InfoGraph
Paper : InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization
Code :
摘要
作者使用 Deep Infomax 的方法来学习网络的图表示,并提出了自监督学习版本的训练方法 InfoGraph 与非监督学习版本的训练方法 InfoGraph* ,两者之间的差别在于 InfoGraph* 损失函数多了一项防止发生 negative transfer 。
Mutual Information
互信息定义为
I ( X ; Y ) = H ( X ) − H ( X ∣ Y ) = H ( Y ) − H ( Y ∣ X ) I(X;Y) = H(X)-H(X|Y) = H(Y)-H(Y|X) I(X;Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)
其中 H ( ⋅ ) H(\cdot) H(⋅) 表示随机变量的熵, I ( X ; Y ) I(X;Y) I(X;Y) 的直观解释是已知随机变量 Y Y Y 时会使 X X X 的不确定度减少多少,用于描述随机变量 X X X 与随机变量 Y Y Y 之间的相关性。计算方法如下所示
I ( X ; Y ) = ∑ X ∼ X ∑ Y ∼ Y p ( X , Y ) log p ( X , Y ) p ( X ) p ( Y ) I(X;Y) = \sum_{X\sim \mathcal X} \sum_{Y\sim\mathcal Y} p(X,Y) \log\frac{p(X,Y)}{p(X)p(Y)} I(X;Y)=X∼X∑Y∼Y∑p(X,Y)logp(X)p(Y)p(X,Y)
互信息与KL散度具有如下性质
I ( X ; Y ) = ∑ Y ∼ Y p ( Y ) ∑ X ∼ X p ( X ∣ Y ) log p ( X ∣ Y ) p ( X ) = ∑ Y ∼ Y p ( Y ) D K L ( p ( X ∣ Y ) ∣ ∣ p ( X ) ) = E Y [ D K L ( p ( X ∣ Y ) ∣ ∣ p ( X ) ) ] I(X;Y) = \sum_{Y\sim \mathcal Y}p(Y)\sum_{X\sim \mathcal X}p(X|Y)\log\frac{p(X|Y)}{p(X)} \\ = \sum_{Y\sim \mathcal Y}p(Y) D_{KL}(p(X|Y)||p(X)) \\ = \mathbb E_{Y}[D_{KL}(p(X|Y)||p(X))] I(X;Y)=Y∼Y∑p(Y)X∼X∑p(X∣Y)logp(X)p(X∣Y)=Y∼Y∑p(Y)DKL(p(X∣Y)∣∣p(X))=EY[DKL(p(X∣Y)∣∣p(X))]
InfoGraph
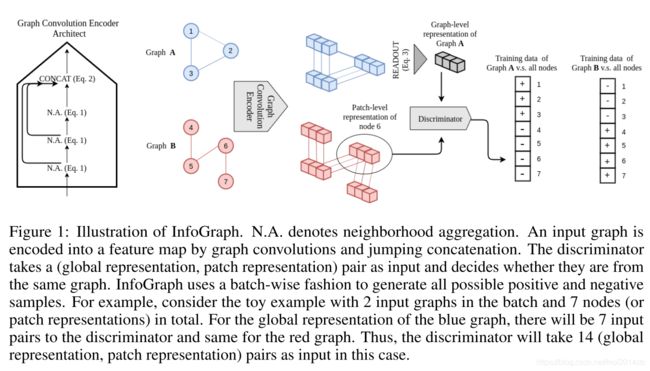
经过GNN网络中的若干层卷积,图上的点特征表示可以看作是对每个点感受野内的子图进行编码,最大化图表示与每个节点的隐变量之间的互信息可以看作是使图表示学习到图中每个子结构共有的特性。
首先对GNN进行形式化定义,GNN中第k层执行的操作是
h v ( k ) = Combine ( k ) ( h v ( k − 1 ) , Aggregate ( k ) ( { h v ( k − 1 ) , h u ( k − 1 ) , e u v ∣ u ∈ N ( u ) } ) ) h_v^{(k)} = \text{Combine}^{(k)}(h_v^{(k-1)},\text{Aggregate}^{(k)}(\{h_v^{(k-1)},h_u^{(k-1)},e_{uv}|u\in \mathcal N(u)\})) hv(k)=Combine(k)(hv(k−1),Aggregate(k)({hv(k−1),hu(k−1),euv∣u∈N(u)}))
