方差代价函数:知错
参数自适应调整
古老的【Rosenblatt感知器】启发了现代神经网络的研究,但目前已经不常用了。但从【Rosenblatt感知器】中,发现参数自适应调整乃是一个人工神经元的精髓。【Rosenblatt感知器】中,自适应的调整是通过w+α·误差·x=新w得到。

1. 我们应该如何评估误差?
方法:用差值评估预测误差
问题:误差和为0,并不代表是完美预测,差值有正负,相互之间会发生抵消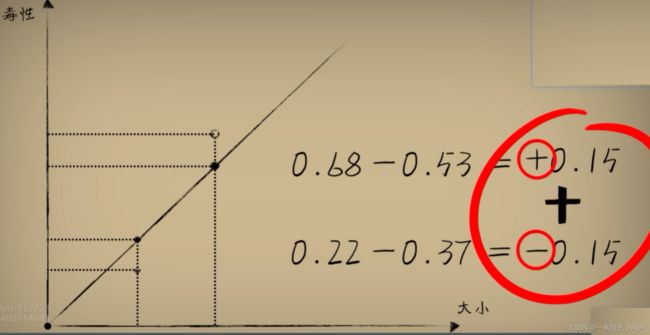
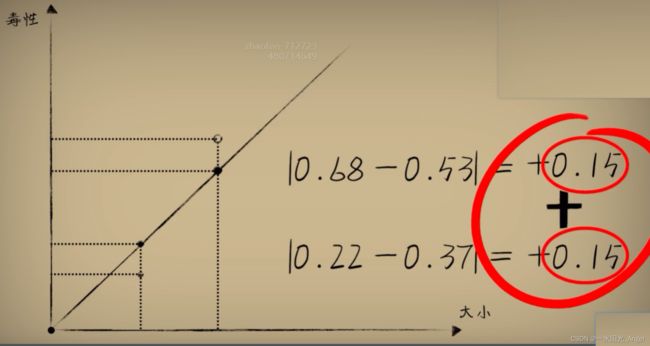

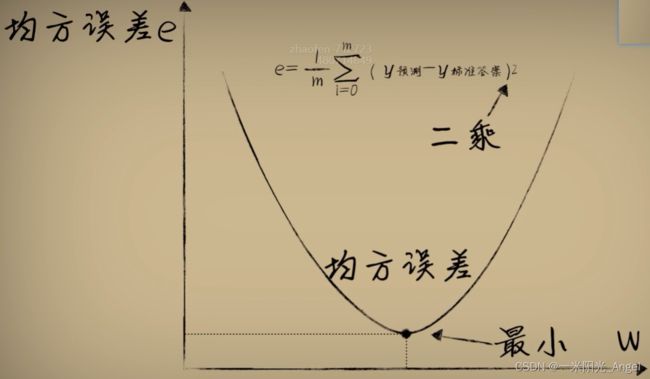
解决:用绝对值来表示误差,因为我们并不关心正负,面对误差,不论是比结果大0.15,还是比结果小0.15,其实和标准答案的差距都是0.15。误差通过绝对值处理后叫做“绝对差”。但绝对值在数学和编码上处理并不方便,所以把差值取平方,正负号就消失了,使用【平方误差】来评估误差。
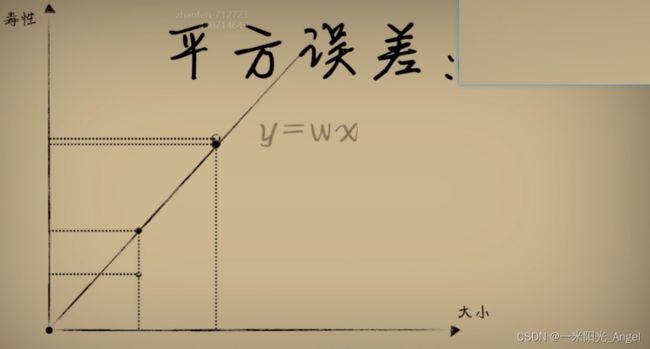
