又一个百亿规模智能汽车新赛道,谁在「领跑」数据引擎中间件
基于数据闭环驱动的汽车智能化迭代升级模式,已经成为行业的共识。
时间线推到2021年8月,特斯拉在美国加州总部举行的AI DAY,一个名为「DOJO超级计算机」的项目正式亮相。这是特斯拉首次对后端大数据分析、模型训练体系进行公开披露。
DOJO超级计算机的「内核」是D1芯片,每个DOJO由25颗D1芯片组成,形成36TB/s的带宽和9PetaFLOPS(9千万亿次)算力。通过分布式计算机架构,使人工智能拥有更高速的学习能力,并驱动车端智能驾驶功能的不断优化。

这得益于特斯拉在汽车行业率先布局的“影子模式”(shadow mode),借助车端标配的传感器(比如,摄像头),采集实时数据并进行模拟和测试神经网络的驾驶决策。
而DOJO则是更进一步,目标是能够接收车端采集的大量数据并在视频级别(过去,主要基于图像帧+人工标注或者半自动标注)上进行训练,再借助自动化标签技术,进行无监督的大规模训练。
这意味着,在打通车云数据通道的基础上,特斯拉可以快速在任何一个区域进行智能驾驶系统的前期训练(比如,特殊的场景和区域性特色的法规要求),并加速FSD等高阶智驾系统的OTA释放。
众所周知,基于规则(或者知识、经验)的系统开发模式是一直以来汽车智能化,尤其是智能驾驶系统的常规做法。
比如,典型的就是以Mobileye为代表的厂商。比如,这家公司主推的RSS模型就是一整套数学公式,将安全驾驶的理念和概念转化成为数学公式和计算方式,用来界定什么样的驾驶行为才是安全的驾驶。
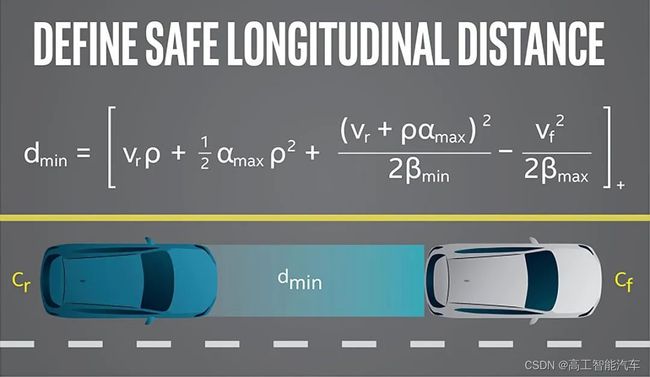
而特斯拉为代表的新玩家,则是依靠神经网络+采集大量数据进行模型训练,并基于样本特征赋予相应的权重来决定如何对事件(比如,车辆前方出现障碍物)做出反应。
这种模式的优势,非常明显。
尤其是对于车企来说,这是打造智能化核心「差异化」的关键所在。原因是,不管是计算平台还是传统的基于规则的开发模式,车企与车企之间并不存在壁垒。有能力、经验的工程师可以挖,芯片也可以从第三方供应商采购。
但,数据则是核心壁垒。比如,经过训练的神经网络的规则和关系的结构是未知的,任何人都无法「拷贝与复制」,数据与模型是深度耦合的状态。同时,模型训练的效率,则取决于车企采集数据集的规模和质量。
而随着NOA等高阶智能驾驶搭载率逐步上升,和传统入门级L2辅助驾驶(以完整功能交付为主)不同,更需要一套完整的车云数据驱动架构来实现功能的快速迭代升级。
第一步,就是搭建车端的数据引擎。
在特斯拉之前,绝大多数L4级自动驾驶公司以及前装工程开发阶段都是采用最原始的「硬盘拷贝」方式,回传道路采集数据,然后再进行数据挖掘、分析和训练。但这种方式,并不适合大规模量产交付后的数据交互。
在智协慧同看来,特斯拉以外的车企都亟需一套高效的Data Engine。作为一家专注于为OEM打造跨车云的数据驱动能力,能够打造车云计算全栈解决方案的供应商,2021年国内首个搭载智协慧同EXCEEDDATA解决方案的量产车型已落地(高合HiPhiX)。

所谓的Data Engine,就是数据引擎中间件,也可以类比为域控制器的中间件模块。作为中间件,位于上层应用和底层操作系统之间,除了基础的通信交互外,还承载着屏蔽底层复杂性的功能,向下适配不同的操作系统和硬件平台。
数据引擎中间件一方面在边缘端保证高价值数据的获取,为智能应用和算法模型提供最有价值的数据;一方面通过车云一体的架构解决了车云异构带来的效率和复杂度问题,大幅提升算法模型的迭代效率,帮助车企通过海量量产数据去持续优化算法模型。
比如,EXCEEDDATA车云一体数据底座,在车端对上万个高并发、毫秒级、时序数据进行高效管理,并基于边缘计算引擎实现对Corner Case的结构化数据和非结构化数据融合采集,相比于传统车联网,效率提升几十倍,成本降低85%以上。
同时,封装了不同车型的异构和车云异构,生态合作伙伴可以基于数据底座去更高效地开发数据智能应用,只需要专注于本身的业务逻辑,而不用去考虑跨车云的算法部署问题和跨车型的适配开发问题,大幅提升智能应用的部署效率。
