支持亿级标签接入,ClickHouse在广域物联网云平台架构的探索与实践

业务背景:自纵行科技在2020年推出ZETag云标签以来广受市场好评,目前已经在物流、资产管理、库存盘点等领域有了许多落地项目。在业务量急速增加的过程中,ZETag云平台作为解决方案中重要的一环,也面临了许多挑战与考验。本文分享了在建设ZETag云平台过程中,我们在架构设计方面的一些思路与实践。
面临的挑战
1)设备量与数据量的快速增加
不同于传统的物联网终端,低成本ZETag云标签更多用于物的定位与追踪,同时,还有次抛等新的应用场景。因此,ZETag云标签的数量远远大于传统的物联网终端,万级别标签每客户将是业务常态,可以预估ZETag云平台需要管理的标签量将在百万到千万级,每天需要保存的上报数据将达到亿级,这对平台数据存储的写性能、扩展性以及存储成本将是一个巨大的考验。
2)如何在保留云上扩展性的同时,降低私有化部署的成本
物联网行业是一个典型的B2B行业,私有化部署是很多对数据私密性较高要求的客户的强需求,一个复杂的大数据平台架构也许能够满足我们对性能、扩展性的需求,但是却同样有非常高的运维成本与设备成本,对于大部分成本敏感的中小长尾客户来说,较高的实施运维成本是难以承受的,因此在离线部署私有云的场景,除了性能之外,整体架构的轻量化也是一个重要的考量因素。
3)如何支持实时灵活的多维分析,挖掘数据价值
ZETag云标签业务大多涉及指标告警、实时追踪、多维分析报表等,端到端的延迟需要控制在秒级别,同时也需要满足客户不同条件、维度、指标的实时统计与分析,因此对于数据的查询延迟、灵活性都有比较高的要求。
技术选型
综合来看,查的快、写的快、成本低是我们三个比较核心的诉求。我们调研了业内常见的开源分布式OLAP数据库,最终确定了 ClickHouse+MySQL 混合存储的方式作为ZETag云平台最终存储方案。
其中,ClickHouse用于存储网关、终端、标签的事件数据,例如心跳、注册等。同时,MySQL专注存储设备的物模型数据,通过两者的协同配合来更好的支撑平台的业务目标,其中ClickHouse的一些独特的特性是我们选择它的主要原因。
-
1.相比其他时序数据库,例如ElasticSearch、HBase等,ClickHouse的LSM-Tree实现机制更为极致,拥有更强大的写性能,这意味着可以用更少的成本支撑更大的数据量。
-
2.ClickHouse支持 Apache 2.0 license开源协议,相比ElasticSearch协议更加友好,同时也不像InfluxDB,开源版本有功能上的限制。
-
3.ClickHouse的架构非常的轻量,相比其他数据库产品,例如OpenTSDB依赖Hbase、Druid.io依赖HDFS,ClickHouse单机版本完全可以不依赖第三方组件,并且只有一个服务进程,有着非常低的离线部署运维成本。
-
4.由于ClickHouse的MPP架构及优秀的工程实现,查询性能在各大基准测试榜中名列前茅。
特性分析
# 存储结构
LSM-Tree是业内存储时序数据的常用数据结构,它的核心思路其实非常简单,每次有数据写入时并不将数据实时写入到磁盘,而是先缓存在内存的memTable中并使用归并排序的方式将内存中的数据合并,等到积累到一定阈值之后,再追加到磁盘中,并按照一定的频率与触发阈值将磁盘存储的数据文件进行合并。
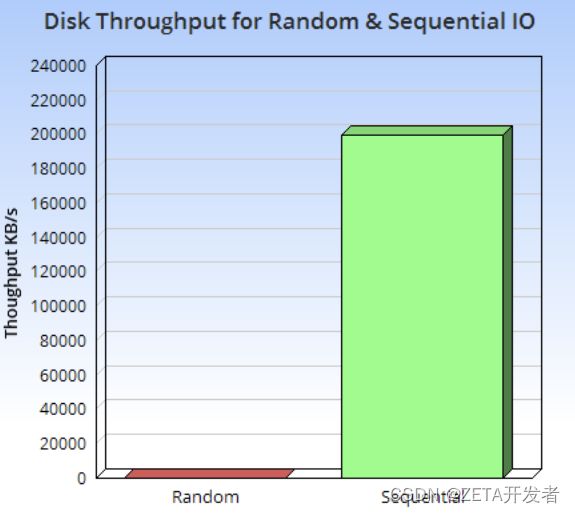
这种方案利用了硬盘顺序写性能远大于随机写的特性,降低了硬盘的寻道时间,对于物联网设备所产生时序数据这种写远大于读的场景来说有非常好的优化效果。

由下图可以看到,硬盘的顺序IO性能与随机IO性能有着巨大的差距。
传统的LSM-Tree虽在写性能上很优秀,但随之带来的读放大与写放大依然是业内难以解决的问题,目前最优秀的LSM-Tree结构数据库读写放大倍数也在20倍以上,读写放大主要来自于几个方面:
