kafka的基本应用
文章目录
- kafka的基本应用
-
- 1、命令操作
-
- 1.1 创建主题
- 1.2 查询主题
- 1.3 创建生产者
- 1.4 创建消费者
- 2、Java API操作
-
- 2.1 创建Java工程
- 2.2 生产者
- 2.3 消费者
- 2.4 配置日志
- 2.5 测试
- 3、案例(kafka生产者拦截器)
-
- 3.1 简介
- 3.2 创建拦截器
- 3.3 配置拦截器
- 3.4 演示结果
kafka的基本应用
1、命令操作
1.1 创建主题
我们可以直接利用kafka提供的脚本(kafka-topics.sh)创建主题
[hadoop@spark001 kafka]$ bin/kafka-topics.sh \
> --create \
> --zookeeper spark001:2181,spark002:2181,spark003:2181 \
> --replication-factor 2 \
> --partitions 2 \
> --topic topictest
Created topic "topictest".
参数解释
–create: 指定命令为创建主题
–zookeeper : 指定zookeeper集群的地址
–replication-factor :指定所创建主题的分区副本数
–partitions : 所创建主题的分区数
–topic topictest : 主题的名称
Zookeeper集群中kafka的信息:

1.2 查询主题
还是使用kafka-topics.sh脚本
# 粗略查询主题
[hadoop@spark001 kafka]$ bin/kafka-topics.sh \
> --list \
> --zookeeper spark001:2181
topictest
[hadoop@spark001 kafka]$
详细查询,在脚本后添加–describe参数,可查询某一个主题的详细信息。

1.3 创建生产者
kafka的生产者是消息的产生者,能够产生消息,并将消息推送到相对应的主题上。
我们可以使用kafka自带的脚本来创建简单的生产者。
# 输出指令后直接按下回车键,控制台进入命令输入态。
# 接下来,我们可以向topic推送消息了,需要一个消费者才能查看效果。
[hadoop@spark001 kafka]$ bin/kafka-console-producer.sh \
> --broker-list spark001:9092,spark002:9092,spark003:9092 \
> --topic topictest
>
参数解释:
–broker-list : 指定broker的连接地址,这里写了集群中的多个地址,只有启动一个连接成功即可
–topic : 指定推送的主题
1.4 创建消费者
kafka中的消费者,是消费对应主题中数据的角色。
[hadoop@spark001 kafka]$ bin/kafka-console-consumer.sh \
> --bootstrap-server spark001:9092,spark002:9092,spark003:9092 \
> --topic topictest
在生产者的窗口输入消息:

观看消费者窗口:

2、Java API操作
2.1 创建Java工程
这里利用idea创建maven工程
导入相应的pom依赖:
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.0.0version>
dependency>
2.2 生产者
package com.demo.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* 创建生产者
*/
public class Producer {
public static void main(String[] args) {
// 利用Propertis配置属性
Properties props = new Properties();
// 设置Broker连接地址
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"spark001:9092,spark002:9092,spark003:9092");
// 设置序列化key采取的类
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//设置序列化value类
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());
// 定义生产者对象
KafkaProducer<String, Integer> producer = new KafkaProducer<String, Integer>(props);
// 发送消息
for(int i=0;i<10;i++){
// 第一个参数为主题的名称,后面为key,value值
// 注意,这里的key value值需要和上面的序列化对应起来
// 这里只是将消息发送出去,并不关心消息是否发送成功。
producer.send(new ProducerRecord<String, Integer>("topictest","hello kafka"+i,i));
}
// 关闭生产者,释放资源
producer.close();
}
}
注意:这里只是将消息发送出去,没有确保消息传递的可靠。
同步发送和异步发送(可以确保消息传递的可靠性)
同步发送:
生产者对象使用send()方法后会返回Future对象,利用Future对象的get方法检测发送结果。若发送成功,get方法可以获取RecordMetadata对象,里面存储消息的相关信息,若发送失败则会抛出异常。
代码:
Future<RecordMetadata> future = producer.send(new ProducerRecord<String, Integer>("topictest", "hello kafka" + i, i));
try {
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
异步发送:
生产者调用send方法时,我们可以指定一个回调函数,服务器返回信息时会调用该方法,在回调方法里,我们可以判断消息的发送状况。
代码:
producer.send(new ProducerRecord<String, Integer>("topictest", "hello kafka" + i, i)
, new Callback() {
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
// 这里可以进行返回信息的判断,和后续操作。
if(e!=null){
e.printStackTrace();
}
}
});
2.3 消费者
package com.demo.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
* 消费者
*/
public class Consumer {
public static void main(String[] args) {
Properties props = new Properties();
// broker连接地址
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"spark001:9092,spark002:9092,spark003:9092");
// 设置反序列化使用的类
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class.getName());
// 设置消费者组id,id相同的消费者属于同一个组
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"group01");
// 创建消费者
KafkaConsumer<String, Integer> consumer = new KafkaConsumer<String, Integer>(props);
// 设置消费者消费的主题,可以是多个
consumer.subscribe(Arrays.asList("topictest"));
// 消费信息
while (true){
// 拉取消息,超时时间为10s
ConsumerRecords<String, Integer> records = consumer.poll(Duration.ofSeconds(10));
for (ConsumerRecord<String, Integer> record : records) {
System.out.println("key:"+record.key()+", value:"+record.value()+", partition: "
+record.partition()+", offset:"+record.offset());
}
}
}
}
2.4 配置日志
为了观察详细信息,配置sl4f日志,我们需要添加log4j的日志配置文件
添加日志依赖:
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>1.6.1version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.6.1version>
dependency>
添加log4j.properties配置文件
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
2.5 测试
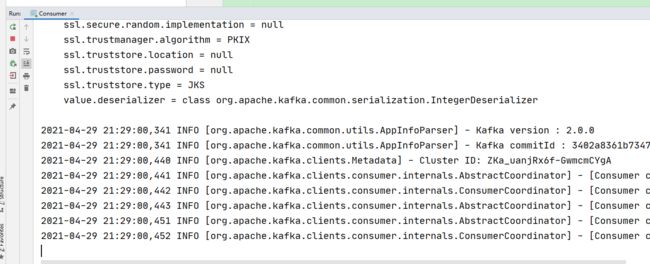
先启动消费者,然后启动生产者观察变化
启动消费者:
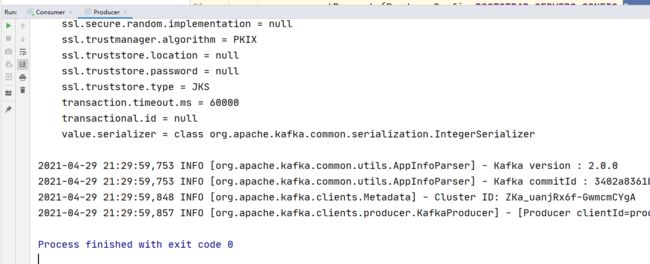
启动生产者:
再观察消费者窗口:
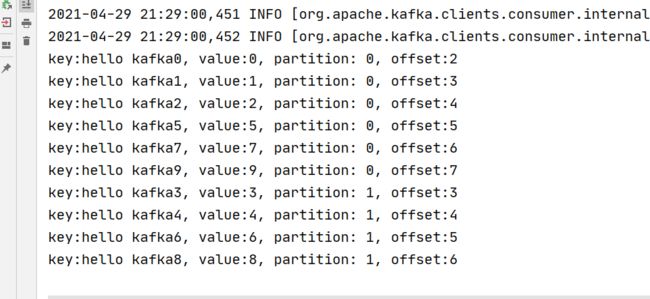
消息已经被拉取了。
3、案例(kafka生产者拦截器)
3.1 简介
拦截器:即在某个方法或者任务执行的前后,动态添加某些功能。
这里类比SpringMVC中的拦截器(interceptor)。
kafka拦截器:可以在消息发送前对内容进行定制化修改,对数据进行粗略的处理,也可用于在消息发送后获取消息的发送状态、所在分区、偏移量。
kafka中可以定义多个拦截器形成一个拦截器链,以增加功能。
下面是两个拦截器组成的拦截器链,第一个为时间拦截器,作用是在消息发送之前修改消息的内容,在消息最前面加入当前时间戳;第二个拦截器为消息发送状态拦截器,统计消息发送成功和失败的数目。
3.2 创建拦截器
时间拦截器:
package com.demo.kafka;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
* 时间拦截器
*/
public class Interceptor_time implements ProducerInterceptor {
/**
* 在消息未被发送,未被序列化时调用
* @param record
* @return
*/
@Override
public ProducerRecord onSend(ProducerRecord record) {
System.out.println("time_interceptor----调用onSend方法。。。。。。");
ProducerRecord<String, String> rec = new ProducerRecord<String, String>(record.topic(), System.currentTimeMillis() + "_" + record.key(),
record.value().toString());
return rec;
}
/**
* 该方法在发送到服务器的记录已被确认或者记录发送失败时调用
* @param recordMetadata
* @param e
*/
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
System.out.println("time_interceptor----调用onAcknowledgement。。。。。。");
}
/**
* 用于关闭拦截器,并释放资源
*/
@Override
public void close() {
System.out.println("time_interceptor----调用close方法。。。。。。");
}
/**
* 初始化数据时调用,用于获取生产者的配置信息。
* @param map
*/
@Override
public void configure(Map<String, ?> map) {
System.out.println("time_interceptor----调用configure方法。。。。。。");
System.out.println(map.get(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG));
}
}
状态拦截器:
package com.demo.kafka;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
* 发送状态统计拦截器
*/
public class Interceptor_status implements ProducerInterceptor {
// 定义发送成功和发送失败的统计变量
private int successcount = 0;
private int failedcount = 0;
@Override
public ProducerRecord onSend(ProducerRecord record) {
System.out.println("status-interceptor----调用onSend。。。。。");
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.println("status-interceptor----调用onAcknowledgement。。。。。");
if(exception == null){
successcount++;
}else{
failedcount++;
}
}
@Override
public void close() {
System.out.println("status-interceptor----调用close。。。。。");
System.out.println("发送成功消息数量:"+successcount);
System.out.println("发送失败消息数量:"+failedcount);
}
@Override
public void configure(Map<String, ?> configs) {
System.out.println("status-interceptor----调用configure。。。。。");
System.out.println(configs.get(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG));
}
}
3.3 配置拦截器
我们需要在生产者类里手动配置拦截器:
// 设置拦截器
List<String> interceptors = new ArrayList<>();
// 添加拦截器
// 这里需要写全类名
interceptors.add("com.demo.kafka.Interceptor_time");
interceptors.add("com.demo.kafka.Interceptor_status");
// 将拦截器添加到properties中
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,interceptors);
3.4 演示结果
生产者中的拦截器调用顺序:

这里拦截器方法调用的顺序:
configure方法 —> onSend方法 —>onAcknowledgement方法 —>close方法
消费者控制台:


这里开启了两个消费者,并且消费者位于同一个分组,可以观察到,同一个消费者组中的消费者只能一个消费者获取消息。