Ububtu18.04安装Hadoop3.1.3全分布集群-持续更新问题集
Ububtu18.04安装Hadoop3.1.3全分布集群
- 摘要
- Ububtu18.04安装
-
- 1.选择NAT网络
- 2.关闭防火墙
- 3.SSH连接
- 4.配置静态IP
- 4.使用hadoop用户
- 5.设置主机名
- 6.配置/etc/hosts文件
- 7.更新 apt
- 8.安装SSH、配置SSH无密码登陆
- 9.Ubuntu 18.04有线连接未托管
- Hadoop安装
-
- 1.准备
- 2.具体过程
-
- 1.三台虚拟机的初始设置
- 2.在master节点安装JDK
- 3.在master节点安装Hadoop
- 4.克隆master到slave1和slave2,并配置静态IP
-
- 节点slave1:
- 节点slave2:
- 5.克隆后配置分布式免密
- 3.启动测试
- 4.报错以及解决方案
-
- 问题1:/usr/bin/env: "bash": 没有那个文件或目录
- 问题2:Cannot set priority of namenode process 15335
摘要
本文主要基于Ububtu18.04完成Hadoop3.1.3的安装,并附带遇到的问题以及解决方案,目的在于读者可以根据本文无缝的完成集群部署,有遇到问题,请留言,看到会及时回复,如果有新的内容,本文会持续更新。
Ububtu18.04安装
本步骤网络教程较多,这里不再描述,如有需要再详细描述。
安装Ubuntu18.04的注意事项为:
1.选择NAT网络
我的NAT网关为192.168.33.2
2.关闭防火墙
sudo ufw status verbose #非管理员需加sudo即可
3.SSH连接
#如果ssh无法连接,可以安装openssh-server
sudo apt install openssh-server -y
4.配置静态IP
搭建完全分布式Hadoop,需要固定的ip地址,故有此文。
一、进入命令终端,执行ifconfig命令,ip地址192.168.33.130,ens33是网卡信息,这个网卡信息再后面用得到,因为有不同的网卡,有的是ens37,所以在配置时要根据自己的机器网卡信息配置。
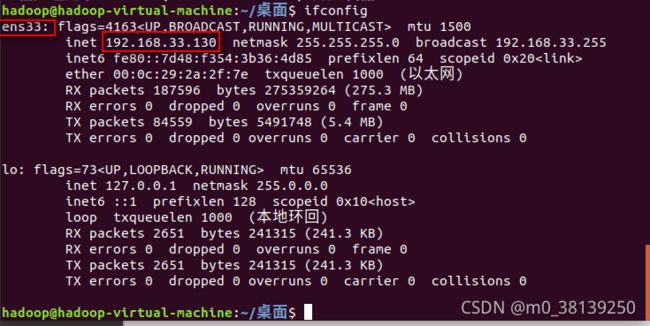
二、配置静态ip
cd /etc/netplan
ls
#返回,这个文件不用修改
01-network-manager-all.yaml
# 创建02-config.yaml文件,添加静态ip
sudo vi 02-config.yaml
#
进入02-config.yaml的编辑界面,yaml格式有严格要求,只需要修改192.168.33.130/24中的130部分就行。我的三台机器分别是130,131和132
network:
version: 2
renderer: networkd
ethernets:
ens33:
addresses:
- 192.168.33.130/24
gateway4: 192.168.33.2
nameservers:
addresses: [8.8.8.8, 1.1.1.1]
三、执行sudo netplan apply来使得配置生效
如果这一步出错,说明上一步的vi 02-config.yaml有问题,格式不对,可以参考错误信息百度查找。
sudo netplan apply
四、再次查看ip:ifconfig
可以查看到静态IP配置完毕
4.使用hadoop用户
如果在创建虚拟机时就指定了hadoop用户,就不用执行本步骤,否则可以安装如下步骤执行:
如果你安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
1.首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
#创建hadoop 用户,并使用 /bin/bash 作为 shell
sudo useradd -m hadoop -s /bin/bash
# 修改hadoop密码,这里设置为123456
sudo passwd hadoop
# 为hadoop用户添加sudo权限
sudo adduser hadoop sudo
#使用hadoop用户登录
在创建虚拟机时,我已经创建了hadoop用户,顾以上命令不用执行
5.设置主机名
# 临时设置hostname
hostname master
# 永久设置hostname
vi /etc/hostname
# 填写hostname值 192.168.33.130中为 master
6.配置/etc/hosts文件
# 编辑/etc/hosts
sudo vi /etc/hosts
# 设置如下,这样配置便于后面克隆虚拟机
192.168.33.130 master
192.168.33.131 slave1
192.168.33.132 slave2
7.更新 apt
建议参考
https://blog.csdn.net/zhangjiahao14/article/details/80554616
8.安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
1.安装SSH server
sudo apt-get install openssh-server
2.安装后,登陆本机:
ssh master
此时会有如下提示(SSH首次登陆提示),输入 yes ,然后需要输入密码
