论文阅读和分析:A Tree-Structured Decoder for Image-to-Markup Generation
HMER论文系列
1、论文阅读和分析:When Counting Meets HMER Counting-Aware Network for HMER_KPer_Yang的博客-CSDN博客
2、论文阅读和分析:Syntax-Aware Network for Handwritten Mathematical Expression Recognition_KPer_Yang的博客-CSDN博客
3、论文阅读和分析:A Tree-Structured Decoder for Image-to-Markup Generation_KPer_Yang的博客-CSDN博客
4、 论文阅读和分析:Watch, attend and parse An end-to-end neural network based approach to HMER_KPer_Yang的博客-CSDN博客
5、 论文阅读和分析:Multi-Scale Attention with Dense Encoder for Handwritten Mathematical Expression Recognition_KPer_Yang的博客-CSDN博客
6、 论文阅读和分析:Mathematical formula recognition using graph grammar_KPer_Yang的博客-CSDN博客
7、 论文阅读和分析:Hybrid Mathematical Symbol Recognition using Support Vector Machines_KPer_Yang的博客-CSDN博客
8、论文阅读和分析:HMM-BASED HANDWRITTEN SYMBOL RECOGNITION USING ON-LINE AND OFF-LINE FEATURES_KPer_Yang的博客-CSDN博客
目录
-
-
- 1.主要内容:
- 2.树解码器
- 3、损失函数
- 4、结论:
- 参考:
-
1.主要内容:
(1、提出创新的树结构解码器来表示树、输出树、优化基于注意力的编解码框架;
(2、设计一个问题说明特别是在复杂结构时字符解码失败的背后原因,图示解释为什么树结构在解码过程中使得更优的解码能力;
(3、证明在化学式识别和数学公式识别上,树解码器的有效性;
2.树解码器
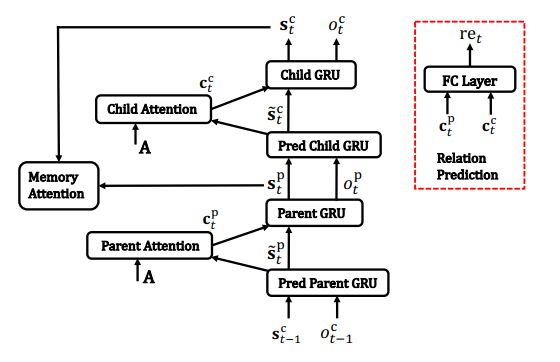
Figure 5. Illustration of tree decoder, including parent decoder part, child decoder part, memory attention part and an optional relation prediction part. “Pred” is short for “prediction”
树解码器使用GRU和注意力机制生成一系列的子树结构:
( o 1 c , o 1 p ) , ( o 2 c , o 2 p ) , … , ( o T c , o T p ) . (o_{1}^{\mathrm{c}},o_{1}^{\mathrm{p}}),(o_{2}^{\mathrm{c}},o_{2}^{\mathrm{p}}),\ldots,(o_{T}^{\mathrm{c}},o_{T}^{\mathrm{p}}). (o1c,o1p),(o2c,o2p),…,(oTc,oTp).
需要添加一些规则,限制:
(1、每个孩子节点必须有一个父节点,因此不存在孤立节点;
(2、父节点必须是一个现存的节点;
2.1、parent解码器
当前父亲节点的隐藏层状态 s ~ t p \tilde{\mathbf{s}}_t^{\mathbf{p}} s~tp:
s ~ t p = G R U ( o t − 1 c , s t − 1 c ) \tilde{\mathbf{s}}_t^{p}=GRU(o_{t-1}^{c},\mathbf{s}_{t-1}^{c}) s~tp=GRU(ot−1c,st−1c)
o t − 1 c o_{t-1}^c ot−1c:前面孩子节点;
s t − 1 c \mathbf{s}_{t-1}^c st−1c:前面孩子节点的隐藏层;
计算注意力部分:
α t p = f a t t p ( A , s ~ t p ) c t p = ∑ i α t i p a i \begin{array}{c}\alpha_t^p=f_{\mathrm{att}}^p(\mathbf{A},\tilde{\mathbf{s}}_t^\mathrm{p})\\ \mathbf{c}_t^p=\sum_i\alpha_{ti}^p\mathbf{a}_i\end{array} αtp=fattp(A,s~tp)ctp=∑iαtipai
A A A:编码器(DenseNet)生成的特征图 A = { a i } . \mathbf{A}=\{\mathbf{a}_i\}. A={ai}.
