七. MySQL 其它优化相关
目录
- 一. 数据库问题排查流程
- 二. 表连接
-
- 驱动表与被驱动表
- Nested Loop Join 与小表驱动大表
- JoinBuffer 连接缓冲区
- Index Nested-Loop Join 索引嵌套循环连接
- Batched Key Access join 批量的key访问连接
- Block Nested-Loop Join 缓存块嵌套循环连接
- 三. 半连接
-
- in 与 exists
- semi-join 半连接
-
- 1. 子查询中的表上拉
- 2. 重复值消除
- 3. 松散扫描
- 4. 半连接物化
- 5. 不能使用半连接的情况
- 三. order by 排序优化
-
- 双路排序
- 单路排序与单路排序可能出现的问题
- 总结orderby优化
- 举例orderby能够命中索引的情况
- 四. group by 分组优化
一. 数据库问题排查流程
MySql 正常生产排查流程
- 开启日志慢查询记录,设置阈值,例如2秒
- 运行生产环境,查看查看慢查询日志
- 找到慢查询SQL, EXPLAIN查看执行计划,分析优化(通常情况下在此处已经解决了大部分慢SQL的问题)
- 如果还有慢SQL, show profile查看执行sql在MySql服务器中执行细节生命周期情况进行分析优化,
- 如果还有慢SQL,就需要进行数据库服务器的参数调优
二. 表连接
驱动表与被驱动表
- 什么是驱动表与被驱动表: :A 表和 B 表 join 连接查询,如果通过 A 表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到 B 表中查询数据,然后合并结果。那么我们称 A 表为驱动表,B 表为被驱动表
- 判断驱动表与被驱动表
- LEFT JOIN 左连接,左边为驱动表,右边为被驱动表.
- RIGHT JOIN 右连接,右边为驱动表,左边为被驱动表.
- INNER JOIN 内连接, mysql会选择数据量比较小的表作为驱动表,大表作为被驱动表.
Nested Loop Join 与小表驱动大表
- MySQL 中使用Nested Loop Join作为表关联算法,是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果
- 针对Nested Loop Join,进行优化,优化的目标是尽可能减少JOIN中Nested Loop的循环次数,也就是减少驱动表中获取出的数据数量,进而减少循环次数,例如选择小表作为驱动表,或者表连接字段添加索引例如:
#user表10000条数据,class表20条数据
#这样则需要用user表循环10000次才能查询出来,而如果用class表驱动user表则只需要循环20次就能查询出来
select * from user u left join class c u.userid=c.userid
#优化为
select * from class c left join user u c.userid=u.userid
- 通过fro循环了解小表驱动大表
//外层for循环相当于驱动表,假设外层的驱动表为大表
//没循环一次MySql获取释放连接,需要1000次,性能浪费
for(int i = 0;i<1000;i++){
for(int i = 0; i<5; i++){
//......
}
}
//外层的表相当于驱动表,只需要获取释放连接5次
for(int i = 0;i<5;i++){
for(int i = 0; i<1000; i++){
//......
