Kafka3.1简介及Kafka3.1部署、原理和API开发使用介绍
第1章-kafka简介
1-1.消息队列简介
什么是消息队列
“消息队列”是在消息的传输过程中保存消息的容器。“消息”是在两台计算机间传送的数据单位。
英文名:Message Queue,经常缩写为MQ
可以简单理解消息队列就是将需要传输的数据存放在队列中
消息队列的作用
1、应用耦合处理:多应用间通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败;
2、异步处理:多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间;
3、限流削峰:广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况;
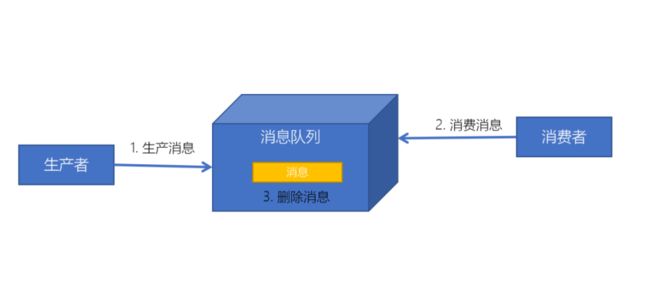
4、消息驱动的系统:系统分为消息队列、消息生产者、消息消费者,生产者负责产生消息,消费者(可能有多个)负责对消息进行处理;
常见消息队列中间件
消息队列中间件就是用来存储消息的软件应用。例如分析网站的用户行为,需要记录用户的访问日志,访问了什么点击了什么收藏了什么等等,这些一条条的信息日志,可以看成是一条条的消息,可以将它们保存到消息队列中。将来有一些应用程序需要处理这些日志,就可以随时将这些消息取出来处理。
常见消息队列有很多,例如:Kafka、RabbitMQ、ActiveMQ、RocketMQ、ZeroMQ等
- Kafka
Apache Kafka是一个分布式消息发布订阅系统。它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),之后成为Apache项目的一部分。
这是一款为大数据而生的消息中间件,在数据采集、传输、存储的过程中发挥着举足轻重的作用。
- RabbitMQ
RabbitMQ 2007年发布,是一个在 AMQP (高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一。
- ActiveMQ.
Java世界的中坚力量。它有很长的历史,而且被广泛的使用。它还是跨平台的,给那些非微软平台的产品提供了一个天然的集成接入点
- RocketMQ
RocketMQ出自阿里公司的开源产品,用 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进。
- ZeroMQ
ZeroMQ具有一个独特的非中间件的模式,不需要安装和运行一个消息服务器,或 中间件。只需要简单的引用ZeroMQ程序库就可以在应用程序之间发送消息。
消息队列的应用场景
消息队列的应用场景和它的作用有关,根据作用特点可以归纳出对应的使用场景
异步处理
电商网站中,新的用户注册时,需要将用户的信息保存到数据库中,同时还需要额外发送注册的邮件通知、以及短信注册码给用户。但因为发送邮件、发送注册短信需要连接外部的服务器,需要额外等待一段时间,此时,就可以使用消息队列来进行异步处理,从而实现快速响应
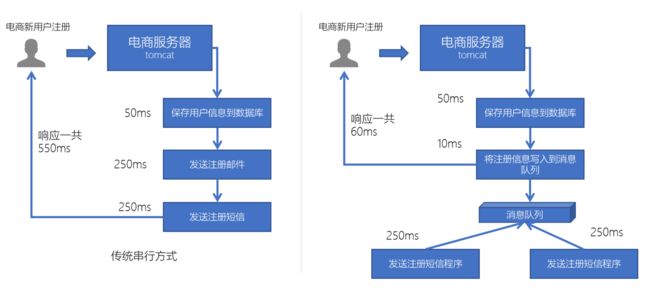
系统解耦
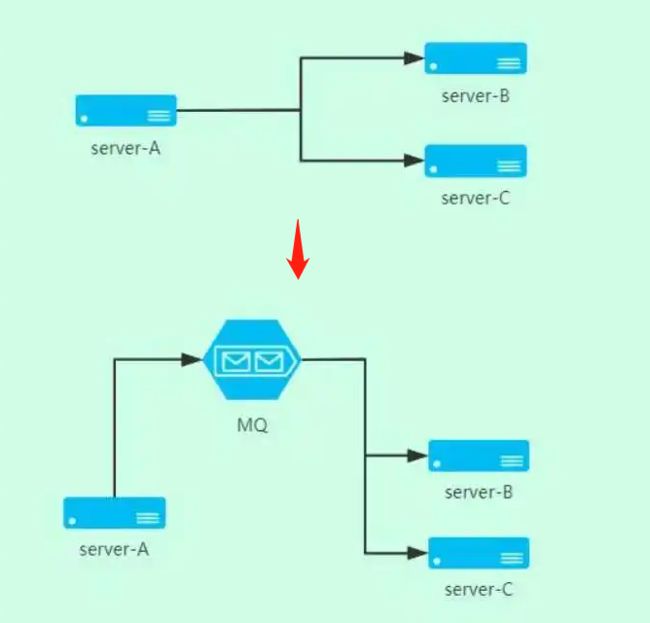
多应用间通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败
例如上方没有MQ中间件时,serverB或者serverC服务中断,则整个服务相当于都中断
而加入MQ中间件后,serverB或者serverC服务有一个出问题,那么它的处理消息是在MQ中的,此时serverA就不会有影响,可以正常运转,等到serverB或者serverC故障恢复了再处理对应的工作,从而提高了系统的可用性
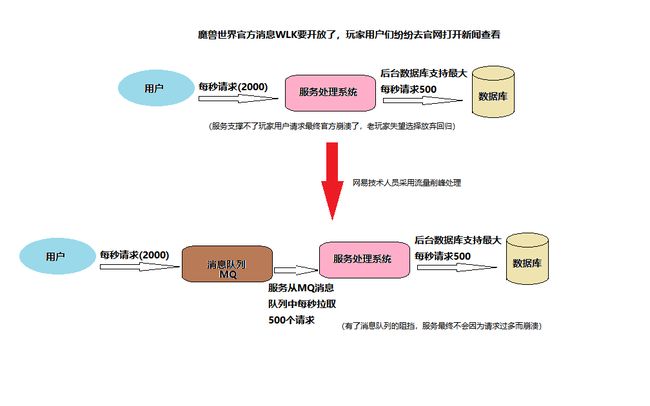
流量削峰
广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况
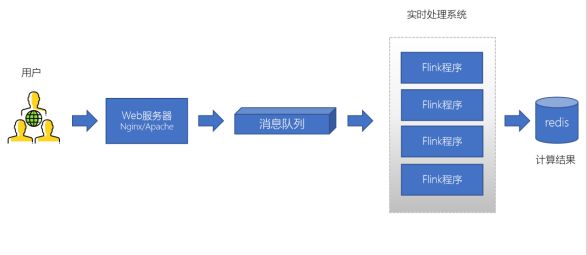
日志消息处理
大型电商网站(淘宝、京东、国美、苏宁等等)、App(抖音、美团、滴滴等)等需要分析用户行为,要根据用户的访问行为来发现用户的喜好以及活跃情况,需要在页面上收集大量的用户访问信息,可以有效实现实时的推荐以及喜好推送
生产者、消费者模型
生产者消费者模型是针对在任务处理中既要产生数据,又要处理数据这一情景而设计出来的一种解决方案。如果生产者生产资源很快,消费者处理资源的速度很慢,则生产者就必须等待消费者处理完数据才能继续生产,反之同理,这样的话生产者与消费者之间的耦合度较高(依赖关系),导致总体效率较低。
于是通过引入一个交易场所(缓冲区),来解决生产者与消费者之间的强耦合关系,生产者与消费者之间直接通讯,而是通过这个交易场所来间接通讯,将两者的直接关系转变成间接关系,生产者生产完数据直接交给仓库,而消费者要使用则直接从缓冲区取出数据,这样效率就大大的提高。
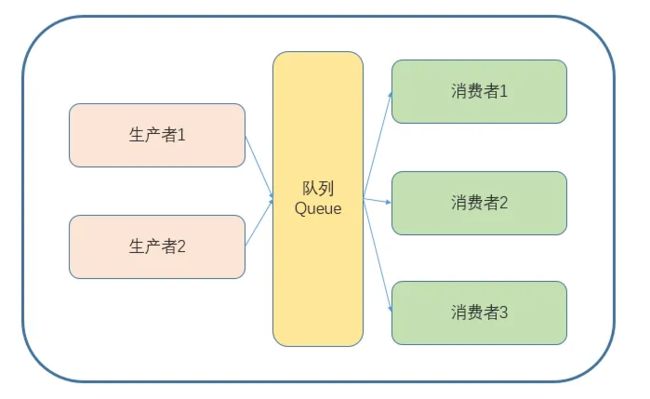
生产者与消费者之间不直接交互
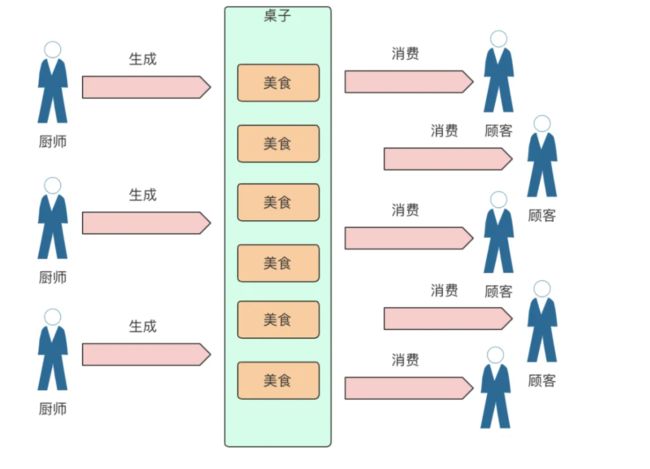
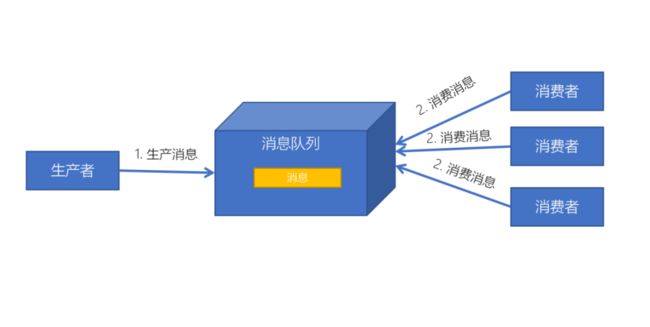
消息队列的两种模式
点对点模式
消息发送者生产消息发送到消息队列中,然后消息接收者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
点对点模式特点:
- 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中)
- 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
发布订阅模式
发布者发送到topic的消息,只有订阅了topic的订阅者才会收到消息。topic实现了发布和订阅,当你发布一个消息,所有订阅这个topic的服务都能得到这个消息,所以从1到N个订阅者都能得到这个消息的拷贝。
发布/订阅模式特点:
- 每个消息可以有多个订阅者;
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息;
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
1-2.kafka简介
什么是kafka
Kafka是由Apache软件基金会开发的一个开源流平台,由Scala和Java编写。Kafka的Apache官网是这样介绍Kakfa的。
Apache Kafka是一个分布式流平台。一个分布式的流平台应该包含3点关键的能力:
-
发布和订阅流数据流,类似于消息队列或者是企业消息传递系统
-
以容错的持久化方式存储数据流
-
处理数据流
kafka应用场景
我们通常将Apache Kafka用在两类程序:
-
建立实时数据管道,以可靠地在系统或应用程序之间获取数据
-
构建实时流应用程序,以转换或响应数据流
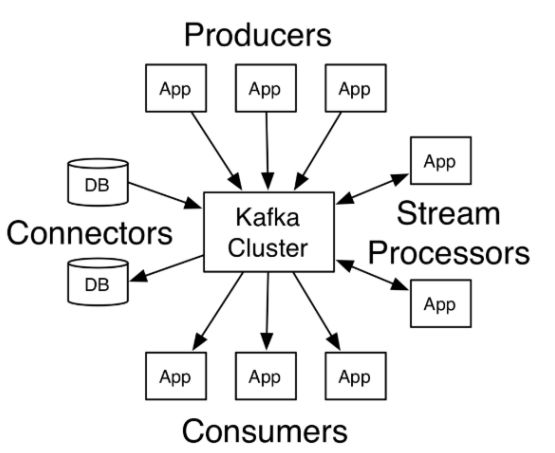
上图,我们可以看到:
Producers:可以有很多的app应用程序,将消息数据放入到Kafka集群中。
Consumers:也可以有很多的app应用程序,将消息数据从Kafka集群中拉取出来。
Connectors:Kafka的连接器可以将数据库中的数据导入到Kafka,也可以将Kafka的数据导出到
数据库中。
- Stream Processors:流处理器可以Kafka中拉取数据,也可以将数据写入到Kafka中。
kafka诞生背景
kafka的诞生,是为了解决linkedin的数据管道问题,起初linkedin采用了ActiveMQ来进行数据交换,大约是在2010年前后,那时的ActiveMQ还远远无法满足linkedin对数据传递系统的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了能够解决这个问题,linkedin决定研发自己的消息传递系统,当时linkedin的首席架构师jay kreps便开始组织团队进行消息传递系统的研发。
1-3.kafka的优势
在大数据技术领域,一些重要的组件、框架都支持Apache Kafka,不论成成熟度、社区、性能、可靠性,Kafka都是非常有竞争力的一款产品。
kafka与竞品的对比表
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|---|
| 所属社区/公司 | Apache | Mozilla Public License | Apache | Apache/Ali |
| 成熟度 | 成熟 | 成熟 | 成熟 | 比较成熟 |
| 生产者-消费者模式 | 支持 | 支持 | 支持 | 支持 |
| 发布-订阅 | 支持 | 支持 | 支持 | 支持 |
| REQUEST-REPLY | 支持 | 支持 | - | 支持 |
| API完备性 | 高 | 高 | 高 | 低(静态配置) |
| 多语言支持 | 支持JAVA优先 | 语言无关 | 支持,JAVA优先 | 支持 |
| 单机呑吐量 | 万级(最差) | 万级 | 十万级 | 十万级(最高) |
| 消息延迟 | - | 微秒级 | 毫秒级 | - |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 高 |
| 消息丢失 | - | 低 | 理论上不会丢失 | - |
| 消息重复 | - | 可控制 | 理论上会有重复 | - |
| 事务 | 支持 | 不支持 | 支持 | 支持 |
| 文档的完备性 | 高 | 高 | 高 | 中 |
| 提供快速入门 | 有 | 有 | 有 | 无 |
| 首次部署难度 | - | 低 | 中 | 高 |
1-4.kafka生态圈
在kafka的主项目外,还有大量的支持工具。在官方项目confluence上,列出了这些工具,包括流处理系统、hadoop聚合接口、监控工具、部署工具等。
https://cwiki.apache.org/confluence/display/KAFKA/Ecosystem
1-5.kafka版本
截止到目前,3.2.1 是最新版本。kafka当前最新的稳定版本是 3.2.1;于2022 年 7 月 29 日发布。
kafka的所有版本下载连接:http://archive.apache.org/dist/kafka/
第2章-kafka3.1搭建部署
本文章介绍kafka3.1.0的安装部署搭建
如果想部署比较早的版本可以点击(2.4.1版)https://blog.csdn.net/wt334502157/article/details/116518259
2-1.环境准备阶段
阿里云申请3台云主机
搭建服务机器资源准备可以自定义,企业测试环境、虚拟机均可。
| 公网IP | 内网IP | 主机名 | 操作系统 | cpu | 内存 |
|---|---|---|---|---|---|
| 8.130.40.212 | 172.28.54.203 | kafka01 | CentOS 7.4 | 2C | 8g |
| 8.130.33.123 | 172.28.54.202 | kafka02 | CentOS 7.4 | 2C | 8g |
| 8.130.41.170 | 172.28.54.201 | kafka03 | CentOS 7.4 | 2C | 8g |
配置hosts解析[ 所有主机 ]
[root@kafka01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# kafka
172.28.54.203 kafka01
172.28.54.202 kafka02
172.28.54.201 kafka03
注意公有云主机有公网IP和内网IP,服务之间配置可以使用内网IP即可,而本地电脑去访问服务时则需要使用公网IP
预先安装好java1.8[ 所有主机 ]
注意:您的本地环境必须安装 Java 8+
[root@kafka01 local]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
2-2.安装zookeeper集群
zookeeper官方下载地址:http://archive.apache.org/dist/zookeeper/
本次安装部署zookeeper-3.5.7
在kafka01上操作
# 创建应用部署目录
[root@kafka01 ~]# mkdir /opt/software
[root@kafka01 ~]# cd /opt/software
# 下载zookeeper安装包
[root@kafka01 software]# wget http://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
# 解压缩包
[root@kafka01 software]# tar -xf apache-zookeeper-3.5.7-bin.tar.gz
# 创建软连接
[root@kafka01 software]# ln -s apache-zookeeper-3.5.7-bin zookeeper
[root@kafka01 software]# cd zookeeper/
[root@kafka01 zookeeper]# mkdir -p zkData
[root@kafka01 zookeeper]# cd zkData/
[root@kafka01 zkData]# echo 1 > myid
[root@kafka01 conf]# cd /opt/software/zookeeper/conf/
