数据分析从0到1----Numpy篇
文章目录
- 前言
- 什么是Numpy(Numerical Python)?
- Numpy ndarray对象
-
- array
- arange
- linspace
- logspace
- zeros/ones
- Numpy的数组属性
- 切片与索引
- 广播机制
- 统计函数
- 数据类型
- 文件操作
- 随机函数
- 数组的其他函数
-
- numpy.resize(arr,shape)
- numpy.append(arr,values,axis=None)
- numpy.insert(arr,obj,values,axis)
- numpy.delete(arr,obj,axis)
- numpy.argwhere()
- numpy.unique(arr,return_index,return_inverse,return_counts)
- numpy.sort(a,axis,kind,order)
- numpy.argsort()
前言
本文只适用于已经了解如何使用jupyter的选手,因此如果不知道或者不了解jupyter的使用,那么应该先学一下.本文主要用于指导新手入门了解各种函数的使用,具体函数的使用方法可以寻找一些其他资料或者查看下方我贴出的官方文档,本文所有代码基于Anaconda5.3.0版本
Anaconda5.3.0下载
Matplotlib篇
Pandas篇
什么是Numpy(Numerical Python)?
Numpy-API
全文代码下载
- 是一个开源的Python科学计算库
- 使用Numpy可以方便的使用数组,矩阵进行计算
- 包含线性代数,傅里叶变换,随机数生成等大量函数
对于统一的数值计算任务,使用Numpy比直接使用Python代码实现,有以下优点:
- 代码更简洁:Numpy直接以数组、矩阵为粒度计算并且支撑大量的数学函数,而python需要用for循环从底层实现;
- 性能更高效: Numpy的数组存储效率和输入输出计算性能,比Python使用List或者嵌套List好很多;
注:Numpy的数据存储和Python原生的List是不一样的
注:Numpy的大部分代码都是C语言实现的,这是Numpy比纯Python代码高效的原因
Numpy是Python各种数据科学类库的基础库
比如: Scipy,Scikit-Learn、TensorFlow,pandas等
下面用一份代码测试原生Python代码和numpy的速度
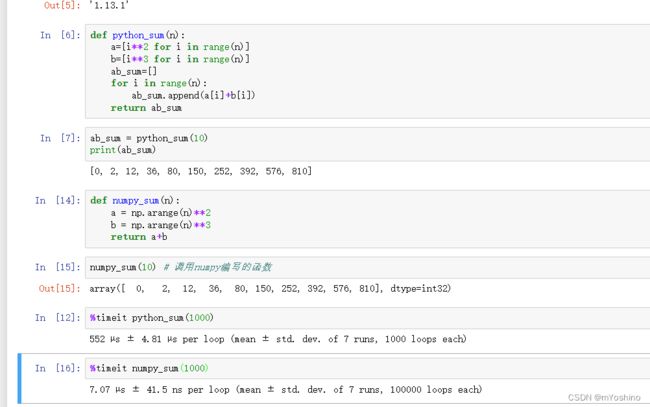
可以看到这个速度差距有近百倍,其实这也就是因为numpy的底层是C,而C的速度一般为Python速度的100-200倍.
Numpy ndarray对象
Numpy-narray
NumPy定义了一个n 维数组对象,简称ndarray对象,它是一个一系列相同类型元素组成的数组集合。数组中的每个元素都占有大小相同的内存块。
ndarray 对象采用了数组的索引机制,将数组中的每个元素映射到内存块上,并且按照一定的布局对内存块进行排列(行或列)。
使用numpy可以快速的创建n维数组
array
array(object, dtype=None, copy=True, order=‘K’, subok=False, ndmin=0)



arange
arange([start,] stop[, step,], dtype=None)
根据start与stop指定的范围以及step设定的步长,生成一个ndarray.


linspace
linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
返回在间隔[开始,停止]上计算的num个均匀间隔的样本。数组由一个等差数列构成。


