muduo网络库—分布式系统知识精要
目录
-
-
-
- 1、编译期常量
- 2、定义类型并使用
- 3、分布式网络问题——TCP Incast问题
- 4、分布式网络问题——Fat-tree网络拓扑
- 5、分布式系统和单机系统的区别
- 6、如何做到负载均衡
- 7、分布式系统时间与时间顺序违反直觉
- 8、能随时重启进程作为程序设计目标
- 9、如何重启
- 10、分布式中心跳协议
- 11、有状态服务和无状态服务
- 12、 SO_REUSEADDR
- 13、 socket的四个地址信息
- 14、分布式系统中的进程标识
- 15、linux procfs
- 15、易于维护的分布式系统
- 16、为系统演化做准备
- 17、分布式程序的自动化回归测试
- 18、rsync远程数据同步
- 18、分布式系统部署、监控与进程管理的几种境界
-
-
- 1)全手工操作
- 2)使用零散的自动化脚本和第三方组件
- 3)自制机群管理系统,集中化配置
- 4)机群管理与naming service结合
-
-
-
1、编译期常量
const int getconst()
{
return 1;
}
void testfun(int n)
{
int arr[getconst()] = { 0 };//无法通过编译
switch (n)
{
case getconst()://无法通过编译
{
//.......
}break;
default:
break;
}
}
可以使用c++11里面的关键字
constexpr int getconst()
{
return 1;
}
2、定义类型并使用

3、分布式网络问题——TCP Incast问题
每个数据块都分割到分布式许多服务器上,因此每个服务器都存储了一个较小的数据块。
首先,由于高带宽和低时延,在需要数据的客户端向存储数据的服务器发送数据请求后,这些服务器几乎同时向客户端发送数据,导致大量数据流同时涌向网络。又由于交换机缓冲区空间有限,这种流量很容易就会将其溢出,接着发生丢包,TCP 通过超时重传进行恢复。超时的时间通常至少要几百毫秒。需要超时重传的服务器会进入超时等待。由于同步的传输模式,多个服务器可能会同时进入这种等待。因此在等待的这段时间内,链路几乎处于完全空闲状态,这就导致链路的不充分利用,以及吞吐量的急剧下降。
解决办法:要么使用高缓存的交换机,要么采用一些算法策略
其实一个数据中心的网络都是使用clos/Fat-tree网络拓扑结构
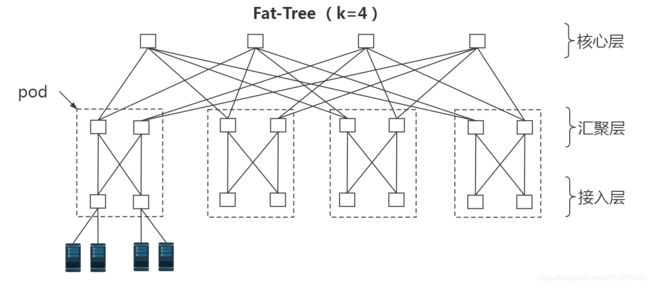
4、分布式网络问题——Fat-tree网络拓扑
参考与
Fat-Tree是以交换机为中心的拓扑。支持在横向拓展的同时拓展路径数目;且所有交换机均为相同端口数量的普通设备,降低了网络建设成本。
Fat-Tree结构共分为三层:核心层、汇聚层、接入层。一个k元的Fat-Tree可以归纳为5个特征:
- 每台交换机都有k个端口;
- 核心层为顶层,一共有(k/2)^2个交换机;
- 一共有k个pod,每个pod有k台交换机组成。其中汇聚层和接入层各占k/2台交换机;
- 接入层每个交换机可以容纳k/2台服务器,因此,k元Fat-Tree一共有k个pod,每个pod容纳kk/4个服务器,所有pod共能容纳kk*k/4台服务器;
- 任意两个pod之间存在k条路径。
常见的有2元、4元、6元等结构。
这是k =4 的结构
这是k = 8的结构

5、分布式系统和单机系统的区别
分布式系统不是用网络连起来的放大的单击系统,因为单机没有部分故障,对于单机我们能轻易地判断某个进程某个硬件是否还在正常工作,但是在分布式系统中,这是无解的。我们无法及时获得另外一台机器的死活,也无法将机器崩溃和网络故障分开。
6、如何做到负载均衡
1、一个服务响应一个客户端,会有一个 满负荷,其他都闲着的情况