}
}
- 针对 Nested Loop Join 算法实际有多种,上面说的是最基础的嵌套for循环暴力算法 Simple Nested-Loop Join,
- 使用索引关联的情况下,有Index Nested-Loop join和Batched Key Access join两种算法
- 未使用索引关联的情况下,有Simple Nested-Loop join和Block Nested-Loop join两种算法
- 并且学习表连接查询算法前要先看一下 JoinBuffer 连接缓冲区
JoinBuffer 连接缓冲区
- JoinBuffer连接缓冲区: 针对被驱动表的连接字段**没有索引的情况(或联接是ALL、index、和range的类型)**需要进行全表扫描时,全表扫描过程的优化,当发现连接查询没使用到索引时
- 不使用JoinBuffer: 获取一条驱动表中的数据,根据该数据与连接条件查询被驱动表中满足的数据,一条一条的匹配
- 使用JoinBuffer: 只缓存驱动表数据,不再是每次从驱动表中取1条记录。而是在开始时通过joinBuffer将驱动表全部装入内存,当joinBbuffer满或者是最后一条记录的时候,开始启动被驱动表的扫描,将读取出的数据结合前面缓存的每一个记录进行匹配判断,减少驱动表的io查询
- 适当调大JoinBuffer通过内存存储更多数据,减少获取驱动表数据时的磁盘io
- 通过此处也能说明为什么不推荐用"select * ", MySQL为了查询性能提供了多种缓存,用来减少磁盘io,以JoinBuffer为例,连表查询时如果使用到了JoinBuffer,会将查询的字段跟过滤条件字段存储到缓存中,避免使用 " * ",减少不必要的缓存占用
- JoinBuffer不同版本好像不一样,当前生产使用的5.7版本,默认262144字节也就是256k,并且不是设置越大越好,针对128GB,1万并发的mysql推荐"8~16M"
Index Nested-Loop Join 索引嵌套循环连接
- 实际就是针对连接条件在被驱动表添加索引,使外层驱动表直接与内存被驱动表的索引进行匹配,通过索引提高内存驱动表的查询性能
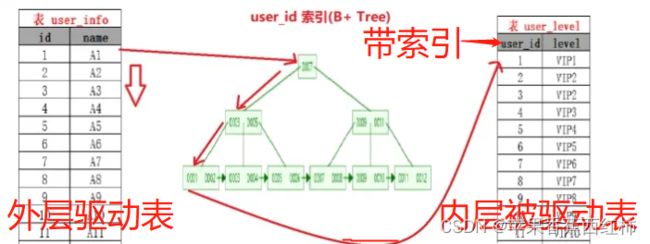
Batched Key Access join 批量的key访问连接
- 已知驱动表的每条记录在关联被驱动表时,如果需要用到索引不包含的数据时,就需要回表一次,去聚集索引上查询记录,这是一个随机查询的过程。每条记录就是一次随机查询,性能不是非常高。mysql对这种情况有选择的做了优化,将这种随机查询转换为顺序查询
- 根据where条件查询驱动表,将符合记录的数据行放入join buffer,然后根据关联的索引获取被驱动表的索引记录,存入read_rnd_buffer。join buffer和read_rnd_buffer都有大小限制,无论哪个到达上限都会停止此批次的数据处理,等处理完清空数据再执行下一批次。也就是驱动表符合条件的数据可能不能够一次处理完,而要分批次处理,在回表查询时将随机读优化为MRR顺序读技术
Block Nested-Loop Join 缓存块嵌套循环连接
- 这块实际是结合JoinBuffer连接缓冲区一块使用的,在连表查询时,如果无法触发"Index Nested-Loop Join"(连接条件在被驱动表上不是索引),数据库默认使用Block Nested-Loop Join算法
- 该算法通过一次性缓存外层驱动表的多条数据,进而减少,内层表的扫表次数,通过joinBuffer缓存多条驱动表记录,然后通过多条记录批量扫描内存被驱动表,减少了被驱动表的io次数
- Index Nested-Loop Join 是通过索引的机制减少内层表的循环匹配次数达到优化效果,而Block Nested-Loop Join 是通过一次缓存多条数据批量匹配的方式来减少外层表的IO次数,同时也减少了内层表的扫表次数
- 与Index Nested-Loop join不同的是能使用joinBuffer,可以每次从驱动表筛选一批数据,同时每个join关键字就对应着一个joinBuffer,也就是驱动表和第二张表用一个joinBuffer,得到的块结果集与第三张表用一个joinBuffer
三. 半连接
参考博客
in 与 exists
- 先说一下in查询与mysql对in做的优化,引出下面的问题
- in条件查询有多种情况例如:
#1.in中包含的是常量数据
select * from table1 where key1 in (1,2,3,4)
#2.in中的数据是通过子查询在其它表中查询出的
select * from table1 where key1 in( select f from table2 ...)
