IOC/DI、AOP相关原理
文章目录
- IOC/DI
-
- 为什么IOC就降低了耦合性
- AOP
-
- 原理
- 使用
-
- AOP的名词们
-
- 概念性名词
-
- JoinPoint/Target
- Introduction
- Proxy
- Weaving
- 在代码中有对应注解的名词
-
- Aspect
- Pointcut(在哪儿切)
- Advice(什么时候切)
- 示例代码
IOC/DI
IOC全称是Inversion of Control 就是控制反转的意思,DI全称是Dependency Injection就是依赖注入的意思。这俩其实是对同一个原理的不同解释,实际上是一回事。DI注入的方式有Setter注入、构造方法注入和注解注入三种。
在传统的程序中当我们需要通过对象去调用某个类的方法时都是这样,在需要某个对象时new一个对象然后调用它,比如这样:
public class Test{
public void save(){
ManagerObject managerObj= new ManagerObject ();
managerObj.insert();
}
public void remove(){
ManagerObject managerObj= new ManagerObject ();
managerObj.delete();
}
}
然后这么一来如果Test类中有20处使用到了ManagerObject这个方法就需要new20次,如果ManagerObject的方法中还调用了别的类对象,这么一来错综复杂的依赖就会像这样。

从这个代码来看虽然起到了代码逻辑复用,但是却没实现资源复用,每一个链路都创建了同样的对象,造成了极大的资源浪费。本应多个 Controller 复用同一个 Service,多个 Service 复用同一个 DAO。现在变成了一个 Controller创建多个重复的 Service,多个 Service 又创建了多个重复的 DAO,从倒三角变成了正三角。

许多组件只需要实例化一个对象就够了,创建多个没有任何意义。针对对象重复创建的问题,我们自然而然想到了单例模式。只要编写类时都将其写为单例,这样就避免了多例模式造成的资源浪费。但是,引入设计模式必然会带来复杂性,况且还是每一个类都为单例,每一个类都会有相似的代码,其弊端不言自明。而且这样还有个致命的弊端就是假如某个接口的实现类变了,需要再每个调用的地方都改一遍。
简单来讲,总归于这么三大问题:
1、创建了许多重复对象(多例模式),造成大量资源浪费;
2、更换实现类需要改动多个地方;
3、创建和配置组件工作繁杂,给组件调用方带来极大不便。
为了解决这三个问题,Spring做了这么一件事,就是把创建对象的过程交给Spring来维护,用户只需要跟Spring将我需要用什么对象即可,无需关心这个对象的创建过程,依赖的这个对象由Spring注入进来,这个过程就是控制反转和依赖注入。当对象交给Spring容器来管理时,默认是单例的,解决了问题1,然后我们只需要告诉Spring我们需要的对象的名字就可以了不需要关心实现,若要更换实现类,只需更改 Bean 的声明配置,即可达到无感知更换,也就解决了问题2,然后创建和配置都交给Spring来处理,无需每个类都写单例的构造方法,解决了问题3。
public class Test{
@AutoWired
private MangerService managerService;
public void save(){
managerService.insert();
}
public void remove(){
managerService.delete();
}
}
@Service("managerService") //若要更换实现类,只需更改 Bean 的声明配置,即可达到无感知更换
public class ManagerServiceImpl implements MangerService {
@AutoWired
private ManagerDao managerDao;
public void insert() {
managerDao.save();
}
public void delete() {
managerDao.delete();
}
}
}
现在组件的使用和组件的创建与配置完全分离开来。调用方只需通过@AutoWired来调用组件而无需关心其他工作,@AutoWired会先根据类型匹配,如果有多个实现类再根据限定符和名字匹配,如果重名则抛出异常程序启动不起来。(@AutoWired的实现原理看这篇文章,已经写得很详细了)这极大提高了我们的开发效率,也让整个应用充满了灵活性、扩展性,并且降低了耦合性。