使用 ϕ \phi ϕ 表示GNN的参数,定义表示节点 u u u 在不同的感受野下的隐变量为
h ϕ u = Concat ( { h u ( k ) } k = 1 K ) h_\phi ^u = \text{Concat}(\{h_u^{(k)}\}_{k=1}^K) hϕu=Concat({hu(k)}k=1K)
定义使用读出层读出所有的节点表示获得的图表示为
H ϕ ( G ) = Readout ( { h ϕ u } u = 1 N ) H_\phi(G) = \text{Readout}(\{h_\phi^u\}_{u=1}^N) Hϕ(G)=Readout({hϕu}u=1N)
很难直接在不同的空间上定义互信息,因此采用一种迂回的方式,如果对于输入 x x x 与输出 y ( x ) y(x) y(x),之间的互信息较大,那么对于任一与 x x x 同分布但是与 x x x 不同的输入 x ′ x' x′,那么识别器应当很轻易的区分出来 y ( x ) y(x) y(x) 与 y ( x ′ ) y(x') y(x′) 之间存在差异。因此,定义 T ψ T_{\psi} Tψ 表示互信息评估用的区分器(discriminator),其中 ψ \psi ψ 表示区分器中的参数,InfoGraph 的目标是学习到
ϕ ^ , ψ ^ = arg max ϕ , ψ ∑ G ∈ G 1 ∣ G ∣ ∑ u ∈ G I ϕ , ψ ( h ϕ u ; H ϕ ( G ) ) \widehat \phi,\widehat \psi = \arg\max_{\phi,\psi} \sum_{G\in\mathcal G} \frac{1}{|G|}\sum_{u\in G} I_{\phi,\psi}(h^u_\phi;H_\phi(G)) ϕ ,ψ =argϕ,ψmaxG∈G∑∣G∣1u∈G∑Iϕ,ψ(hϕu;Hϕ(G))
其中互信息定义为
I ϕ , ψ ( h ϕ u ; H ϕ ( G ) ) = E x [ − softplus ( − T ψ ( h ϕ u ( x ) , H ϕ ( x ) ) ) ] − E x , x ′ [ softplus ( T ψ ( h ϕ u ( x ′ ) , H ϕ ( x ) ) ) ] I_{\phi,\psi}(h^u_\phi;H_\phi(G)) = \mathbb E_{x}[-\text{softplus}(-T_\psi(h^u_\phi(x),H_{\phi}(x)))] - \mathbb E_{x,x'}[\text{softplus}(T_\psi(h^u_\phi(x'),H_{\phi}(x)))] Iϕ,ψ(hϕu;Hϕ(G))=Ex[−softplus(−Tψ(hϕu(x),Hϕ(x)))]−Ex,x′[softplus(Tψ(hϕu(x′),Hϕ(x)))]
其中 softplus ( x ) = ln ( 1 + e x ) \text{softplus}(x) = \ln(1+e^{x}) softplus(x)=ln(1+ex),在训练时,使用batch中所有图实例的全局和局部点特征表示的所有可能组合来生成负样本。
InfoGraph*
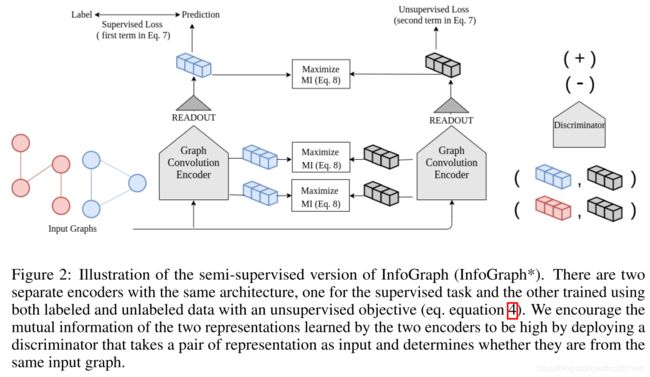
InfoGraph* 是 InfoGraph 的半监督版本,如果直接使用 InfoGraph 到半监督任务中,那么损失函数定义为