3.配置成SSH无密码登陆
exit # 退出刚才的 ssh localhost
# 若没有该目录,请先执行一次ssh localhost
cd ~/.ssh/
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权方法1
# 加入授权方法2 或这种方法
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
4.无需输入密码,直接登陆
此时再用 ssh master命令,无需输入密码就可以直接登陆了
hadoop@hadoop-virtual-machine:~/.ssh$ ssh master
Welcome to Ubuntu 18.04.4 LTS (GNU/Linux 5.3.0-28-generic x86_64)
9.Ubuntu 18.04有线连接未托管
参考:
https://blog.csdn.net/p1279030826/article/details/116328260
解决:
1、编辑 interfaces:
sudo vim /etc/network/interfaces
确定文件里面只保留下面的内容:
# interfaces(5) file used by ifup(8) and ifdown(8)
auto lo
iface lo inet loopback
2、编辑 NetworkManager.conf:
sudo vim /etc/NetworkManager/NetworkManager.conf
将managed改为true,修改后的NetworkManager.conf:
[main]
plugins=ifupdown,keyfile
[ifupdown]
managed=true
[device]
wifi.scan-rand-mac-address=no
3、分析:查看NetworkManager的配置:
sudo NetworkManager --print-config
里面有一项内容,显示NetworkManager管理的设备情况:
[keyfile]
unmanaged-devices=*,except:type:wifi,except:type:wwan
这表示配置文件里只有无线设备,没有有线网卡。
4、修改这个文件:
sudo vim /usr/lib/NetworkManager/conf.d/10-globally-managed-devices.conf
在语句中添加
找到“unmanaged-devices”一行,在最后添加
,except:type:ethernet
[keyfile]
unmanaged-devices=*,except:type:ethernet,except:type:wifi,except:type:wwan
然后运行
sudo systemctl restart NetworkManager
Hadoop安装
1.准备
Ubuntu 18.04 64位
Hadoop版本:Hadoop3.1.3
hadoop集群搭建详细过程(完全分布式)
1.上面已经配置ubuntu安装,静态IP配置,免密登录等操作
下面提供hadoop3.1.3和jdk8的安装百度网盘
链接:https://pan.baidu.com/s/1oja60SdCYOGKoLZZSRTBfA
提取码:2021
--来自百度网盘超级会员V7的分享
2.具体过程
1.三台虚拟机的初始设置
搭建分布式主要用三台虚拟机:master、slave1、slave2,可以先不进行克隆,等一台机器配置好后克隆再到相应的机器去修改。
master目前配置:
hostname为master
配置静态IP,静态IP为192.168.33.130
免密登录已经完成
关闭防护墙
用户名为hadoop,密码为123456
配置/etc/hosts文件,并在该文件中标注了
> 192.168.33.130 master
192.168.33.131 slave1
192.168.33.132 slave2
2.在master节点安装JDK
解压下载的jdk文件到 /home/hadoop/opt/app/jdk目录下
hadoop@master:~/$ tar zxf jdk-8u162-linux-x64.tar.gz -C ~opt/app/jdk
编辑~./bashrc文件,快捷键G可快速切换到在文件尾部
sudo vim ~./bashrc #修改当前用户即可
配置JAVA_HOME等环境变量
export JAVA_HOME=/home/hadoop/opt/app/jdk
export JRE_HOME=/home/hadoop/opt/app/jdk/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
输入下面的命令测试是否配置成功:
java -version
成功信息:
3.在master节点安装Hadoop
Hadoop有三种运行模式,这只讲完全分布式的配置。
具体三种模式可见:
https://blog.csdn.net/zane3/article/details/79829175
解压官网下载Hadoop的压缩包
hadoop@master:~/下载$ tar -zxf hadoop-3.1.3.tar.gz -C ~/opt/app/
编辑~./bashrc文件,快捷键G可快速切换到在文件尾部
sudo vim ~./bashrc #修改当前用户即可
