8 年产品经验,我总结了这些持续高效研发实践经验 · 研发篇
**前言:**在产研全链路流程上,协同最大的目标就是团队信息的透明化,即在清晰目标的指引下进行团队信息透明的日常研发工作,助力项目/产品成功发布。基于此,研发过程是否行之有效就成为我们关注的另一重点要素。通常「研发过程」是指:代码到制品再到部署上线的全链路,这个过程是持续集成的重中之重。
本期主要围绕「研发过程」展开探讨,在具体分享实践之前,笔者想先和大家畅想讨论下,在软件研发全流程中,我们需要怎样的产品和特性来支撑我们持续去追求高效研发(本期主要围绕成本、效能,质量这块后续单独再做分析)的目标,个人思考了几点内容(部分内容会在正文的实践分享中详细说明),在此抛个砖让欢迎大家一起探讨。
思考一 支持团队把实践和文化通过自定义配置方式沉淀。
所有团队成员在使用产品功能的过程中,会潜移默化按照团队希望的实践路线进行。一方面,团队的研发是按既定路线进行的,研发效能是可预期的;另一方面,团队新人也能快速融入到团队开发模式中,快速融入团队文化。
思考二 在软件研发全链路中,应该具备高度自动化的能力。
研发全链路工作流中的各节点,通过高度自动化的能力,能实现以下目标:
- 除代码开发和项目管理事项信息录入外,尽量减少登录平台的手动操作;
- 自动精准消息的推送,借助端的能力,让用户本地异步订阅查看研发和项目管理信息。
思考三 强大且丰富的端能力。
让研发成员能够在本地沉浸式开发,目标要做到不感知 DevOps 平台存在的情况下,无时无刻不在使用平台能力。
思考四 产品能力和形态应该能够高度自定义化。
想通过一种产品形态去支撑覆盖所有的行业是不现实的,一个 DevOps 平台研发团队,不可能深入了解熟悉各行各业的研发模式,更不可能去定义实践去引领所有行业的研发提效。平台能做和需要做的是:把平台底层基础能力做强、做灵活,让不同业领导者,在高效持续交付的理论引导下,利用平台丰富的基础能力和高度自定义配置能力,去构建属于自己行业的研发实践模式,最终通过行业研发实践模式沉淀模版的可复制化,助力该行业整体研发效能的提升。
思考五 平台需要深度结合低代码开发平台,让应用研发变得更简单。
思考六 借助 AI 的能力,辅助提升用户代码开发、质量、安全、问题定位等应用研发过程效能。
思考七 结合大数据、AI、函数计算等技术特性,让研发效能度量、运维监控等观测能力变得更强大。
- 通过公有云或者企业级大数据、AI 和底层云计算能力的对接,让研发效能度量、监控数据统计的成本变得更低;
- 通过函数计算以低成本的方式满足用户对研发效能和监控数据的灵活统计诉求;
- 通过低代码开发平台 + DevOps 平台底层 Tracing、Logs、Metrics + 函数计算 + 数据可视化,让用户能够快速构建行业最佳实践的监控运维系统,通过模版可以复制到其他行业用户。
言归正传,接下来我将主要从「研发全链路」出发,分享一下 Erda 团队具体的实践过程,希望能给大家带来新的思考。
基于主干的开发模式
在研发模式方面,Erda 团队采用的是基于主干开发模式(Trunk Based Development),相对于主干开发模式还有特性分支开发模式(Feature Branch Development),其典型的代表就是 gitflow 模式。两者都是软件届常用的软件分支模式,各自有着各自的优缺点,选择适合自己的才是最重要的。Erda 团队选择基于主干开发模式的初衷,是想以持续集成的方式尽快发布版本,以及希望通过主干开发模式促成团队成为精英绩效团队。
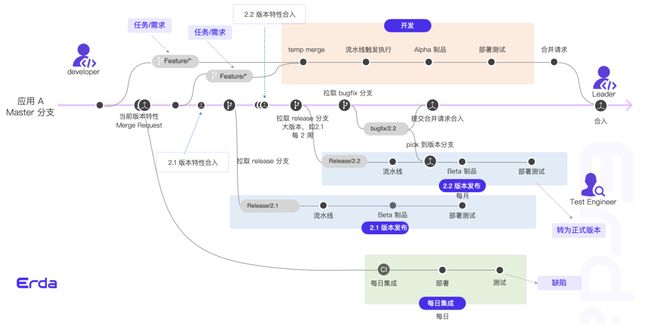
Erda 团队基于主干开发的目标:
- 每日有新代码合入主干,每日完成持续集成、持续测试
- 随时随刻能够提供可发布的版本,特性可以按需紧急发布上线
- 产品特性快速实现验证,减少试错成本
为了让团队通过主干开发模式来实现上述的目标,有两个实践要点非常重要:
- 项目协同的高要求:任务拆分(参考迭代事项协同中的任务颗粒度建议,尽量拆分到 1-2 天)需要足够小驱动 mr 变小,从而能从项目管理上支持产品特性快速实现验证和试错;
- 研发质量的高要求:特性开发的快,不能是牺牲质量的快,所以在这个快的前提下,对于合入的特性代码要求就会变的更高,这里的关键就是开发需要确保代码质量,不要想着把质量交给测试团队来保障 (建设自动化流程对规则、标准、规范进行自动检查;单元测试;数据库规范等等)。
实践要点分析后,接下来一起看看具体的实践步骤以及需要怎样的 DevOps 平台工具来支撑。
基于主干分支的代码研发
通过项目协同把需求进行任务拆分,研发同学认领任务后即进入开发工作,开发的首要工作就是创建一个特性分支(Feature/ 任务 ID)用于该特性的代码托管。OK,对于团队新成员来说可能开工第一步问题就来了
Feature 的源分支是谁?