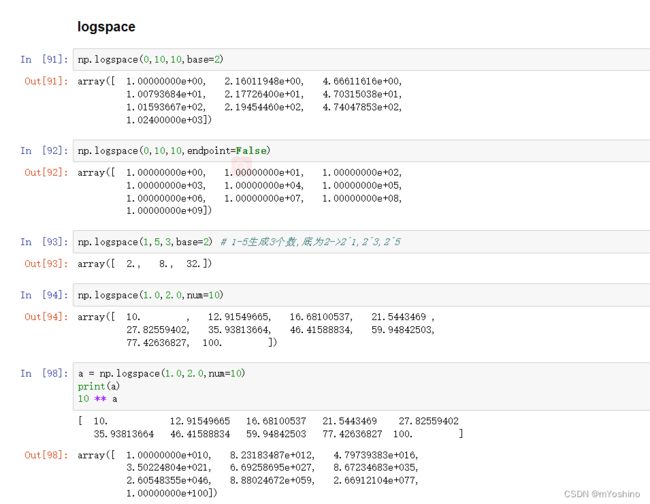
logspace
logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
返回在间隔[开始,停止]上计算的num个均匀间隔的样本,数组是一个等比数列构成.


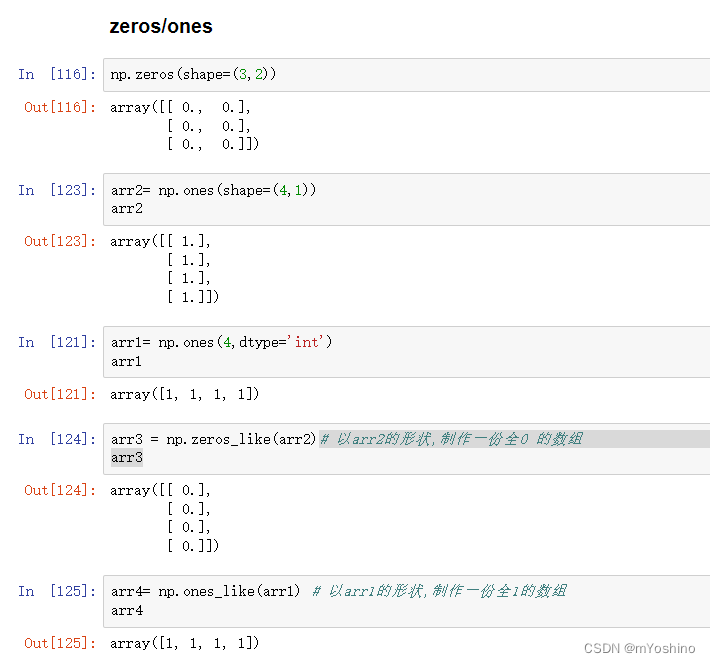
zeros/ones
zeros(shape, dtype=float, order=‘C’)
ones(shape, dtype=None, order=‘C’)
创建一份全为0/1的由shape指定维度的数组

Numpy的数组属性
Numpy的数组中比较重要的ndarray对象属性有

- 1:ndarray.shape ndarray对象的维度
返回一个包含数组维度的元组,对于矩阵,n行m列,它也可以用于调整数组维度

reshape(shape, order=‘C’)
将原有的数组的维度修改为新的shape定义的维度,要求原有的数组内的数据量必须等于reshape内参数相乘后的积,否则报错

resize(a, new_shape)
如果新数组大于原数组,则新数组将填充a的重复副本,此行为与a.resize(new_shape)不同,后者用0而不是重复的a填充.

