InnoDB学习笔记一引擎架构及特性
文章目录
-
- 一、InnoDB引擎架构
-
- 1.1 InnoDB架构图
- 1.2 InnoDB的一个多线程模型
- 1.2.1 Master Thread - 核心线程
-
- 1.0.x版本之前的Master Thread
-
- 主loop线程
- backgroud线程
- flush loop线程
- suspend loop线程
- 1.2.x版本之前Master Thread
- 1.2.x版本的Master Thread
- 1.2.2 IO Thread
- 1.2.3 Purge Thread
- 1.2.4 Page Cleaner Thread
- 1.3 基础知识补充
- 二、InnoDB的特性
-
- 2.1 Insert Buffer - 插入缓冲
-
- 为啥非唯一约束
- 插入缓冲占用内存过多
- 插入缓存的内部实现
- 2.2 Double Write - 两次写
-
- double write空间构成
- 崩溃恢复
- 2.3 自适应哈希索引
-
- 建立要求
- 限制
- 2.4 AIO - 异步IO
- 2.5 刷新临近页
- 2.6 预读 read ahad
-
- 数据库读操作流程
- 预读机制
数据库是数据的集合,数据库管理系统(DBMS)是操作和管理数据库的应用程序。数据库应用主要有两类:OLAP(联机分析处理)和OLTP(联机事务处理)。
OLAP的主要特点是:
- 实时性要求不高
- 数据量大
- 并发量小
OLTP的主要特点是:
- 实时性要求高
- 数据量小
- 高并发
- 要求满足ACID
mysql是一种OLTP类型的DBMS或者说OLTP是传统的关系型数据库的主要应用,其体系架构如下图所示:
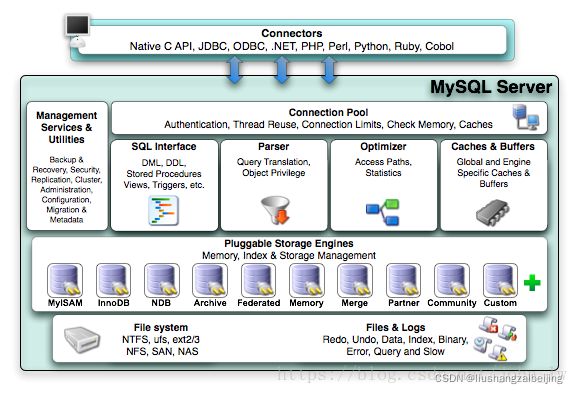
mysql中集成的是插件式的存储引擎,InnoDB引擎是其中之一。存储引擎基于表而不是数据库:同一个数据库中根据不同表的访问操作需求可以选择不同的存储引擎。
一、InnoDB引擎架构
InnoDB引擎主要面对OLTP类应用。
InnoDB引擎在mysql中处于文件和文件系统的上层,管理着对InnoDB引擎表的访问和更新。
1.1 InnoDB架构图
InnoDB完整架构图
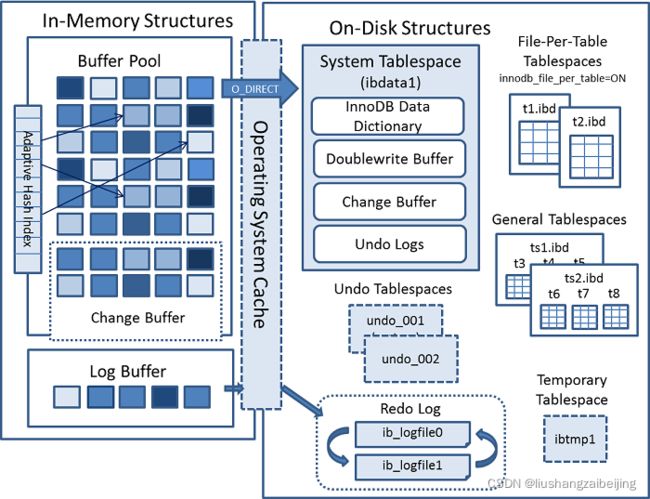
图片来源与官网:
https://dev.mysql.com/doc/refman/5.7/en/innodb-architecture.html
1.2 InnoDB的一个多线程模型
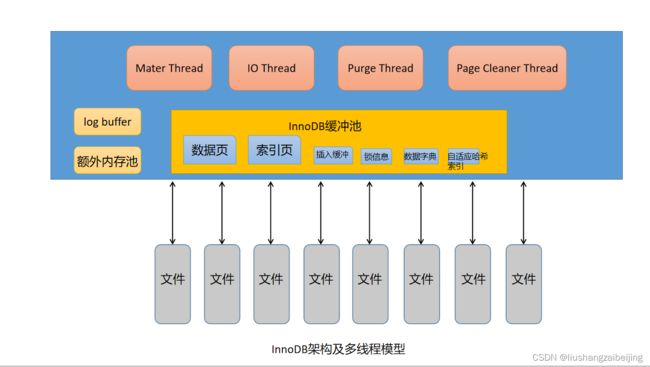
1.2.1 Master Thread - 核心线程
Master Thread是InnoDB存储引擎非常核心的一个后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新、合并插入缓冲、UNDO页的回收等。
1.0.x版本之前的Master Thread
Master Thread具有最高的线程优先级别。内部由多个循环组成:主循环(loop)、后台循环(backgroup loop)、刷新循环(flush loop)、暂停循环(suspend loop)。Master Thread会根据数据库运行的状态在loop、backgroup loop、flush loop和suspend loop中进行切换。
主loop线程
loop是主循环,大多数的操作都在这个循环中,主要有两大部分的操作——每秒钟的操作和每10秒钟的操作。伪代码如下:
void master_thread()
{
loop:
for(int i = 0; i < 10; ++i){
do thing once per second;
sleep 1 second if necessary;
}
do things once per ten seconds;
goto loop;
}