- 针对第一种in(多个常量)时, MySQL会先将in中的多个条件参数进行排序,如果查询时不能利用索引形成若干扫描区间,那么将会对已排好序的参数进行二分查找,加速in表达式的效率
- 针对第二种in中通过子查询获取数据的情况,MySQL提出物化表的概念,
- 通过临时表缓存子查询中的列,并根据所有的列当做联合唯一索引进行去重
- 有了物化表后,考虑将原本的表和物化表建立连接查询, 计算连接成本,选择最优的执行计划了
- 最终执行原理: 是把外表和内表做连接,先查询内表,再把内表结果与外表匹配
- 对 exists 解释: “select * from where exists (subquery)”: 该语句可以理解为将主查询的数据放到子查询中做条件验证,根据验证结果返回true或false,来决定查询的数据结果是否可以保留
- MySQL在执行in或exists操作时,实际底层会进行判断:
- 如果A表数据集大于B表的数据集使用in优与Exists,
- 如果A表的数据集小于B表的数据集使用Exists优与in
- 注意: A表id与B表id添加索引(exists子查实际执行过程中可能经过了优化,而不是我们理解的逐条对比,exisits也可以用条件表达式,其它子查询或者JOIN代替,具体情况具体分析)
semi-join 半连接
- 上面了解到在执行in查询时,MySQL可能会根据实际的sql将in查询通过物化表优化为连接查询,示例
#原sql
select * from t1 where key1 in (select m1 from s2 where key2 = 'a')
#优化后
#1.对于t1表,s2结果集中如果没有满足on条件的,不加入结果集
#2.对于t1表,s2结果集中有且只有一条符合条件的,加入结果集
#3.对于t1表,s2结果集中有多条符合条件的,那么该记录将多次加入结果集
select t1.* from t1 innert join s2 on t1.key1 = s2.m1 where s2.key2 = '1'
- 根据上方sql发现问题:对于情况1、2的内连接,都是符合上面子查询的要求的,但是结果3,在子查询中只会出现一条记录,但是连接查询中将会出现多条
- 最终优化出的半连接sql类似是这么写的(只是一种概念),半连接可以理解为mysql优化特殊sql出现的一种概念
select t1.* from t1 semi join s2 on t1.key1 = s2.m1 where s2.key2 = '1'
- 半连接的实现方式:
- 子查询中的表上拉
- 重复值消除:
- 松散扫描:
- 半连接物化:
- 首次匹配:
1. 子查询中的表上拉
- 当子查询的列中只有主键或唯一二级索引时,直接将子查询提升到外层来做连接查询,示例sql及解释:
#原sql
select * from t1 where key1 in (select m1 from s2 where key2 = 'a')
#优化后
#1.如果m1是s2的主键或唯一索引,因为子查询中的主键或唯一索引本身就是不重复的,因此直接提升做连接,
#也不会出现重复值那么语句直接被优化为:
select t1.* from t1 inner join s2 on t1.key1 = s2.m1 where s2.key2 = '1'
2. 重复值消除
- 可以认为物化表有去重功能
#原sql
select * from t1 where key1 in (select m1 from s2 where key2 = 'a')
#如果m1不是s2的主键或唯一索引,优化后的语句依然可以是
select t1.* from t1 inner join s2 on t1.key1 = s2.m1 where s2.key2 = '1'
- 每当有s1的记录加入结果集时,则把该记录的id放到这个临时表中,如果添加失败,说明之前有重复的数据已经添加过了,直接丢弃,保证了数据不会重复
3. 松散扫描
4. 半连接物化
半连接物化就是前面提到的 物化表转连接 的方式
5. 不能使用半连接的情况
- 不能转为半连接进行优化的情况
#1.在外层查询的where条件中,存在其他搜索条件使用or操作符与in子查询组成的布尔表达式
select * from s1 where key1 in (select m1 from s2 where key3 = 'a') or key2 > 100
#2.使用not in,而不是 in
select * from s1 where key1 not in (select m1 from s2 where key3 = 'a')
#3.位于 select 子句中
select key1 in (select m1 from s2 where key3 = 'a') from s1
#4.子查询中包含 group by 、having 或者 聚合函数
select * from s1 where key1 not in (select count(*) from s2 group by key1)
#5.子查询包括union
