seaborn可视化入门
seaborn可视化入门
-
- 案例部分
-
- 案例01-pairplot对图
- 案例02-heatmap热力图
- 案例3boxplot箱型图
- 案例4violin小提琴图
- 案例5 Density plot密度图
案例部分
案例01-pairplot对图
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import os
os.chdir(os.path.dirname(__file__)) # 切换目录到当前文件所在目录
# seaborn预设了darkgrid,whitegrid,dark,white,ticks五种主题风格
sns.set(style="ticks")
iris = pd.read_csv('iris.csv',header=None)
iris.columns=['sepal_length','sepal_width',
'petal_length','petal_width','species']
# iris传入的数据集,类型为DataFrame
# hue="species" hue观点,代表用来充当标签或类别的字段
# diag_kind="kde" 对角线图形的类别,默认有hist频率分布直方图,kde核密度估计图
# palette="muted"表示预制的调色板,
sns.pairplot(iris,hue="species",diag_kind="kde",
palette="muted")
plt.show()

案例02-heatmap热力图
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import os
os.chdir(os.path.dirname(__file__)) # 切换目录到当前文件所在目录
plt.figure(figsize=(6,6))
iris = pd.read_csv('iris.csv',header=None)
iris.columns=['sepal_length','sepal_width',
'petal_length','petal_width','species']
data = iris[['sepal_length','sepal_width',
'petal_length','petal_width']]
iris_corr = data.corr()
sns.heatmap(iris_corr,annot=True,square=True,fmt='.2f',) # square:单元格是否方形
plt.show()

案例3boxplot箱型图
什么是箱线图:

import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import os
os.chdir(os.path.dirname(__file__)) # 切换目录到当前文件所在目录
#方案1:利用pandas读取数据
sns.set(style = "ticks")
iris = pd.read_csv('iris.csv', header = None)
iris.columns=['sepal_length','sepal_width','petal_length','petal_width','species']
sns.boxplot(x = iris['sepal_length'], data = iris)
plt.show()

多个箱线图:
import seaborn as sns, matplotlib.pyplot as plt
import pandas as pd
import os
os.chdir(os.path.dirname(__file__)) # 切换目录到当前文件所在目录
#用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams["axes.unicode_minus"]=False # 显示负号
# sns.set(font='SimHei') # sns中乱码问题
# sns.set_style({'font.sans-serif':['SimHei','Arial']})
#导入数据集合
sns.set(style = "ticks")
iris = pd.read_csv('iris.csv', header = None)
iris.columns=['sepal_length','sepal_width','petal_length','petal_width','species']
#设置x轴、y轴及数据源
ax = sns.boxplot(x = "species", y = "sepal_length", data=iris)
# 计算每组的数据量和中位数显示的位置
#medians = iris.groupby(['species'])['sepal_length'].median().values #和下面的语句等价
medians = iris.pivot_table(index="species", values="sepal_length",aggfunc="median").values
# print(medians)
# #[5. 5.9 6.5]
# print(ax.get_xticklabels())
# [Text(0, 0, 'Iris-setosa'), Text(1, 0, 'Iris-versicolor'), Text(2, 0, 'Iris-virginica')]
#形成要显示的文本:每个子类的数量
nobs = iris['species'].value_counts().values
nobs = [str(x) for x in nobs.tolist()]
nobs = ["nobs:" + i for i in nobs]
# 设置要显示的箱体图的数量
pos = range(len(nobs))
#将文本分别显示在中位数线条的上方
for tick,label in zip(pos, ax.get_xticklabels()):
# tick分别取值 0 1 2 代表x的坐标
# medians[tick] 对应[5. 5.9 6.5],代表y的坐标
# nobs[tick] 表示标注的值
# horizontalalignment 水平对齐
ax.text(pos[tick], medians[tick] + 0.03, nobs[tick],
horizontalalignment='center', size='x-small',
color='w', weight='semibold')
plt.show()

import seaborn as sns, matplotlib.pyplot as plt
import pandas as pd
#导入数据集合
import os
os.chdir(os.path.dirname(__file__)) # 切换目录到当前文件所在目录
#用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams["axes.unicode_minus"]=False # 显示负号
#导入数据集合
sns.set(style = "ticks")
df = pd.read_csv('iris.csv', header = None)
df.columns=['sepal_length','sepal_width','petal_length','petal_width','species']
# sharey = True 共享Y轴,共享后便于比较
fig,axes=plt.subplots(1,2,sharey = True) #一行两列共两个子图
sns.boxplot(x = "species",y = "petal_width",data = df,ax = axes[0]) #左图
sns.boxplot(x = "species",y = "petal_length",data = df, palette="Set2", ax = axes[1]) #右图
plt.show()