每秒一次的操作包括:
-
日志缓冲刷新到磁盘,即使这个事务还没有提交(总是);
即使某个事务还没有提交,InnoDB存储引擎仍然每秒会将reDo日志缓冲中的内容刷新到重做日志文件。这也解释了为什么再大的事务提交的时间也是很短的。
-
合并插入缓冲(可能);
合并插入缓冲并不是每秒都会发生的。InnoDB存储引擎会判断当前一秒内发生的IO次数是否小于5次,如果小于5次,InnoDB存储引擎认为当前的IO压力很小,可以执行合并插入缓冲的操作;
什么叫做合并插入缓冲:对于非聚集索引每次插入会随机访问页,写入性能低,这里可以采取将多个插入操作合并到一个io中,增加写的性能
-
至多刷新100个InnoDB的缓冲池中的脏页到磁盘(可能);
刷新100个脏页也不是每秒都会发生的,InnoDB存储引擎通过判断当前缓冲池中脏页的比例(buf_get_modified_ratio_pct)是否超过了配置文件中
innodb_max_dirty_pages_pct这个参数(默认是75,代表75%),如果超过了这个值,InnoDB存储引擎则认为需要做磁盘同步的操作,将100个脏页写入磁盘中。 -
如果当前没有用户活动,则切换到background loop(可能);
每10秒的操作主要是下面几个方面:
-
刷新100个脏页到磁盘(可能)
InnoDB存储引擎会先判断过去10秒之内磁盘的IO操作是否小于200次,如果是,InnoDB存储引擎认为当前有足够的磁盘IO能力,因此将100个脏页刷新到磁盘。 -
合并至多5个插入缓冲(总是)
-
将日志缓冲刷新到磁盘(总是)
-
删除无用的Undo页(总是)
-
刷新100个或者10个脏页到磁盘(总是)
InnoDB存储引擎会执行full purge操作,即删除无用的Undo页。对表进行update,delete这类的操作时,原先的行被标记为删除,但是因为一致性读的关系,需要保留这些行版本的信息。但是在full purge过程中,InnoDB存储引擎会判断当前事务系统中已被删除的行是否可以删除,比如有时候可能还有查询操作需要读取之前版本的undo信息,如果可以删除,InnoDB存储引擎会立即将其删除。从源代码中可以看出,InnoDB存储引擎在执行full purge 操作时,每次最多尝试回收20个undo页。然后,InnoDB存储引擎会判断缓冲池中脏页的比例(buf_get_modified_ratio_pct),如果有超过70%的脏页,则刷新100个脏页到磁盘,如果脏页的比例小于70%,则只需刷新10%的脏页到磁盘。
backgroud线程
如果当前没有用户活动(数据库空闲)或者数据库关系,就会切换到backgroud loop这个循环。
backgroud loop会执行以下操作:
- 删除无用的Undo页(总是)
- 合并20个插入缓冲(总是)
- 跳回到主循环(总是)
- 不断刷新100个页直到符合条件(可能,需要跳转到flush loop中完成)
flush loop线程
-
刷新脏页到磁盘(总是)
-
如果缓冲池中的脏页比例大于innodb_max_dirty_pages_pct的值(默认75%)继续刷新脏页
否则跳转到suspend loop中。
suspend loop线程
Master Thread挂起,等待事件的发生。
若用户启用了InnoDB存储引擎,却没有使用任何InnoDB存储引擎的表,那么Master Thread总是处于挂起的状态。
最后,Master Thread完整的伪代码如下:
void master_thread()
{
loop:
//每一秒的操作
for(int i = 0; i < 10; ++i){
thread_sleep(1);
//刷新日志到磁盘
do log buffer flush to disk;
//合并插入缓冲
if(last_one_second_ios < 5)
do merge at most 5 insert buffer;
//至多刷新100个InnoDB的缓冲池中的脏页到磁盘(可能)