L = ∑ i = 1 ∣ G L ∣ L supervised ( y ϕ ( G i ) , y ^ i ) + λ ∑ i = 1 ∣ G L ∣ + ∣ G U ∣ L unsupervised ( h ϕ ( G i ) ; H ϕ ( G i ) ) \mathcal L = \sum_{i=1}^{|\mathcal G_L|}\mathcal L_\text{supervised}(y_\phi(G_i),\widehat y_i)+\lambda \sum_{i=1}^{|\mathcal G_L|+|\mathcal G_U|} \mathcal L_\text{unsupervised}(h_{\phi}(G_i);H_\phi(G_i)) L=i=1∑∣GL∣Lsupervised(yϕ(Gi),y i)+λi=1∑∣GL∣+∣GU∣Lunsupervised(hϕ(Gi);Hϕ(Gi))
其中无监督学习部分的损失函数定义为
L unsupervised ( h ϕ ( G i ) ; H ϕ ( G i ) ) = 1 ∣ G i ∣ ∑ u ∈ G i I ϕ , ψ ( h ϕ u ; H ϕ ( G i ) ) \mathcal L_\text{unsupervised}(h_{\phi}(G_i);H_\phi(G_i)) = \frac{1}{|G_i|}\sum_{u\in G_i} I_{\phi,\psi}(h^u_\phi;H_\phi(G_i)) Lunsupervised(hϕ(Gi);Hϕ(Gi))=∣Gi∣1u∈Gi∑Iϕ,ψ(hϕu;Hϕ(Gi))
为了防止发生 negative transfer ,即互信息与监督学习的优化方向不同,对监督学习和非监督学习部分分别在不同的参数上进行学习,并通过互信息监督两边学习到的图表示一致
L = ∑ i = 1 ∣ G L ∣ L supervised ( y ϕ ( G i ) , y ^ i ) + λ 1 ∑ i = 1 ∣ G L ∣ + ∣ G U ∣ L unsupervised ( h φ ( G i ) ; H φ ( G i ) ) − λ 2 ∑ i = 1 ∣ G L ∣ + ∣ G U ∣ 1 ∣ G i ∣ ∑ k = 1 K I ( H ϕ k ( G i ) ; H φ ( G i ) ) \mathcal L = \sum_{i=1}^{|\mathcal G_L|}\mathcal L_\text{supervised}(y_\phi(G_i),\widehat y_i)+\lambda_1 \sum_{i=1}^{|\mathcal G_L|+|\mathcal G_U|} \mathcal L_\text{unsupervised}(h_{\varphi}(G_i);H_\varphi(G_i))\\-\lambda_2 \sum_{i=1}^{|\mathcal G_L|+|\mathcal G_U|} \frac{1}{|G_i|}\sum_{k=1}^KI(H_{\phi}^k(G_i);H_\varphi(G_i)) L=i=1∑∣GL∣Lsupervised(yϕ(Gi),y i)+λ1i=1∑∣GL∣+∣GU∣Lunsupervised(hφ(Gi);Hφ(Gi))−λ2i=1∑∣GL∣+∣GU∣∣Gi∣1k=1∑KI(Hϕk(Gi);Hφ(Gi))
这种损失函数定义方式可以类比于学生-教师模型。在实际训练过程中,随机采样编码层来进行互信息最大化。
总结
这篇论文中的实验部分个人觉得做的很有问题,它比较的方法要么就和GNN没啥关系,要么就是比较老的GNN自监督学习的方法,而且看上去没有做消融实验,使用的GNN结构还是表示能力很强的GIN,结果没有太强的说服力。