[root@kafka01 conf]# cp zoo_sample.cfg zoo.cfg
[root@kafka01 conf]# vim zoo.cfg
# 数据存储路径
dataDir=/opt/software/zookeeper/zkData
# 增加集群信息
server.1=kafka01:2888:3888
server.2=kafka02:2888:3888
server.3=kafka03:2888:3888
[root@kafka01 conf]# vim /etc/profile
# zookeeper
export ZOOKEEPER_HOME=/opt/software/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@kafka01 zookeeper]# source /etc/profile
[root@kafka01 software]# cd /opt/software/
[root@kafka01 software]# scp -r apache-zookeeper-3.5.7-bin/ kafka02:/opt/software/
[root@kafka01 software]# scp -r apache-zookeeper-3.5.7-bin/ kafka03:/opt/software/
[root@kafka01 software]# rm -f /opt/software/apache-zookeeper-3.5.7-bin.tar.gz
【注意1】:
1 . server.1 / server.2 / server.3 中的 1 2 3 对应的就是zkData目录中myid中的值
- server后面的kafka01 / kafka02 / kafka03 没采用ip是因为配置了/etc/hosts的解析
- dataDir=/data/zookeeper路径可以自定义,建议3台服务器尽量配置一样的路径,便于管理
【注意2】:
配置cluster信息解读:
server.A=B:C:D [ server.1=kafka01:2888:3888 ( A=1 , B=kafka01 , C=2888, D=3888)
A 是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在配置的data目录下,这个文件里面数值就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B 是这个服务器的地址;
C 是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D 是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
在kafka02上操作
[root@kafka02 ~]# cd /opt/software/
[root@kafka02 software]# ln -s apache-zookeeper-3.5.7-bin zookeeper
[root@kafka02 software]# echo 2 > zookeeper/zkData/myid
[root@kafka02 software]# vim /etc/profile
# zookeeper
export ZOOKEEPER_HOME=/opt/software/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@kafka02 software]# source /etc/profile
在kafka03上操作
[root@kafka03 ~]# cd /opt/software/
[root@kafka03 software]# ln -s apache-zookeeper-3.5.7-bin zookeeper
[root@kafka03 software]# echo 3 > zookeeper/zkData/myid
[root@kafka03 software]# vim /etc/profile
# zookeeper
export ZOOKEEPER_HOME=/opt/software/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@kafka03 software]# source /etc/profile
启动zookeeper服务 [ 所有机器 ]
[root@kafka01 ~]# zkServer.sh start
[root@kafka02 ~]# zkServer.sh start
[root@kafka03 ~]# zkServer.sh start
检查zookeeper服务运行状态
# kafka01
[root@kafka01 ~]# jps -l
20353 org.apache.zookeeper.server.quorum.QuorumPeerMain
20406 sun.tools.jps.Jps
[root@kafka01 ~]#
[root@kafka01 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/software/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
# kafka02
[root@kafka02 zookeeper]# jps -l
20228 sun.tools.jps.Jps
20173 org.apache.zookeeper.server.quorum.QuorumPeerMain
[root@kafka02 zookeeper]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/software/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
# kafka03
[root@kafka03 conf]# jps -l
20204 sun.tools.jps.Jps
20158 org.apache.zookeeper.server.quorum.QuorumPeerMain
[root@kafka03 conf]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/software/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
2-3.搭建kafka集群
在kafka01上操作
[root@kafka01 ~]# cd /opt/software
#下载kafka3.1.0安装包
[root@kafka01 software]# wget https://archive.apache.org/dist/kafka/3.1.0/kafka_2.13-3.1.0.tgz
[root@kafka01 software]# tar -xzf kafka_2.13-3.1.0.tgz
[root@kafka01 software]# ln -s kafka_2.13-3.1.0 kafka
[root@kafka01 software]# cd kafka
[root@kafka01 kafka]# vim config/server.properties
broker.id=0
listeners=PLAINTEXT://kafka01:9092
log.dirs=/opt/software/kafka/kafka-logs
zookeeper.connect=kafka01:2181,kafka02:2181,kafka03:2181
[root@kafka01 software]# scp -r kafka_2.13-3.1.0/ kafka02:/opt/software/
[root@kafka01 software]# scp -r kafka_2.13-3.1.0/ kafka03:/opt/software/
[root@kafka01 software]# vim /etc/profile
#kafka
export KAFKA_HOME=/opt/software/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@kafka01 software]# source /etc/profile
在kafka02上操作
[root@kafka02 ~]# cd /opt/software
[root@kafka02 software]# ln -s kafka_2.13-3.1.0 kafka
[root@kafka02 software]# cd kafka
[root@kafka02 kafka]# vim config/server.properties
broker.id=1
listeners=PLAINTEXT://kafka02:9092
[root@kafka02 kafka]# vim /etc/profile
#kafka
export KAFKA_HOME=/opt/software/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@kafka02 kafka]# source /etc/profile
在kafka03上操作
[root@kafka03 conf]# cd
[root@kafka03 ~]# cd /opt/software
[root@kafka03 software]# ln -s kafka_2.13-3.1.0 kafka
[root@kafka03 software]# cd kafka
[root@kafka03 kafka]# vim config/server.properties
broker.id=2
listeners=PLAINTEXT://kafka03:9092
[root@kafka03 kafka]# vim /etc/profile
#kafka
export KAFKA_HOME=/opt/software/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@kafka03 kafka]# source /etc/profile
启动kafka服务[ 所有机器 ]
[root@kafka01 ~]# kafka-server-start.sh /opt/software/kafka/config/server.properties &
[root@kafka02 ~]# kafka-server-start.sh /opt/software/kafka/config/server.properties &
[root@kafka03 ~]# kafka-server-start.sh /opt/software/kafka/config/server.properties &
查看kafka服务运行状态
# kafka01
[root@kafka01 ~]# jps -l | grep kafka
20955 kafka.Kafka
[root@kafka01 ~]# netstat -tnlpu|grep 9092
tcp 0 0 172.28.54.203:9092 0.0.0.0:* LISTEN 20955/java
# kafka02
[root@kafka02 ~]# jps -l | grep kafka
20322 kafka.Kafka
[root@kafka02 ~]# netstat -tnlpu|grep 9092
tcp 0 0 172.28.54.202:9092 0.0.0.0:* LISTEN 20322/java
# kafka03
[root@kafka03 ~]# jps -l | grep kafka
20293 kafka.Kafka
[root@kafka03 ~]# netstat -tnlpu|grep 9092
tcp 0 0 172.28.54.201:9092 0.0.0.0:* LISTEN 20293/java
第3章-kafka命令行操作以及kafka tool
3-1.创建topic
# 创建一个topic
[root@kafka01 ~]# kafka-topics.sh --create --topic wangting --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
[root@kafka01 ~]# kafka-topics.sh --create --topic wangting666 --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
[root@kafka01 ~]# kafka-topics.sh --create --topic wangting_666 --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
# topic创建wangting_666时,友情提示不建议使用"_"符号,所以尽量都使用字母以及数字的组合
[2022-09-17 18:03:41,646] INFO Creating topic wangting with configuration {} and initial partition assignment HashMap(0 -> ArrayBuffer(2)) (kafka.zk.AdminZkClient)
Created topic wangting.