预测的结果和标准答案的平方误差越小,说明偏离事实越小
但,w决定了预测函数的样子,w取不同的值,产生的误差也会不同
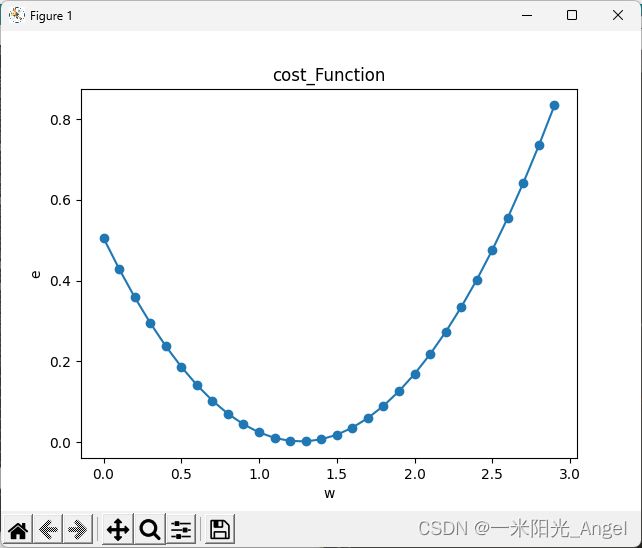
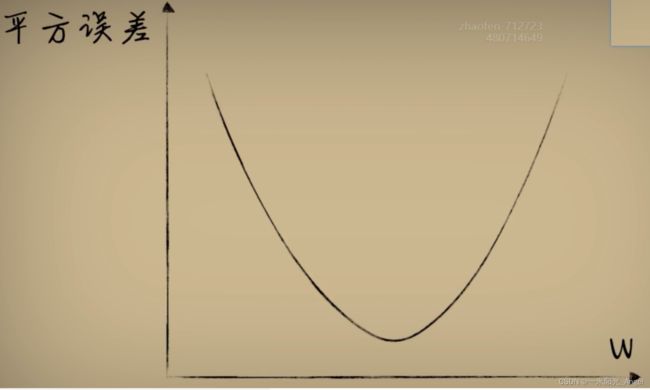
通过画图,发现,w与平方误差的关系是一个开口向上的一元二次函数
数学证明:
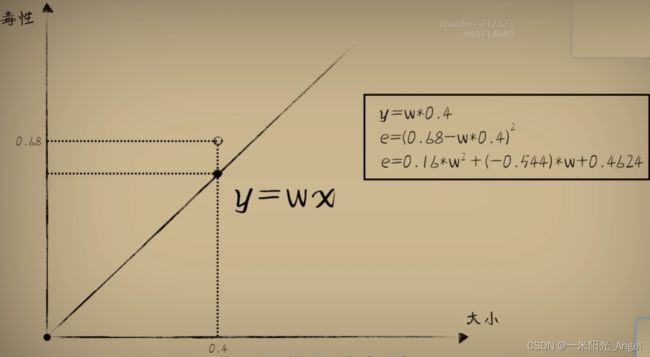
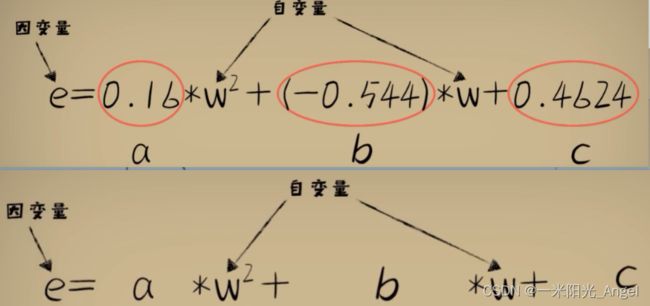
而对于任意一个豆豆,它的预测误差和参数w的关系,都是一个开口向上的抛物线函数
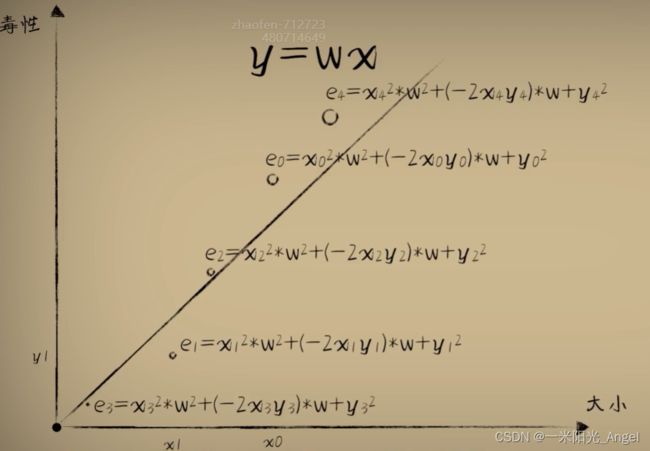
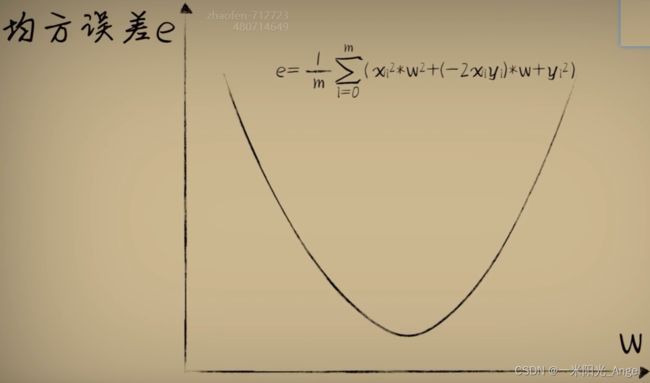
整体误差【均方误差】= 所有误差和求平均值

2. 概率和统计
函数是我们对事物认知的数学描述
一般情况下,函数的形成过程都是由某个问题的专家通过多年的经验总结出来的

但由于世界复杂,很多非理想环境下,我们一点点研究和总结是不现实的,比如掷硬币,正反出现概率都应该 1/2

