Kafka第一讲:应用场景及架构设计详解
本节是Kafka专题第一篇,主要介绍Kafka的发展历史、应用场景以及Kafka的基本架构,后续还会对Kafka的生产者、Broker、消费者、集群做详细讲解,敬请期待。
1.kafka的发展历史及应用场景
1.1kafka的定位
可以实现如下功能:

1.2为什么叫kafka?
通过Scala语言编写。

1.3 kafka的应用场景
2.Kafka管理界面
2.1管理工具
2.2命令窗口
2.2.1bin目录
这些脚本是对java命令的一些封装,例如生产端、消费端、zk、测试工具等一些列命令。
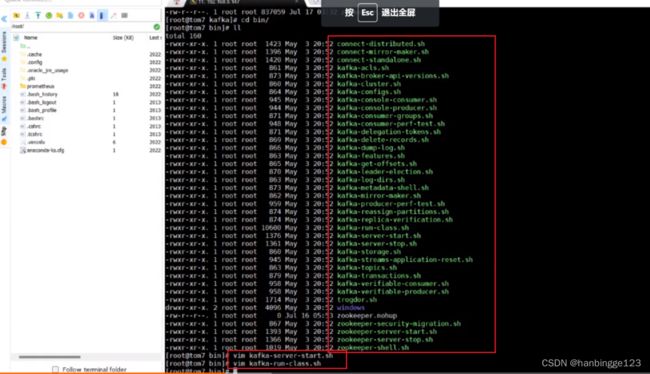
通过vim命令进去查看,可以看到命令的底层是.jar文件(运行命令实际就是运行一些java的jar包,里面是用shell脚本写的)。
3.kafka架构
3.1Kafka架构图
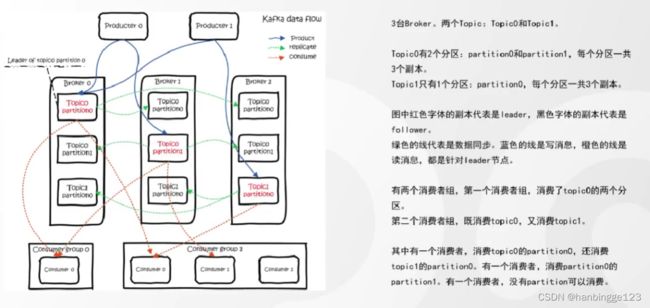
注意:partition的leader如果没挂,那么partition的副本只同步数据(做灾备),不能被消费;如果leader挂了,副本才有可能成为leader被消费。
3.2Broker
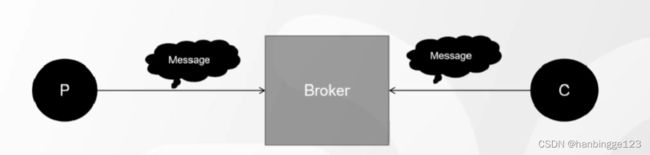
1.Kafka采用批量发送的方式(攒够一定数量一次性发送,这些参数可以自己设置);
2.所有的生产者、消费者都要跟Broker建立连接,才能实现消息的收发;
3.消息就是传输的数据(record),消息传输过程中都要序列化,代码中有相关序列化的工具。
3.2.1Kafka相关参数
Kafka的相关参数可以去官网进行获取(https://kafka.apache.org/documentation/#api)
1.linger.ms(批量发送的等待时间)
2.max.poll.records(消费者消费数据的能力)
 3.3. Topic
3.3. Topic
3.3.1相关介绍
-
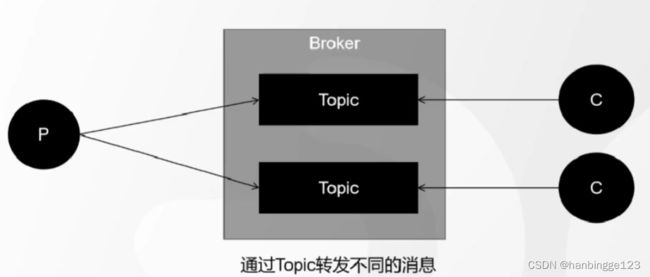
Topic是逻辑上的一个队列,跟Rabbitmq的exchange中的Topic交换机类型不是一回事,为一组消息的集合,这个消息可能是不同的业务用途,然后起了个名字;
-
生产环境建议一个生产者对应一个Topic,一个消费者对应一个Topic(多对多的关系);
-
一个Topic对应多个Partition;
-
如果Topic不存在,Kafka会自动创建这个Topic。
