TensorRT量化第二课:对称量化与非对称量化
目录
- 模型量化原理
-
- 注意事项
- 一、2023/3/30更新
- 前言
- 1.引出问题
-
- 1.1 问题
- 1.2 代码实现
-
- 1.2.1 初始化输入数组
- 1.2.2 Scale计算
- 1.2.3 量化截断
- 1.2.4 反量化
- 1.2.5 完整代码
- 2. 非对称量化
-
- 2.1 动态范围量化
- 2.2 代码实现
- 2.3 原理分析
-
- 2.3.1 动态量化范围
- 2.3.2 偏移量Z
- 2.3.3 图例分析
- 3.对称量化
-
- 3.1 相关知识
- 3.2 代码实现
- 3.3 思考
- 4.对称量化 vs. 非对称量化
- 总结
模型量化原理
注意事项
一、2023/3/30更新
新增对称量化方法处理量化过程中值域截断问题
前言
手写AI推出的全新TensorRT模型量化课程,链接。记录下个人学习笔记,仅供自己参考。
本次课程为第二课,主要讲解量化的具体方法。课程有些抽象呀,自己结合ChatGPT学习了一下。
课程大纲可看下面的思维导图
1.引出问题
1.1 问题
正常模型量化的流程是计算Scale=>量化=>截断=>反量化,上节课中提出这样做会存在一个问题,那就是量化截断操作后,反量化获取的值与原来的值有一个较大的误差,这将对模型的精度影响非常大。
量化的流程中的计算公式如下所示:
S c a l e = ( R m a x − R m i n ) ( Q m a x − Q m i n ) Q = R o u n d ( R S c a l e ) Q = C l i p ( Q , − 128 , 127 ) R ′ = Q ∗ S c a l e (1) \begin{aligned} Scale &= \frac{(Rmax-Rmin)}{(Qmax-Qmin)} \\ Q &= Round(\frac{R}{Scale}) \\ Q &= Clip(Q,-128,127) \\ R' &= Q * Scale \end{aligned} \tag1 ScaleQQR′=(Qmax−Qmin)(Rmax−Rmin)=Round(ScaleR)=Clip(Q,−128,127)=Q∗Scale(1)
现在假设有一个数组[ 1.6243454 -0.6117564 -0.5281718]为float32类型,需要将其量化到int8类型即[-128 127]范围,首先计算下Scale的值为0.008769,然后计算下其量化的结果为[185. -70. -60.],由于量化的结果超出了int类型[-128 127]的范围,所以进行截断,截断后的结果为[127. -70. -60.],利用阶段后的结果进行反量化后的值为[ 1.1136664 -0.6138319 -0.52614164],原始值和量化反量化恢复的值相差[-0.510679 -0.00207549 0.00203013],可以看到数组中第一个数值相差了将近原数值的三分之一,这样量化后的结果肯定是不行的。需要解决方法。
1.2 代码实现
1.2.1 初始化输入数组
代码如下:
import numpy as np
if __name__ == "__main__":
np.random.seed(1)
data_float32 = np.random.randn(3).astype('float32')
int_max = 127
int_min = -128
print(f"input = {data_float32}")
1.2.2 Scale计算
代码如下:
def scale_cal(x, int_max, int_min):
scale = (x.max() - x.min()) / (int_max - int_min)
return scale
1.2.3 量化截断
代码如下:
import numpy as np
def saturete(x, int_max, int_min):
return np.clip(x, int_min, int_max)
def quant_float_data(x, scale, int_max, int_min):
xq = saturete(np.round(x/scale), int_max, int_min)
return xq
1.2.4 反量化
代码如下:
def dequant_data(xq, scale):
x = ((xq)*scale).astype('float32')
return x
1.2.5 完整代码
完整示例代码如下:
import numpy as np
def saturete(x, int_max, int_min):
return np.clip(x, int_min, int_max)
def scale_cal(x, int_max, int_min):
scale = (x.max() - x.min()) / (int_max - int_min)
return scale
def quant_float_data(x, scale, int_max, int_min):
xq = saturete(np.round(x/scale), int_max, int_min)
return xq
def dequant_data(xq, scale):
x = ((xq)*scale).astype('float32')
return x
if __name__ == "__main__":
np.random.seed(1)
data_float32 = np.random.randn(3).astype('float32')
int_max = 127
int_min = -128
print(f"input = {data_float32}")
scale= scale_cal(data_float32, int_max, int_min)
print(f"scale = {scale}")
data_int8 = quant_float_data(data_float32, scale, int_max, int_min)
print(f"quant_result = {np.round(data_float32 / scale)}")
print(f"saturete_result = {data_int8}")
data_dequant_float = dequant_data(data_int8, scale)
print(f"dequant_result = {data_dequant_float}")
print(f"diff = {data_dequant_float - data_float32}")
输出如下:
input = [ 1.6243454 -0.6117564 -0.5281718]
scale = 0.008769026924582089
quant_result = [185. -70. -60.]