3-2.查看某个topic具体信息
# 查看某个topic信息
[root@kafka01 ~]# kafka-topics.sh --describe --topic wangting --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
Topic: wangting TopicId: K9LpoplPTWCEnB6idWWHQw PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: wangting Partition: 0 Leader: 2 Replicas: 2 Isr: 2
3-3.查看所有topic清单
# 查看topic列表清单
[root@kafka01 ~]# kafka-topics.sh --list --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
wangting
wangting666
wangting_666
3-4.在topic中生产和消费消息
# 在其中一个节点使用kafka-console-producer.sh生产消息
[root@kafka01 ~]# kafka-console-producer.sh --topic wangting --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
>
# 在另一个节点使用kafka-console-consumer.sh消费消息
[root@kafka02 ~]# kafka-console-consumer.sh --topic wangting --from-beginning --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
# 开始在生产端尝试输入消息
[root@kafka01 ~]# kafka-console-producer.sh --topic wangting --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
>now is 2022-09-17 19:47
>i am wangting_666
>this is kafka_v3.1.0
>
# 查看消费端的控制台输出情况
[root@kafka02 ~]# kafka-console-consumer.sh --topic wangting --from-beginning --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
now is 2022-09-17 19:47
i am wangting_666
this is kafka_v3.1.0
3-5.Offset Explorer工具(Kafka Tools)
下载安装Kafka Tools
Apache Kafka 的 UI 工具 ,通过官方信息得知:可视化工具现在改名Offset Explorer
Offset Explorer(kafka tools)可视化工具官方下载地址:https://www.kafkatool.com/download.html
找到对应版本下载安装即可
编辑win机本地hosts文件
编辑本地电脑hosts文件:C:\Windows\System32\drivers\etc
增加kafka集群的公网IP的解析并保存
# kafka
8.130.40.212 kafka01
8.130.33.123 kafka02
8.130.41.170 kafka03
配置工具连接信息
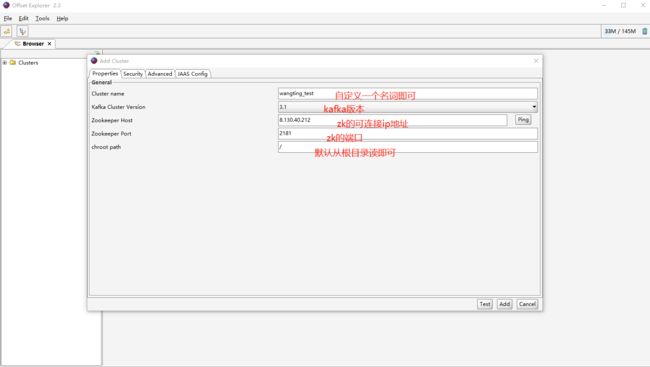
点击Test保存,之后在左边Clusters中就可以看到新加的连接信息
通过界面工具创建topic
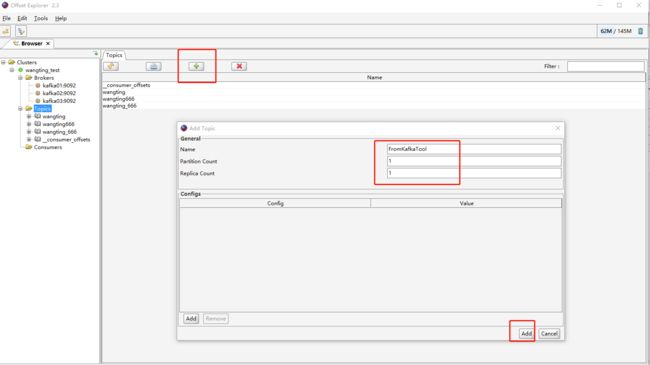
在命令行查看验证是否已经有topic为FromKafkaTool的信息
[root@kafka03 ~]# kafka-topics.sh --describe --topic FromKafkaTool --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
Topic: FromKafkaTool TopicId: lqLPMOQJSoqoZZOwcP_8WA PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: FromKafkaTool Partition: 0 Leader: 1 Replicas: 1 Isr: 1
[root@kafka03 ~]#
第4章-kafka基准测试
基准测试(benchmark testing)是一种测量和评估软件性能指标的活动。我们可以通过基准测试,了解到软件、硬件的性能水平。主要测试负载的执行时间、传输速度、吞吐量、资源占用率等。
4-1.基于1个分区1个副本的基准测试
测试步骤:
- 启动Kafka集群
- 创建一个1个分区1个副本的topic: benchmark
- 同时运行生产者、消费者基准测试程序
- 观察结果
创建topic:benchmark
[root@kafka01 ~]# kafka-topics.sh --create --topic benchmark --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092 --partitions 1 --replication-factor 1
Created topic benchmark.
# 查看topic信息
[root@kafka01 ~]# kafka-topics.sh --describe --topic benchmark --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
Topic: benchmark TopicId: cJN7vW7qQYK_XlPAYlazuQ PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: benchmark Partition: 0 Leader: 2 Replicas: 2 Isr: 2
生产消息基准测试
[root@kafka01 ~]# kafka-producer-perf-test.sh --topic benchmark --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=kafka01:9092,kafka02:9092,kafka03:9092 acks=1
164089 records sent, 32804.7 records/sec (31.28 MB/sec), 718.9 ms avg latency, 940.0 ms max latency.
338462 records sent, 67692.4 records/sec (64.56 MB/sec), 300.9 ms avg latency, 699.0 ms max latency.
351983 records sent, 70396.6 records/sec (67.14 MB/sec), 1.5 ms avg latency, 72.0 ms max latency.
201106 records sent, 40221.2 records/sec (38.36 MB/sec), 14.6 ms avg latency, 2090.0 ms max latency.
374303 records sent, 74860.6 records/sec (71.39 MB/sec), 244.9 ms avg latency, 2129.0 ms max latency.
344476 records sent, 68895.2 records/sec (65.70 MB/sec), 0.6 ms avg latency, 20.0 ms max latency.
331722 records sent, 64200.1 records/sec (61.23 MB/sec), 91.3 ms avg latency, 540.0 ms max latency.
361251 records sent, 72250.2 records/sec (68.90 MB/sec), 13.2 ms avg latency, 267.0 ms max latency.
351073 records sent, 70214.6 records/sec (66.96 MB/sec), 0.5 ms avg latency, 18.0 ms max latency.
337815 records sent, 64260.0 records/sec (61.28 MB/sec), 49.8 ms avg latency, 572.0 ms max latency.
367673 records sent, 73534.6 records/sec (70.13 MB/sec), 40.3 ms avg latency, 390.0 ms max latency.
345800 records sent, 69160.0 records/sec (65.96 MB/sec), 0.7 ms avg latency, 33.0 ms max latency.
336629 records sent, 62792.2 records/sec (59.88 MB/sec), 0.6 ms avg latency, 552.0 ms max latency.
374130 records sent, 74826.0 records/sec (71.36 MB/sec), 43.0 ms avg latency, 555.0 ms max latency.
349857 records sent, 69971.4 records/sec (66.73 MB/sec), 0.5 ms avg latency, 17.0 ms max latency.
5000000 records sent, 65110.101181 records/sec (62.09 MB/sec), 79.74 ms avg latency, 2129.00 ms max latency, 0 ms 50th, 591 ms 95th, 894 ms 99th, 2115 ms 99.9th.
结果分析:
| 测试指标 | 测试数值 |
|---|---|
| 吞吐量 | 65110.101181 records/sec 每秒6.5W条记录 |
| 吞吐速率 | (62.09 MB/sec)每秒约62.09MB数据 |
| 平均延迟时间 | 79.74 ms avg latency |
| 最大延迟时间 | 2129.00 ms max latency |
kafka-producer-perf-test.sh --topic benchmark --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=kafka01:9092,kafka02:9092,kafka03:9092 acks=1kafka-producer-perf-test.sh # 测试脚本
–topic topic benchmark # 测试主题topic为benchmark
–num-records # 总共指定生产数据量(5000000条,不设置则默认5000W条)
–throughput # 指定吞吐量——限流(-1不指定限流)
–record-size # record数据大小(单位字节)
–producer-props bootstrap.servers=192.168.1.20:9092,192.168.1.21:9092,192.168.1.22:9092 # 指定Kafka集群地址
acks=1 # ACK模式
消费消息基准测试
[root@kafka01 ~]# kafka-consumer-perf-test.sh --broker-list kafka01:9092,kafka02:9092,kafka03:9092 --topic benchmark --fetch-size 1048576 --messages 5000000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-09-17 21:23:43:574, 2022-09-17 21:23:58:547, 4768.3716, 318.4647, 5000000, 333934.4153, 423, 14550, 327.7231, 343642.6117
| 测试项目 | 测试数值 |
|---|---|
| data.consumed.in.MB 共计消费的数据 |
4768.3716MB |
| MB.sec 每秒消费的数量 |
318.4647 每秒318MB |
| data.consumed.in.nMsg 共计消费的数量 |
5000000 |
| nMsg.sec 每秒的数量 |
333934.4153 每秒34.36W条 |
4-2.基于3个分区1个副本的基准测试
测试步骤:
- 启动Kafka集群
- 创建一个1个分区1个副本的topic: benchmark
- 同时运行生产者、消费者基准测试程序
- 观察结果
创建topic:benchmark2
[root@kafka01 ~]# kafka-topics.sh --create --topic benchmark2 --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092 --partitions 3 --replication-factor 1
Created topic benchmark2.
[root@kafka01 ~]# kafka-topics.sh --describe --topic benchmark2 --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
Topic: benchmark2 TopicId: P9MPJSyVT2inSU-G1uZhbg PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: benchmark2 Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: benchmark2 Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: benchmark2 Partition: 2 Leader: 1 Replicas: 1 Isr: 1
生产消息基准测试
[root@kafka01 ~]# kafka-producer-perf-test.sh --topic benchmark2 --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=kafka01:9092,kafka02:9092,kafka03:9092 acks=1
149989 records sent, 29997.8 records/sec (28.61 MB/sec), 359.5 ms avg latency, 2125.0 ms max latency.
239592 records sent, 47861.0 records/sec (45.64 MB/sec), 447.2 ms avg latency, 2000.0 ms max latency.
332516 records sent, 66436.8 records/sec (63.36 MB/sec), 250.1 ms avg latency, 1227.0 ms max latency.
340064 records sent, 68012.8 records/sec (64.86 MB/sec), 6.3 ms avg latency, 76.0 ms max latency.
331992 records sent, 66398.4 records/sec (63.32 MB/sec), 2.2 ms avg latency, 65.0 ms max latency.
344061 records sent, 68812.2 records/sec (65.62 MB/sec), 2.4 ms avg latency, 42.0 ms max latency.
339294 records sent, 67858.8 records/sec (64.72 MB/sec), 5.8 ms avg latency, 123.0 ms max latency.
337419 records sent, 67483.8 records/sec (64.36 MB/sec), 2.3 ms avg latency, 45.0 ms max latency.
337766 records sent, 67553.2 records/sec (64.42 MB/sec), 4.9 ms avg latency, 145.0 ms max latency.
339366 records sent, 67873.2 records/sec (64.73 MB/sec), 1.8 ms avg latency, 52.0 ms max latency.