select * from s1 where key1 in
(select m1 from s2 where key3 = 'a' union select m1 from s2 where key3 = 'b')
- 针对不能转换为半连接进行优化时的处理
- 物化表: 对于not in无法半连接. 直接将子查询物化,判断结果是否在物化表中,进行速度加快
- 转为exists: 在where或on子句中的in子查询无论是相关还是不相关的,都可以转为exists子查询
三. order by 排序优化
- 首先提出: 尽量使用index方式排序,避免使用FileSert方式排序,尽可能在索引列上完成排序操作,遵照索引的最佳左前缀原则(FileSert是指使用EXPLAIN执行计划中Extra列中显示"Using fileSert"表示使用临时表存储了中间结果,使用索引,与遵照最佳左前缀原则是如果执行的order by字段上可以命中索引,可以避免fileSert,但是例如联合索引时,并且执行sql中有多种过滤条件,假设从where开始到order by中间有过滤条件造成order by中的无法命中也会出现fileSert)
- 如果order by 不在索引列上,或者执行的sql中同时ASE与DESC两种排序,无法避免FileSert,此时就要MySql启动双路排序和单路排序
双路排序
- MySql 4.1之前使用双路排序,意思是两次扫描磁盘,最终得到需要的数据,读取行指针合orderby列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出,
- 总结双路排序造成的问题: 需要两次磁盘io,一是从磁盘取排序字段,然后再buffer缓存中进行排序,第二次从磁盘读取其它字段,io比较耗时,所以在4.1之后出现了单路排序
单路排序与单路排序可能出现的问题
-
MySql 4.1之后为了解决双路排序两次磁盘io问题出现的,首先从磁盘读取查询的所有列,按照orderby的列在buffer缓存中对数据进行排序,然后扫描排序后的列输出,避免二次读取数据提高效率,并且把随机io变成了顺序io,但是单路排序会销毁空间,因为把每一行的数据保存到了内存中
-
单路排序可能出现的问题: MySql4.1后使用单路排序解决双路排序两次磁盘io问题,但是有可能出现一个问题,MySql有个缓存区sort_buffer,单路排序是一次磁盘io读取查询数据的所有列,加入读取数据的总大小超过了sort_buffer的容量,会导致每次磁盘io读取sort_buffer容量大小的数据,然后排序,创建临时表进行缓存,最终多路合并,会导致多次io
-
优化策略: : 增大 sort_buffer_size 参数设置,并且增大 max_length_for_sort_data 参数设置
总结orderby优化
- order by 排序时,使用索引,考虑多种过滤过滤时索引是否能够命中(例如order by前的过滤条件中有范围查询,联合索引时不能满足最左前缀原则,order by中同时存在ASC DESC多种等)
- order by 排序是,避免使用"select *",控制查询数据大小,减少查询数据超过sort_buffer容量的概率
- 在查询数据总大小不超过max_length_for_sort_data,并且排序字段不是TEXT与BLOB类型是,会使用大陆排序,否则使用多路排序,调高max_lenght_for_sort_data参数
- 单路排序与多路排序都有可能出现磁盘io读取数据超过sort_buffer容量,创建临时表缓存,最终进行合并,导致多次io问题,(单路排序磁盘io读取查询数据所有列风险更大),调高sort_buffer_size参数
- 设置max_lenght_for_sort_data与sort_buffer_size需要考虑的问题
sort_buffer_size: 需要根据系统能力进行设置,一问这个参数是针对每个进程的
max_lenght_for_sort_data: 在设置这个参数时要考虑sort_buffer_size的大小,如果max_lenght_for_sort_data值设置太高,数据容量可能会超出sort_buffer_size的概率增大,会出现搞的磁盘io活动和低的处理器使用率的现象
举例orderby能够命中索引的情况
- 表中a,b,c三个字段添加联合索引,能够使用索引,不会FileSort的情况(两种排序是index排序,与fileSort排序,fileSort也就是执行计划中Extra中出现 Using filesort)

- 不能使用索引,出现FileSort的情况

四. group by 分组优化
- group by 与order by 优化大致相同: group by 实质是先进行排序,然后进行分组,遵照索引最左前缀原则
- 当无法使用索引时,增大max_length_for_sort_data参数与sort_buffer_size参数设置
- where 高于 having,能在where限定的条件不要使用having