Flink--- 批处理 / 流处理
目录
Flink的主要特点
Flink 和 Spark Streaming
搭建maven工程 FlinkTutorial
添加Scala框架 和 Scala文件夹
Flink-批处理wordcount
Flink---流处理wordcount
Flink 是一个框架和分布式的处理引擎,用于对无界和有界数据流进行状态计算。
传统数据处理架构
事务处理

分析处理
:将数据从业务数据库复制到数仓,再进行分析和查询

流处理的演变
lambda架构
:用两套系统,同时保证低延迟和结果准确

流处理的演变
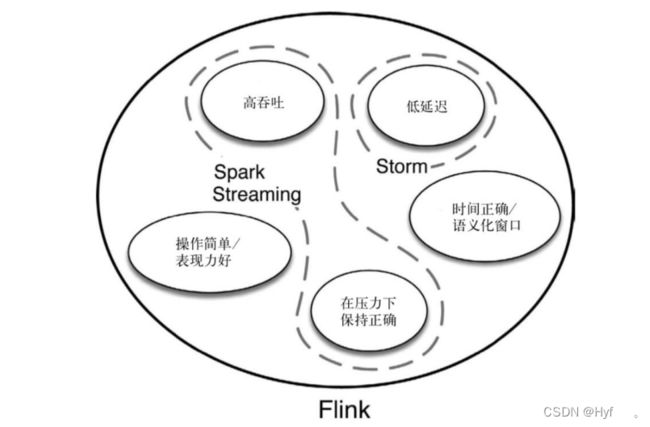
Flink的主要特点
1、事件驱动
2、基于流的世界观
在Flink的世界观中,一切都是由流组成的,离线数据是有界的流;实时数据是一个没有界限的流 :这就是所谓的有节流和无界流
3、分层API
越顶层越抽象,表达含义越简明,使用越方便
越底层越具体,表达能力越丰富,使用越灵活
Flink的其他特点
1、支持事件时间(event-time)和处理时间(processing-time)语义
2、精确一次(exactly-once) 的状态一致性保证
3、低延迟,每秒处理数百万个事件,毫秒级延迟
4、与众多常用存储系统的连接
5、高可用,动态扩展,实现7*24小时全天候运行
Flink 和 Spark Streaming
流(stream)和微批(micro-batching)
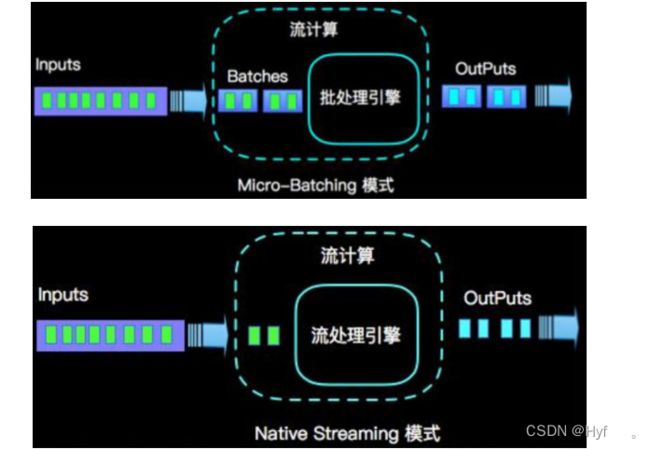
数据模型:
--- spark采用RDD模型,spark streaming 是 DStream实际上也就是一组组小批数据RDD的集合
--- flink基本数据模型是数据流,以及事件(Event)序列
运行时架构:
--- spark是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个
--- flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
搭建maven工程 FlinkTutorial
文件---新建---项目---maven
在pom文件中插入
如下内容:
org.apache.flink
flink-scala_2.12
1.10.1
org.apache.flink
flink-streaming-scala_2.12
1.10.1
net.alchim31.maven
scala-maven-plugin
3.4.6
compile
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly 添加Scala框架 和 Scala文件夹
在src-main目录下创建一个新目录,命名为:Scala

(在新建目录上)单击右键---将目录标记为----源 根
然后,创建一个Scala类--object--命名;即可
Flink-批处理wordcount
首先创建一个 . txt 文件
在resources目录下创建,命名为:hello
在新建文件夹中输入一些英语单词,一会进行批处理即可!

运行代码
package com.atguigu.wc
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]): Unit = {
//创建一个批处理的执行环境
val env:ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//接收文件
val inputPath:String = "D:\\HYF\\FlinkTutorial\\src\\main\\resources\\hello.txt"
val inputDataSet:DataSet[String] = env.readTextFile(inputPath)
//对数据进行转换处理统计,先分词,再按照word进行分组,最后进行聚合统计
val resultDataSet:DataSet[(String,Int)] = inputDataSet
.flatMap(_.split(" ")) //按照空格对String进行一个分割
.map((_,1)) // _进行分组,1进行求和
.groupBy(0) //以第一个元素作为key,进行分组
.sum(1) //对所有数据的第二个元素求和
resultDataSet.print()
}
}
运行结果

Flink---流处理wordcount
运行代码如下
package com.atguigu.wc
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
object StreamWordCount {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val inputDataStream:DataStream[String] = env.socketTextStream("localhost",7777)
val resultDataStream:DataStream[(String,Int)] = inputDataStream
.flatMap(_.split(" "))
.filter(_.nonEmpty)
.map((_,1))
.keyBy(0)
.sum(1)
resultDataStream.print()
//启动任务执行
env.execute("stream word count")
}
}测试——在 linux 系统中用 netcat 命令进行发送测试
启动命令 ---- nc -lk 7777
输入一些数据即可!
运行结果:当时监听窗口出现错误了,所以没有监听成功,结果这里就不显示了