- 1.由于数据需要buffer在内存之中,为了保证瞬时停机例如断电时数据不丢失,因此所有内存里的数据都需要记录一份WAL(Write Ahead Log),用于在极端时刻进行数据恢复。
- 2.后台进行数据文件合并时是一个先读取再写入的过程,这个行为同样会造成写放大。
- 3.当数据库发生数据查询操作时,由于LSM-Tree写数据的方式会生成较多的小文件,读请求往往需要跨越内存与硬盘的多个memTable与数据文件才能获取到正确的结果。
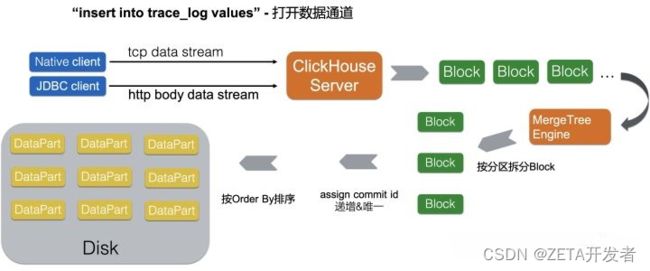
相比其他使用LSM-Tree的数据库,ClickHouse在设计上直接取消了memTable的内存聚合阶段,只对同一写入批次的数据做排序并直接落盘。因此,完全不需要传统的写WAL的过程,减少了数据的重复写入。
同时,ClickHouse也限制了数据的实时修改,这样就减少了合并时产生的读写放大,这个思路相当于限缩了数据库的使用场景,但却换取了更强大的读写性能。
对于物联网设备产生的数据来说,写入时本来就是一定间隔的批量写入,同时极少有数据修改的场景,与ClickHouse的优化方向正好一致。
# 列式存储带来的极高压缩比
相比于传统的行存储数据库(例如MySQL),ClickHouse采用列式存储的方式存储数据,而列式存储,能够带来更极致的压缩比。
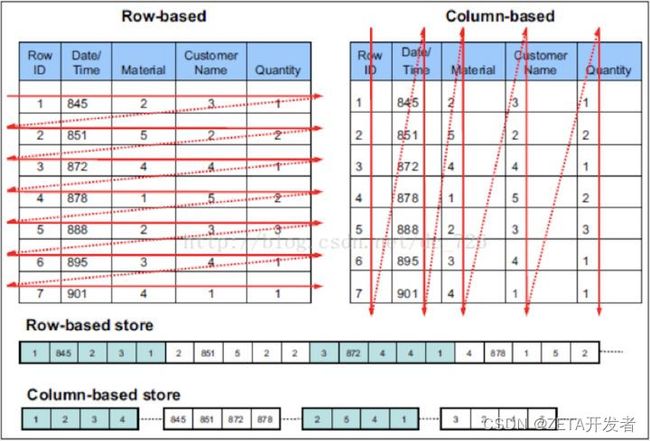
压缩的本质是按照一定步长对数据进行匹配扫描,当发现重复部分的时候就进行编码转换。数据中的重复项越多,则压缩率越高,举一个简单的例子:
压缩前:12345678_2345678
压缩后:12345678_(8,7)
上述示例中的 (8,7),表示如果从下划线开始向前移动8个字节,并向前匹配到7个字节长度的重复项,即这里的2345678,真实的压缩算法肯定比这个简单的例子复杂,但本质是一样的。显而易见,同一个列字段的数据,因为它们拥有相同的数据类型和现实语义,重复项的可能性自然就更高,在大数据量的场景下,更高的压缩比,会给我们带来更大的性能和成本优势。
- 1.分析场景中往往有需要读大量行但是少数列的情况。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
- 2.更高的压缩比意味着更小的文件,从磁盘中读取相应数据耗时更短。
- 3.高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
- 4.同样更高的压缩比下,相同大小的硬盘可以存储更多的数据,大大地降低了存储成本。
# 极低的查询延迟
在索引正确的情况下,ClickHouse可以说是世界上最快的OLAP分析引擎之一。这里快指的就是查询延迟,简单说就是用户发起一次查询到用户获取到结果的时间,这种快很大的原因也来自于ClickHouse极端的设计思路与优秀的工程实现。
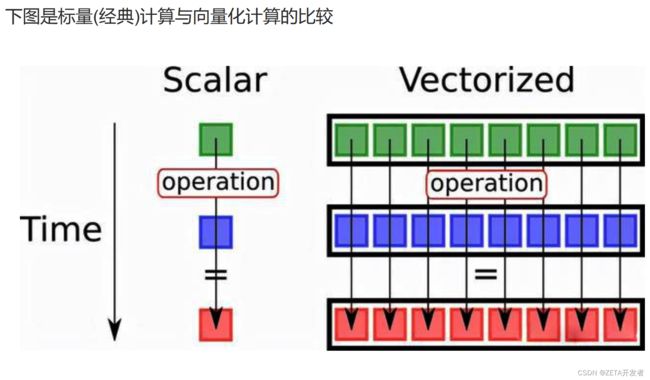
ClickHouse的大部分计算操作,都基于CPU的SIMD指令,SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据,它的原理是在CPU寄存器层面实现数据的并行操作,例如一次for循环每次处理一条数据,有8条数据则需要循环8次,但使用SIMD指令可以让这8条数据并行处理,从而在一次就得到结果,这种方式被称为向量化计算。
ClickHouse的每一次查询或统计分析操作,都会尽可能的使用所有的CPU资源来进行并行处理,这种方式能够让廉价的服务器同样拥有极低的查询延迟,从而在海量数据的场景下保证平台产品的流畅与快速,而快速和流畅就是最好的用户体验。