配置HADOOP_HOME等环境变量
export HADOOP_HOME=/home/hadoop/opt/app/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
编辑Hadoop目录下的子目录etc/Hadoop目录文件Hadoop-env.sh文件:
将JAVA_HOME设为jdk所在绝对路径(否则运行时可能会出现找不到的情况)
export JAVA_HOME=/home/hadoop/opt/app/jdk
单机测试:
# 查看版本号
hadoop@master:~/opt/app/hadoop$ hadoop version
hadoop@master:~/opt/app/hadoop$ cd /home/hadoop/opt/app/hadoop
hadoop@master:~/opt/app/hadoop$ mkdir ./input
# 将配置文件作为输入文件
hadoop@master:~/opt/app/hadoop$ cp ./etc/hadoop/*.xml ./input
# 测试MR程序
hadoop@master:~/opt/app/hadoop$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep ./input ./output 'dfs[a-z.]+'
hadoop@master:~/opt/app/hadoop$ cat ./output/*
# 输出如下表示正确
1 dfsadmin
伪分布安装:
接着配置Hadoop的四个配置文件(core-site.xml ,mapred-site.xml,hdfs-site.xml,yarn-site.xml,对应Hadoop的四个主要组成部分:核心包,HDFS文件系统,MapReduce模型,yarn资源调度框架)
core-site.xml的配置:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/opt/app/hadooptmp</value>
</property>
</configuration>
hdfs-site.xml配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
若是没有该文件,使用复制命令从当前目录下模板复制(可选)
cd ~/opt/app/hadoop
cp ./etc/hadoop/mapred-site.xml.template hadoop/etc/hadoop/mapred-site.site.xml
mapred-site.xml配置:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml配置(初始可不设置):
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
在该目录下/home/hadoop/opt/app/hadoop/etc/hadoop目录下添加workers文件,文件内容为:
master
slaves1
slaves2
4.克隆master到slave1和slave2,并配置静态IP
克隆master到slave1和slave2
克隆后需要修改slave1和slave2的静态ip,配置方案为
节点slave1:
配置静态IP
cd /etc/netplan
ls
#返回,这个文件不用修改
01-network-manager-all.yaml
# 创建02-config.yaml文件,添加静态ip
sudo vi 02-config.yaml
#
进入02-config.yaml的编辑界面,yaml格式有严格要求,slave1节点设置为131
network:
version: 2
renderer: networkd
ethernets:
ens33:
addresses:
- 192.168.33.131/24
gateway4: 192.168.33.2
nameservers:
addresses: [8.8.8.8, 1.1.1.1]
执行
sudo netplan apply
来使得配置生效
节点slave2:
配置静态IP
cd /etc/netplan
ls
#返回,这个文件不用修改
01-network-manager-all.yaml
# 创建02-config.yaml文件,添加静态ip
sudo vi 02-config.yaml
#
进入02-config.yaml的编辑界面,yaml格式有严格要求,slave2节点设置为132
network:
version: 2
renderer: networkd
ethernets:
ens33:
addresses:
- 192.168.33.132/24
gateway4: 192.168.33.2
nameservers:
addresses: [8.8.8.8, 1.1.1.1]
执行
sudo netplan apply
来使得配置生效
5.克隆后配置分布式免密
将master,slave1,slave2节点的公钥都发给给master节点,注意执行的节点
# 将各个节点的公钥发给hadoop@master节点
# master节点
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@master
# slave1节点
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@master