341334 records sent, 68266.8 records/sec (65.10 MB/sec), 1.5 ms avg latency, 45.0 ms max latency.
339645 records sent, 67929.0 records/sec (64.78 MB/sec), 1.8 ms avg latency, 37.0 ms max latency.
336588 records sent, 67317.6 records/sec (64.20 MB/sec), 1.4 ms avg latency, 30.0 ms max latency.
335838 records sent, 67167.6 records/sec (64.06 MB/sec), 80.9 ms avg latency, 634.0 ms max latency.
331386 records sent, 66277.2 records/sec (63.21 MB/sec), 3.4 ms avg latency, 70.0 ms max latency.
5000000 records sent, 63858.591535 records/sec (60.90 MB/sec), 56.74 ms avg latency, 2125.00 ms max latency, 1 ms 50th, 422 ms 95th, 1395 ms 99th, 2006 ms 99.9th.
结果分析:
| 测试指标 | 3分区1个副本 | 对比单分区单副本 |
|---|---|---|
| 吞吐量 | 63858.591535 records/sec | 65110.101181 records/sec |
| 吞吐速率 | 60.90 MB/sec | 62.09 MB/sec |
| 平均延迟时间 | 56.74 ms avg latency | 79.74 ms avg latency |
| 最大延迟时间 | 2125.00 ms max latency | 2129.00 ms max latency |
因为云主机都是低配置,所以分区多和单分区相比,效果没有明显区别,但如果是真实的高配服务器,分区多效率是会有明显提升
消费消息基准测试
[root@kafka01 ~]# kafka-consumer-perf-test.sh --broker-list kafka01:9092,kafka02:9092,kafka03:9092 --topic benchmark2 --fetch-size 1048576 --messages 5000000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-09-17 21:50:39:601, 2022-09-17 21:50:51:955, 4768.3716, 385.9779, 5000000, 404727.2139, 409, 11945, 399.1939, 418585.1821
[root@kafka01 ~]#
结果比对
| 测试指标 | 3分区1个副本 | 对比单分区单副本 |
|---|---|---|
| data.consumed.in.MB 共计消费的数据 |
4768.3716MB | 4768.3716MB |
| MB.sec 每秒消费的数量 |
385.9779 每秒385MB |
318.4647 每秒318MB |
| data.consumed.in.nMsg 共计消费的数量 |
5000000 | 5000000 |
| nMsg.sec 每秒的数量 |
404727.2139 每秒41.85W条 |
333934.4153 每秒34.36W条 |
第5章-Java api操作kafka
5-1.开发环境准备
创建maven工程配置pom依赖
groupid
- cn.wangting
artifactId
- kafka_test
pom配置文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>cn.wangtinggroupId>
<artifactId>kafka_testartifactId>
<version>1.0-SNAPSHOTversion>
<repositories>
<repository>
<id>centralid>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<releases>
<enabled>trueenabled>
releases>
<snapshots>
<enabled>trueenabled>
<updatePolicy>alwaysupdatePolicy>
<checksumPolicy>failchecksumPolicy>
snapshots>
repository>
repositories>
<dependencies>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>3.1.0version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-ioartifactId>
<version>1.3.2version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.6version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.16version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.7.0version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
plugins>
build>
project>
创建package包和class实验类
创建包cn.wangting.kafka,并创建KafkaProducerTest类
并且println(“hello kafka”)测试是否可以正常运行
导入log4j
导入log4j.properties文件:
下载地址:https://osswangting.oss-cn-shanghai.aliyuncs.com/kafka/log4j.properties
将log4j.properties配置文件放入到项目的resources目录中
5-2.java api开发同步生产者消息到kafka中
KafkaProducerTest代码:
package cn.wangting.kafka;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class KafkaProducerTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "kafka01:9092,kafka02:9092,kafka03:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
// 3. 调用send发送1-100消息到指定Topic test
for(int i = 0; i < 100; ++i) {
try {
// 获取返回值Future,该对象封装了返回值
Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>("wangting", null, i + ""));
// 调用一个Future.get()方法等待响应
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
}
执行代码后控制台输出:
"C:\Program Files\Java\jdk1.8.0_192\bin\java.exe" "-javaagent:D:\Program Files\JetBrains\IntelliJ IDEA 2020.1\lib\idea_rt.jar=11533:D:\Program Files\JetBrains\IntelliJ IDEA 2020.1\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program ...
...
INFO - Kafka version: 3.1.0
INFO - Kafka commitId: 37edeed0777bacb3
INFO - Kafka startTimeMs: 1663426544939
INFO - [Producer clientId=producer-1] Resetting the last seen epoch of partition wangting-0 to 0 since the associated topicId changed from null to K9LpoplPTWCEnB6idWWHQw
INFO - [Producer clientId=producer-1] Cluster ID: m9Q1ky6jT2-UdtVA_AoUsw
Process finished with exit code 0
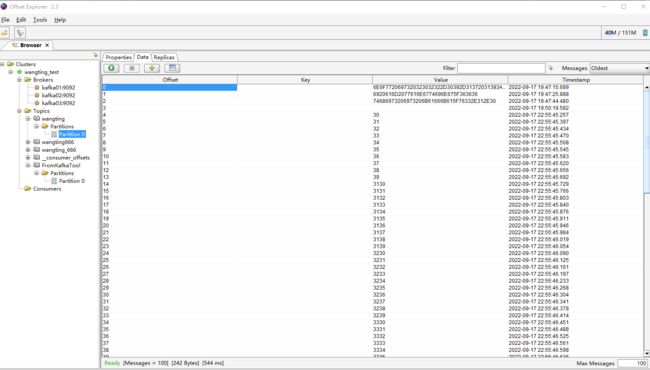
通过界面工具去验证是否有数据写入
5-3.java api开发从kafka的topic中消费消息
从 wangting topic中,将消息都消费,并将记录的offset、key、value打印出来
在cn.wangting.kafka包下创建KafkaConsumerTest类
KafkaConsumerTest代码:
package cn.wangting.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerTest {
public static void main(String[] args) throws InterruptedException {
// 1.创建Kafka消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "kafka01:9092,kafka02:9092,kafka03:9092");
// 自动提交offset
props.setProperty("enable.auto.commit", "true");
// 自动提交offset的时间间隔
props.setProperty("auto.commit.interval.ms", "1000");
// 拉取的key、value数据的
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 2.创建Kafka消费者
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(props);
// 3. 订阅要消费的主题
// 指定消费者从哪个topic中拉取数据
kafkaConsumer.subscribe(Collections.singletonList("wangting"));
// 4.使用一个while循环,不断从Kafka的topic中拉取消息
while(true) {
// Kafka的消费者一次拉取一批的数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));
// 5.将将记录(record)的offset、key、value都打印出来
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
// 主题
String topic = consumerRecord.topic();
// offset:这条消息处于Kafka分区中的哪个位置
long offset = consumerRecord.offset();
// key\value
String key = consumerRecord.key();
String value = consumerRecord.value();
System.out.println("topic: " + topic + " offset:" + offset + " key:" + key + " value:" + value);
}
Thread.sleep(1000);
}
}
}
执行效果:
...
...
topic: wangting offset:188 key:null value:84
topic: wangting offset:189 key:null value:85
topic: wangting offset:190 key:null value:86
topic: wangting offset:191 key:null value:87
topic: wangting offset:192 key:null value:88
topic: wangting offset:193 key:null value:89
topic: wangting offset:194 key:null value:90
topic: wangting offset:195 key:null value:91
topic: wangting offset:196 key:null value:92
topic: wangting offset:197 key:null value:93
topic: wangting offset:198 key:null value:94
topic: wangting offset:199 key:null value:95
topic: wangting offset:200 key:null value:96
topic: wangting offset:201 key:null value:97
topic: wangting offset:202 key:null value:98
topic: wangting offset:203 key:null value:99
成功获取到消息队列中的数据
5-4.java api异步使用回调函数方法生产消息
如果我们想获取生产者消息是否成功,或者成功生产消息到Kafka中后,执行一些其他动作。此时,可以很方便地使用带有回调函数来发送消息。
需求:
-
在发送消息出现异常时,能够及时打印出异常信息
-
在发送消息成功时,打印Kafka的topic名字、分区id、offset
在cn.wangting.kafka包下创建KafkaProducerTest2类
package cn.wangting.kafka;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class KafkaProducerTest2 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "kafka01:9092,kafka02:9092,kafka03:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(props);
int MAX = 10000000;
// 3. 发送1-100的消息到指定的topic中
for(int i = 1000000; i < MAX; ++i) {
// 二、使用异步回调的方式发送消息
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("wangting666", null, i + "");
kafkaProducer.send(producerRecord, (metadata, exception) -> {
// 1. 判断发送消息是否成功
if(exception == null) {
// 发送成功
// 主题
String topic = metadata.topic();
// 分区id
int partition = metadata.partition();
// 偏移量
long offset = metadata.offset();
System.out.println("topic:" + topic + " 分区id:" + partition + " 偏移量:" + offset);
}
else {
// 发送出现错误
System.out.println("生产消息出现异常!");
// 打印异常消息
System.out.println(exception.getMessage());
// 打印调用栈
System.out.println(exception.getStackTrace());
}
});
Thread.sleep(1000);
}
// 4.关闭生产者
kafkaProducer.close();
}
}
控制台输出内容:
topic:wangting666 分区id:0 偏移量:221
topic:wangting666 分区id:0 偏移量:222
topic:wangting666 分区id:0 偏移量:223
topic:wangting666 分区id:0 偏移量:224
topic:wangting666 分区id:0 偏移量:225
topic:wangting666 分区id:0 偏移量:226
...
...
打开界面管理工具验证消息
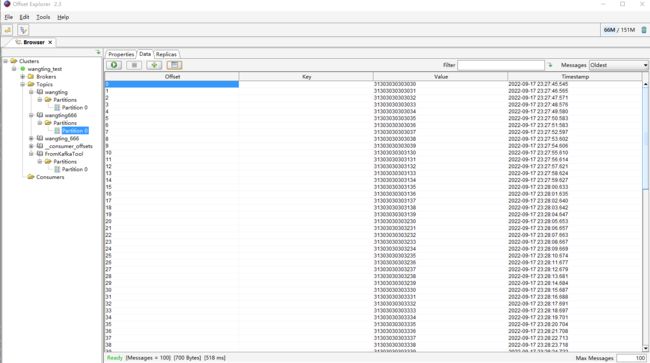
第6章-kafka架构
6-1.Broker
在kafka里面,broker是消息的中介,生产者producer往broker里面指定的topic中写消息,消费者consumer从broker里面拉取指定topic的消息,然后进行业务处理,broker在中间起到一个代理保存消息的中转站。
- 一个Kafka的集群通常由多个broker组成,这样才能实现负载均衡、以及容错
- broker是无状态(Sateless)的,它们是通过ZooKeeper来维护集群状态
- 一个Kafka的broker每秒可以处理数十万次读写,每个broker都可以处理TB消息而不影响性能
- 一个独立的kafka服务器就对应一个broker
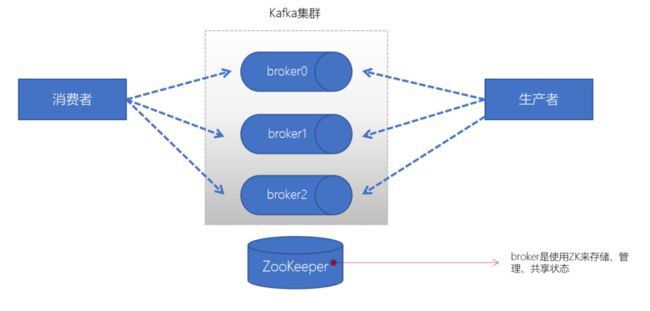
6-2.Zookeeper
- ZK用来管理和协调broker,并且存储了Kafka的元数据(例如:有多少topic、partition、consumer)
- ZK服务主要用于通知生产者和消费者Kafka集群中有新的broker加入、或者Kafka集群中出现故障的broker。
通过命令行进入到zookeeper可以查看kafka的元数据
[root@kafka01 ~]# zkCli.sh
Connecting to localhost:2181
...