ClickHouse在工程实现上也同样坚持了快这个原则,可以看到在ClickHouse源码中不断地给函数或者算子的局部逻辑增加更多的变种实现,以提升在特定情形下的性能,根据不同数据类型、常量和变量、基数的高低选择不同的算法。
例如ClickHouse的hash agg,用模板实现了30多个版本,覆盖了最常见的group key的类型,再比如去重计数函数uniqCombined函数,当数据量较小的时候会选择Array保存,当数据量中等的时候会选择HashSet保存,当数据量很大的时候,则使用HyperLogLog算法等等,Clickhouse的性能,就是大量类似的工程优化堆积起来的。
# 那么代价是什么呢?
然而,世界上并没有完美无缺的方案,方案设计更像是一场trade-off,比起了解它的优点,更重要的是能不能接受它的缺点。
为了更极致的写入性能,ClickHouse去掉memtable缓存数据再写入的机制以及实时修改的能力,前者需要客户端进行额外的攒批操作,而后者限缩了数据库的使用场景。ClickHouse其实更像一个单机的数据库,极致的单表性能优化,非常轻量的安装部署流程,这些给我们带来了非常低的离线部署成本,但在大规模分布式场景下却有着一些缺陷。
在分布式查询的场景上,ClickHouse使用Distributed Table来实现分布式处理,查询Distributed Table相当于对不同节点上的单机Table进行一个UNION ALL,这种办法对付单表查询还可以,但涉及多表Join就有点力不从心了,在分布式多表Join的场景下,由于没有Data shuffling之类的功能,ClickHouse需要耗费更多的内存和带宽来缓存和迁移数据,造成了性能的严重下降,大部分人不得不使用大宽表的方式来规避这个问题。
另外,运维一个分布式ClickHouse集群也是非常头疼的一个点。ClickHouse并不具备数据均衡功能,提供的Distributed Table由于写入性能太差形同虚设,往往需要通过业务层来保证分发的数据足够均匀,开源的ClickHouse并没有集中的元数据管理,ON CLUSTER语法能够节约一定的操作,但集体扩容以后由于新的节点并不会同步元数据信息,也不会自动平衡数据的负载,因此需要大量的人工介入。
作为从标准的计算存储一体的Shared-nothing结构发展而来的数据库,ClickHouse对于云原生和存算分离的支持也比较一般,目前社区正在朝这个方向努力,只能说还算是未来可期。
实践经验
# 写入优化
由于ClickHouse特殊的数据写入方式,为了获得更高的性能我们需要在写入客户端上进行一定的定制化开发。
在整体架构上,我们主要使用Flink来实现ClickHouse数据的写入,由于目前还没有官方的Connector,我们基于社区接口自研了自己的ClickHouse Connector,主要实现了以下功能:
- 1.实现了基于表与分区的攒批功能,由于ClickHouse特殊的写入策略,相同表与分区数据在同一批次进行写入会有更好的性能,同时也能减少写入时生成的文件数量。
- 2.支持通过配置不同算法将数据以不同的方式分发到节点的shard中,实现了常规的Hash、轮询、加权等等算法。
- 3.背压感知与限流功能,通过查询ClickHouse不同shard的文件碎片数,经限流算法评估后在必要时触发Flink的反压机制,防止ClickHouse客户端报错造成写入性能持续下降。
- 4.支持通过接入设备数自动化调节攒批的各种参数、包括数据量大小、条数、间隔时间等等,减少在参数配置时的工作量与门槛。
# 冷热分离
时序数据的价值往往与时间相关,越靠近当前时间的热数据越有价值,会被频繁的使用,越久远的冷数据价值相对较低,但依然需要长期的存储。因此,可以通过冷热分离的策略将近期高价值的数据存储在相对昂贵的存储来提升统计分析的性能,并在一段时间后将数据移动到相对便宜的大容量存储中,这种方式可以在不影响用户体验的情况下较好的节省数据的存储成本。
