版本:
JDK8
一、结构分析
首先,我们对其各自结构分析。
1.Hashtable
其类在java.util包下,
查看其源码,其类的注解大致介绍了这个类,我们阅读后大概的意思就是:
这是一个线程安全的、实现了哈希表(键值对结构)的一个类。
简单通俗的可以用图来直观表现:
没错,就是以数组+链表结构来实现集合操作。
接下来我们所要去研究的就是元素如何存储、如何取值、数据临界操作、使用范围以及注意事项,最终我们从中学习到其目的以及思想,提高我们的思维。
通过源码来分析一波:
- 基本私有变量和默认初始化
/**
* The hash table data.集合中存放数据的数组
*/
private transient Entry[] table;
/**
* The total number of entries in the hash table.当前数组中的元素个数
*/
private transient int count;
/**
* The table is rehashed when its size exceeds this threshold. (The
* value of this field is (int)(capacity * loadFactor).)数组需要进行扩容的峰值
*
* @serial
*/
private int threshold;
/**
* The load factor for the hashtable.加载因子,即数组实际能存储元素个数的百分比
*
* @serial
*/
private float loadFactor;
/**
* The number of times this Hashtable has been structurally modified
* Structural modifications are those that change the number of entries in
* the Hashtable or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the Hashtable fail-fast. (See ConcurrentModificationException).
*/
private transient int modCount = 0;
/**
* Constructs a new, empty hashtable with a default initial capacity (11)
* and load factor (0.75).默认出初始化数组大小11,加载因子0.75
*/
public Hashtable() {
this(11, 0.75f);
}
- put操作
//这里使用synchronized关键字来保证线程安全
public synchronized V put(K key, V value) {
//这里限定了HashTable中value不允许为null
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
//要存入的元素已经存在的情况下的操作
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
/**
* 这里通过hash值和数组长度来确定元素存储的位置
*/
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry entry = (Entry)tab[index];
//这里判定是否是存在的key
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//经过判定,插入的是一个新的值,尽心插值操作
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry tab[] = table;
//数组中的元素数量是否到达了临界值,是进行扩容操作
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry e = (Entry) tab[index];
//这里使用到了一个链表操作,即同一个hash值的不同对象key的最新的元素永远在链表的最前端
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
- get操作
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
- 扩容操作
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table;
// overflow-conscious code 扩容大小为 x2 + 1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry old = (Entry)oldMap[i] ; old != null ; ) {
Entry e = old;
old = old.next;
//重新计算元素在数组中索引的位置
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry)newMap[index];
newMap[index] = e;
}
}
}
源码基本分析完毕,我们总结出Hashtable的特性:
- 数组+链表 结构
- 通过
synchronized关键字修饰在方法上保证线程安全
从中我们学到的一些方法:
- 通过key的hashCode和数组的长度来确定元素位置,这样可以保证查询效率为O(1)
- 在key的hashCode的值相同的时候,通过链地址法(其实就是链表结构数据)来解决所谓的哈希冲突
缺点:
- 由于基本的查询、插入、修改方法都是使用
synchronized关键字修饰来保证线程安全的,即对象锁,所以多线程下执行效率肯定低下。
2.HashMap
一、HashMap的结构及其原理
1.什么是HashMap
HashMap是基于哈希表的Map接口的非同步实现。是双列集合,一次储存键与值键与值一一对应(键是唯一性,值不唯一,同时键与值都可以是null)。
2.数据结构
Java中最基本的数据结构是数组和引用(指针),HashMap通过这两个数据结构实现。HashMap是一个==“链表散列”==的数据接口,即通过数组+链表结合实现。而从jdk1.8起,为了进一步提高效率,引入了红黑树,即数组+链表/红黑树。(当同一hash索引下的节点个数超过8个的话,就通过红黑树的形式存储起来,当然若数组大小小于64即为扩容)

为什么要采取这种结构呢?
这里我们简单的说一下,不做深究:
1.数组的查找通过索引查找是非常快的,时间复杂度o(1)。
2.链表呢,我们删除和增加效率是非常高的。
3.红黑树,将普通链表的查找速度由o(n)降低到了o(logn)
所以这几者相结合,将会达到很好的效果,具体如何结合的,我们通过下面的分析一步一步探究。
3.通过源码一步一步研究HashMap的存储元素过程
去看了源码,密密麻麻的好多代码啊,难道要一行一行的去研究吗?
不用,研究他们的核心部分即可,那从何处开始研究呢?
我们就通过我们使用HashMap的步骤去研究:
1.