...
Welcome to ZooKeeper!
JLine support is enabled
# topics信息
[zk: localhost:2181(CONNECTED) 4] ls /brokers/topics
[FromKafkaTool, __consumer_offsets, benchmark, benchmark2, wangting, wangting666, wangting_666]
quit退出
6-3.Producer(生产者)
producer生产者负责将数据推送给broker的topic,是kafka中消息的产生方,产生消息并提交给kafka集群完成消息的持久化,这个过程中主要涉及ProducerRecord对象的构建、分区选择、元数据的填充、ProducerRecord对象的序列化、进入消息缓冲池、完成消息的发送、接受broker的响应
ProducerRecord:
ProducerRecord 对象比较核心的信息有:topic、partition(这个信息是根据分区选择器来确定的)、key、value、timestamp
6-4.Consumer(消费者)
consumer消费者负责从broker的topic中拉取数据,并自己进行处理
6-5.Consumer group(消费者组)
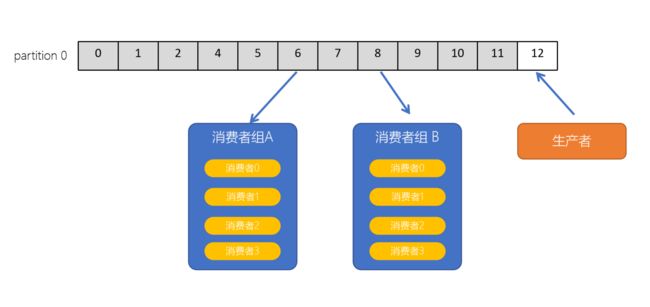
- consumer group是kafka提供的可扩展且具有容错性的消费者机制
- 一个消费者组可以包含多个消费者
- 一个消费者组有一个唯一的ID(group Id)
- 组内的消费者一起消费主题的所有分区数据
当一个Topic有两个消费者或者更多时,而只有一个partition时,只有一个消费者程序能够拉取到消息。想要让两个消费者同时消费消息,必须要给这个Topic主题,添加一个分区,也就是说分区数量小于消费者数量时,会有消费者消费不到数据
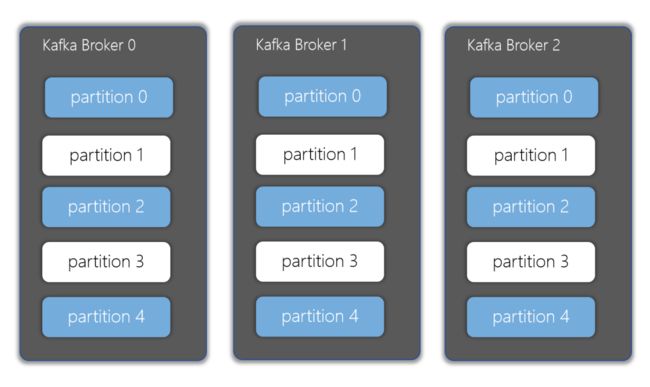
6-6.Partitions(分区)
partition(分区)是kafka的一个核心概念,kafka将1个topic分成了一个或多个分区,每个分区在物理上对应一个目录,分区目录下存储的是该分区的日志段(segment),包括日志的数据文件和两个索引文件。然后每个分区又对应一个或多个副本,由一个ISR列表来维护。
注意:分区数可以大于节点数,但是副本数不能大于节点数,因为副本需要分不到不同的节点上,才能达到备份的目的。
# 例如创建benchmark2主题时设置为3个分区,创建wangting_666主题时设置为1个分区
[root@kafka01 ~]# ll /opt/software/kafka/kafka-logs | grep benchmark2
drwxr-xr-x 2 root root 4096 Sep 17 21:38 benchmark2-0
[root@kafka01 ~]# ll /opt/software/kafka/kafka-logs | grep wangting_666
drwxr-xr-x 2 root root 4096 Sep 17 19:02 wangting_666-0
[root@kafka01 ~]#
[root@kafka02 ~]# ll /opt/software/kafka/kafka-logs | grep benchmark2
drwxr-xr-x 2 root root 4096 Sep 17 21:38 benchmark2-2
[root@kafka02 ~]# ll /opt/software/kafka/kafka-logs | grep wangting_666
[root@kafka02 ~]#
[root@kafka03 ~]# ll /opt/software/kafka/kafka-logs | grep benchmark2
drwxr-xr-x 2 root root 4096 Sep 17 21:38 benchmark2-1
[root@kafka03 ~]# ll /opt/software/kafka/kafka-logs | grep wangting_666
[root@kafka03 ~]#
# 可以看出来wangting_666主题只对应在kafka01上有wangting_666-0
# 而benchmark2主题在kafka01上有benchmark2-0,在kafka02上有benchmark2-2,在kafka03上有benchmark2-1
6-7.Replicas(副本)
replicas(副本)就是一个只能追加写消息的提交日志。根据 Kafka 副本机制的定义,同一个分区下的所有副本保存有相同的消息序列,这些副本分散保存在不同的 Broker 上,从而能够对抗部分 Broker 宕机带来的数据不可用。
- 副本可以确保某个服务器出现故障时,确保数据依然可用
- 在Kafka中,一般都会设计副本的个数>1
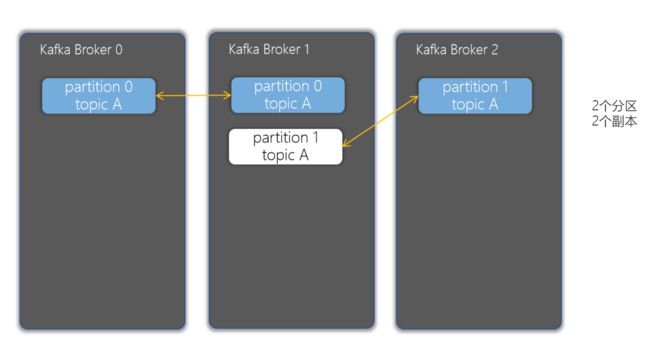
6-8.Topic(主题)
在 Kafka 中,Topic可以认为是一个消息集合。每条消息发送到 Kafka 集群的消息都有一个类别。物理上来说,不同的 Topic 的消息是分开存储的,每个 Topic 可以有多个生产者向它发送消息,也可以有多个消费者去消费其中的消息。
- Topic主题是一个逻辑概念,用于生产者发布数据,消费者拉取数据
- Kafka中的主题必须要有标识符,而且是唯一的,Kafka中可以有任意数量的主题,没有数量上的限制
- 在主题中的消息是有结构的,一般一个主题包含某一类消息
- 一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
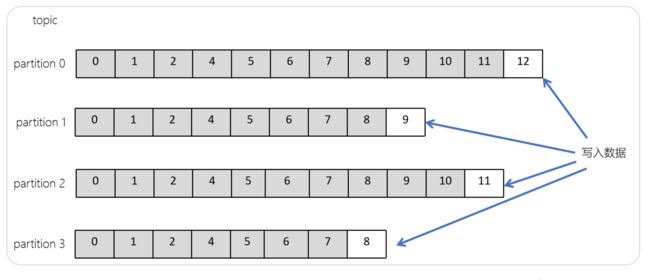
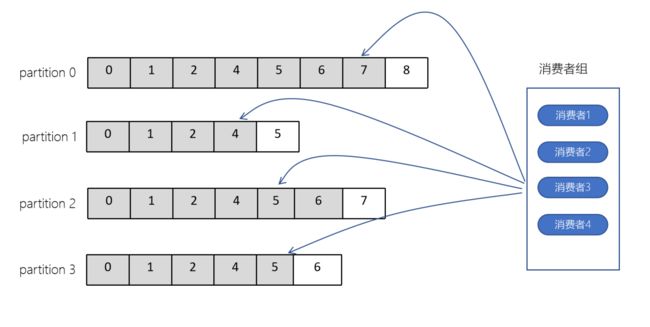
6-9.Offset(偏移量)
- offset记录着下一条将要发送给Consumer的消息的序号
- 默认Kafka将offset存储在ZooKeeper中
- 在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都是有一个递增的id。这个就是偏移量offset
- 偏移量在分区中才是有意义的。在分区之间,offset是没有任何意义的
[root@kafka01 ~]# zkCli.sh
Connecting to localhost:2181
[zk: localhost:2181(CONNECTED) 0] ls /brokers/topics
[FromKafkaTool, __consumer_offsets, benchmark, benchmark2, wangting, wangting666, wangting_666]
[zk: localhost:2181(CONNECTED) 2] ls /brokers/topics/__consumer_offsets/partitions
[0, 1, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 3, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 4, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 5, 6, 7, 8, 9]
[zk: localhost:2181(CONNECTED) 3]
生产端offset
Kafka接收到生产者发送的消息实际上是以日志文件的形式保存在对应分区的磁盘上。每条消息都有一个offset值来表示它在分区中的位置。每次写入都是追加到文件的末尾
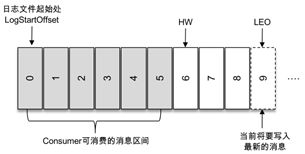
上图代表一个日志文件,这个日志文件中有 9 条消息,第一条消息的 offset( logStartOffset)为 0,最后一条消息的 offset 为 8,LEO(Log End Offset)为 9 ,代表下一条待写入的消息。日志文件的 HW(Low Watermark)为 6,表示消费者只能拉取到 offset 在 0 至 5 之间的消息, 而 offset 为 6 的消息对消费者而言是不可见的
消费端offset
消费者在消费时,也维护一个offset,表示消费到分区中的某个消息所在的位置
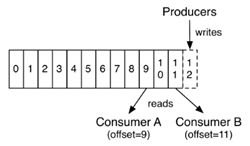
ConsumerA的offset=9,表示ConsumerA已经消费完offset为8的那条数据,提交的offset值为9,下次消费从offset为9的数据开始消费
第7章-生产者幂等性以及事务
7-1.Kafka幂等性
Kafka分生产者producer和消费者consumer,生产者负责把消息写入topic,topic类似于离线的hive表,生产者会记录自己写到哪个位置,这个位置信息就是生产者的offset,并不断地追加写入,更新offset信息,同样消费者也会有消费者自己的状态,一个消费者会根据自己的程序消费数据情况记录当前消费的位置,即消费的offset,与生产者的offset以及其他消费者的offset互相独立。
生产者在发送消息的时候难免会有数据重复,这时候如何来保障呢?生产者有重试机制,在出现故障,网络异常等情况,导致消息重复发送。而Kafka的“幂等性”,可以保证即使有重复消息发送也只写入一条有效消息。
幂等性简介
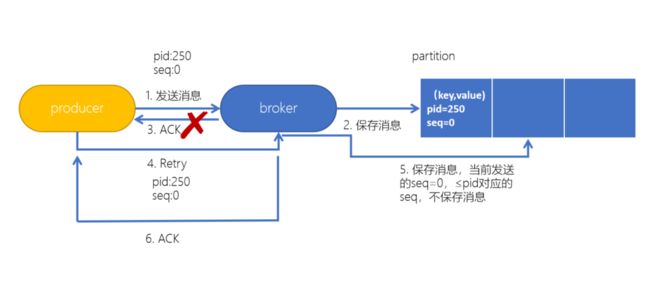
当生产者发送消息给Broker时,Broker接收到消息并追加到消息流。这时Broker会返回Ack信号给生产者时,发生异常导致生产者接收Ack信号失败。
对于生产者来说,会触发重试机制,再次发送消息,但是,由于引入了幂等性,在每条消息中附带了生产者id和SequenceNumber。相同的PID(每个新的Producer初始化时,会被分配一个唯一的ProducerID,这个ProducerID对客户端使用者是不可见的。)和相应的SequenceNumber(可以理解成生产者的offset)发送给Broker,而之前Broker缓存过之前发送的相同的消息,那么在消息流中的消息就只有一条,不会出现重复发送的情况。