if(buf_get_modified_ratio_pct > innodb_max_dirty_pages_pct)
do buffer pool flush 100 dirty page;
//无用户活动 跳转到backgroup 循环中
if(no user activity)
goto backgroud loop;
}
//每10秒的操作
//如果上一次10秒内 io次数小于200
//则刷新100个脏页到磁盘
if(last_ten_second_ios < 200)
do buffer pool flush 100 dirty page;
//并至多5个插入缓冲
do merge at most 5 insert buffer;
//将日志缓冲刷新到磁盘
do log buffer flush to disk;
//删除无用的Undo页
do full purge;
//缓冲池中的脏页如果超过70% 则刷新100个脏页到磁盘
if(buf_get_modified_ratio_pct > 70%)
do buffer pool flush 100 dirty page;
else
//否则刷新10个脏页到磁盘
buffer pool flush 10 dirty page;
// 后台循环
backgroud loop:
// 删除无用的undo页
do full purge
//合并插入缓冲是innodb_io_capacity的5%(10)(总是)
do merge 20 insert buffer;
// 如果不空闲,就跳回主循环,如果空闲就跳入flush loop
if not idle
goto loop:
else
goto flush loop
// 刷新循环
flush loop:
do buffer pool flush 100 dirty page;
if(buf_get_modified_ratio_pct > innodb_max_dirty_pages_pct)
// 如果缓冲池中的脏页比例大于innodb_max_dirty_pages_pct的值(默认75%)
// 跳到刷新循环,不断刷新脏页,直到符合条件
goto flush loop;
// 完成刷新脏页的任务后,跳入suspend loop
goto suspend loop;
suspend loop:
//master线程挂起,等待事件发生
suspend_thread();
waiting event;
goto loop;
}
1.2.x版本之前Master Thread
-
使用innodb_io_capacity来动态调整InnoDB引擎的刷新脏页数量和合并插入缓存数量
(1)在合并插入缓冲时,合并插入缓冲的数量为innodb_io_capacity值的5%;
(2)在从缓冲区刷新脏页时,刷新脏页的数量为innodb_io_capacity;
mysql> show variables like 'innodb_io_capacity';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| innodb_io_capacity | 200 |
+--------------------+-------+
1 row in set (0.00 sec)
如果用户使用的是SSD类的磁盘,可以将innodb_io_capacity的值调高,直到符合磁盘IO的吞吐量为止;
- innodb_max_dirty_pages_pct的默认值由原来的90改为了75。这样既可以加快刷新脏页的频率,又能够保证磁盘IO的负载。
mysql> show variables like 'innodb_max_dirty_pages_pct';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_max_dirty_pages_pct | 75 |
+----------------------------+-------+
