Python 操作 protobuf 常见用法
ProtoBuf: 是一套完整的 IDL(接口描述语言),出自Google,基于 C++ 进行的实现,开发人员可以根据 ProtoBuf 的语言规范生成多种编程语言(Golang、Python、Java 等)的接口代码,本篇只讲述 Python 的基础操作。据说 ProtoBuf 所生成的二进制文件在存储效率上比 XML 高 3~10 倍,并且处理性能高 1~2 个数量级,这也是选择 ProtoBuf 作为序列化方案的一个重要因素之一。
安装:
- 安装 protoc :Protoc下载地址,可以根据自己的系统下载相应的 protoc,windows 用户统一下载 win32 版本。
- 配置 protoc 到系统的环境变量中,执行如下命令查看是否安装成功:
$ protoc --version
如果正常打印 libprotoc 的版本信息就表明 protoc 安装成功
- 安装 ProtoBuf 相关的 python 依赖库
$ pip install protobuf
使用
-
创建 demo python 工程
-
在 example 包中编写 person.proto
syntax = "proto3"; package example; message person { int32 id = 1; string name = 2; } message all_person { repeated person Per = 1; } -
进入 demo 工程的 example 目录,使用 protoc 编译 person.proto
- 在 python 工程中使用 protobuf 进行序列化与反序列化
main.py:#! /usr/bin/env python # -*- coding: utf-8 -*- from example import person_pb2 # 为 all_person 填充数据 pers = person_pb2.all_person() p1 = pers.Per.add() p1.id = 1 p1.name = 'xieyanke' p2 = pers.Per.add() p2.id = 2 p2.name = 'pythoner' # 对数据进行序列化 data = pers.SerializeToString() # 对已经序列化的数据进行反序列化 target = person_pb2.all_person() target.ParseFromString(data) print(target.Per[1].name) # 打印第一个 person name 的值进行反序列化验证
其他常用操作:
1、python对序列化的字串反序列化为protobuf结构
注:其中用到的im_msg_body_pb2就是im_msg_body.proto文件经过编译后生成的python库文件。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import im_msg_body_pb2
row_msg_body = b"\n\271\001\n!\010\000\020\223\203\321\363\005\030\343\337\232\334\007 \000(\n0\0008\206\001@\002J\006\345\256\213\344\275\223\022^\312\001[\nY\010\003\022\004\010\000\020\001(\0030\242\333\255\311\005H\225\340\215\320\n\212\001\017861684676539011\352\001.webim_2852155980_861684676539011_1584676769010\0224\n2\n0\345\275\223\346\227\266\347\273\231\346\210\221\344\273\213\347\273\215\347\232\204\346\227\266\345\200\231\350\257\264\344\270\200\346\254\241\346\200\247\351\200\200\345\256\214\345\225\212";
print("----------实例结构对象,对原生字串反序列化-----------")
msgbody = im_msg_body_pb2.MsgBody()
msgbody.ParseFromString(row_msg_body)
print(msgbody)
print("---------------母结构赋值子结构----------------------")
rich_text = im_msg_body_pb2.RichText()
rich_text = msgbody.rich_text;
print(rich_text)
print("----------取repeated对象(Elem为repeated)------------")
elem = im_msg_body_pb2.Elem();
elem = msgbody.rich_text.elems[1]
print(elem)
print("-----------下面打印的就是汉字了----------------")
text = im_msg_body_pb2.Text();
text = msgbody.rich_text.elems[1].text
print(text.str)2、python操作protobuf中repeated修饰的数据(给repeated字段赋值)
切记两个点:(1)对于repeated的结构使用.add() (2)对于单个元素使用append()追加
Python序列化proto中repeated修饰的数据 - YYRise - 博客园
3、python判断某个字段是否存在(子字段&子结构)
#判断elem实例对象中是否有text字段(最终字段可以这样;子结构貌似不可以)
if elem.text != None:
print(elem.text)
#对于子结构这里先提供一个不是很美观但是能用的方法
#那就是用这个子结构和ph创建的空这个子结构对比,如下:
if msg_body.rich_text==im_msg_body_pb2.MsgBody().rich_text:
print("rich_text is empty!!")
4、python循环遍历某个repeated字段
#for循环遍历msgbody→rich_text→elems(repeated)
for elem in msgbody.rich_text.elems:
print(elem)
5、获取某个repeated字段的size
#使用python的len函数即可
print("length:",len(msgbody.rich_text.elems))6、按序号取repeated字段的值
#使用中括号"[]"
for i in range(0,len(msgbody.rich_text.elems)):
print("elems[",i,"]",msgbody.rich_text.elems[i])晚点继续完善python对于protobuf常用的操作。。。。
这里先贴两个python常用操作protobuf的链接,后续整理一下。
参考一 参考二
其实最高效快速的方式就是看官方使用手册(真的啥都有):
Protocol Buffer Basics: Python | Protocol Buffers | Google Developers
Python Generated Code | Protocol Buffers | Google Developers
遇到的报错:
1、“Couldn't build proto file into descriptor pool ”,大致如下:
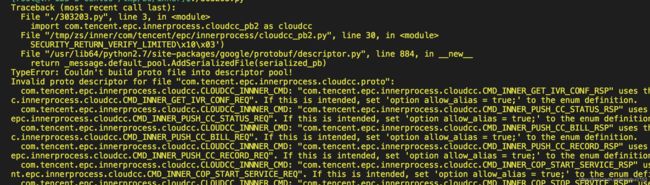
正解如下:这是protobuf二进制轮子的问题,解决该问题的唯一方法是安装纯python的实现。具体如下:
pip uninstall protobuf
pip install --no-binary=protobuf protobuf参照:https://github.com/ValvePython/csgo/issues/8