HashMap map = new HashMap();
附上这行代码的源码:
/**
* 哈希表的加载因子
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
/**
* 在构造函数未指定的时候,加载因子的默认值=0.75f
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted 其他的属性都是默认值
}
这里我们要记住的就是loadFactor(加载因子),那么这个加载因子有什么用呢?
这个加载因子是和数组的空间利用率有关,即一个数组的长度为length时,我们所能存储元素的长度只能是length*loadFactor。
2.
public V put(K key, V value),key代表键,value代表值
看这个方法的源代码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//继续解刨,看putVal(hash(key),key,value,false,true)
//首先我们看看hash(key)干嘛的
static final int hash(Object key) {
int h;
/*
我们看到,当key为空的时候,会返回值0,不为空的时候,会将key的哈希值的高位(16位)与低位(16位)进行^(异或)计算,然后返回结果值,这个结果有什么用呢,是用来用于后面再次计算得出所在数组中的索引值
*/
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//这个就是储存每个节点的具体步骤了
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
/*
变量名解释:tab(数组) p(节点,数组中每个元素)
n为数组的长度,i为数组的索引
*/
Node[] tab; Node p; int n, i;
//如果tab引用为空指针,或者数组长度为0,即返回一个新的数组,长度为n
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/*
这里有个(n-1)&hash式子,计算的结果是数组的索引
这里的逻辑是判断数组中这个索引的对应的值是否为null,若是
为空的话,将将这个节点储存在这个索引的位置
*/
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {//执行这里,说明这个索引位置储存的不是链表就是红黑树了
Node e; K k;
/*
这里的逻辑是,这个索引位置已有节点了,那么就判断添加的的key
和这里已有节点的key是否是同一个地址的或者是否是内容相同的,是的话,就将添加进来的value值替换掉原有节点的value值
*/
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判断当前索引位置的对象是否属于红黑树,是的话,添加上去
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {//执行这里说明这里不是红黑树,是链表
/*
遍历循环链表
*/
for (int binCount = 0; ; ++binCount) {
//此节点的下一个节点是否为空节点,是的话,直接赋值节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//判断此位置的链表个数是否超过了8个,超过
//将执行teeifyBin()方法(扩容或转为红黑树),并结束并推出循环
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//节点不为空,判断哈希值和key是否是一样的,是的话结束并退出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;//遍历下一个节点