团队采用的是主干分支的开发模式,自然就是从主干分支(Master)来拉取了,对于熟悉团队开发模式的同学来说,根本就不是问题,新同学只要通过培训或者自己去 google 学习一下也就明白了。
团队的实践和文化固然可以通过管理规范来进行约束来实现,不过古人也云“堵不如疏”,是否能够把这些实践规范约束在产品中定义?通过产品功能交互,引导用户按团队的预定的实践路线进行。Erda 团队就是这样实践的,效果还不错!
代码开发到提测的整体流程
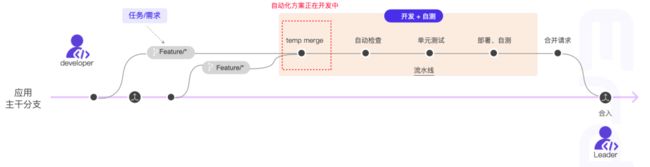
基于主干分支开发的规范配置
Erda 团队的研发规范是在产品的研发工作流中进行定义配置,内容涉及分支清单、分支策略和工作流配置,具体示意图如下:
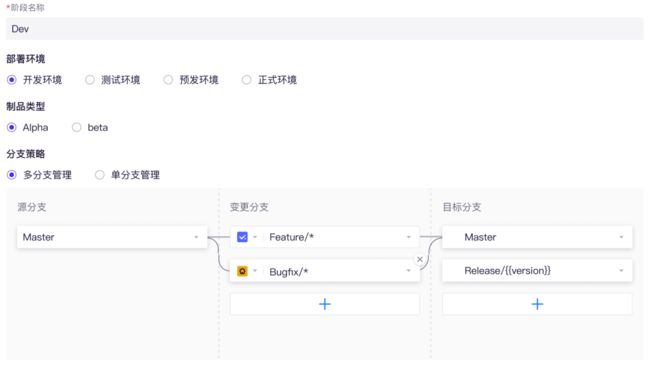
Erda 产品-研发工作流配置示意图
具体以产品实际交互为主
工作流具体配置内容:
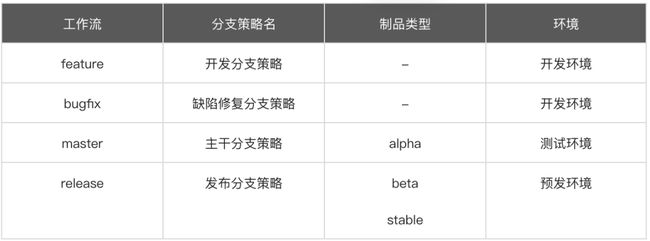
分支策略具体配置内容:
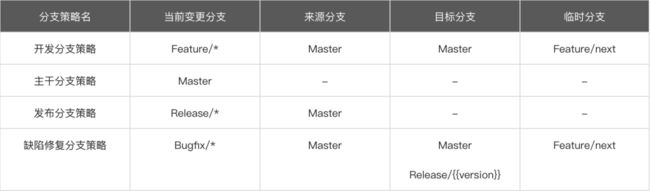
具体过程
- 研发同学在任务详情中,选择应用一键选择创建工作流。工作流创建后就会自动创建对应的开发分支(如feature/XXXX,其中 XXXX 代表特性 ID);
- 相同应用相同环境不同特性进行系统临时合并部署自测。通过 Erda 平台提供开发环境下相同应用不同特性分支的系统临时合并的功能,让所有特性研发同学可以一起部署和冒烟测试,在不影响效率的情况下大幅减少环境资源的压力;
- 通过研发自测后,工作流中可以一键发起 MR 合并请求,研发 TL 对合并请求相关分支 Code Review 后(因为任务工作流中事项和分支的关系绑定,Code Review 的时候可以清晰知道本次合并请求的具体任务内容),特性分支自动合入主干分支,主干分支通过定时/代码变更的触发器进行集成部署+测试,至此研发同学的特性任务状态也会自动完成。(上述特性正在开发中,目前以手动发起 MR 请求为主)。
基于主干分支的每日集成部署
通过 Erda 平台来支撑项目级每日持续集成部署。通过项目流水线,构建各应用最新制品(基于各应用主干最新代码)并集成为项目整体制品进行自动化的部署到统一的主干测试环境(Erda 叫集成环境)。
部署的策略为每日 23 时,定时触发流水线运行构建、集成、部署 (其他项目也可以根据实际情况设定其他的部署策略)。
基于主干分支的每日持续测试
自动化测试
- 用例管理
根据需求的 deadline ,测试同学会基于研发同学的特性完成时间,去安排自动化测试用例(主要是是基于 API 接口的测试)和功能测试用例的作成。在研发同学特性分支合并到主干分支后,测试同学会在原有的测试计划上追加新特性的自动化测试用例,已有的自动化测试用例回归确保之前特性的可用性。