案例4violin小提琴图
小提琴图:

【小提琴图】其实是【箱线图】与【核密度图】的结合,【箱线图】展示了分位数的位置,【小提琴图】则展示了任意位置的密度,通过【小提琴图】可以知道哪些位置的密度较高。
小提琴图的内部是箱线图(有的图中位数会用白点表示,但归根结底都是箱线图的变化);外部包裹的就是核密度图,某区域图形面积越大,某个值附近分布的概率越大。
通过箱线图,可以查看有关数据的基本分布信息,例如中位数,平均值,四分位数,以及最大值和最小值,但不会显示数据在整个范围内的分布。如果数据的分布有多个峰值(也就是数据分布极其不均匀),那么箱线图就无法展现这一信息,这时候小提琴图的优势就展现出来了!
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
os.chdir(os.path.dirname(__file__)) # 切换目录到当前文件所在目录
# 导入数据
iris = pd.read_csv("iris.csv")
iris.columns=['sepal_length','sepal_width','petal_length','petal_width','species']
# 绘图
sns.violinplot(x='species', y = 'sepal_length', data = iris, split = True, scale='width', inner="box")
# 输出显示
plt.title('Violin Plot', fontsize=10)
plt.show()

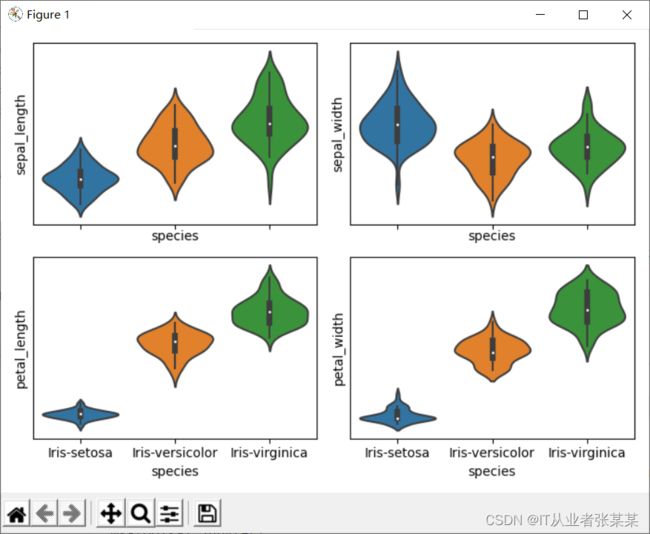
多个小提琴图:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 导入数据
import os
os.chdir(os.path.dirname(__file__)) # 切换目录到当前文件所在目录
iris = pd.read_csv("iris.csv")
iris.columns=['sepal_length','sepal_width','petal_length','petal_width','species']
# 绘图设置
fig, axes = plt.subplots(2, 2, figsize=(7, 5), sharex=True)
sns.violinplot(x = 'species', y = 'sepal_length',
data = iris, split = True,
scale='width', inner="box",
ax = axes[0, 0])
sns.violinplot(x = 'species', y = 'sepal_width',
data = iris, split = True, scale='width',
inner="box",
ax = axes[0, 1])
sns.violinplot(x = 'species', y = 'petal_length',
data = iris, split = True, scale='width',
inner="box",
ax = axes[1, 0])
sns.violinplot(x = 'species',
y = 'petal_width',
data = iris, split = True,
scale='width', inner="box",
ax = axes[1, 1])
# 输出显示
plt.setp(axes, yticks=[])
plt.tight_layout()
plt.show()
案例5 Density plot密度图
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
# 导入数据
import os
os.chdir(os.path.dirname(__file__)) # 切换目录到当前文件所在目录
iris = pd.read_csv("iris.csv")
iris.columns=['sepal_length','sepal_width','petal_length','petal_width','species']
#绘图
# shade=False 密度线内是否用阴影填充
# vertical= True表示垂直显示
sns.kdeplot(iris.loc[iris['species'] == 'Iris-versicolor', 'sepal_length'],
shade=False, vertical = True, color="g", label="Iris-versicolor", alpha=.7)
sns.kdeplot(iris.loc[iris['species'] == 'Iris-virginica', 'sepal_length'],
shade=False, vertical = True, color="deeppink", label="Iris-virginica", alpha=.7)
sns.kdeplot(iris.loc[iris['species'] == 'Iris-setosa', 'sepal_length'],
shade=False, vertical = True, color="dodgerblue", label="Iris-setosa", alpha=.7)
# Decoration
plt.title('鸢尾花花瓣长度的密度图', fontsize=16)
plt.legend()
plt.show()