4.1Kafka有个参数allow auto create topics,可以设置Topic的创建权限,生产环境不建议打开这个参数,创建最好还是要申请,这个参数最好设为false。
3.3.2问题
Topic中的消息很多很多,会带来如下问题:
1.不利于横向扩展(如果需要继续进行横向扩展,则需要把消息分布在集群环境不同的机器上,而不是通过升级硬件,因为硬件厂商生产的硬件是有瓶颈的,比如戴尔的ssd硬盘最大为16T);
2.并发或者负载的时候,性能会下降(可以通过分片的思想,把消息拆分成多份,kafka里面引入了Partition的概念)。
3.3.Partition
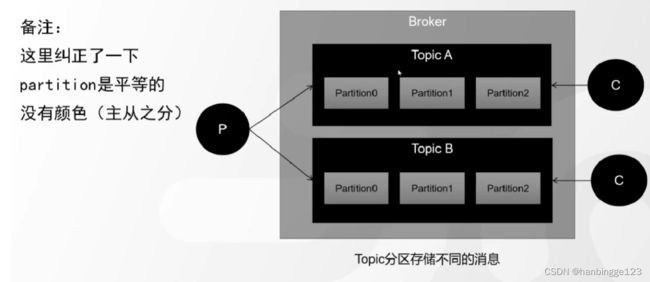 1. 把一个topic中的数据拆分成多份(partition:分片思想,可以设置一个或者多个);
1. 把一个topic中的数据拆分成多份(partition:分片思想,可以设置一个或者多个);
2.Partition里面的数据被消费之后不会删除(里面的消息是追加的,属于增量数据,所以这就是Kafka吞吐量比较大的原因);
3.一个partition对应多个segment;
kafka-topics.sh --create --topic mytopic --bootstrap-server 192.168.40.100:9092 --replication-factor 1 --partitions 2
通过以上命令创建topic时,可以指定patition分区数量,同时可以通过--replication-factor xx创建副本因子(xx不能大于集群的节点数,取值0~集群节点数,存在集群中不同的机器上)。
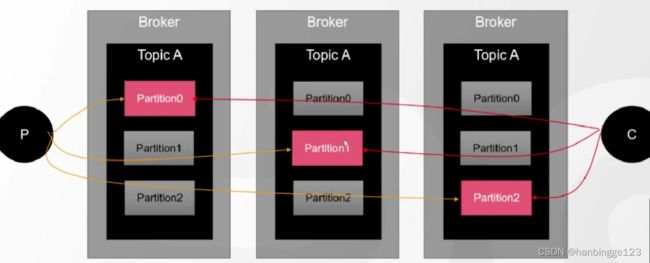
3.3.1副本机制
-
红色的代表的是leader,灰色代表的是副本(follower),follower数据是从leader同步过来的。同一个Topic,它的leader不一定在同一个节点上。
-
为了达到负载均衡的目的,Partition不一定在同一个节点上。
-
kafka的数据全部存在.log文件里面。

3.3.2Segment
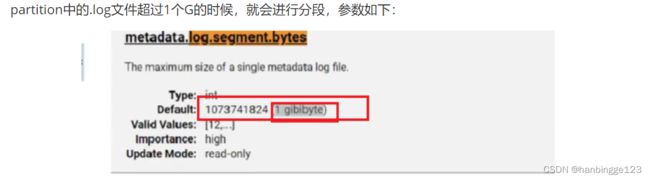
log文件页很大的话,检索的效率就会很低,Kafka会对Partition再做一个拆分,引入Segment(段)的概念。
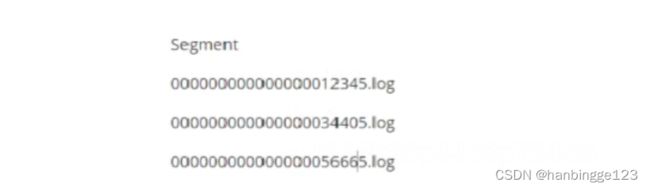 以上是三个segment示例,是对Partition的一个分段,每个Segment都会有.index(索引)、.log(数据)、.timeindex(时间戳)三个文件。