- 2:ndarray.ndim ndarray对象的稚
- 3:ndarray.size ndarray对象的数据个数

- 4:ndarray.dtype ndarray对象的元素类型

astype(dtype, order=‘K’, casting=‘unsafe’, subok=True, copy=True)
返回修改后的数据类型

- 5:ndarray.itemsize 返回数组中每个数据类型所占用的字节数

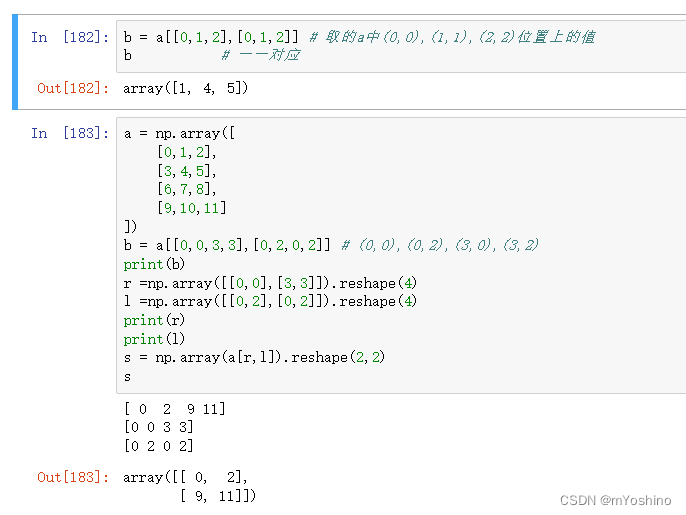
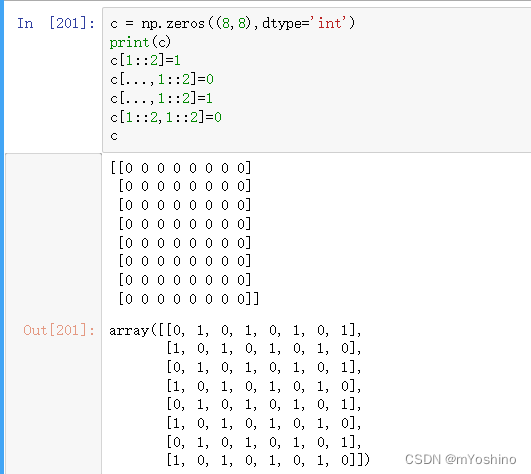
切片与索引



广播机制
广播(Broadcast)是numpy对不同形状(shape)的数组进行数值计算的方式,对数组的算术运算通常在相应的元素上进行。如果两个数组a和b形状相同,即满足a.shape ==- b.shape,那么 a×b的结果就是a与b数组对应位相乘。这要求维数相同,且各维度的长度相同。

但如果两个形状不同的数组呢?它们之间就不能做算术运算了吗?
当然不是!为了保持数组形状相同,NumPy设计了一种广播机制,这种机制的核心是对形状较小的数组,在横向或纵向上进行一定次数的重复,使其与形状较大的数组拥有相同的维度。

广播的规则:
- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加1补齐。
- 输出数组的形状是输入数组形状的各个维度上的最大值。
- 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为1时,这个数组能够用来计算,否则出错。
- 当输入数组的某个维度的长度为1时,沿着此维度运算时都用此维度上的第一组值。
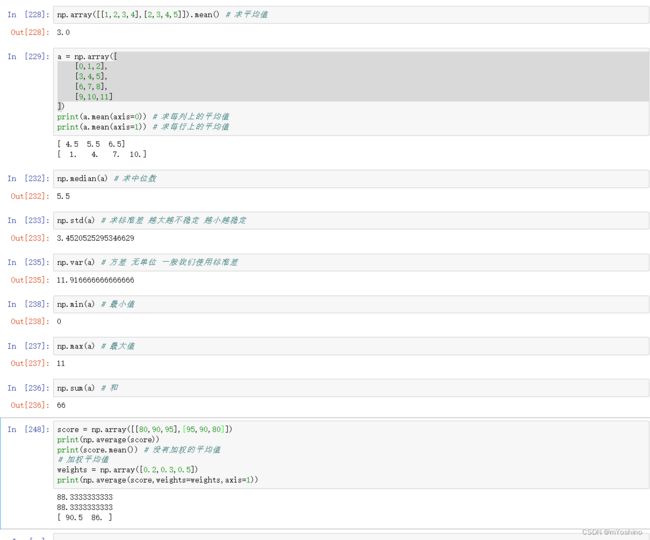
统计函数