- 自动化测试执行
那么每日持续测试如何触发?
即通过部署测试流水线中的 action,触发自动化测试计划的执行。
- 自动化测试结果通知
自动化测试结果通过钉钉同步给研发团队。

手动功能测试
自动化测试并不能百分之百覆盖所有的产品特性,而对于自动化无法覆盖的特性,就需要手动完成。功能性测试是需要实打实投入测试同学人力去一遍遍手动覆盖的,且不说必要性,人力成本可能就是敏捷团队所不能容忍的。对于这样的场景,Erda 团队在手动功能性测试方面主要采用以下策略:
- 针对迭代新功能需要手动功能测试覆盖,主要是测试团队对当前迭代的需求内容进行针对性的测试;
- 测试团队基于需求、任务的状态来判断每日新增的大概内容 (erda 测试团队甚至被要求关注开发提交的 MR/PR,对测试团队的要求是更高的)。
基于主干分支的制品管理策略
通常意义上的「软件制品」主要是源码文件的集合或者编译后的产物,主要包括二进制包和压缩包两种形式。如果基于 Erda 平台,制品的概念上稍微有点难以区别,我们主要定义为包含部署一个应用所需的全部内容,包括镜像、依赖的 Addon 以及各类配置信息,最终的目的就是通过制品能够在任何一套 Erda 上进行环境级别的部署。
这里暂时不去分析和讨论制品的定义和具体的功能点(如对产品制品管理功能有兴趣的同学可以联系我们继续讨论),还是回归到主题,以分享 Erda 团队对于制品管理的实践为主。
语义化版本管理
首先在制品版本和类型的管理上,团队主要采用的是「语义化版本」管理规范,主要涉及以下几种版本类型:
- alpha:仅仅是研发自测通过,未经过测试的版本,不稳定的版本
- beta:阶段性测试通过,相对稳定的版本
- stable:经过系统性测试,稳定的发布版本
版本和分支的关系
其次,制品版本和分支上做了强实践的绑定(主要通过研发工作流配置完成)。不管制品如何定义,肯定是基于代码或者编译产物的基础,也就是说制品肯定是从代码来的。所以 Erda 团队在实践中是把分支和制品类型进行绑定关联的,并且把这个以最佳实践沉淀到 Erda 产品中,当然产品支持研发工作流的自定义配置来满足其他特性分支和制品版本类型的关联。
Erda 团队的研发模式是基于主干研发的模式,所以分支和版本类型的关系如下:
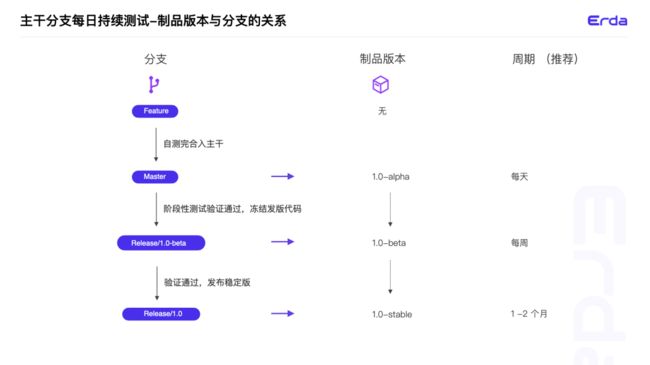
如果采用 Gitflow 可以参考如下:
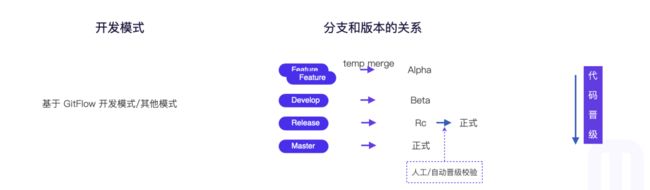
版本和分支的配置
分支和制品版本的配置:在研发工作流中配置
主要过程说明:
- 研发同学在 feature 分支上开发完成后,并在开发环境上完成自测,代码合入到主干分支(Master);
- 主干分支(Master)通过每日定时触发器执行流水线,会自动构建生成【版本号 + alpha +时间戳】的制品;