以上是三个segment示例,是对Partition的一个分段,每个Segment都会有.index(索引)、.log(数据)、.timeindex(时间戳)三个文件。
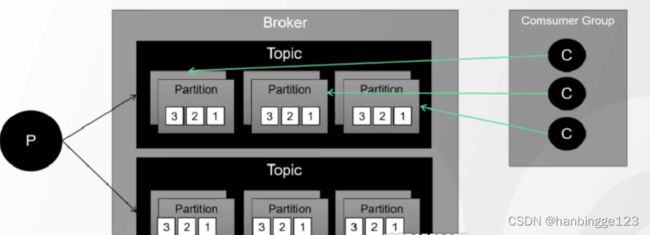
3.4消费者(消费者组)
1.如果消息有积压,可以通过增加消费者的数量来消费,Kafka通过引入消费者组的概念,来确定消费的是哪个Topic的数据。
2.消费者组也是一个逻辑概念。
3.消费者组的设计是为了保证消费的顺序。
通过如下参数指定:
![]()
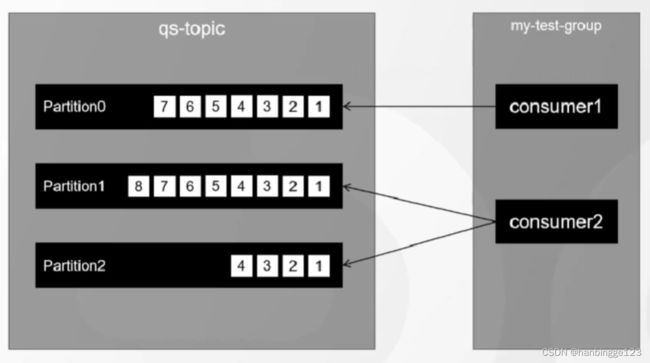
注意: 在同一个消费者组中的消费者不能消费相同的partition。
1.如果一个消费者组中的消费者比Partition多,那么多出来的消费者肯定消费不到partition,此时可以通过如下两种方法去解决:
1.1可以把多出来的消费者分到其它消费者组中;
1.2可以增加Partition来给消费者消费。
2.如果一个消费者组中的消费者比Partition少,那么一个消费者可以消费多个Partition;
3.同一个Partition可以被其它消费者组中的不同消费者消费。
3.4.1Consumer Offset
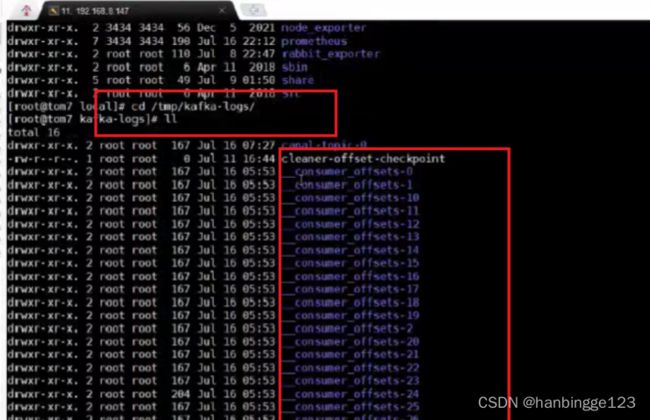
之前,Kafka消费者的偏移量是记录在zk中的,现在Kafka引入了默认的50个消费者偏移量文件分段标识,用于记录消费者的偏移量,这个分段标识数量可以根据消费者的数量进行调整。
4.Kafka java开发API介绍
4.1.ProducerAPI
发送消息的API
4.2.ConsumerAPI
接收消息的API
4.3.Admin API
管理、监测API
4.4.Stream API
处理大数据的API(Spark、Flink等)
4.5.Connect API
用于持续的从原系统输入数据的、或者从kafka推从数据到系统(比如数据库等)
4.6.Springboot连接Kafka
4.7数据多写的场景
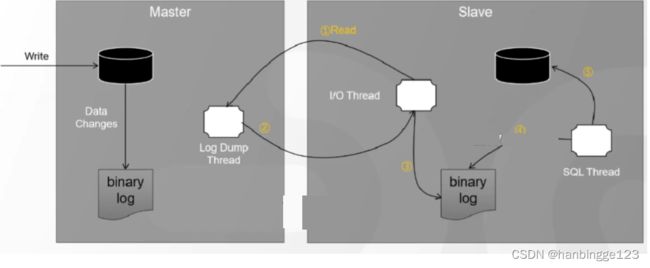
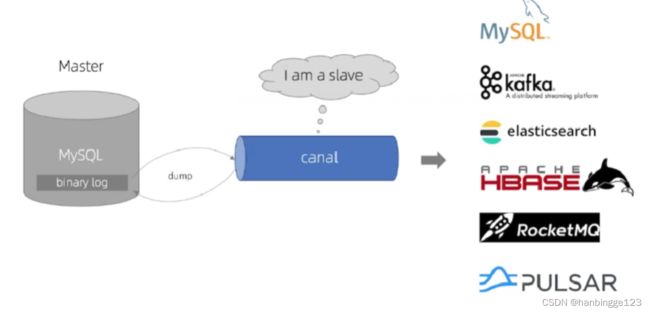
假如mysql变动,又要同步更新es,此时怎么做呢?
通过canal特性把数据实时同步到kafka、es、mysql这些中间件里面,这样可以完成数据流的操作,后续可以用来做数据的恢复、数据库日志的分析等等(Canal把自己伪装成一个slave节点,不断的去请求最新的binlog日志(记录了所有数据库的操作轨迹))。