连你女朋友都能看懂的分布式架构原理!
目录
- 从一个新闻门户网站案例引入
- 推算一下你需要分析多少条数据?
- 黄金搭档:分布式存储+分布式计算
这篇文章聊一个话题:什么是分布式计算系统?
一、从一个新闻门户网站案例引入
现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。
但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。
如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。
比如说现在你有一个网站,咱们假设是一个新闻门户网站好了。每天是不是会有可能上千万用户会涌入进来看你的新闻?
好的,那么他们会怎么看新闻呢?
其实很简单,首先他们会点击一些板块,比如“体育板块”,“娱乐板块”。
然后,点击一些新闻标题,比如“20年来最刺激的一场比赛即将拉开帷幕”,接着还可能会发表一些评论,或者点击对某个好的新闻进行收藏。
那么你的这些用户干的这些事儿有一个专业的名词,叫做“用户行为”。
因为在你的网站或者APP上,用户一定会进行各种操作,点击各种按钮,发表一些信息,这些都是各种行为,统称为“用户行为”。
好了,现在假如说新闻门户网站的boss说想要做一个功能,在网站里每天做一个排行榜,统计出来每天每个版块被点击的次数,包括最热门的一些新闻。
然后呢,在网站后台系统里需要有一些报表,要让他看到不同的编辑产出的文章的点击量汇总,做一个编辑的绩效排名,还有很多类似的事情。
这些事情叫什么呢?你可以认为是基于用户行为数据进行分析和统计,产出各种各样的数据统计分析报表和结果,供网站的用户、管理人员来查看。
这也有一个专业的名词,叫做“用户行为分析”。
二、推算一下你需要分析多少条数据?
好,咱么继续。如果你要对用户行为进行分析,那你是不是首先需要收集这些用户行为的数据?
比如说有个哥儿们现在点了一下“体育”板块,你需要在网页前端或者是APP上立马发送一条日志到后台,记录清楚“id为117的用户点击了一下id位003的板块”。
同样,这个东西也有一个专业的名词,叫做“用户行为日志”。
那你可以来计算一下,这些用户行为如果采用日志的方式收集,每天大概会产生多少条数据?
假设每天1000万人访问你的新闻网站,平均每个人做出30个点击、评论以及收藏等行为,那么就是3亿条用户行为日志。
假设每条用户行为日志的大小是100个字节,因为可能包含了很多很多的字段,比如他是在网页点击的,还是在手机APP上点击的,手机APP是用的什么操作系统,android还是IOS,类似这样的字段是很多的。
那么你就有每天大概28GB左右的数据,这里一共包含3亿条。
假如对这3亿条数据,你就自己写个Java程序,从一个超大的28GB的大日志文件里,一条一条读取日志来统计分析和计算,一直到把3亿条数据都计算完毕,你觉得会花费多少时间?
不可想象,根据你的计算逻辑复杂度来说,搞不好要花费几十个小时的时间。
所以你觉得这种大数据场景下的分析,这么玩儿靠谱么?不靠谱。
三、黄金搭档:分布式存储+分布式计算
所以这个时候,你就可以首先采用分布式存储的方式,把那3亿条数据分散存放在比如30台机器上,每台机器大概就放1000万条数据,大概就1GB的数据量。
大家看看下面的图:
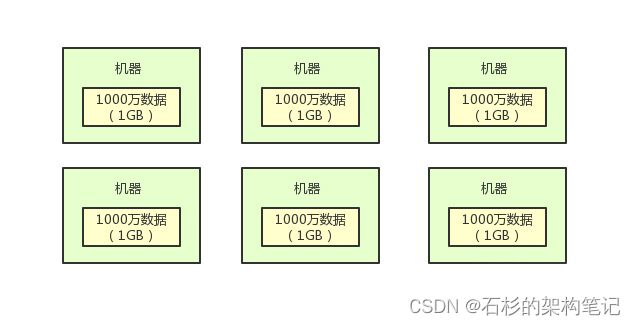
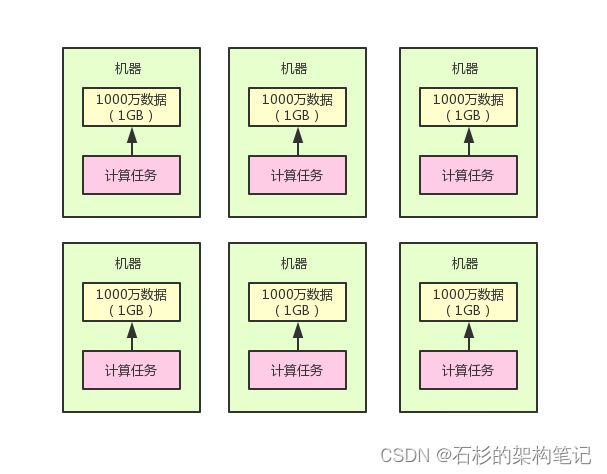
接着你就可以上分布式计算了,你可以把统计分析数据的计算任务,拆分成30个计算任务,每个计算任务都分发到一台机器上去运行。
也就是说,就专门针对机器本地的1GB数据,那1000万条数据进行分析和计算。
这样的好处就是可以依托30台机器的资源并行的进行数据的统计和分析,这也就是所谓的分布式计算了。
每台机器的计算结果出来之后,就可以进行综合性的汇总,然后就可以拿到最终的一个分析结果,大家看下图。
假设之前你的3亿条数据都在一个30GB的大文件里,然后你一个Java程序一条一条慢慢读慢慢计算,需要耗费30小时。
那么现在把计算任务并行到了30台机器上去,就可以提升30倍的计算速度,是不是就只需要1小时就可以完成计算了?
所以这个就是所谓的分布式计算,他一般是针对超大数据集,也就是现在很流行的大数据进行计算的。
首先需要将超大数据集拆分成很多数据块分散在多台机器上,然后把计算任务分发到各个机器上去,利用多台机器的CPU、内存等计算资源来进行计算。
这种分布式计算的方式,对于超大数据集的计算可以提升几十倍甚至几百倍的效率,其实这个理论和概念,也是大数据技术的基础。
比如现在最流行的大数据技术栈里,Hadoop HDFS就是用做分布式存储的,他可以把一个超大文件拆分为很多小的数据块放在很多机器上。
而像Spark就是分布式计算系统,他可以把计算任务分发到各个机器上,对各个数据块进行并行计算。
以上就是用大白话+画图,给小白同学们科普了一下分布式计算系统的相关知识,相信大家看了之后,对分布式计算系统,应该有一个初步的认识了。