Array-Method查看所有方法
数据类型


文件操作
loadtxt(fname, dtype=


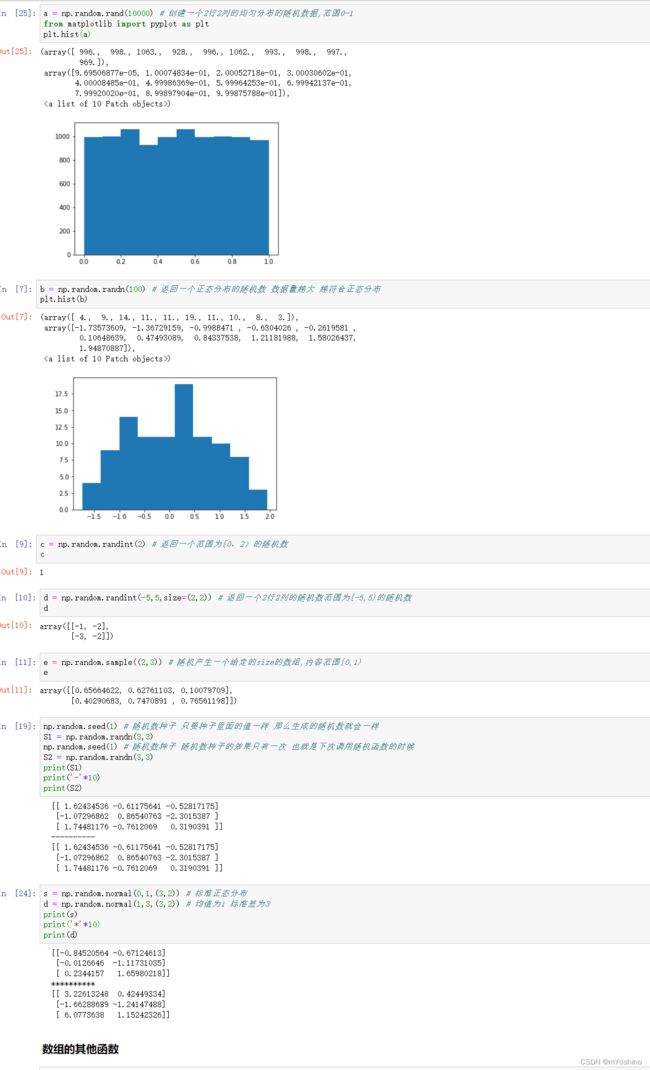
随机函数
NumPy中也有自己的随机函数,包含在random模块中。它能产生特定分布的随机数,如正态分布等。接下来介绍一些常用的随机数。

normal(loc=0.0, scale=1.0, size=None)
作用:返回一个由size指定形状的数组,数组中的值服从u=loc,a=scale的正态分布。
参数:
- loc : float型或者float型的类数组对象,指定均值u
- scale : float型或者float型的类数组对象,指定标准差σ
- size : int型或者int型的元组,指定了数组的形状。如果不提供size,且loc和scale为标量(不是类数组对象),则返回一个服从该分布的随机数。
数组的其他函数
numpy.resize(arr,shape)
该函数用于返回指定形状的新数组
numpy.resize(arr,shape),有返回值,返回复制内容.如果维度不够,会使用原数组数据补齐
ndarray.resize(shape, refcheck=False),修改原数组,不会返回数据,如果维度不够,会使用0补齐

numpy.append(arr,values,axis=None)
参数说明:
- arr:输入的数组;
- values:向arr数组中添加的值,需要和arr 数组的形状保持一致;
- axis:默认为None,返回的是一维数组;当axis =0时,追加的值会被添加到行,而列数保持不变,若axis=1则与其恰好相反。