α t P \alpha_t^P αtP:父亲注意力概率;
c t P c_t^P ctP:父亲上下文向量;
f a t t P f_{att}^P fattP:注意力函数:
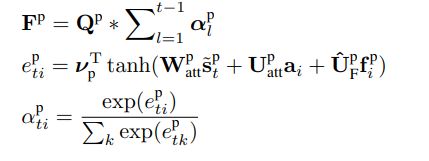
α t i P \alpha_{ti}^P αtiP:在 t t t步解码的 i − t h i-th i−th元素的父亲节点注意力概率;
∗ * ∗:卷积层;
∑ l = 1 t − 1 α l p \sum_{l=1}^{t-1}\alpha_l^p ∑l=1t−1αlp:过去父亲注意力概率和;
e t i P e_{ti}^P etiP:输出energy;
f i P \mathbf{f}_i^P fiP: F P \mathbf{F}^P FP的元素,可以帮助添加历史信息到标准注意力机制;
使用父亲上下文向量 c t P \mathbf{c}_t^P ctP,计算父亲解码器:
s t p = G R U ( c p , s ~ t ) \mathbf{s}^{p}_t=GRU(\mathbf{c}^{p},\tilde{\mathbf{s}}_t) stp=GRU(cp,s~t)
类似于父解码器,还有孩子解码器、记忆注意力、关系预测;
2.2、child解码器
计算子节点隐状态:
s ~ t c = G R U ( o t − 1 p , S t − 1 p ) \tilde{\mathbf{s}}_t^{c}=GRU(o_{t-1}^{p},\mathbf{S}_{t-1}^{p}) s~tc=GRU(ot−1p,St−1p)
使用和父亲相同的注意力机制计算孩子注意力概率和上下文向量:
α t c = f a t t c ( A , s ~ t c ) \boldsymbol{\alpha}_t^c=f_{\mathrm{att}}^c(\mathbf{A},\tilde{\mathbf{s}}_t^c) αtc=fattc(A,s~tc)
c t c = ∑ i α t i c a i \mathbf{c}_t^{\mathsf{c}}=\sum_i\alpha_{ti}^{\mathsf{c}}\mathbf{a}_i ctc=i∑αticai
计算孩子节点隐藏状态:
s t c = G R U ( c t c , s ~ t c ) \mathbf{s}_t^c = G RU(\mathbf{c}_t^c,\tilde{\mathbf{s}}_t^c) stc=GRU(ctc,s~tc)
预测孩子节点概率:
p ( o t c ) = s o f t m a x ( W o u t c ( o t p , s t c , c t c ) ) p(o_t^c)=\mathrm{softmax}\left(\mathbf{W}_{\mathrm{out}}^c(o_t^p,\mathbf{s}_t^c,\mathbf{c}_t^c)\right) p(otc)=softmax(Woutc(otp,stc,ctc))
计算分类损失函数:
L c = − ∑ t log p ( w t c ) \mathcal{L}_{\mathrm{c}}=-\sum_t\log p(w_t^{\mathrm{c}}) Lc=−t∑logp(wtc)
w t c w_t^c wtc:在时间步 t t t,孩子节点的ground-truth
2.3、基于记忆的注意力
生成中间父亲节点序列和为训练父亲解码器的目标函数
d t j m e m = tanh ( W m e m s t p + U m e m b e r s s j m e m ) \mathbf{d}_{tj}^{\mathrm{m}em}=\tanh(\mathbf{W}_{\mathrm{mem}}\mathbf{s}_t^{\mathrm{p}}+\mathbf{U}_{\mathrm{members}}\mathbf{s}_{j}^{\mathrm{mem}}) dtjmem=tanh(Wmemstp+Umemberssjmem)
G t j m e m = σ ( ν m e m T d t j m e m ) G^{\mathrm{m}em}_{tj}=\sigma(\mathbf{\nu}^{\mathrm{T}}_{\mathrm{mem}}\mathbf{d}^{\mathrm{mem}}_{tj}) Gtjmem=σ(νmemTdtjmem)
s t p \mathbf{s}_t^p stp:父亲解码器状态;
s j m e m \mathbf{s}_j^{mem} sjmem:孩子解码器状态 s t c \mathbf{s}_t^c stc存储,作为key;
父亲节点二分类训练损失:
L p = − ∑ t ∑ j [ G ˉ t j m e m log ( G t j m e m ) + ( 1 − G ˉ t j m e m ) log ( 1 − G t j mem ) ] \begin{aligned}\mathcal{L}_\mathrm{p}=-\sum_t\sum_j[\bar{G}_{tj}^\mathrm{mem}\log(G_{tj}^{\mathrm{mem}})\\ +(1-\bar{G}_{t j}^\mathrm{mem})\log(1-G_{tj}^\text{mem})]\end{aligned} Lp=−t∑j∑[Gˉtjmemlog(Gtjmem)+(1−Gˉtjmem)log(1−Gtjmem)]