1 row in set (0.00 sec)
-
新增一个参数innodb_adaptive_flushing(自适应地刷新),该值影响每秒刷新脏页的数量。
原来写死参数,现在由buf_flush_get_desired_flush_rate函数通过判断产生重做日志的速率来决定最合适的刷新脏页数量。
-
innodb_purge_batch_size,该参数可以控制每次full purge回收的Undo页的数量。
该参数的默认值为20,并可以动态地对其进行修改。
mysql> show variables like 'innodb_purge_batch_size';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| innodb_purge_batch_size | 20 |
+-------------------------+-------+
1 row in set (0.00 sec)
- 查看innodb引擎的线程状态
mysql> show engine innodb status\G
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
170312 20:14:04 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 38 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 1 1_second, 1 sleeps, 0 10_second, 1 background, 1 flush
srv_master_thread log flush and writes: 1
1.2.x版本的Master Thread
1.2.x版本中再次对Master Thread进行了优化。
Master Thread的伪代码如下:
if InnoDB is idle
srv_master_do_idle_tasks();
else
srv_master_do_active_tasks();
-
srv_master_do_idle_tasks()就是之前版本中每10秒的操作,srv_master_do_active_tasks()处理的是之前每秒中的操作。
-
对于刷新脏页的操作,从Master Thread线程分离到一个单独的Page Cleaner Thread,从而减轻了Master Thread的工作,同时进一步提高了系统的并发性。
1.2.2 IO Thread
InnoDB中大量使用AIO (Async IO) 来处理IO请求。
IO Thread的作用,是负责这些 IO 请求的回调(call back)
可使用 show engine innodb status看到以下类型
- insert buffer thread
- log thread
- read thread(4个)
- write thread(4个)
1.2.3 Purge Thread
作用
事务被提交后,其所使用的undo log可能不在需要。因此,需要purge thread来回收已经使用并分配的undo页。
来历
以前Master Thread来完成释放undo log,InnoDB1.1独立出来,分担主线程压力
查看purge thread的数量
mysql> show variables like 'innodb_purge_threads';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| innodb_purge_threads | 4 |
+----------------------+-------+
1 row in set (0.02 sec)
1.2.4 Page Cleaner Thread
** 作用**
脏页刷新到磁盘
来历
以前Master Thread来刷新脏页,InnoDB1.2独立出来,分担主线程压力
