获取。
关于Representation对象的命名
命名总是一件令开发者头疼的事情,特别对于需要返回多种数据形式的查询接口来说。为此,笔者自己采用以下方式命名不同的Representation对象,以Order为例:
- **
OrderRepresentation:**仅仅包含聚合根实体自身状态详情,一种常见的形式是通过Order.toRepresentation()方法获得 - **
OrderSummaryRepresentation:**用于返回聚合根的列表,仅仅包含Order本身的状态 - **
OrderWithProductRepresentation:**用于返回带有Product数据的Order详情 - **
OrderWithProductSummaryRepresentation:**用于返回带有Product数据的Order列表
当然,命名是一件见仁见智的事情,以上也绝非最佳方式,不过总的原则是要一致、清晰、可读。
什么时候该采用CQRS
事实上,不管是Martin Fowler、Udi Dahan还是Chris Richardson,都提醒到需要慎用CQRS,因为它会带来额外的复杂性;而另有人(比如Gabriel Schenker)却提到,当前很多软件逻辑复杂性能低下恰恰是因为没有选择CQRS造成的。
的确,不管在架构层面还是编码层面,采用CQRS的都会增加程序的复杂度和代码量,不过,这种复杂性可以在很大程度上被其所带来的“条理性”所抵消,“有条理的多”恰恰是为了简单。因此,当你的项目正在承受本文一开始的“一个例子”小节中所提到的“痛楚”时,不妨试一试本文提到的几种简化版的CQRS实践。
总结
本文本着“简单可用的CQRS”的目的讲到了不同的CQRS实现模式,其中包含如何在单体和微服务架构中进行不同的CQRS落地实践。可以看出,CQRS并不像人们想象中的那么难,通过适当的设计与选择,CQRS可以在很大程度上将程序架构变得更加的有条理,进而使软件项目在CQRS上的付出变成一件值得做的事情。
更多精彩洞见,请关注微信公众号:ThoughtWorks洞见