python爬虫——实战篇
python爬虫——实战篇
2021.7.20晚已更新
注:注释和说明已在代码中注释
python爬虫实战篇
- 笔趣阁小说及其网址爬取
- 4k图片网站图片爬取
- 简历模板爬取
- 自动填体温小程序
- 待补充
笔趣阁小说及其网址爬取
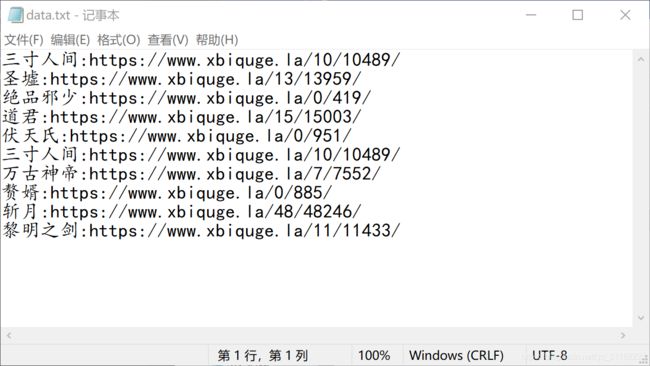
爬取结果:
txt文件,内容是 “小说名:网址”。
步骤:(几乎所有步骤都一样)
1.右键,查看,network(网络),找到headers:User-agent伪装头
2.点击这个红色同步点击框(最上面那个),然后点击一个小说标题元素
3.查看标签目录
4.编写爬虫程序
import requests
from lxml import etree
url = "https://www.xbiquge.la/"
headers = {'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67'}
def main():
html_text = requests.get(url = url, headers = headers).text
#解析
#先实例化一个etree对象
html_etree_object = etree.HTML(html_text)
passage_title_list1 = html_etree_object.xpath("//div/dl/dt/a[@href]")
passage_addre_list1 = html_etree_object.xpath("//dt/a/@href")
fp = open('data.txt','w',encoding='utf-8')
# print(passage_title_list1)
# print(passage_addre_list1)
# print(passage_title_list1[0].xpath('./text()'))
#局部解析并写入文件
for (ti,ad) in zip(passage_title_list1,passage_addre_list1):
#print(ti.xpath("./text()"),ad) ti.xpath("./text()")是局部解析,注意需要是./text(),特别注意点号“ . ”不能少!!
fp.write(ti.xpath("./text()")[0] + ":" + ad + '\n')
fp.close()
main()
结果:
4k图片网站图片爬取
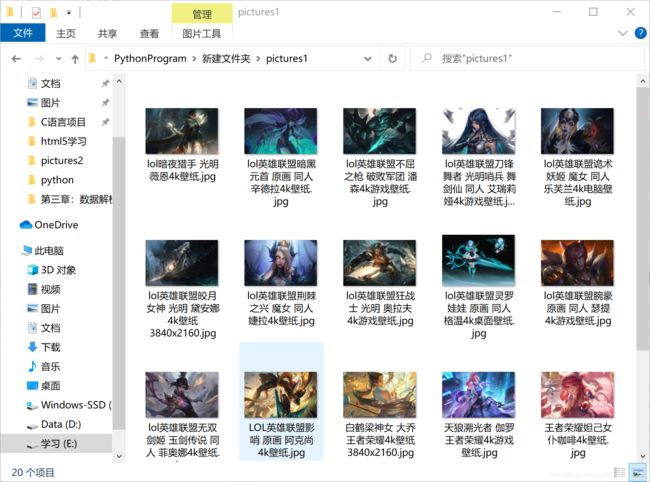
爬取结果:
图片存入文件夹
4k图片网站:https://pic.netbian.com/
import requests
from lxml import etree
import os
def get_picture():
try:
url = "https://pic.netbian.com/4kdongman/index_2.html"
headers = {'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
#抓取网页
html_pic = requests.get(url = url , headers = headers)
#查看状态码,若不是200返回异常
html_pic.raise_for_status()
#编码utf-8
html_pic.encoding = html_pic.apparent_encoding
#使用xpath数据解析
html_text = html_pic.text
etree_html = etree.HTML(html_text)
li_list = etree_html.xpath('//div[@class="slist"]/ul/li')
#创建文件夹
if not os.path.exists('./pictures1'):
os.mkdir('./pictures1')
#写入文件picture1
for li in li_list:
#局部解析出图片地址和名字
pic_add ="https://pic.netbian.com/" + li.xpath("./a/img/@src")[0]#注意xpath返回一个列表所以取下标[0],而且返回的地址不完全,所以在网址上打开看一下,把少的域名补上
pic_name = li.xpath("./a/img/@alt")[0] + '.jpg'
img_data = requests.get(url = pic_add,headers = headers).content
img_path = "pictures1/" + pic_name
with open(img_path,'ab') as fp:
fp.write(img_data)
print(pic_name,"保存成功!")