除了通过质地,受力的研究得到概率函数,还可以通过统计的方式,因为 事物出现的频率收敛于它的概率。
当我们在设计“智能体大脑”(神经元模型)时,其实就是在尝试多次抛掷硬币的过程,只不过小蓝事件中,我们是通过平方误差来评估w到底合不合适
引入数理统计学(回归分析和代价函数)
回归分析:最小二乘法
代价函数 cost_function
研究方向一开始的做法:
向模型输入数据,得到结果
研究方向改进后的做法:
用很多观察到的数据去评估这个函数机器到底是否可行
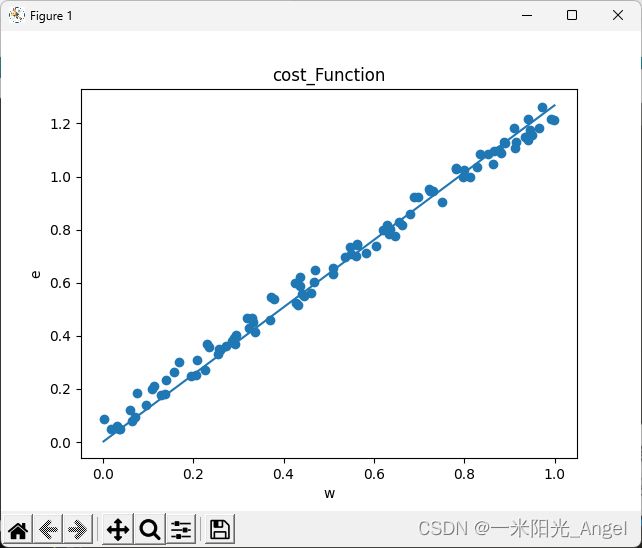
从原先自变量x 和因变量 y --> 从环境中观测到的大量已知数,将w作为自变量,e作为因变量,形成了【代价函数】,当参数w取不同值的时候,对环境中的问题数据预测时产生不同的误差e,而利用【代价函数】最低点的w值,放回预测函数中,会发现,这个时候,预测函数很好的完成了对数据的拟合。
【代价函数】作为分析并改进预测函数的辅助函数
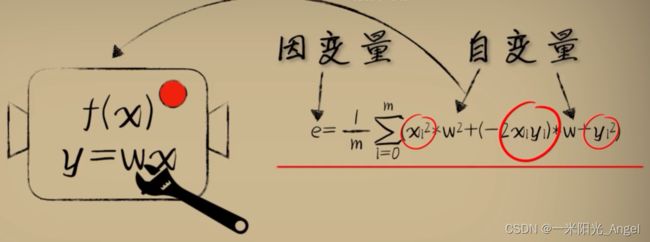
如何让机器自己把w向最低点挪动呢?