1.3 基础知识补充
-
redo log: redo log叫做重做日志,记录InnoDB的更改后的值,用来恢复数据。
-
undo log:undo log(撤销日志) 记录了数据修改之前的历史值,通过 undo log 回溯到可见的历史版本,用于事务回滚。
-
bin log:binlog,记录InnoDB、MYISAM等所有存储引擎的修改记录。在事务之前提交,用于从库三方同步数据使用。存储为具体的数据内容或者完整的sql。
-
脏页:innodb为了读写的高效性,读写操作先从其服务的缓存区或缓存池读写数据,写操作导致在内存中数据和磁盘上的数据不一致,则内存上的修改数据的页被称为脏页。
二、InnoDB的特性
2.1 Insert Buffer - 插入缓冲
插入缓冲是为了提高插入数据效率的,往非聚簇索引中插入数据时,首先会看缓冲池中,是否有要插入的非聚簇索引页。如果有则直接插入,那个页变成脏页。如果没有,就把多次插入的数据先缓冲到插入缓冲中,然后合并多次操作,即把非聚集索引在一起的数据合并为一次IO(减少IO),再以一定的频率刷新到磁盘(将Insert Buffer和辅助索引页字节点进行merge操作),但是插入缓冲只是针对非聚集索引且没有唯一约束的索引的插入有效。
为啥非唯一约束
如果该非聚集索引有唯一约束,那么为了保证唯一性,必须每次插入前都去查询是否存在相同的数据,这时就必须到磁盘到处找是否存在该值(也称为离散读),这就导致插入缓冲失效了。
插入缓冲是为了解决非聚集索引随机写导致的效率低的问题,但是对于有唯一约束的非聚集索引也无能为力。
插入缓冲占用内存过多
在写密集的情况下,插入缓冲会占用过多的缓冲池内存,默认最大可以占用1/2的缓冲池内存,修正这个问题可以修改默认值对插入缓冲的大小进行控制。
插入缓存的内部实现
insert buffer内部是一颗B+树,mysql4.1之前是每张表有一颗insert buffer B+树,而现在的版本是全局只有一颗B+树,负责对所有的表的辅助索引进行insert buffer, 这颗B+树存放在共享表空间中即ibdata1中。
2.2 Double Write - 两次写
当innodb存储引擎正在写入某个页到表中,而这个页只写了一部分就发生了宕机,称为部分写失效,会导致数据丢失,可以通过重做日志恢复,可是重做日志中记录的是对页的物理操作,如偏移量80,写‘ddd’操作。如果这个页本身已经损坏,则重做也没意义,因此,可以在应用重做之前,用户需要一个页的副本,当发生写失效时,通过副本还原该页,再进行重做,这就是doublewrite。
两次写带给innodb存储引擎的是数据页的可靠性。
Double write 要解决数据库 flush 脏页的时候,系统可能宕机,这个时候数据库的一个脏页可能只刷了一部分。
而 InnoDB 的 redo log 没有记录整个 page 的内容。因为如果每次修改都记录整个 page,那日志就太大了。
也就是说, old_page + redo_log => new_page,如果 old_page 的内容被写坏了,数据就没法恢复了。
Double write 的做法就是先将 old_page + redo_log 得到的 new_page 先持久化到磁盘上的“另一个地方”。然后再进行 inplace update,如果中途发生宕机,可以从“另一个地方”恢复这个 page 的数据。
double write空间构成
1. 内存的doublewrite buffer,大小为2MB(128页)
2. 磁盘上共享空间doublewrite buffer,大小2MB(128页),其中120个用于批量刷脏数据,另外8个用于Single Page Flush。
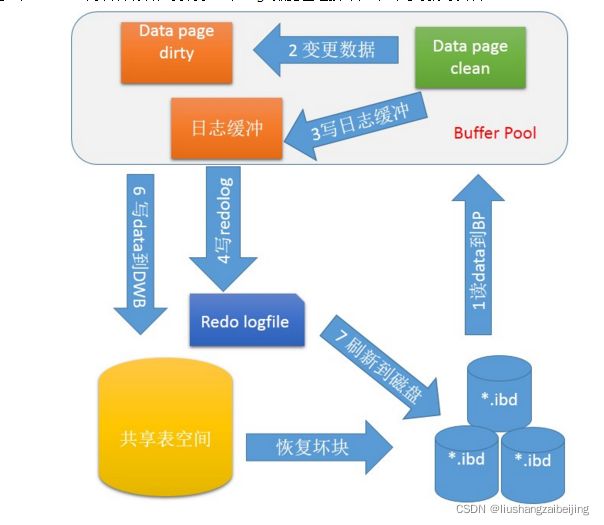
- 当一系列机制触发数据缓冲池中的脏页刷新时,并不直接写入磁盘数据文件中,而是先拷贝至内存中的doublewrite buffer中;