fp.close()
except:
return"产生异常"
def main():
get_picture()
main()
结果展示:
简历模板爬取
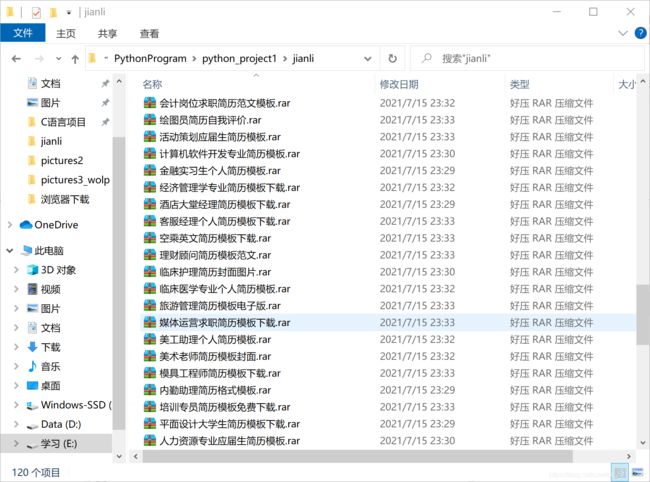
爬取结果:
简历模板的压缩包保存到文件夹中
简历模板网站:https://sc.chinaz.com/jianli/free.html
代码如下:(注释已注明)
import requests
from lxml import etree
import os
def main():
url = "https://sc.chinaz.com/jianli/free.html"
headers = {'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
down_data(url, headers)
url_set = set()
#把每一页的url放到一个容器里(有待完善,不能爬取足够多的网址,比如789页)
url_set = get_url(url,headers,url_set)
for urll in url_set:
down_data(urll,headers)
def get_url(url,headers,url_set):#此函数有待完善,缺点是只能爬取第一页的几个分页链接
#其实这个也应该使用try-except
html_text = requests.get(url = url ,headers = headers ).text
html_tree = etree.HTML(html_text)
lable_list = html_tree.xpath('//div[@class="pagination fr clearfix clear"]/a')
for lable_ in lable_list[2:7]:
lable_url = "https://sc.chinaz.com/jianli/" + lable_.xpath("./@href")[0]
url_set.add(lable_url)
return url_set
def down_data(url,headers):
try:
html_ = requests.get(url = url,headers = headers)
#print("状态码",html_.status_code)
html_.raise_for_status()
html_.encoding = html_.apparent_encoding
#页面解析
html_text = html_.text
html_tree = etree.HTML(html_text)
#局部解析
#下载地址列表
loadadd_lable_list = html_tree.xpath('//div[@id="container"]/div/a')
loadadd_list = []
for lable in loadadd_lable_list:
loadadd_list.append(lable.xpath('./@href'))
#再解析+下载
if not os.path.exists('./jianli'):
os.mkdir('./jianli')
for loadadd in loadadd_list :
url = "https:" + loadadd[0]
#解析单个简历的页面
html_2 = requests.get(url = url,headers = headers)
html_2.encoding = html_2.apparent_encoding
etree_html = etree.HTML(html_2.text)
loadfilename = etree_html.xpath("//div[@class='ppt_tit clearfix']/h1/text()")
loadpath = "jianli/" + loadfilename[0] + ".rar"
data_address = etree_html.xpath('//div[@class="down_wrap"]//li[1]/a/@href')[0]
jianli_data = requests.get(url = data_address,headers = headers).content
with open(loadpath,"ab") as fp:
fp.write(jianli_data)
print(loadfilename[0],"保存成功!")
fp.close()
except:
print("产生异常")
main()
结果展示:
自动填体温小程序
大家可以仿照这个案例去写一个类似的程序(仅供学习使用!!)
我想能不能使用爬虫实现自动补填体温(仅供学习!!!)