简单来说有点像传统数据库的事务,也就是追加数据和offset更新必须都成功,才能都算成功。幂等性可以较好的保障数据重复写入和数据丢失问题。
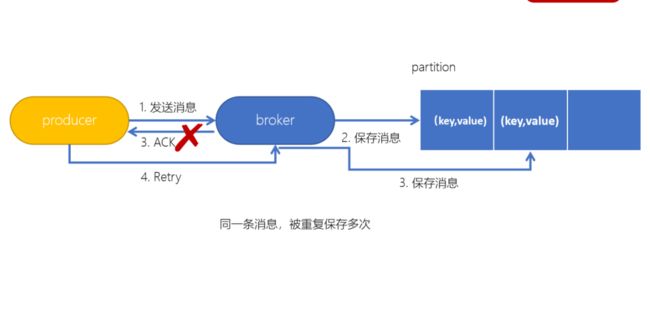
生产者幂等性
在生产者生产消息时,如果出现retry时,有可能会一条消息被发送了多次,如果Kafka不具备幂等性的,那么就有可能会在partition中保存多条一模一样的消息
配置幂等性
# 命令行中配置,执行脚本命令中加入如下参数
enable.idempotence=true
// 代码中配置
props.put("enable.idempotence",true);
7-2.Kafka事务
Kafka事务是2017年Kafka 0.11.0.0引入的新特性。类似于数据库的事务。Kafka事务指的是生产者生产消息以及消费者提交offset的操作可以在一个原子操作中,要么都成功,要么都失败。尤其是在生产者、消费者并存时,事务的保障尤其重要。(consumer-transform-producer模式)
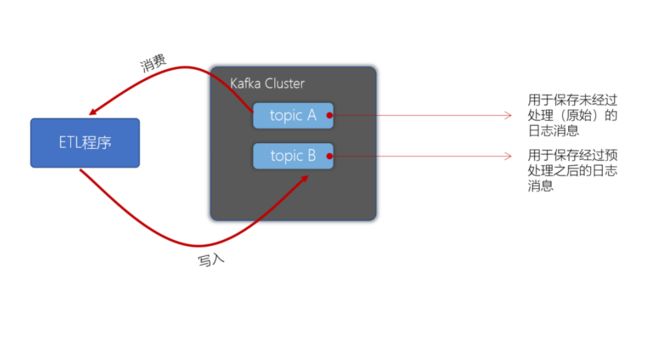
Producer接口中定义了以下5个事务相关方法:
-
initTransactions(初始化事务):要使用Kafka事务,必须先进行初始化操作
-
beginTransaction(开始事务):启动一个Kafka事务
-
sendOffsetsToTransaction(提交偏移量):批量地将分区对应的offset发送到事务中,方便后续一块提交
-
commitTransaction(提交事务):提交事务
-
abortTransaction(放弃事务):取消事务
第8章-分区和副本机制
8-1.生产者分区写入策略
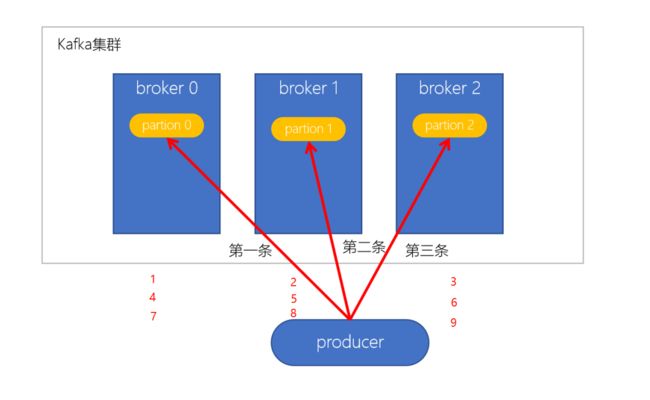
轮询策略
-
默认的策略,也是使用最多的策略,可以最大限度保证所有消息平均分配到一个分区
-
如果在生产消息时,key为null,则使用轮询算法均衡地分配分区
随机策略
随机策略,每次都随机地将消息分配到每个分区。在较早的版本,默认的分区策略就是随机策略,也是为了将消息均衡地写入到每个分区。但后续轮询策略表现更佳,所以基本上很少会使用随机策。
按key分配策略
按key分配策略,有可能会出现「数据倾斜」,例如:某个key包含了大量的数据,因为key值一样,那么所有的数据将都分配到一个分区中,造成该分区的消息数量远大于其他的分区。
乱序问题
轮询策略、随机策略都会导致一个问题,生产到Kafka中的数据是乱序存储的。而按key分区可以一定程度上实现数据有序存储——也就是局部有序,但这又可能会导致数据倾斜,所以在实际生产环境中要结合实际情况来做取舍。
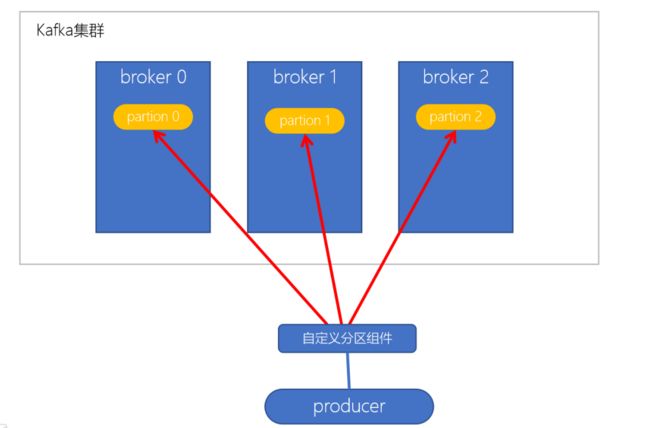
自定义分区策略
用户自行定义分配的策略机制
8-2.消费者组Rebalance机制
Rebalance再均衡
Kafka中的Rebalance称之为再均衡,是Kafka中确保Consumer group下所有的consumer如何达成一致,分配订阅的topic的每个分区的机制
-
消费者组中consumer的个数发生变化。例如:有新的consumer加入到消费者组,或者是某个consumer停止
-
订阅的topic个数发生变化
- 消费者可以订阅多个主题,假设当前的消费者组订阅了三个主题,但有一个主题突然被删除了,此时也需要发生再均衡
-
订阅的topic分区数发生变化
Rebalance机制不良影响
- 发生Rebalance时,consumer group下的所有consumer都会协调在一起共同参与,Kafka使用分配策略尽可能达到最公平的分配
- Rebalance过程会对consumer group产生非常严重的影响,Rebalance的过程中所有的消费者都将停止工作,直到Rebalance完成
8-3.消费者分区分配策略
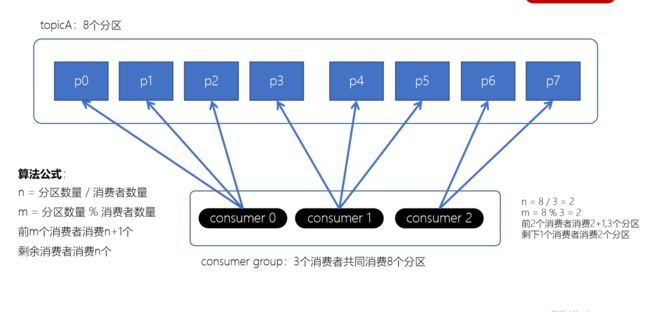
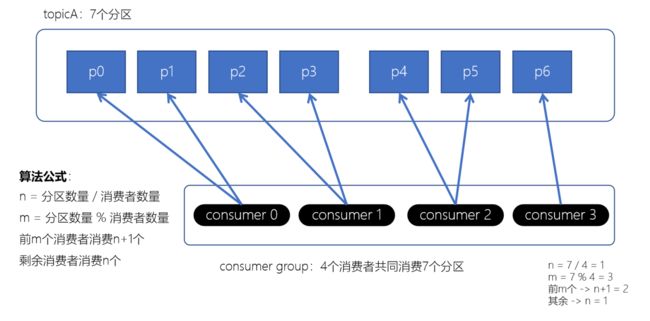
Range范围分配策略
Range范围分配策略是Kafka默认的分配策略,它可以确保每个消费者消费的分区数量是均衡的。
注意:Rangle范围分配策略是针对每个Topic的
算法公式
n = 分区数量 / 消费者数量
m = 分区数量 % 消费者数量
前m个消费者消费n+1个
剩余消费者消费n个
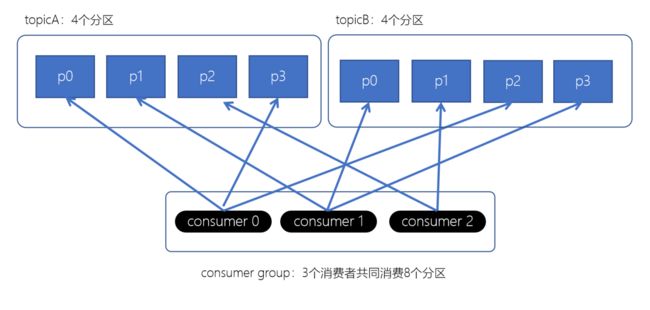
RoundRobin轮询策略
RoundRobinAssignor轮询策略是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序(topic和分区的hashcode进行排序),然后通过轮询方式逐个将分区以此分配给每个消费者
Stricky粘性分配策略
-
分区分配尽可能均匀
-
在发生rebalance的时候,分区的分配尽可能与上一次分配保持相同
没有发生rebalance时,Striky粘性分配策略和RoundRobin分配策略类似
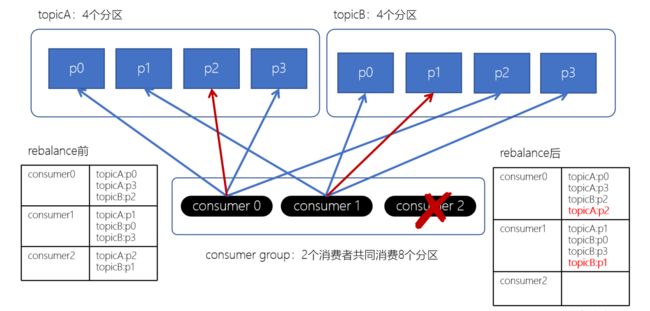
Striky粘性分配策略,保留rebalance之前的分配结果。这样,只是将原先consumer2负责的两个分区再均匀分配给consumer0、consumer1。这样可以明显减少系统资源的浪费,例如:之前consumer0、consumer1之前正在消费某几个分区,但由于rebalance发生,导致consumer0、consumer1需要重新消费之前正在处理的分区,导致不必要的系统开销。(例如:某个事务正在进行就必须要取消了)
8-4.副本机制
副本的目的就是冗余备份,当某个Broker上的分区数据丢失时,依然可以保障数据可用。因为在其他的Broker上的副本是可用的
producer的acks参数
对副本关系较大的就是,producer配置的acks参数,acks参数表示当生产者生产消息的时候,写入到副本的要求严格程度。它决定了生产者如何在性能和可靠性之间做取舍
// props.put("acks", "all");为定义副本写入严格级别程度
Properties props = new Properties();
props.put("bootstrap.servers", "kafka01:9092,kafka02:9092,kafka03:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
acks为0策略
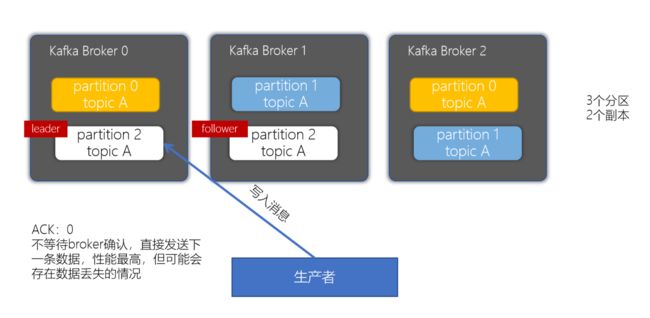
当生产者的ACK配置为0时,生产者写入消息不等待broker确认,直接发送下一条消息数据,这种策略性能最高,但也存在数据丢失的可能性
acks为1策略
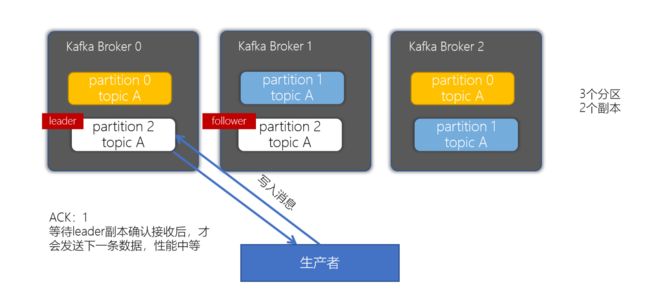
当生产者的ACK配置为1时,生产者会等待leader副本确认接收后,才会发送下一条数据,性能中等。
acks为-1或者all策略
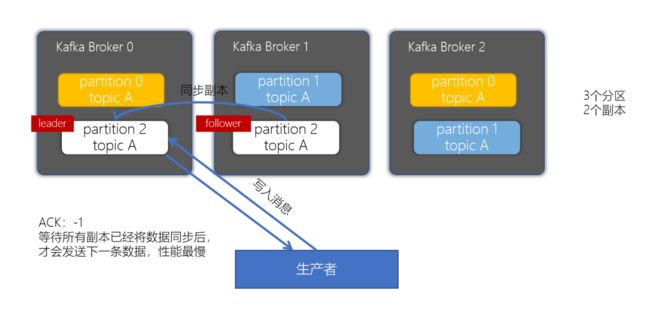
当生产者的ACK配置为-1或者all时,生产者会等待所有副本已经将数据同步完成后,才会发送下一条数据,性能最慢
第9章-监控工具kafka-eagle(EFAK)
9-1.kafka-eagle简介(EFAK)
在开发工作中,当业务前提不复杂时,可以使用Kafka命令来进行一些集群的管理工作。但如果业务变得复杂,例如:我们需要增加group、topic分区,此时,我们再使用命令行就感觉很不方便,此时,如果使用一个可视化的工具帮助我们完成日常的管理工作,将会大大提高对于Kafka集群管理的效率,而且我们使用工具来监控消费者在Kafka中消费情况。
早期,要监控Kafka集群我们可以使用Kafka Monitor以及Kafka Manager,但随着我们对监控的功能要求、性能要求的提高,这些工具已经无法满足。
Kafka Eagle是一款结合了目前大数据Kafka监控工具的特点,重新研发的一块开源免费的Kafka集群优秀的监控工具。它可以非常方便的监控生产环境中的offset、lag变化、partition分布、owner等。
官方地址:https://www.kafka-eagle.org/
极力推荐此管理工具
9-2.安装kafka-eagle
注意:
安装使用kafka-eagle工具需要有java环境
[root@kafka01 software]# java -version
java version “1.8.0_211”
Java™ SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot™ 64-Bit Server VM (build 25.211-b12, mixed mode)
[root@kafka01 ~]# cd /opt/software/
[root@kafka01 software]# wget https://github.com/smartloli/kafka-eagle-bin/archive/v3.0.1.tar.gz
[root@kafka01 software]# tar -xf v3.0.1.tar.gz
[root@kafka01 software]# ln -s kafka-eagle-bin-3.0.1 eagle
[root@kafka01 software]# cd eagle/
[root@kafka01 eagle]# ll
total 87840
-rw-rw-r-- 1 root root 89947836 Sep 6 12:45 efak-web-3.0.1-bin.tar.gz
[root@kafka01 eagle]# tar -xf efak-web-3.0.1-bin.tar.gz
[root@kafka01 eagle]# cd efak-web-3.0.1
[root@kafka01 eagle]# mv efak-web-3.0.1 efak-web