为什么IOC就降低了耦合性
耦合性就是各个类之间有着相互关联的依赖关系。高耦合就是牵一发而动全身,比如上面讲到通过ManagerObject managerObj= new ManagerObject ();的方式调用对象,假如ManagerObject类中调整了某个方法的参数则调用方都得跟着改,如果MangerObject类中的方法如果想换实现类则调用的地方也得跟着全改,这就是耦合度很高。
后来出现了使用接口的形式,即ManagerService manager = new ManagerServiceImpl();那这个时候如果想换个实现类,则只需要改下后面的实现类即可,调用的方法名还是原来接口定义的方法名,改动比之前有所降低,耦合度也相比第一种似乎降低了不少,但是这样还是得在每个声明这个依赖关系的地方都改下调用的实现类。
再后来出现了工厂模式,就是工厂配置好接口和实现类,然后调用A实现类的地方传A的名字,在调用B实现类的地方传B的名字,工厂根据配置的实现类通过反射给创建好返回回去,实现类怎么换都跟调用处没有代码上的关联,这样一来耦合度再次降低。Spring的IOC通过工厂模式+反射+配置文件实现了,因此降低了耦合性。
AOP
原理
AOP的全称是Aspect Oriented Programming,意思是面向切面编程。是Spring的重要思想之一,是在面向对象编程的基础上衍生而来,针对每个对象都需要做的工作抽取成一个截面,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。常用于日志打印、权限校验、统计访问量等这种公共性的地方。假如我们需要在访问前校验下是否有权限并且访问时打印下日志,如果按常规的套路应该是这样,判断权限和记录日志的代码在每个类的每个方法都会重复出现多次:
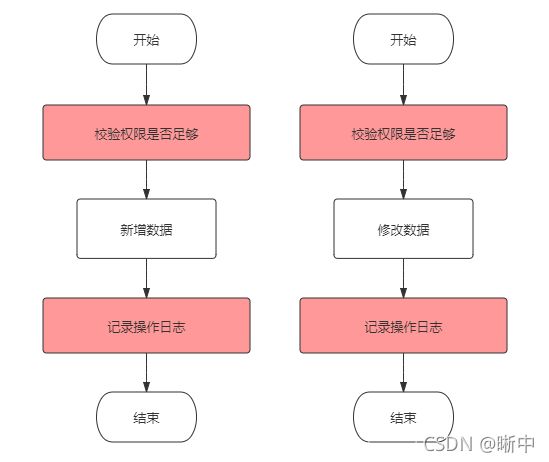
当采用了AOP的思想后代码应该是这个样:

那使用AOP切面无非就是以下几个步骤:1、在哪切;2、啥时候切;3、切了干啥。下面将按照这个顺序讲一下AOP的使用。
使用
AOP的名词们
AOP理论中有很多名词,官方文档对这些名词的解释,大多数人刚开始看拆开每个字都认识但是合在一起就不认识了。下面我把这些名词分成了两部分,一类是概念性名词,这部分名词在实际编码中不会有对应的代码实现,就是一个概念,还有一类是在代码中有对应代码实现或有对应注解的名词。这个图囊括了AOP的名词概念:

概念性名词
JoinPoint/Target
JoinPoint和Target实际上是一回事,这名词有些像PointCut,它的意思是连接点,简单点说就是可以定义为切点的任何地方都是连接点,PointCut是在他的基础上经过条件筛选后的连接点。形象话的例子就是特殊人群(军人及警察)买火车票可以不排队,军人或者警察就相当于是PointCut而他们的统称特殊人群就相当于JointPoint。
Introduction
这个名词的意思是引入,说白了就是切面实现的功能。一般通过AOP统一定义切面功能时,基本都会用到@Pointcut,而@PointCut一般会修饰一个空的方法,在配合Advide使用,而这个空的方法就是相当于实际要调用的方法,这个下面的示例代码会讲到。
Proxy
这个指的是Spring通过动态代理的方式实现了AOP,涉及的内容比较难也比较多,此处不在深究其内部原理。
Weaving
就是将切面应用到目标对象从而创建一个新的代理对象的过程。或者可以理解为把切面的代码和业务代码合并形成一个新的对象来执行的过程。织入方式有编译时织入、类加载时织入、运行时织入三种方式,Spring采用的是运行时织入。织入原理相关文章可以参考这个
在代码中有对应注解的名词
上面的是一些理论性的概念名词,而这部分是真正在编写代码时会用到的东西
Aspect
Aspect就是切面,对应的注解为@Aspect。这个注解是标记在类上的,意思就是被这个注解标记的类就是切面,这个类里面包含了什么时候在什么地方去进行切面处理,以及处理的内容,这三部分组成了Aspect。
Pointcut(在哪儿切)
Pointcut就是切点,就是在什么地方切面。对应的注解为@Pointcut,@Pointcut注解的value可以是@annotation还可以是@execution,annotation代表在使用了某个注解的地方进行切面处理,这个注解可以是自定义注解也可以是官方注解。execution代表在某个方法或者类上进行切面处理。具体的用法继续往下面看有代码更详细些。