2、让每个web服务器与后台服务器联系,但是如何能做到负载均衡

处理的一些想法
1)轮流从第一个开始,走马灯一样移动,但是会造成第一台始终在忙碌状态
2)使用随机数挑选。但是随机数是伪随机数,也会造成潮涌现象
3)让后台服务器向前台服务器汇报当前负载情况。但是这样消息数目和服务器数目呈平方关系
4)通过某个几种的负载均衡器来收集并分发负载情况。但是会造成单点故障现象。
具体解决办法:
客户端不需要知道服务器负载的情况,只需要知道后台响应自己的请求速度就知道下一个请求应该发给谁。具体就是选择活动请求数目最少的服务端。
客户端把服务端看成一个循环队列 ,在选择服务端时,从上次调用的服务端的下个位置进行遍历,找出负载最轻的服务端。

7、分布式系统时间与时间顺序违反直觉
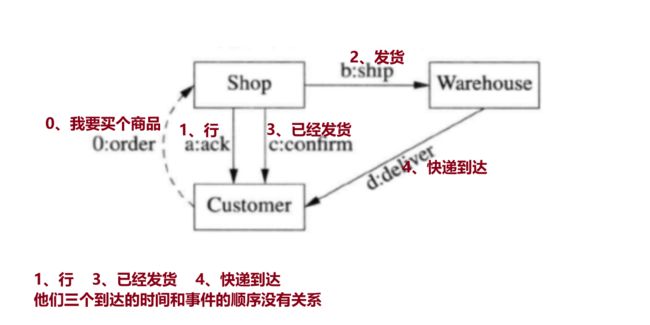
此外。在局域网内,消息的传输时延不能通过发送方和接收方时间戳的差值算出来,因为NTP对时间的精度是1毫秒,但是消息延迟也在1毫秒内,延迟差不多,所以测量结果毫无意义。
8、能随时重启进程作为程序设计目标
硬件和软件都不允许程序长期运行,那么程序在设计的时候必须要清楚重启进程的方式和代价。
9、如何重启