[root@kafka01 efak-web]# vim /etc/profile
# efak
export KE_HOME=/opt/software/eagle/efak-web
export PATH=$PATH:$KE_HOME/bin
[root@kafka01 efak-web]# source /etc/profile
[root@kafka01 efak-web]# cd /opt/software/eagle/efak-web/conf/
[root@kafka01 conf]# vim system-config.properties
efak.zk.cluster.alias=cluster1
cluster1.zk.list=kafka01:2181,kafka02:2181,kafka03:2181
#cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181
efak.metrics.charts=true
efak.metrics.retain=30
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://47.64.11.13:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=123456
[root@kafka01 ~]# ke.sh start
Welcome to
______ ______ ___ __ __
/ ____/ / ____/ / | / //_/
/ __/ / /_ / /| | / ,<
/ /___ / __/ / ___ | / /| |
/_____/ /_/ /_/ |_|/_/ |_|
( Eagle For Apache Kafka庐 )
Version v3.0.1 -- Copyright 2016-2022
*******************************************************************
* EFAK Service has started success.
* Welcome, Now you can visit 'http://172.28.54.203:8048'
* Account:admin ,Password:123456
*******************************************************************
* <Usage> ke.sh [start|status|stop|restart|stats] </Usage>
* <Usage> https://www.kafka-eagle.org/ </Usage>
*******************************************************************
根据输出可以看到打开的地址和用户密码
注意远程访问需要有公网IP地址,内网访问,则需要内网ip互联互通
通过本地访问:http://kafka01:8048打开
通过Overview- TV Dashboard可以看到炫酷的大屏监控
9-3.kafka度量指标
topic list
点击Topic下的List菜单,就可以展示当前Kafka集群中的所有topic
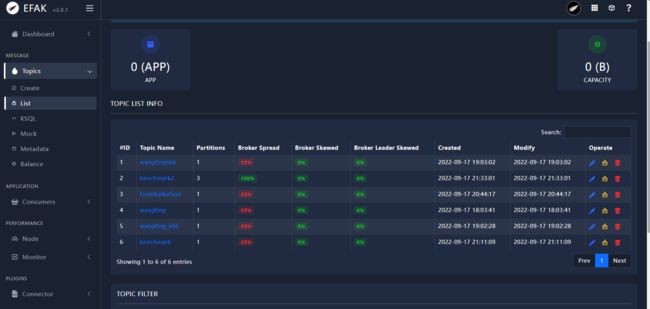
| 指标 | 意义 |
|---|---|
| Topic Name | 当前的Topic名称 |
| Partitions | 对应Topic的分区数 |
| Brokers Spread | broker使用率,红色提醒为使用率较低 |
| Brokers Skew | 分区是否有倾斜 |
| Brokers Leader Skew | leader partition是否存在倾斜 |
| Created | Topic的创建时间 |
| Modify | Topic的最近一次修改时间 |
创建Topic
红色信息仅为提示,并非报错以及警告
[root@kafka01 ~]# kafka-topics.sh --list --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
FromKafkaTool
__consumer_offsets
benchmark
benchmark2
wangting
wangting0918
wangting666
wangting_666
Topic信息查看
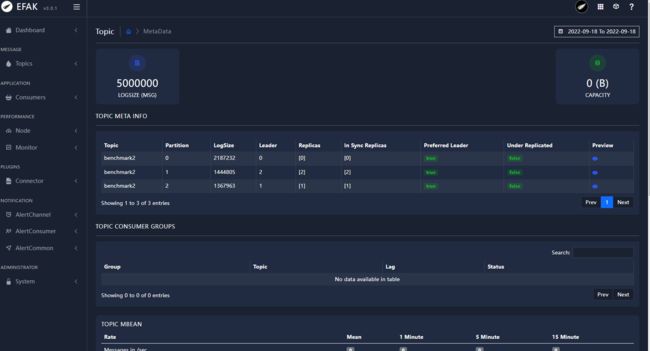
从工具可以看到Topic主题benchmark2的partiton0分区信息Leader在Broker0上,partiton1分区信息Leader在Broker2上,而partiton2分区信息Leader在Broker1上
ksql
KSQL 是 Apache Kafka 的开源流 SQL 引擎。 它为 Kafka 的流处理提供了一个简单而完整的 SQL 界面;不需要再用编程语言(如 Java 或 Python )编写代码。 KSQL 是分布式、可扩展、可靠的和实时的,支持多种流式操作,包括聚合(aggregate)、连接(join)、时间窗口(window)、会话(session)等等。基于 Apache 2.0 协议开源。
KSQL 的两个核心概念是流(Stream)和表(Table),它将流和表集成在一起,允许将代表当前状态的表与代表当前发生事件的流连接在一起
界面工具使用zookeeper命令行
第10章-kafka原理介绍
10-1.分区的leader与follower
leader、follower
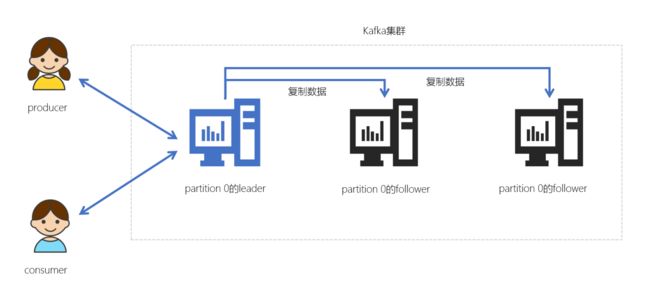
在Kafka中,每个topic都可以配置多个分区以及多个副本。每个分区都有一个leader以及0个或者多个follower,在创建topic时,Kafka会将每个分区的leader均匀地分配在每个broker上。我们正常使用kafka是感觉不到leader、follower的存在的。但其实,所有的读写操作都是由leader处理,而所有的follower都复制leader的日志数据文件,如果leader出现故障时,follower就会被选举为leader
- Kafka中的leader负责处理读写操作,而follower只负责副本数据的同步
- 如果leader出现故障,其他follower会被重新选举为leader
- follower像一个consumer一样,拉取leader对应分区的数据,并保存到日志数据文件中
通过命令行查看某个Topic的分区信息:
[root@kafka01 ~]# kafka-topics.sh --describe --topic benchmark2 --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092
Topic: benchmark2 TopicId: P9MPJSyVT2inSU-G1uZhbg PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: benchmark2 Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: benchmark2 Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: benchmark2 Partition: 2 Leader: 1 Replicas: 1 Isr: 1
或者通过EFAK界面查看Topic
AR、ISR、OSR
在实际环境中,leader有可能会出现一些故障,所以Kafka一定会选举出新的leader。在讲解leader选举之前,我们先要明确几个概念。Kafka中,把follower可以按照不同状态分为三类——AR、ISR、OSR
- 分区的所有副本称为 「AR」(Assigned Replicas——已分配的副本)
- 所有与leader副本保持一定程度同步的副本(包括 leader 副本在内)组成 「ISR」(In-Sync Replicas——在同步中的副本)
- 由于follower副本同步滞后过多的副本(不包括 leader 副本)组成 「OSR」(Out-of-Sync Replias)
- AR = ISR + OSR
- 正常情况下,所有的follower副本都应该与leader副本保持同步,即AR = ISR,OSR集合为空。
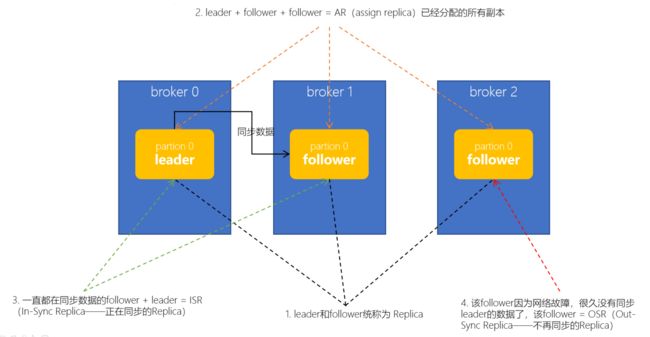
Leader选举
leader在崩溃后,Kafka又从其他的follower中快速选举出来了leader
Controller
- Kafka启动时,会在所有的broker中选择一个controller
- 前面leader和follower是针对partition,而controller是针对broker的
- 创建topic、或者添加分区、修改副本数量之类的管理任务都是由controller完成的
- Kafka分区leader的选举,也是由controller决定的
Controller的选举
- 在Kafka集群启动的时候,每个broker都会尝试去ZooKeeper上注册成为Controller(ZK临时节点)
- 但只有一个竞争成功,其他的broker会注册该节点的监视器
- 一点该临时节点状态发生变化,就可以进行相应的处理
- Controller也是高可用的,一旦某个broker崩溃,其他的broker会重新注册为Controller
Controller选举partition leader
- 所有Partition的leader选举都由controller决定
- controller会将leader的改变直接通过RPC的方式通知需为此作出响应的Broker
- controller读取到当前分区的ISR,只要有一个Replica还幸存,就选择其中一个作为leader否则,则任意选这个一个Replica作为leader
- 如果该partition的所有Replica都已经宕机,则新的leader为-1
为什么不能通过ZK的方式来选举partition的leader?