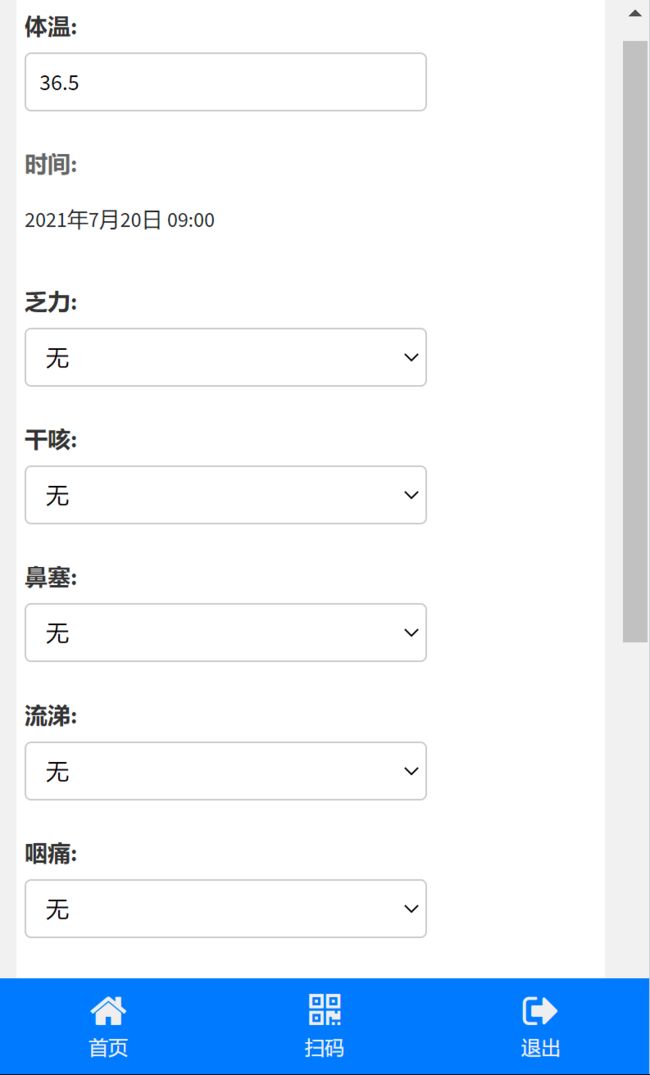
填完之后点击保存。这个是基本需求。
进入正题:
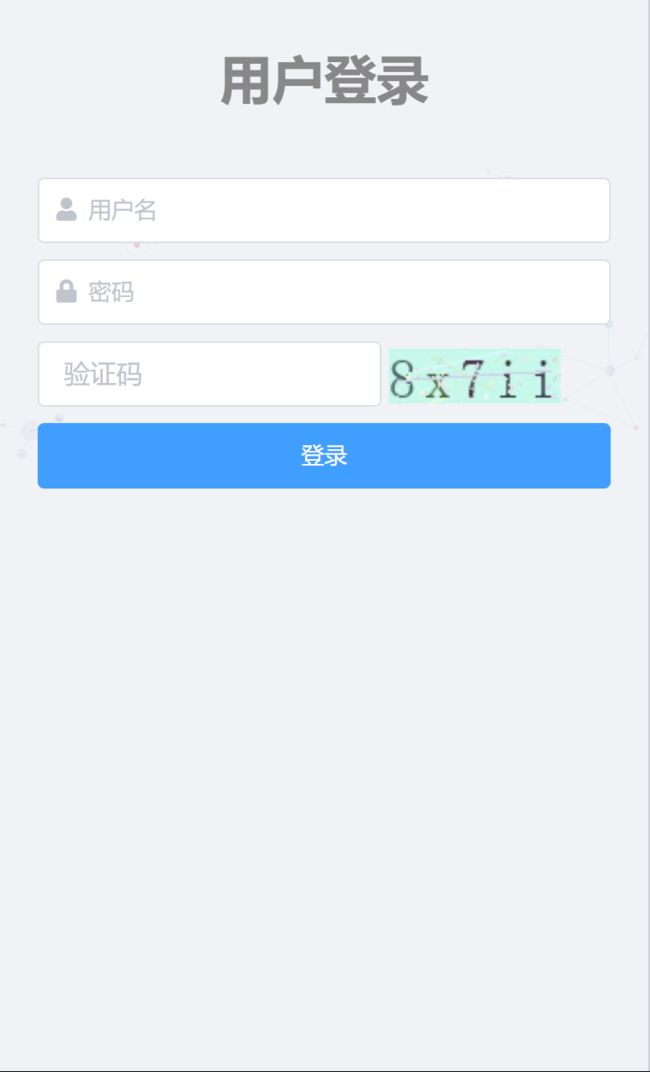
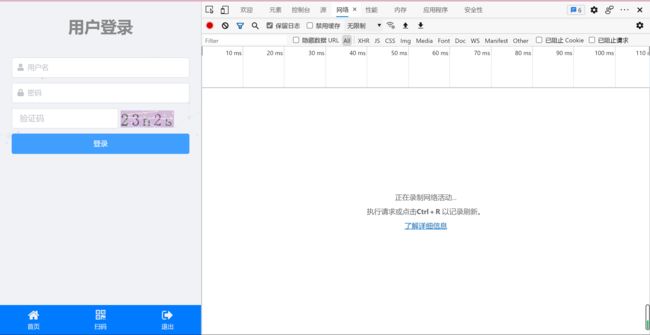
在这个界面打开抓包工具(右键检查),切到network,点击登录(提交请求),在network给的一系列包中国找到状态为post的,最下面会有data,这个就是我们需要调用request库post的data,包括账号,密码,验证码,然后就会实现登录,注意需要使用session(会自动保存cookie,这样下次再request 去post体温情况的时候才能是你登录的账号的操作,否则就仍是登录页面),然后提交体温的时候也是类似的操作,点击提交体温按钮发起请求,再network中寻找状态为post的包,看看data的格式,然后使用刚才已经自动保存了cookie的session对象post体温(data)
还有就是,对于验证码我使用的是超级鹰打码平台。
上代码:(由于有的部分涉及到了隐私,所以此代码不可以直接运行!仅供学习参考!!)
