密码译码(ASCII码详解)
刚写完一个单片机的代码,再发这个博客就感觉不适应,但是今天我翻了一眼专栏,发现好久没有常规的更新了,那么今天,我们就来用C++来编写一个代码:密码译码
先看一眼题目:
- 要将"China"译成密码,译码规律是:用原来字母后面的第4个字母代替原来的字母.例如,字母"A"后面第4个字母是"E"."E"代替"A"。因此,"China"应译为"Glmre"。请编一程序,用赋初值的方法使cl、c2、c3、c4、c5五个变量的值分别为,’C’、’h’、’i’、’n’、’a’,经过运算,使c1、c2、c3、c4、c5分别变为’G’、’l’、’m’、’r’、’e’,并输出。
-
输入 China
-
输出 加密后的China
样例输入
China
样例输出
Glmre当然他也给了一个提示:so easy
这道题的确很简单,但以你必须知道一个概念:ASCII码

ASCII码是一种计算机编码系统,用于把文字和符号转换为二进制数,方便计算机进行读取和处理。它由美国国家标准协会标准化制定并在1963年发布,共包含128个字符编码,包括数字、字母、符号、控制字符等。ASCII码在计算机应用中广泛使用,并成为了信息交流的基础编码。例如,英文字母A就对应着十进制的65,二进制的01000001(对照图来看)
那理解了这个又有什么用呢?
这个理解以后,就可以很好的处理通信过程中发送和接收的数据格式。只要记住一点,实际通信的数据形式是透明的比特流,无论是在哪里。因此,对于提供的数据是字符或者十六进制数据,都不影响下一层的数据传输,你想要什么格式发送,只需要在发送前接收后做统一的格式转换,转换后统一发送十六进制数据,这样理解以后,就不会纠结于怎样发送二进制形式的字符,怎样接收十六进制的字符,也不会提出类似的问题,因为本身发送的就已经是你想要的了。
ASCII码的特点
0~31 及 127(共 33 个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换
行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)
32~126(共 95 个)是字符(32 是空格),其中 48~57 为 0 到 9 十个阿拉伯数字。
65~90 为 26 个大写英文字母,97~122 号为 26 个小写英文字母,其余为一些标点符号、运算符号等。
后 128 个称为扩展 ASCII 码。许多基于 x86 的系统都支持使用扩展(或“高”)ASCII。扩展ASCII 码允许将每个字符的第 8 位用于确定附加的 128 个特殊符号字符、外来语字母和图形符号。
缺点
- 不能表示所有字符。
- 相同的编码表示的字符不一样: 比如, 130在法语编码中代表了é, 在希伯来语编码中却代表了字母Gimel。
编码的发展史:
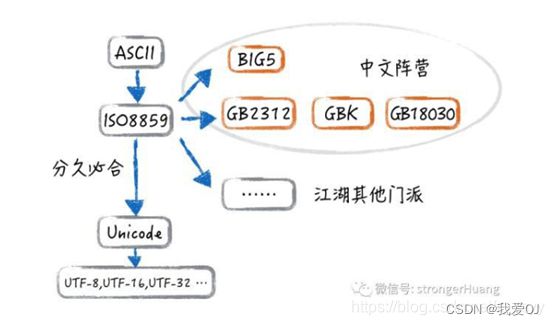
多么生动形象啊~~~
乱码
指在电脑中文系统中,当占有二个位元的中文码和占有一个位元的英文字码重叠时,所产生的无法识辨的紊乱符号现象
解读一下:就是因为每个文件的编码不同,如果你想成功打开一个文件,就必须知道它的编码方式,否则系统就会以错误的形式解读,这样就出现了乱码

拓展一下:除了ASCII码以外的其他编码格式
Unicode 编码
这条目以列表形式展示并介绍 Unicode 字符。如果字母显示得模糊,请把浏览器字体调为例如“Arial Unicode MS”之类的字体或调高浏览器的放大比率。
中文名
Unicode字符列表
外文名
Unicode horizontal tabulation character
类 型
字符列表
例 子
U+0020 空格
如下图(看起来真的好吓人啊):
base64编码
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。可查看RFC2045~RFC2049,上面有MIME的详细规范。
Base64编码是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。采用Base64编码具有不可读性,需要解码后才能阅读。
Base64由于以上优点被广泛应用于计算机的各个领域,然而由于输出内容中包括两个以上“符号类”字符(+, /, =),不同的应用场景又分别研制了Base64的各种“变种”。为统一和规范化Base64的输出,Base62x被视为无符号化的改进版本。
用一个C++程序举例(源代码:C++ 实现Base64编码_c++ base64编码_Anansi_safe的博客-CSDN博客):
string Base64::Base64Encode
(
_In_ string tsrc,
_In_ u_long srcsize
)
{
const u_char* src = (const u_char*)tsrc.c_str();
u_char* tempBuff = new u_char[3];
string destStr;
//取到最后剩几个数据
int lastNumb = srcsize % 3;
//分为三组处理
int i;
for (i = 0; i < (srcsize / 3); i++)
{
memset(tempBuff, 0x00, 3);
memcpy(tempBuff, (src+i*3), 3);
destStr += base64tab[(tempBuff[0] >> 2)];
destStr += base64tab[(((tempBuff[0] & 0x03) << 4) | (tempBuff[1] >> 4))];
destStr += base64tab[(((tempBuff[1] & 0x0f) << 2) | (tempBuff[2] >> 6))];
destStr += base64tab[(tempBuff[2] & 0x3f)];
}
//剩余不够一组的数据处理
if (lastNumb == 1)
{
memset(tempBuff, 0x00, 3);
memcpy(tempBuff, (src + i * 3), 1);
destStr += base64tab[(tempBuff[0] >> 2)];
destStr += base64tab[(tempBuff[0] & 0x03) << 4];
destStr.append("==");
}
if (lastNumb == 2)
{
memset(tempBuff, 0x00, 2);
memcpy(tempBuff, (src + i * 3), 2);
destStr += base64tab[(tempBuff[0] >> 2)];
destStr += base64tab[(((tempBuff[0] & 0x03) << 4) | (tempBuff[1] >> 4))];
destStr += base64tab[((tempBuff[1] & 0x0f) << 2)];
destStr.append("=");
}
//释放内存
delete[] tempBuff;
return destStr;
}
完了完了,又扯多了,还是直接上代码吧
#include
#include
#include
using namespace std;
int main()
{
char a[5]={'C','h','i','n','a'};
for(int i=0;i<5;i++)
{
a[i]+=4;
cout<