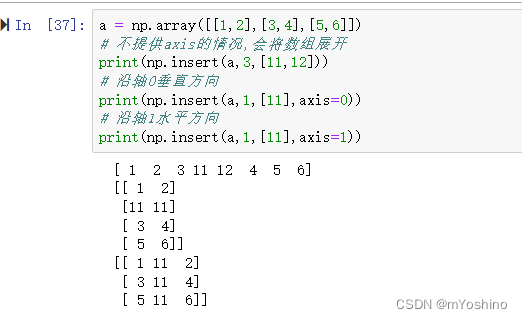
numpy.insert(arr,obj,values,axis)
表示沿指定的轴,在给定索引值的前一个位置插入相应的值,如果没有提供轴,则输入数组被展开为一维数组。\
参数说明:
- arr:要输入的数组
- obj:表示索引值,在该索引值之前插入
- values:要插入的值
- axis:指定的轴,如果未提供,则输入数组会被展开为一维数组
numpy.delete(arr,obj,axis)
该方法表示从输入数组中删除指定的子数组,并返回一个新数组。它与insert()函数相似,若不提供 axis 参数,则输入数组被展开为一维数组。numpy. delete(arr,obj, axis)
参数说明:
- arr:要输入的数组
- obj:整数或者整数数组,表示要被删除数组元素或者子数组;
- axis:沿着哪条轴删除子数组。

numpy.argwhere()
该函数返回数组中符合条件的数据的索引,若是在多维数组,则返回行,列索引组成的索引坐标

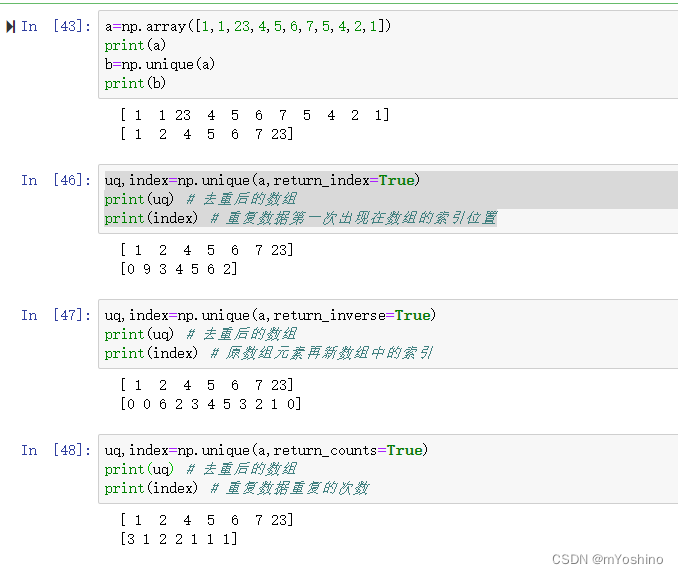
numpy.unique(arr,return_index,return_inverse,return_counts)
用于删除数组中重复的元素
参数说明:
- arr:输入数组,若是多维数组则以一维数组形式展开;
- return_index:如果为True,则返回新数组元素在原数组中的位置(索引);.
- return_inverse:如果为True,则返回原数组元素在新数组中的位置(索引);
- return_counts:如果为True,则返回去重后的数组元素在原数组中出现的次数。
numpy.sort(a,axis,kind,order)
对输入数组执行排序,并返回一个数组副本。
参数说明:
- a:要排序的数组;
- axis:沿都指定轴进行排序,如果没有指定axis,默认在最后一个轴上排序,若axis=0表示按列排序, axis=1表示按行排序;
- kind:默认为quicksort(快速排序);
- order:若数组设置了字段,则order表示要排序的字段。

numpy.argsort()
argsort()沿着指定的轴,对输入数组的元素值进行排序,并返回排序后的元素索引数组。