}
}
//判断添加的节点是否为新节点,不是新节点,则将新的value值替换老的value值,并返回老的value值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//记录HashMap结构修改的个数(只有添加了新的节点)
++modCount;
//添加元素后此时数组中元素个数>数组中规定的个数(数组长度*负载因子)时扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
这里我们通过源码分析了我们使用HashMap添加对象的一系列过程,这里我们画个图看看一比较形象的逻辑:
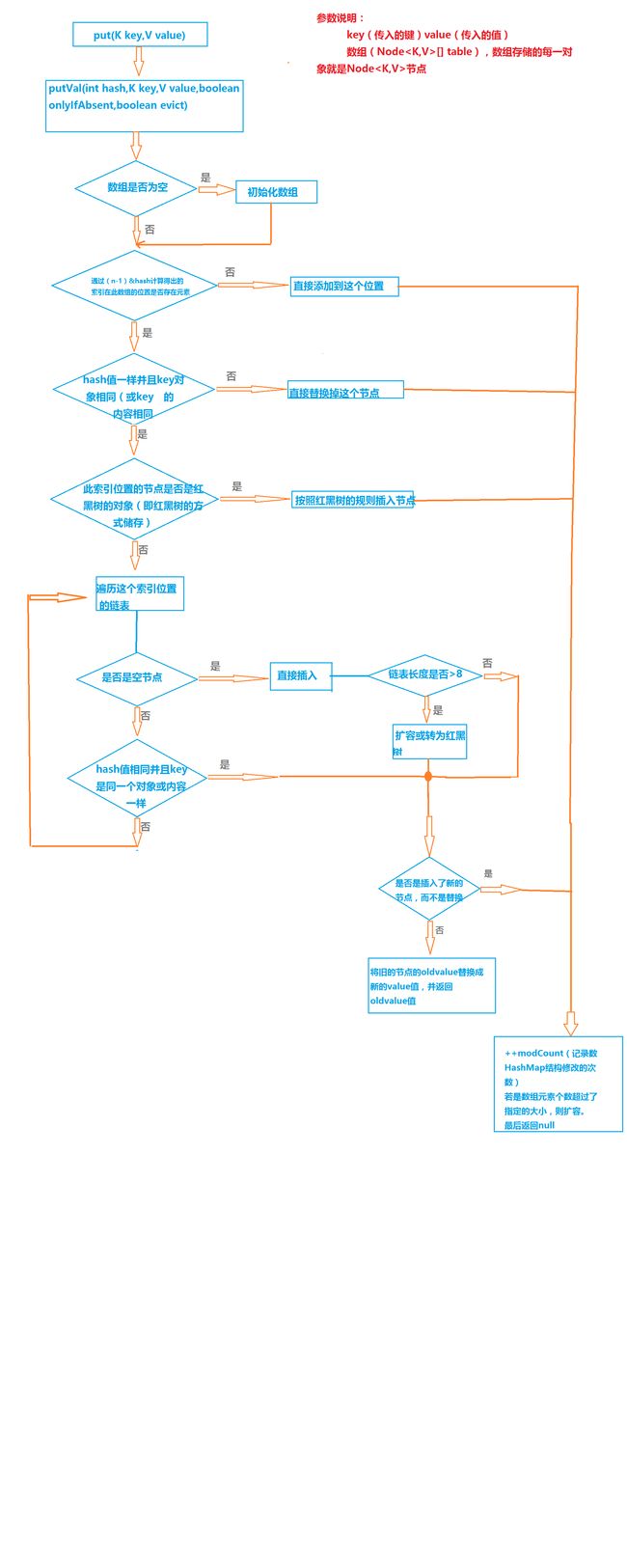
通过分析put(K key,V value)的源码,我们知道了HashMap内部结构:
- 数组Node
:
//节点,通过内部内实现
static class Node implements Map.Entry {
final int hash;//存放hash值(key的)
final K key; //存放key值
V value; //存放value至
Node next; //存放下一个节点的地址
Node(int hash, K key, V value, Node next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
...
}
上面就是链表的组成部分,一个一个节点组成的。而数组呢,就是存放每一个hash值相同的节点,从第一个开始存放,往后相同的hash值节点便通过链表的形式存放。
- hash算法:
hash算法是我们需要了解的部分,因为你存入的元素放在数组的那个位置是通过这个来计算的,即上面出现的计算公式:
(n-1)&hash
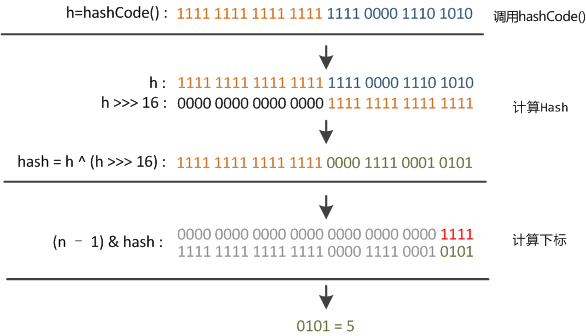 计算出索引位置的算法.png
计算出索引位置的算法.png
具体计算过程如图所示。(这里需要注意的是,因为数组的长度始终是2的次方幂,这里的与运算,就相当于给length-1取模运算)
注意:通过这样的算法,我们其实可以知道,总会有一种情况,计算得出的值是相同的,所以需要解决哈希冲突,HashMap的解决办法就是一开始我们介绍的形式,数组+链表,即==链表法==。还有一种方法是==开放地址法==(即通过探测算法,当此位置被占用,即寻找下一个可用的位置)。
二.HashMap的哈希表散列运算
我们知道每一个对象都有它的哈希值,这是Object类中的本地方法,具体怎么计算的,目前我也不知道,只要知道这个对于每一个对象得出的值基本不可能即可。
因为通过%(取模运算)是要进行/(除法)运算的,效率低。(其实到底低多少我也不知道)
而通过&(与运算)是直接通过对二进制来计算的,效率高。
那么:
(n-1)&hash
n为什么要-1呢?
首先,我们要知道n是数组的长度,而HashMap的数组长度是==偶数,即长度为2的幂次方,每次扩容都是之前的一倍==。
然后我们知道偶数的二进制最低位是0,那好,偶数的&(与运算)我们可以很明确的得出,结果必然是偶数,所以,如果直接用偶数来进行哈希表散列将浪费一半的空间。
所以,我们将n-1得到奇数,而奇数进行与运算,得到的结果可能是可能是偶数,也可能是奇数,这样就不会浪费空间了!
所以,利用这个特性1&N(N为0/1),结果可能为0,也可能为1,这就解释了为什么扩容要是2的幂次,因为2的幂次 -的二进制结果所有位都是1,这样结果可能性会增加。
3.总结
通过以上我们总结出两者区别:
- Hashtable实现了线程安全,HashMap没有实现线程安全
- Hashtabke是
数组+链表结构,HashMap是数组+链表+红黑数结构 - 不考虑线程安全情况下,HashMap效率要远远高于Hashtable