另一种升级软件做法是迁移,先启动一个新版本的服务进程,让旧版本大的服务局进程停止接收新请求,把所有心情求都导向新进程。
10、分布式中心跳协议
使用TCP连接作为分布式系统中进程间通信的唯一方式,好处是任何一方进程意外退出时对方能及时得到连接断开的通知。如果一方进程意外断开,那么这一方的操作系统会关闭使用中的TCP socket,并向对方发送FIN分节。但是也是需要应用层的心跳的。原因有
- 如果操作系统在发送FIN前操作系统崩溃或者硬件故障,没有机会发送
- 如果并发连接数很高,但是由于重启没有机会断开全部连接
TCP 的keepalive机制不能代替应用层心跳,心跳能够保证对方或者并且能够正常工作,但tcp keepalive只能保证活着,但对进程死锁并不管。
1、心跳通常是服务端向客户端发送心跳。心跳消息很像看门狗,只有不断逗狗才能防止电路复位。如果接收方最后一次收到心跳消息的时间与当前时间之差超过某个timeout值,就会判断对方心跳失效。判断这个也会有延迟,不存在超过timeout立即就能检测出来,这是分布式系统的本质困难。
如果保守一点,用两次检查都失效则认证故障。这反映了内在矛盾:高置信度和低反应时间不可兼得。
2、心跳消息中应该加上发送时间,防止出现消息传输过程累积造成假心跳。
3、闰秒的影响,为了加一秒,这将在分布式系统中两台机器在发生闰秒时出现时间差。闰秒的插入点是12月31日或者 6月30日。
心跳协议在实现上两个关键点:
1)在工作线程上发送,不要单起一个心跳线程(防止死锁),应该注册周期定时器回调,然后在线程池中post一个任务,该任务发送信条消息。
2)与业务消息用同一个连接,不要单独使用心跳连接(要验证收发业务数据的tcp连接顺畅。)
11、有状态服务和无状态服务
服务一般分为有状态服务(Stateful Service)和无状态服务(Stateless Service)。它们的区别是,当请求发起后,服务在服务端运行时是否需要关联上下文。
有状态服务,服务端需要保存请求的信息,并且其它请求还可以使用已保存的信息。
无状态服务,服务端处理逻辑中所需要的数据,全部来此本次请求中带的信息。虽然服务端也保存了一些信息,但是这些信息要么与请求无关,要么所有请求都可以公用。
12、 SO_REUSEADDR
这是一个选项,用于解决Address already in use。一般来说,一个端口释放后会等待两分钟之后才能再被使用,SO_REUSEADDR是让端口释放后立即就可以被再次使用。
产生后者的原因有:
-
服务器启动后,有客户端连接并已建立,如果服务器主动关闭,那么和客户端的连接会处于TIME_WAIT状态,此时再次启动服务器,就会bind不成功,报:Address already in use。
-
服务器父进程监听客户端,当和客户端建立链接后,fork一个子进程专门处理客户端的请求,如果父进程停止,因为子进程还和客户端有连接,所以再次启动父进程,也会报Address already in use。
上面两种情况都是TCP套接字处于TIME_WAIT状态下的socket,也只有在这种状态下,使用这个选择才可以重复绑定使用
13、 socket的四个地址信息
一个socket包含四个地址信息: 两台计算机的IP地址和两个进程所使用的端口(port)。IP地址用于定位计算机,而port用于定位进程 (一台计算机上可以有多个进程分别使用不同的端口)。
在服务器端,我们使用bind()方法来赋予socket以固定的地址和端口,并使用listen()方法来被动的监听该端口。当有客户尝试用connect()方法连接的时候,服务器使用accept()接受连接,从而建立一个连接的socket
14、分布式系统中的进程标识
进程的标识符应该与已消亡的进程不通过,新进程应该与它的前世进程的状态不同。
一般有的端口是静态分配的,比如3306留给mysqld,但也有动态分配端口号,因为端口号只有六万个。
错误做法
ip:port
host:pid
使用ip:port标识一个静态分配的进程没有关系,但是对于动态的就不行,尤其是设置了SO_REUSEADDR,可能上一分钟你在用着服务,下一分钟由于对方重启,端口换成了另外一个服务。
host:pid,pid是递增的,遇到上限后才会到最小的pid,但是换汤不换药,照样有可能换成了另外一个服务。
甚至ip:port:pid也不能做到唯一,虽然ip:port这部分在重启后不会变,但是pid有可能会轮回。
正确做法是用四元组 ip:port:start_time:pid作为分布式系统中进程的gpid。
这个想法是通过tcp协议来的,一个socket是有两个ip:port,但是为了防止起一次同样地址的连接的,tcp协议使用seq号码区分本次连接和以往的连接。
15、linux procfs
Linux系统/proc目录下,有一些特殊的目录和文件,用来展示或者设置内核数据。例如,/proc/meminfo展示系统内存信息,这些数据随着系统的变化动态调整
15、易于维护的分布式系统
分布式系统中的每个长期运行的、会与其他机器打交道的进程都应该提供一个管理接口,对外提供一个维修探查通道,可以查看进程的全部状态。一种具体的做法是在程序里内置HTTP服务器,能查看基本的进程健康状态与当前负载,包括活动连接及其用途,能从root set开始查到每一个业务对象的状态。这种做法类似Java的JMX,又类似memcached的stats命令。
这样暴露内部数据就很像linxu procfs,而如果暴露以http最好,因为可以远程访问而不用登录到这台机器上。
16、为系统演化做准备
1、消息格式可以扩展
1)不要在消息中加入版本号,否则代码中会有一堆堆难以维护的switch-case