Advice(什么时候切)
Advice文档解释是叫通知,其实就是什么时候切,比如Pointcut指定了在某个类的某个方法出进行处理,然后Advice的作用就是在执行这个方法前处理还是执行后处理,或者是抛出异常时处理等等。对应的注解有多个:
@Before是在方法前处理,
@After是在方法后处理,
@AfterReturning也是在方法后处理,但是与@After不同的是它可以改变原来方法的返回值,而@After不能改变原有方法的返回值。
@AfterThrowing是抛出异常时处理
@Around是一个比较强大的处理,它实际上是@Before、@After、@AfterReturning的结合体,意思就是用这个注解时你可以吧@Before、@After、@AfterReturning的内容合到一起。Around增强处理可以决定目标方法在什么时候执行,如何执行,甚至可以完全阻止目标方法的执行。当定义一个Around增强处理方法时,该方法的第一个形参必须是ProceedJoinPoint类型(至少含有一个形参),在增强处理方法体内,调用ProceedingJoinPoint参数的procedd()方法才会执行目标方法——这就是Around增强处理可以完全控制方法的执行时机、如何执行的关键;如果程序没有调用ProceedingJoinPoint参数的proceed()方法,则目标方法不会被执行。@Around功能虽然强大,但通常需要在线程安全的环境下使用或者配合原子类使用。因此,如果使用普通的Before、AfterReturning就能解决的问题,就没有必要使用Around了。如果需要目标方法执行之前和之后共享某种状态数据,则应该考虑使用Around。尤其是需要使用增强处理阻止目标的执行,或需要改变目标方法的返回值时,则只能使用Around增强处理了。
示例代码
/**
* 定义一个类并用@Aspect标注,那这个类就是一个切面,这个类里面包含了 Pointcut和Advice,
* 如果有多个@Order可以定义执行顺序,数字越小执行优先级越高。
* 引入的切面及切面实现的功能就是上面提到的Introduction
*/
@Aspect
@Order(1)
public class TxAspect
{
@Pointcut("@annotation(com.test.SysLog) || @within(com.main.SysLog)")
public void logPointCut() {
// 不需要写函数体,这个方法其实就代表了我们用@SysLog注解标记的那个方法
}
@Around("logPointCut()")
public Object logAround(ProceedingJoinPoint joinPoint) throws Throwable {
/**
*这里面就是切面真正实现的功能,比如调整参数、记录访问日志还可以调整返回参数等等
*/
System.out.println("执行目标方法之前,模拟开始事务...");
// 获取目标方法原始的调用参数
Object[] args = jp.getArgs();
if(args != null && args.length > 1)
{
// 修改目标方法的第一个参数
args[0] = "【增加的前缀】" + args[0];
}
// 以改变后的参数去执行目标方法,并保存目标方法执行后的返回值
Object rvt = jp.proceed(args);
System.out.println("执行目标方法之后,模拟结束事务...");
// 如果rvt的类型是Integer,将rvt改为它的平方
if(rvt != null && rvt instanceof Integer)
rvt = (Integer)rvt * (Integer)rvt;
return rvt;
}
@Before("com.test.TxAspect.logPointCut()")
public void beforeTest(JoinPoint joinPoint) {
//在进入logPointCut()之前执行
log.info("xxx登录了");
}
@After("com.test.TxAspect.logPointCut()")
public void after(JoinPoint joinPoint) {
//在执行完logPointCut()之后执行
log.info("xxx退出了");
}
}