在ClickHouse 19.15版本之后开始原生支持冷热分离的存储策略,通过相应配置可以按照时间或大小自动的将数据迁移到冷盘。
disk_ssd
1073741824
disk_hdd
0.2
上述配置中配置了一个名为moving_from_ssd_to_hdd的存储策略,该策略包含了hot和cold两个volume。
在volumes的前后顺序决定了volume的优先级,意味着part会优先在这个卷上生成,且没有轮询策略。因此volumes内的顺序是敏感的。hot中含有一块ssd类型的disk;cold中含有一块hdd类型的disk。move_factor定义了前一个卷剩余存储空间的量。当存储空间小于这个值时,会将前一个volume中相对较早的part迁移到后面的volume中。上述配置表示,当hotvolume的存储空间超过80%时,便将数据迁移到cold中。
# 字段扩展场景
查询中需要扩充字段是非常常见的业务场景,在我们的架构中部分字段甚至存在不同的数据库例如MySQL中。目前,业内的常见做法是通过流式计算引擎,例如Flink、Storm等,在入库之前进行数据字段的拼接,在ClickHouse中直接存储计算后的数据。这种方案可以最大的保证数据的查询效率,但需要付出额外的开发工作量以及硬件资源,特别是SQL JOIN的场景,需要在流式计算引擎中缓存大量实时更新的状态,有着很大的资源消耗。
而我们在实践中发现,有些更新频率很低的字段扩充场景,例如设备型号、所属企业等其实有更好的解决方案,通过ClickHouse提供的Dictionaries特性能够代替部分更新频率较低JOIN场景。
CREATE [OR REPLACE] DICTIONARY [IF NOT EXISTS] [db.]dictionary_name [ON CLUSTER cluster]
(
key1 type1 [DEFAULT|EXPRESSION expr1] [IS_OBJECT_ID],
key2 type2 [DEFAULT|EXPRESSION expr2],
attr1 type2 [DEFAULT|EXPRESSION expr3] [HIERARCHICAL|INJECTIVE],
attr2 type2 [DEFAULT|EXPRESSION expr4] [HIERARCHICAL|INJECTIVE]
)
PRIMARY KEY key1, key2
SOURCE(SOURCE_NAME([param1 value1 ... paramN valueN]))
LAYOUT(LAYOUT_NAME([param_name param_value]))
LIFETIME({MIN min_val MAX max_val | max_val})
SETTINGS(setting_name = setting_value, setting_name = setting_value, ...)
COMMENT 'Comment'
ClickHouse支持将外部数据源例如MySQL、Redis、PostgreSQL等等配置为一个内置的字典,在查询中可以通过函数进行key -> attributes的转换,变相的实现了类似JOIN的功能,这种方式相比于JOIN有着更好的性价比。
总结
在物联网这个业务场景下,需要存储大量的时序事件数据并且不需要事后进行修改,刚好契合了ClickHouse的写入性能优势并且规避了使用场景上的劣势,同时ClickHouse部署成本低、架构轻量化的优势也很符合当前物联网客户需求。
目前,ZETag云平台已经对接大量的网关、标签、设备,帮助许多客户实现了降本增效,这些都离不开一个高效稳定的存储计算引擎的帮助,后续我们也会持续优化产品,积累优秀实践,打造一个更强大、稳定、通用的物联网云平台。