2)在通过tcp连接不要发送c struct或者使用bit fields
c struct如果新加一些元素那么就要求客户端和服务端一块升级,另一个原因是不夸语言,如果客户端和服务端用不同语言来写,那么解析这种消息格式很麻烦,对于同步稍不注意会有格式混乱。
具体解决办法是 可以使用中间语言,如果是文本可以用json或者xml,如果用二进制格式可以用google protocol buffers。
文本格式一个常见问题就是处理转义字符
google protocol buffers定义的消息格式有可选字段,一举解决服务端和客户端升级的难题,新版的服务端可以定义一些可选选项,根据请求这些字段的存在与否来实施不同的行为,即可以同时兼容旧版和新版的客户端。
17、分布式程序的自动化回归测试
自动化测试的作用是将程序已经实现的特征固化下来,将来任何代码改动破坏了现有的功能需求将触发测试错误。
单元测试很麻烦,比如碰到多线程,一些错误场景无法测试。
冒烟测试:对一个硬件或硬件组件进行更改或修复后,直接给设备加电。如果没有冒烟,则该组件就通过了测试。在软件中,“冒烟测试”这一术语描述的是在将代码更改嵌入到产品的源树中之前对这些更改进行验证的过程。在检查了代码后,冒烟测试是确定和修复软件缺陷的最经济有效的方法。冒烟测试设计用于确认代码中的更改会按预期运行,且不会破坏整个版本的稳定性。
18、rsync远程数据同步
参考链接
rsync是什么
rsync(remote synchronize)是Liunx/Unix下的一个远程数据同步工具。
它可通过LAN/WAN快速同步多台主机间的文件和目录,并适当利用rsync算法(差分编码)以减少数据的传输。
rsync算法并不是每一次都整份传输,而是只传输两个文件的不同部分,因此其传输速度相当快。
除此之外,rsync可拷贝、显示目录属性,以及拷贝文件,并可选择性的压缩以及递归拷贝。
工作原理
a、客户端构造FileList,FileList包含了需要与服务器同步的所有文件信息对name->id
(id用来唯一表示文件例如MD5)
b、客户端将FileList发送到服务器。
c、服务器上rsync处理客户端发过来的FileList,构建新的NewFileList。
其中根据MD5值比较,删除服务器上已经存在的文件信息对,只保留服务器上不存在或变化的文件。
d、客户端得到服务器发送过来的NewFileList,然后把NewFileList中的文件重新传输到服务器。
18、分布式系统部署、监控与进程管理的几种境界
这里约定host为服务器硬件,webserver和suduku 为服务器软件
1)全手工操作
系统规模不大,十来台机器上下,host的ip地址是静态配置的。
部署: 将可执行文件 拷贝到各个机器上,或者放到公用的NFS目录下
管理:手工启动,重启时需要登录到host并kill进程
升级:重新部署并重启
配置:webserver的配置文件中写上solver服务的ip:port
监控:无
2)使用零散的自动化脚本和第三方组件
公司内网有DNS,可以将hostname解析为ip地址,host的ip地址由dhcp配置
机器安装的包和第三方文件版本号完全一样。
使用ssh看机器上可执行文件是否相同

部署 :可执行文件需要经过QA质量部签署才能部署到生产环境中,可能采用rsync将文件拷贝到本机目录。用md5sum检查拷贝的文件是否相同
管理 :第一次启动进程时会从SVN check-out配置文件,以后重启后从本地备份读取配置文件(防止svn服务器故障),服务进程用守护进程方式管理,故障后会立即重启( 通过给守护进程设置 respawn参数),服务进程随着服务器硬件的启动而启动(/etc/init.d),每台服务器能够运行那些service完全由/etc/init.d目录决定。
升级 :有版本管理,升级时不能覆盖已有的可执行文件
配置 :Web Server的配置文件里写上 Sudoku Solver的host:port
监控:使用监控工具(例如Monit),但是判断进程是通过轮询完成的
配置依赖关系很棘手,依赖作者会知道程序依赖那些服务,但是被依赖不好办,但是用tcp就可以通过netstat找到现在的客户
3)自制机群管理系统,集中化配置
整合现有运维工具,开发一套自己的机群管理软件
部署:发送一条指令,自动rsync新的可执行文件到本地目录
进程管理和监控:提供一个接口(可以是http)以供查看
升级:直接发送指令,不需要ssh&kill
配置:配置文件会制定哪些service会在哪些host上运行
对于host:port可以用一个很笨的方法,在内核动手脚,让两台机器共享一个ip,通过专门的心跳连线来控制哪台host对外提供服务,哪台是备用机。
4)机群管理与naming service结合
摆脱host:port的束缚,用分布式系统特制的naming service代替DNS