- 迭代版本所有的特性代码都合入到主干分支(Master),并且通过自动化测试用例及测试同学手动功能阶段性测试后,测试同学会从主干分支(Master)上切出迭代版本的 Release 分支(分支名:Release/版本号-beta+递增数字),时间频率取决于团队的发布频率(Erda 团队的发布频率是每周,所以这边的时间频率就是每周);
- 当迭代版本进行到一定周期后,产品一般会对外发布一个正式的版本(这个版本可以是上面一个迭代版本,也可以由多个迭代版本组成,这个取决于产品的版本发布计划,Erda 产品的一个大的 Rc 版本由 4 个迭代 beta 版本的特性组成),测试同学会从主干分支(Master)切出Release 分支(分支名:Release/版本号)进行全面测试;
- 测试同学通过 Release/版本号分支流水线构建部署该分支的 beta 制品,在通过测试验证后,测试同学会手动把该 beta 版本制品切换为 stable 版本,并且在制品中维护好制品的 ChangeLog 和制品标签,最终发布到 Gallery 提供的交付团队下载使用。

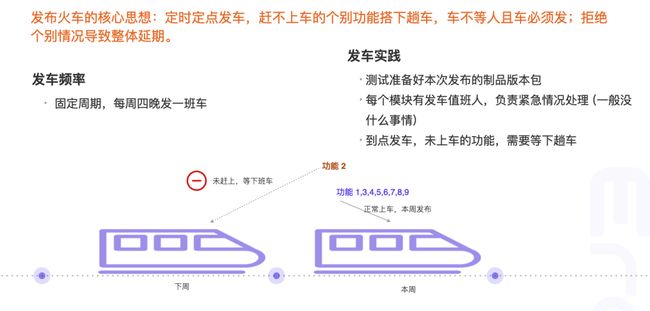
发布火车
概念和规则
发布火车,通常是指设定固定的发布窗口,具体可以按周或者按月固定一个时间,在这个时间进行定时发布,产品特性能够赶上这趟火车就发布,否则就需要等下趟火车。
发布火车的规则看似非常简单,只要固定时间发布即可,其实不然,团队并不能通过一个发布火车的概念就能让发布变得高效,真正能驱动团队高效发布的还需从建立团队的发布文化开始,文化又依托于发布规则的沉淀:
- 定时定点发车。火车不等特性,拒绝未经测试的新特性上车;
- 只发布高质量的特性。只有测试通过的特性才允许上车,即使研发已经完成相关特性并且要求上线的时候,也要坚决拒绝;
- 频繁发布火车,特性拆分的足够小。更快更小的发布能够让产品的质量更高、成本更低,频繁发布使每次发布的特性变小,出现问题的时候定位和解决也会变得更明确和高效,当然发布的频率需要根据团队的研发和管理整体质量决定,不是一味地追求快;
- 世界没有完美的发布,需要有明确的关键性能指标来决策争议特性的发布。
Erda 团队实践
基于以上的规则,Erda 团队的实践如下:
小结
不管从项目协同、研发全流程以及到最后的发布火车,其本质目标还是希望能够以高效的方式去支撑应用软件持续快速、高质量的更新发布,为了这个目标,每家公司都有自己的实践和见解,没有对和错之说,只要符合企业当下利益最大化,能够布局企业的未来即可。本文只是以 Erda 一个团队视角进行了分享,欢迎大家可以一起参与分享讨论研发提效的实践,共同促进整个行业效能的提升,谢谢!
更多技术干货请关注【尔达 Erda】公众号,与众多开源爱好者共同成长~