浅谈flink-cdc的使用
标题: 浅谈flink-cdc的使用
日期: 2021-12-18 14:31:13
标签: flink
分类: [实时数仓, flink, flink-cdc]
最近使用flink cdc 1.x,生产上碰到了许多问题,这里给大家罗列一下,并给出思路和解决方案。

目前,我使用的flink版本是1.12.1,mysql-cdc版本是1.1.0.
一、mysql表太大,锁表时间长
flink-mysql-cdc 1.x默认有2个阶段:
-
全量阶段:
全量阶段,flink会先获取全局读锁(reload权限),言外之意就是,获取整个mysql实例的全局锁,获取之后,所有连接mysql的ddl dml操作,均会处于wait read lock阶段,如果锁获取时间超时,那么你的程序可能会抛出异常。
另一种情况,如果获取不到全局读锁,比如有另一个cdc程序也在初始化阶段,那么此程序就会去获取表级锁(lock tables),但是表级锁,锁的时间会更长,一般是全局读锁的几十倍时长。
我们生产目前一个mysql表,70万数据,全局读锁锁mysql时间30s,表级锁锁表时间6分钟左右,所以如果表数据量很大,亿级别的话,同步时间需要小时级。这里也讲一下flink cdc 1.x的缺点:
a. 同步时需要获取全局读锁,或者表锁,这可能会影响生产业务;
b. 全量同步阶段(快照),只有一个任务进行同步,所以比较慢,不支持多任务并发同步;
c. 不支持断点续传,如果在同步过程中,出现mysql连接超时,或者flink程序快照中断,那么我们无法从断开点开始续传,因为目前暂不支持checkpoint。
当然flink cdc 2.x解决了这三个问题:无锁、并发任务同步、断点续传。 -
增量阶段
增量阶段,那就是我们所熟知的,通过监控binlog方式,来获取增量数据,这个阶段对mysql基本无影响。
二、同步时间过长,触发flink task failover机制
flink默认checkpoint时间间隔10分钟1次,当我们的mysql表数据量比较大,同步时间超过了10分钟时,task则会失败,触发task的failover重启,前面也介绍过了,flink cdc 1.x不支持断点续传,所以,task重启会造成不停获取锁,造成业务系统无法使用。
那么,我们怎么避免这种情况的发生呢?
来看看官网怎么说的:

解决办法,提高flink task的failover次数,修改单次task checkpoint时长,达到在全量同步阶段,不至于task不停重试。
execution.checkpointing.interval: 10min
execution.checkpointing.tolerable-failed-checkpoints: 100
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2147483647
其实你碰到的大部分问题,大家都碰到过,关键是你怎么去看待这个问题了。
所以,遇到问题,不要烦躁,多看看官方文档,他们介绍的最官方、最详细、最正确,而且问题也有最优的解决方案,百度、google、csdn、stackoverflow技术社区固然是一种解决办法,但是比不上官方来的理解深刻。
这里贴一下官方flink-cdc地址:
https://ververica.github.io/flink-cdc-connectors/master/
三、cdc 2.x
前面我们说了最近工作中使用1.x碰到的一些问题,那么接下来说下2.x。
下图是flink-cdc 2.1的图解:
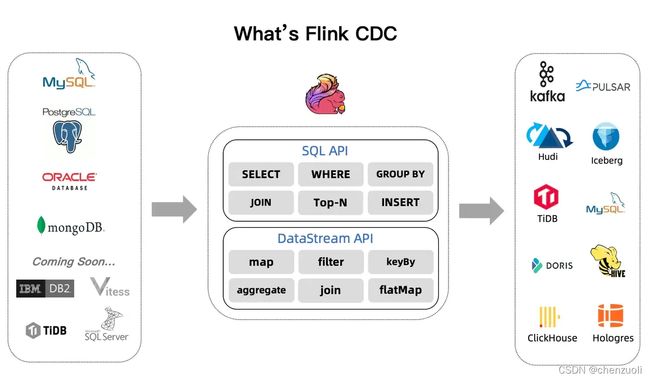
2.x 在2021年已经出来了,cdc 2.x已经解决了前面第一部分出现的三个问题(锁机制、单任务快照同步、不支持断点续传),那么还有什么新特性呢?
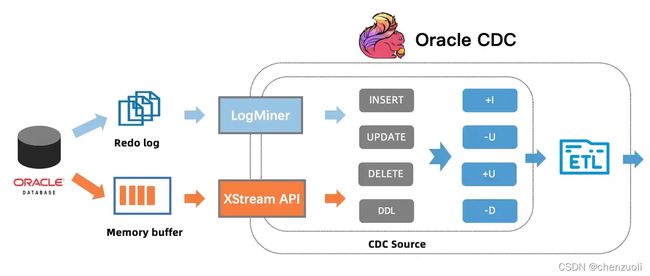
出了对现有的mysql-cdc postgres-cdc connector的优化外,而且支持oracle-cdc mongodb-cdc,我在之前还自己写过oracle-cdc的实现,现在官方自己出了一套,那就很香了。
官方2.1支持的oracle-cdc,它走了2条路,1是oracle提供的实时同步方案Oracle GoldenGate (OGG) ,这也是我之前走的一条路,收费,另外一条是基于oracle LogMiner,这条路不收费,通过解析日志,变为事件输出,但是oracle对日志解析有资源限制,所以慢。
四、如果现在必须使用cdc 1.x怎么办?
我们可以跳过锁机制,直接进行同步,那么损失的是数据同步的准确性,由exactly once变成了at least once,在mysql-cdc建表语句里,带着下面的参数即可:
debezium.snapshot.locking.mode' = 'none'
哪种场景可以使用这个参数呢?
你的下游sink表是可以upsert的,比如kafka hbase mysql postgresql,然后设置了主键,我们在插入的时候,会根据主键自己更新,那么at least once就不怕数据重复了。
五、跳过全量阶段
针对1.x讲解。
cdc默认分两个阶段:全量阶段和增量阶段
全量阶段就会有锁,那么我们也可以跳过锁,去直接进行增量同步binlog变化,这样就避免了锁库的缺陷。
适用于你不需要历史数据,同步最新数据即可的情况。
设置如下参数即可:
scan.startup.mode=latest-offset
这个参数默认是initial,表示带快照的初始化。
注意一个问题,这2个参数scan.startup.mode和debezium.snapshot.mode效果是一样的,是互相冲突的,如果你两个参数都设置了,那么scan.startup.mode不生效。
ok,今天说到这里。
Keep reading, Keep writing, Keep coding.
欢迎关注我的微信公众号,比较喜欢分享知识,也喜欢宠物,所以做了这2个公众号:

喜欢宠物的朋友可以关注:【电巴克宠物Pets】

一起学习,一起进步。