- Kafka集群如果业务很多的情况下,会有很多的partition
- 假设某个broker宕机,就会出现很多的partiton都需要重新选举leader
- 如果使用zookeeper选举leader,会给zookeeper带来巨大的压力。所以,kafka中leader的选举不能使用ZK来实现
10-2.kafka生产数据与消费数据流程
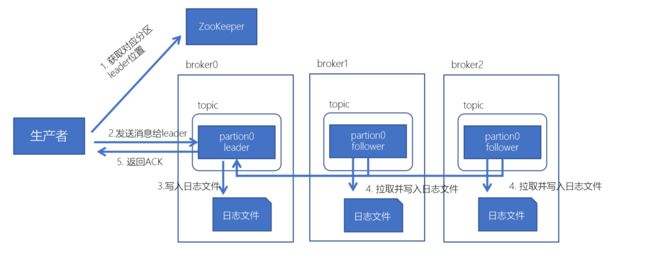
kafka数据写入流程
- 生产者先从 zookeeper 的 "/brokers/topics/主题名/partitions/分区名/state"节点找到该partition的leader
- 生产者在ZK中找到该ID找到对应的broker
- broker进程上的leader将消息写入到本地log中
- follower从leader上拉取消息,写入到本地log,并向leader发送ACK
- leader接收到所有的ISR中的Replica的ACK后,并向生产者返回ACK
kafka数据读取流程
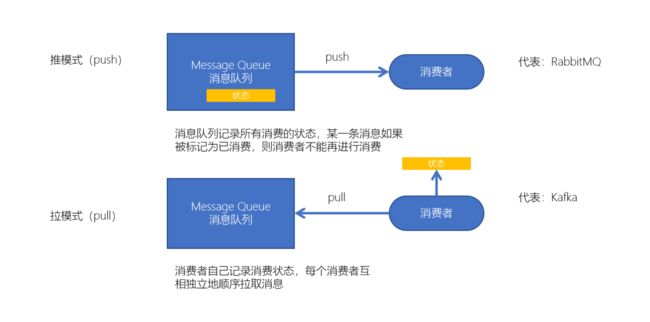
两种消费模式
- kafka采用拉取模型,由消费者自己记录消费状态,每个消费者互相独立地顺序拉取每个分区的消息
- 消费者可以按照任意的顺序消费消息。比如,消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前的时刻开始消费
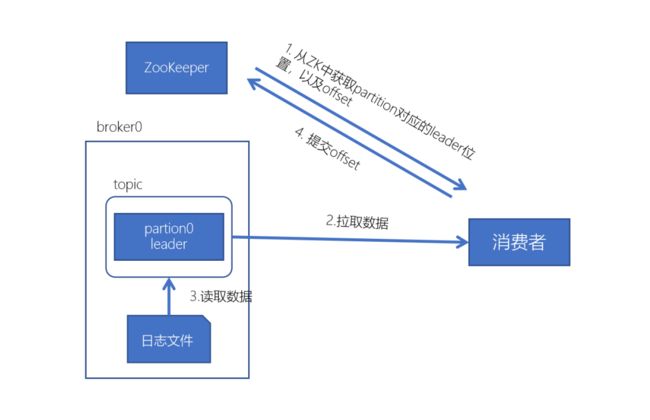
kafka消费数据流程
- 每个consumer都可以根据分配策略(默认RangeAssignor),获得要消费的分区
- 获取到consumer对应的offset(默认从ZK中获取上一次消费的offset)
- 找到该分区的leader,拉取数据
- 消费者提交offset
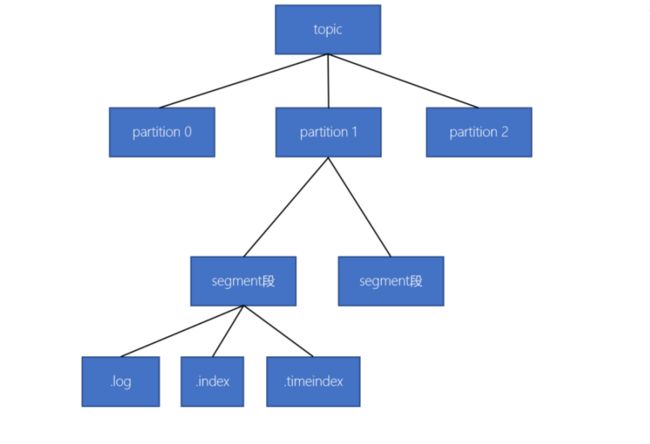
10-3.kafka的数据存储方式
- 一个topic由多个分区组成
- 一个分区(partition)由多个segment(段)组成
- 一个segment(段)由多个文件组成(log、index、timeindex)
10-4.消费不丢失机制
broker数据不丢失
生产者通过分区的leader写入数据后,所有在ISR中follower都会从leader中复制数据,这样,可以确保即使leader崩溃了,其他的follower的数据仍然是可用的
生产者数据不丢失
-
生产者连接leader写入数据时,可以通过ACK机制来确保数据已经成功写入。ACK机制有三个可选配置
- 配置ACK响应要求为 -1 时 —— 表示所有的节点都收到数据(leader和follower都接收到数据)
- 配置ACK响应要求为 1 时 —— 表示leader收到数据
- 配置ACK影响要求为 0 时 —— 生产者只负责发送数据,不关心数据是否丢失(这种情况可能会产生数据丢失,但性能是最好的)
-
生产者可以采用同步和异步两种方式发送数据
- 同步:发送一批数据给kafka后,等待kafka返回结果
- 异步:发送一批数据给kafka,只是提供一个回调函数
消费者数据不丢失
在消费者消费数据的时候,只要每个消费者记录好offset值即可,就能保证数据不丢失。
10-5.数据积压
Kafka消费者消费数据的速度是非常快的,但如果由于处理Kafka消息时,由于有一些外部IO、或者是产生网络拥堵,就会造成Kafka中的数据积压(或称为数据堆积)。如果数据一直积压,会导致数据出来的实时性受到较大影响。
第11章-数据清理机制
Kafka的消息存储在磁盘中,为了控制磁盘占用空间,Kafka需要不断地对过去的一些消息进行清理工作。Kafka的每个分区都有很多的日志文件,这样也是为了方便进行日志的清理。在Kafka中,提供两种日志清理方式:
- 日志删除(Log Deletion):按照指定的策略直接删除不符合条件的日志。
- 日志压缩(Log Compaction):按照消息的key进行整合,有相同key的但有不同value值,只保留最后一个版本。
在Kafka的broker或topic配置中:
| 配置项 | 配置值 | 说明 |
|---|---|---|
| log.cleaner.enable | true(默认) | 开启自动清理日志功能 |
| log.cleanup.policy | delete(默认) | 删除日志 |
| log.cleanup.policy | compaction | 压缩日志 |
| log.cleanup.policy | delete,compact | 同时支持删除、压缩 |
11-1.日志删除
日志删除是以段(segment日志)为单位来进行定期清理的
定时日志删除
Kafka日志管理器中会有一个专门的日志删除任务来定期检测和删除不符合保留条件的日志分段文件,这个周期可以通过broker端参数log.retention.check.interval.ms来配置,默认值为300,000,即5分钟。当前日志分段的保留策略有3种:
- 基于时间的保留策略
- 基于日志大小的保留策略
- 基于日志起始偏移量的保留策略
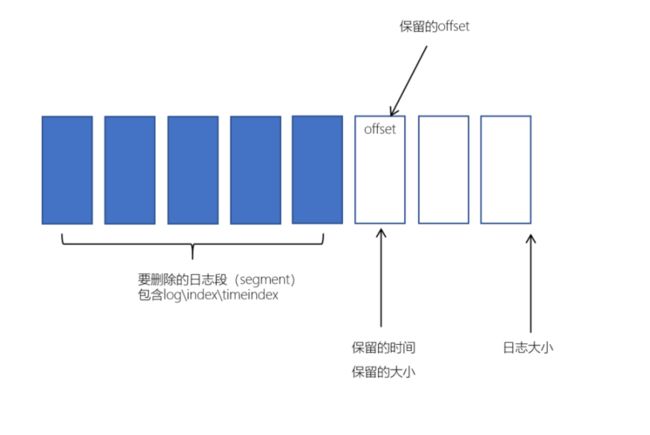
基于时间的保留策略
以下三种配置可以指定如果Kafka中的消息超过指定的阈值,就会将日志进行自动清理:
- log.retention.hours
- log.retention.minutes
- log.retention.ms
其中,优先级为 log.retention.ms > log.retention.minutes > log.retention.hours。默认情况,在broker中,配置如下:
log.retention.hours=168
也就是,默认日志的保留时间为168小时,相当于保留7天
删除日志分段时:
-
从日志文件对象中所维护日志分段的跳跃表中移除待删除的日志分段,以保证没有线程对这些日志分段进行读取操作
-
将日志分段文件添加上“.deleted”的后缀(也包括日志分段对应的索引文件)
-
Kafka的后台定时任务会定期删除这些“.deleted”为后缀的文件,这个任务的延迟执行时间可以通过file.delete.delay.ms参数来设置,默认值为60000,即1分钟
基于日志大小的保留策略
日志删除任务会检查当前日志的大小是否超过设定的阈值来寻找可删除的日志分段的文件集合。可以通过broker端参数 log.retention.bytes 来配置,默认值为-1,表示无穷大。如果超过该大小,会自动将超出部分删除。
注意:
log.retention.bytes 配置的是日志文件的总大小,而不是单个的日志分段的大小,一个日志文件包含多个日志分段
基于日志起始偏移量保留策略
每个segment日志都有它的起始偏移量,如果起始偏移量小于 logStartOffset,那么这些日志文件将会标记为删除
11-2.日志压缩
Log Compaction是默认的日志删除之外的清理过时数据的方式。它会将相同的key对应的数据只保留一个版本
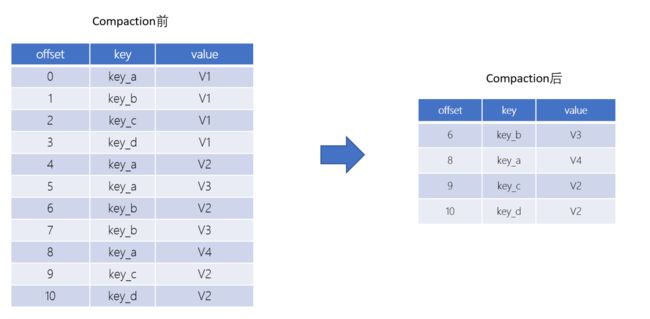
- Log Compaction执行后,offset将不再连续,但依然可以查询Segment
- Log Compaction执行前后,日志分段中的每条消息偏移量保持不变。Log Compaction会生成一个新的Segment文件
- Log Compaction是针对key的,在使用的时候注意每个消息的key不为空
- 基于Log Compaction可以保留key的最新更新,可以基于Log Compaction来恢复消费者的最新状态