import requests
from lxml import etree
from chaojiying.chaojiying import Chaojiying_Client
class tmp_input():
def __init__(self,username,userpaw):
self.username = username
self.userpaw = userpaw
def tmp_in(self):
#获取验证码图片
url = "登录网址"
headers = {
'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36',
'Referer':'登录网址',
'Cookie':''
}
response = requests.get(url = url,headers = headers)
#print(response.status_code)
tree = etree.HTML(response.text)
yzm_pic_address = tree.xpath('验证码图片url的xpath表达式')[0]
#print(yzm_pic_address)
yzm_pic = requests.get(url = yzm_pic_address,headers = headers).content
with open("./yzm_pic.jpg",'wb') as fp:
fp.write(yzm_pic)
fp.close()
#识别验证码
chaojiying_idf = Chaojiying_Client('', '', '') # 这一行调用超级鹰,有三个参数,大家可以去了解一下超级鹰的使用
image = open('yzm_pic.jpg', 'rb').read()
yzm = chaojiying_idf.PostPic(image, 1005)['pic_str'] # 返回验证码识别后的内容
print('验证码识别结果:',yzm)
#登录请求
session = requests.Session()
login_url = '登录网址'
csrf = tree.xpath('csrf的xpath表达式')[0]
data = {
'csrfmiddlewaretoken': csrf,
'username': self.username,
'password': self.userpaw,
'check_code': str(yzm),
'next': '/'
}
menu_response = session.post(url = login_url,headers = headers,data = data)
#上午体温补填
tmpam_url = '填体温页面地址'
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36',
'Referer': '填体温页面使用抓包工具查找到的referer地址(发起请求的前一个页面地址)',
}
responseam = session.get(url = tmpam_url,headers = headers)
amtree = etree.HTML(responseam.text)
amcsrf = amtree.xpath('上午体温补填页面csrf的xpath表达式')[0]
amdata = {
'csrfmiddlewaretoken': amcsrf,
'tw':'36.5',
'fl': 'False',
'gk': 'False',
'hx': 'False',
'qt': 'False',
'jc': 'False',
'fx': 'False',
'jqjc':'',
'lc':'',
'actionName': 'actionValue'
}
session.post(url = tmpam_url,headers = headers,data = amdata)
#下午体温补填
tmppm_url = '下午填体温页面地址'
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36',
'Referer': '同上所讲(可能没说清,可以去百度)',
}
responsepm = session.get(url=tmppm_url, headers=headers)
pmtree = etree.HTML(responsepm.text)
pmcsrf = pmtree.xpath('下午体温补填页面csrf的xpath表达式')[0]
pmdata = {
'csrfmiddlewaretoken': pmcsrf,
'tw': '36.4',
'fl': 'False',
'gk': 'False',
'hx': 'False',
'qt': 'False',
'jc': 'False',
'fx': 'False',
'jqjc': '',
'lc': '',
'actionName': 'actionValue'
}
session.post(url=tmppm_url, headers=headers, data=pmdata)
person1_tmpinput = tmp_input(username="我女朋友的账号",userpaw="我女朋友的密码")#如果没有女朋友就可以把这一行和下一行删掉
person1_tmpinput.tmp_in()
person1_tmpinput = tmp_input(username="我的账号",userpaw="我的密码")
person1_tmpinput.tmp_in()