# slave2节点
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@master
将合并在hadoop@master节点的公钥分发给slave1和slave2节点
# master节点执行,将公钥分发为slave1和slave2节点
scp -r ~/.ssh/authorized_keys hadoop@slave1:~/.ssh/authorized_keys
scp -r ~/.ssh/authorized_keys hadoop@slave2:~/.ssh/authorized_keys
在master,slave1,slave2节点分别重启ssh服务
service sshd restart
3.启动测试
在master节点上执行格式化命令
hadoop namenode -format
会在master,slave1,slave2节点上的路径下看到格式化后的
dfs目录
在master执行启动hdfs命令
start-dfs.sh
然后在各个节点上依次执行
jps
可以查看到启动的节点
其中master节点有
namenode
datanode
secondarynamenode
jps
其中slave1节点有
datanode
jps
其中slave2节点有
datanode
jps
打开浏览器
http://192.168.33.130:9870
即可查看到如下信息,到此,安装完毕
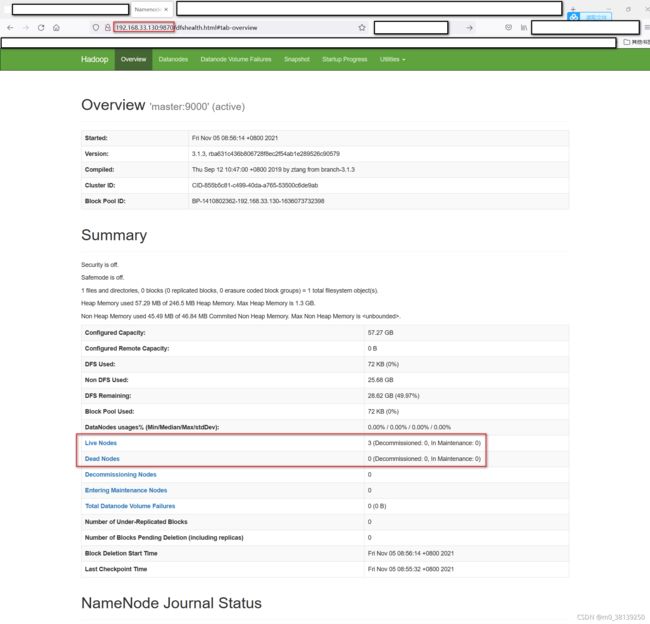
②使用start-dfs.sh
4.报错以及解决方案
问题1:/usr/bin/env: “bash”: 没有那个文件或目录
需要注意的是,执行前,查看自己的环境变量是否设置正确
Starting secondary namenodes [master]
master: /usr/bin/env: "bash": 没有那个文件或目录
hadoop@master:~/opt/app/hadoop$ ls -l `which sh`
lrwxrwxrwx 1 root root 4 11月 4 11:05 /bin/sh -> dash
hadoop@master:~/opt/app/hadoop$ su root
密码:
su:认证失败
hadoop@master:~/opt/app/hadoop$
hadoop@master:~/opt/app/hadoop$ sudo dpkg-reconfigure dash
正在删除 dash 导致 /bin/sh 转移到 /bin/sh.distrib
正在添加 bash 导致 /bin/sh 转移到 /bin/sh.distrib
正在删除 dash 导致 /usr/share/man/man1/sh.1.gz 转移到 /usr/share/man/man1/sh.distrib.1.gz
正在添加 bash 导致 /usr/share/man/man1/sh.1.gz 转移到 /usr/share/man/man1/sh.distrib.1.gz
hadoop@master:~/opt/app/hadoop$ ls -l `which sh`
lrwxrwxrwx 1 root root 4 11月 4 15:43 /bin/sh -> bash
同时查看自己的环境变量是否设置正确。
问题2:Cannot set priority of namenode process 15335
本解决方案参考网络,链接有些不记得了,以后找到再给补上。
需要注意的是,执行前,查看自己的环境变量是否设置正确
hadoop@master:~/opt/app/hadoop$ start-dfs.sh
Starting namenodes on [master]
master: ERROR: Cannot set priority of namenode process 15335
Starting datanodes
slaves1: ssh: Could not resolve hostname slaves1: Name or service not known
slaves2: ssh: Could not resolve hostname slaves2: Name or service not known
Starting secondary namenodes [master]
master: ERROR: Cannot set priority of secondarynamenode process 15735
解决方案
在$HADOOP_HOME/etc/hadoop/hadoop-env.sh最后一行加上HADOOP_SHELL_EXECNAME=hadoop,否则该环境变量默认值为hdfs。同时其他涉及USER的变量也改成hadoop,例如:
export HDFS_DATANODE_USER=hadoop
export HADOOP_SECURE_DN_USER=hadoop
export HDFS_NAMENODE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
另外,又发现一个地方会导致此问题,vi $HADOOP_HOME/bin/hdfs会发现脚本前几行有个地方如下:
HADOOP_SHELL_EXECNAME="hadoop"
如果您在安装过程中有遇到什么问题,可以留言,有时间会及时回复。