G ˉ t j m e m \bar{G}_{tj}^\mathrm{mem} Gˉtjmem:父亲节点的ground-truth;如果 j − t h j-th j−th孩子节点被存储在内存中是step t t t的父亲节点则是1,否则是0;
在测试阶段,选择作为父亲节点;
o j ^ c , j ^ = argmax ( G t j mem ) o^c_{\hat{j}},\hat{j}=\operatorname{argmax}(\mathbf{G}_{tj}^{\text{mem}}) oj^c,j^=argmax(Gtjmem)
2.4、关系预测
正如父亲上下文向量和孩子上下文向量包含空间信息,加上父亲节点和孩子节点的内容信息,可以计算关系:
p r e ( o t r e ) = s o f t m a x ( W o u t r e ( c t p , c c ) ) p^{\mathrm{re}}(o_t^{\mathrm{re}})=\mathrm{softmax}\left(\mathbf{W}^{\mathrm{re}}_{\mathrm{out}}(\mathbf{c}_t^{\mathrm{p}},\mathbf{c}^{\mathrm{c}})\right) pre(otre)=softmax(Woutre(ctp,cc))
损失函数:
L r e = − ∑ t log p r e ( v t ) \mathcal{L}_{\mathrm{re}}=-\sum_t\log p^{\mathrm{re}}(v_t) Lre=−t∑logpre(vt)
2.5、实现在父亲注意力和孩子注意力的正则化
在不同时间步中的孩子节点,可能有相同的父亲节点,这时不同时间步的孩子节点的父亲节点的注意力概率是相似的。
L r e g = − ∑ t α ^ t p log α ^ t p α t P \mathcal{L}_{\mathrm{reg}}=-\sum_t\hat{\alpha}_t^{\mathrm{p}}\log\dfrac{\hat{\alpha}_t^\mathrm{p}}{\alpha_t^\mathrm{P}}\quad Lreg=−t∑α^tplogαtPα^tp
3、损失函数
O = λ 1 L c + λ 2 L p + λ 3 L r e + λ 4 L r e g O=\lambda_1\mathcal{L_c}+\lambda_2\mathcal{L_p}+\lambda_3\mathcal{L_\mathfrak{re}}+\lambda_4\mathcal{L_{\mathfrak{reg}}} O=λ1Lc+λ2Lp+λ3Lre+λ4Lreg
实验经验上: λ 1 = λ 2 = 1 ; λ 4 = 0.1 ; \lambda_1=\lambda_2=1;\lambda_4=0.1; λ1=λ2=1;λ4=0.1;如果是数学公式识别 λ 3 = 1 \lambda_3=1 λ3=1,如果是化学式识别 λ 3 = 0 \lambda_3=0 λ3=0;
4、结论:
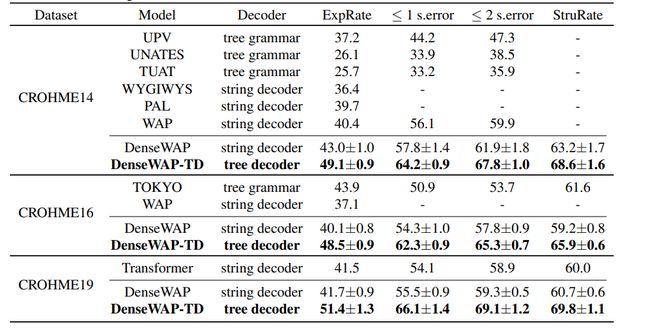
Table 1. Evaluation of math formula recognition systems on CROHME 2014, CROHME 2016 and CROHME 2019 test sets (in %). “ExpRate”, “≤ 1 s.error” and “≤ 1 s.error” means expression recognition rate when 0 to 2 symbol or structural level errors can be tolerated, “StruRate” means structure recognition rate.
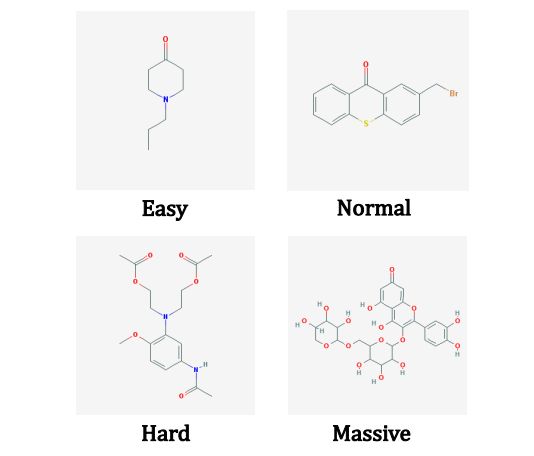
Figure 8. Split the SMILES test set into four sub-sets (“Easy”, “Normal”, “Hard”, “Massive”) based on the length of testing SMILES strings.
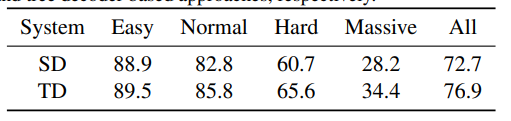
Table 3. Recognition rate comparison (in %) between string decoder and tree decoder on SMILES dataset. “Easy”, “Normal”, “Hard”, “Massive” denote the four sub-sets of test set with different length of SMILES string, “All” means the overall recognition rate on the whole test set (in %). “SD” and “TD” refer to string decoder and tree decoder based approaches, respectively.
参考:
A Tree-Structured Decoder for Image-to-Markup Generation (ustc.edu.cn)