- 接着从内存 doublewrite buffer分两次写入磁盘共享表空间的doublewrite buffer中(连续存储,顺序写,性能很高),每次写1MB;
- 待第二步完成后,再将磁盘中doublewrite buffer中的脏页数据写入实际的各个表空间文件(离散写);(脏页数据固化后,即进行标记对应doublewrite数据可覆盖)。
崩溃恢复
如果操作系统在将页写入磁盘的过程中发生崩溃,在恢复过程中,innodb存储引擎可以从共享表空间的doublewrite中找到该页的一个最近的副本,将其复制到表空间文件,再应用redo log,就完成了恢复过程。
2.3 自适应哈希索引
自适应哈希索引(Adaptive Hash Index )** :innodb存储引擎会监控对表上的各索引页的查询,如果观察到建立哈希索引可以带来速度提升,则建立哈希索引,称之为自适应哈希索引(Adaptive hash index,AHI).AHI是通过缓冲池的B+树构造而来,因此建立速度很快,innodb会自动根据访问的频率和模式自动的为某些热点页建立哈希索引。
建立要求
- 对于这个页的连续访问模式必须是一样的,即指查询条件一样(对于多列索引来说,where a =1 和 where a = 1 and b =2时不同的访问模式)
- 以该模式访问了100次
- 页通过该模式访问了N次,其中N=页中记录*1/16
限制
哈希索引只能用来搜索等值的查询,如select * from table where index_col=“xxx”;而对于其他查找类型,如范围查找不能使用哈希索引,通过参数innodb_adptive_hash_index来禁止或者开启此特性,默认AHI为开启状态。
2.4 AIO - 异步IO
目的
为了提高磁盘操作性能,使用异步io(asynchronous io,AIO)的方式来处理磁盘操作。
用户可以在发出一个IO请求后立即再发出另一个IO请求,当全部IO请求发送完毕后,等待所有的io操作完成,称为AIO,AIO还可以进行io merge操作,也就是将多个io合并为一个io.这样可以提高IPOS性能。
例如,用户查询的页为
(3,5)(3,6)(3,7)
每个页的大小为16KB,那么,Sync IO需要三次IO 操作。而AIO会判断这三个页是连续的,(通过space,offset就可以看出来)因此,AIO会发出一个IO请求,从(3,5)开始,读取48KB的页
应用场景
- 预读(read ahead)
- 脏页的刷新
2.5 刷新临近页
工作原理
当刷新一个脏页时,innodb会检测该页所在区的所有页,如果是脏页,那么一起刷新。
好处
通过AIO,将多个IO写入操作合并到一个IO操作中,对于机械硬盘来说,性能提升很明显。固态硬盘建议关闭。
参数控制
参数innodb_flush_neighbors来开启或关闭该特性,为0则关闭。
2.6 预读 read ahad
数据库读操作流程
数据库请求数据的时候,会将读请求交给文件系统,放入请求队列中;相关进程从请求队列中将读请求取出,根据需求到相关数据区(内存、磁盘)读取数据;取出的数据,放入响应队列中,最后数据库就会从响应队列中将数据取走,完成一次数据读操作过程。
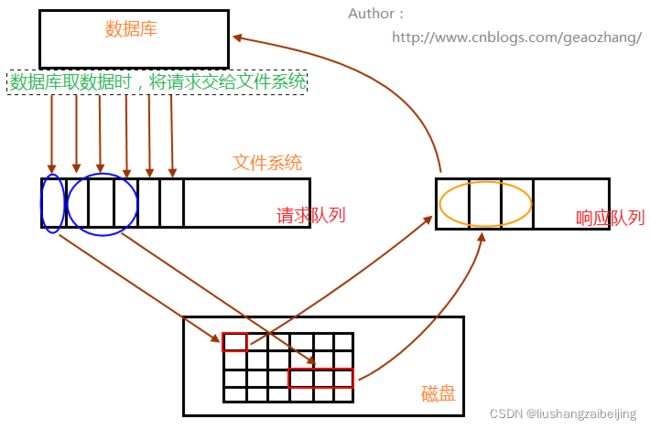
预读机制
InnoDB在I/O优化上提供了预读机制,预读机制是发起一个IO请求,异步的从磁盘预先读取多个页数据(不仅仅只读取IO请求对应的页数据)
InnoDB使用两种预读算法来提高I/O性能:线性预读(linear read-ahead)和随机预读(randomread-ahead)
**1.线性预读方式: **通过innodb_read_ahead_threshold控制是否将下一个区(extent)的数据预先读取到缓冲池(buffer pool)中。
**2.随机预读方式:**表示当同一个区段(extent)中的一些页(page)在缓冲池(buffer pool)中发现时,Innodb会将该区段中的剩余页一并读到缓冲池中。