此外,Data Engine也适用于智能座舱。
比如,舱内普及率较高的语音交互系统,智能化的背后同样是基于数据收集、标注、训练和部署等闭环驱动流程。通过在模型训练中基于真人语音交互数据,让语音交互更加自然和个性化。
同时,解决人-车-环境数据与智能座舱场景智能的打通问题,打造真正智能化的产品体验。比如,通过分析车辆的历史导航数据,系统可以更加合理地规划出行路线。
而在商业模式上,目前,除了少部分车企在自研类似的数据引擎(定制化,无法横向复制),大部分车企以及Tier1供应商都在寻求与类似智协慧同这样的解决方案提供商合作,来快速积累丰富的corner case场景库,同时实现多传感器数据融合采集和交叉验证,以及影子模式的量产落地。
这种需求的背景是,从基础L2到NGP、NOA等等,整个行业也不再只是车企自研一条路径。比如,基于ODIN平台最新打造的域控产品ADC20,福瑞泰克也率先实现了国产NOA行泊一体方案的量产落地,具备高速NOA、HPA记忆泊车、影子模式等功能。
一些供应商已经可以在不增加激光雷达的前提下,将摄像头+毫米波雷达+域控制器+OTA的整套NOA方案成本做到数千元的级别。同时,在数据触发与回传机制方面,这些供应商也已经有能力帮助车企构建一套完整的数据驱动迭代升级体系。
“不是每家主机厂都坚持全栈自研,会采取部分自研,部分找合作伙伴做共同推进。此外,随着产业链的成熟健全,更多玩家会选择采用第三方的方案。”这背后,实际上就是功能和成本的平衡。
按照高工智能汽车研究院监测数据显示,高阶辅助驾驶方面,2022年中国市场NOA前装标配搭载交付达到21.22万辆,首次突破20万辆大关(前装搭载率为1.06%),同比增长接近80%。预计2025年,NOA(含城区)前装标配搭载量将超过380万辆,前装搭载率将超过17%。
根据高工智能汽车研究院基于收费模式测算,应用于整车四大域控(座舱、智驾、车身、底盘),到2025年数据引擎中间件(包括车端、云端以及应用分发)的市场规模就将超过120亿元。
这意味着,一个全新的智能化细分赛道正在出现。
比如,智协慧同于2022年12月获商汤国香资本投资,并于近期完成交割,这也是该公司在2022年完成的第2轮融资。本轮融资主要用于车云数据底座及数据智能应用的研发与销售。
按照计划,智协慧同将与商汤等优质合作伙伴携手打造自动驾驶数据全栈解决方案,为主机厂提供可解耦、开放集成全数据链路解决方案,打通从采集到仿真训练的数据壁垒,提升自动驾驶数据价值和使用效率。
第二步,则是构建后端的数据超算中心,从而打造车云一体的架构,从而实现真正意义上的端到端数据驱动闭环。
以智协慧同的车云数据底座为例,一方面使云端能够按需、及时且便捷地获得车端高价值数据,另一方也能将云端数据算法策略快速地完成车端部署,较大地提升了汽车功能开发者收集和使用量产车辆数据的能力和效率。
尤其是近两年时间,随着特斯拉「影子模式」+「超算训练」模式成为行业标杆,打造支持自动驾驶数据训练的超算中心成为各家车企的头等大事。这也是不少互联网公司、云计算及传统数据中心服务商的汽车业务切入点。
比如,在毫末智行看来,近十年自动驾驶技术的发展可以分为三个阶段,最早的1.0时代是硬件驱动,以L1、入门级L2为主;最近几年进入2.0时代,主要是软件驱动,以L2+(NOA为代表)为主;接下来即将很快发生并持续发展的是3.0时代,依靠的是数据驱动,实现自动驾驶的持续迭代。
而在去年8月,基于阿里云智能计算平台,小鹏汽车在乌兰察布建成自动驾驶智算中心“扶摇”,专用于自动驾驶模型训练。“扶摇”算力可达600PFLOPS,同比此前的自动驾驶核心模型训练速度提升了170倍。
此外,腾讯云也在两年前宣布与宝马合作共建高性能数据驱动开发平台,研发更符合中国市场的自动驾驶技术和产品。去年,腾讯再次与奔驰达成合作,提供自动驾驶研发、验证等相关的云服务和数据合规支持。
与此同时,5G上车也将驱动车云一体数据驱动模式的加速落地。
高工智能汽车研究院监测数据显示,2022年中国市场乘用车前装搭载5G联网功能渗透率为2.09%,预计到2025年这个数字将提升至25%;未来三年(2023-2025)累计5G上车(按单车计算)交付将接近1000万辆。