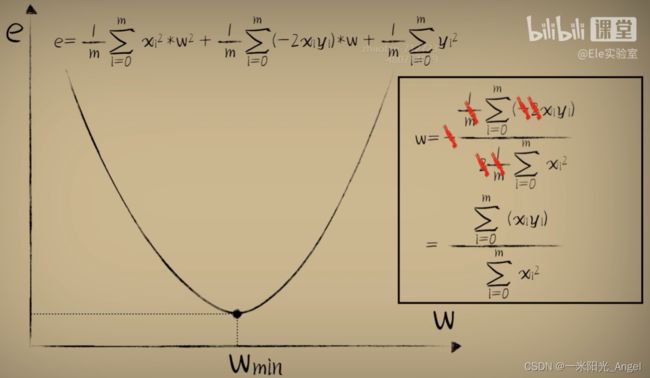
通过最低点坐标公式
正规方程
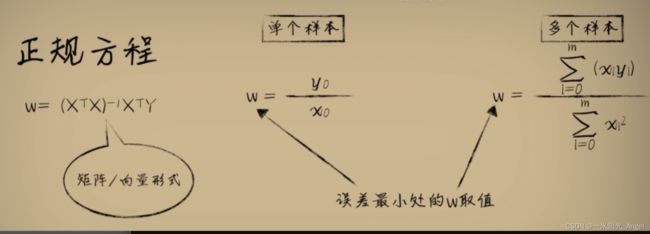
编码查看
import dataset
import matplotlib.pyplot as plt
import numpy as np
#获取豆豆数据
xs,ys = dataset.get_beans(100)
#配置图像
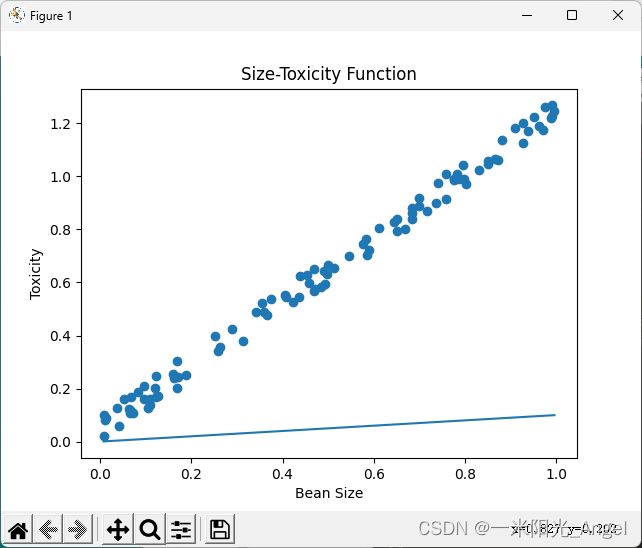
plt.title("Size-Toxicity Function",fontsize=12) #设置图像名称
plt.xlabel("Bean Size")#设置横坐标的名称
plt.ylabel("Toxicity")#设置纵坐标的名称
plt.scatter(xs,ys)
#编写预测函数
w = 0.1
y_pre = w*xs
plt.plot(xs,y_pre)
plt.show()
#求100个豆豆的均方误差
es = (ys-y_pre)**2
#均方误差求和,求均值
sum_e = np.sum(es)*(1/100)
print(sum_e)
# w = 0.1 时,预测函数在100个豆豆样本上的整体误差是0.52
# w 取不同值时,预测函数的误差
ws = np.arange(0,3,0.1)
es = []
for w in ws:
y_pre = w * xs
e = np.sum((ys-y_pre)**2)*(1/100)
es.append(e)
plt.title("cost_Function",fontsize=12) #设置图像名称
plt.xlabel("w")#设置横坐标的名称
plt.ylabel("e")#设置纵坐标的名称
plt.scatter(ws,es)
plt.plot(ws,es)
plt.show()
w_min = np.sum(xs*ys)/np.sum(xs*xs)
print("e最小点w:" + str(w_min))
y_pre = w_min * xs
plt.title("cost_Function",fontsize=12) #设置图像名称
plt.xlabel("w")#设置横坐标的名称
plt.ylabel("e")#设置纵坐标的名称
plt.scatter(xs,ys)
plt.plot(xs,y_pre)
plt.show()