saturete_result = [127. -70. -60.]
dequant_result = [ 1.1136664 -0.6138319 -0.52614164]
diff = [-0.510679 -0.00207549 0.00203013]
2. 非对称量化
2.1 动态范围量化
首先来看下解决方案,通过引入偏移量Z可以解决。具体公式如下:
S c a l e = ( R m a x − R m i n ) ( Q m a x − Q m i n ) Z = Q m a x − R o u n d ( R m a x S c a l e ) Q = R o u n d ( R S c a l e + Z ) Q = C l i p ( Q , − 128 , 127 ) R ′ = ( Q − Z ) ∗ S c a l e (2) \begin{aligned} Scale &= \frac{(Rmax-Rmin)}{(Qmax-Qmin)} \\ Z &= Qmax - Round(\frac{Rmax}{Scale}) \\ Q &= Round(\frac{R}{Scale} + Z) \\ Q &= Clip(Q,-128,127) \\ R' &= (Q -Z) * Scale \end{aligned} \tag2 ScaleZQQR′=(Qmax−Qmin)(Rmax−Rmin)=Qmax−Round(ScaleRmax)=Round(ScaleR+Z)=Clip(Q,−128,127)=(Q−Z)∗Scale(2)
我们先来看下这种解决方案下的反量化结果,首先输入数组不变为[ 1.6243454 -0.6117564 -0.5281718],还是需要将其量化到int8范围即[-128 127],scale还是0.008769,z根据公式计算为-58,量化后的结果为[127 -128 -118],反量化后的结果为[ 1.62227 -0.6138319 -0.52614164],偏差为[-0.00207543 -0.00207549 0.00203013],可以看到加入了Z偏移量后的误差明显减小了。
2.2 代码实现
完整示例代码如下:
import numpy as np
def saturete(x, int_max, int_min):
return np.clip(x, int_min, int_max)
def scale_z_cal(x, int_max, int_min):
scale = (x.max() - x.min()) / (int_max - int_min)
z = int_max - np.round((x.max() / scale))
return scale, z
def quant_float_data(x, scale, z, int_max, int_min):
xq = saturete(np.round(x/scale + z), int_max, int_min)
return xq
def dequant_data(xq, scale, z):
x = ((xq - z)*scale).astype('float32')
return x
if __name__ == "__main__":
np.random.seed(1)
data_float32 = np.random.randn(3).astype('float32')
int_max = 127
int_min = -128
print(f"input = {data_float32}")
scale, z = scale_z_cal(data_float32, int_max, int_min)
print(f"scale = {scale}")
print(f"z = {z}")
data_int8 = quant_float_data(data_float32, scale, z, int_max, int_min)
print(f"quant_result = {data_int8}")
data_dequant_float = dequant_data(data_int8, scale, z)
print(f"dequant_result = {data_dequant_float}")
print(f"diff = {data_dequant_float - data_float32}")
输出如下:
input = [ 1.6243454 -0.6117564 -0.5281718]
scale = 0.008769026924582089
z = -58.0
quant_result = [ 127. -128. -118.]
dequant_result = [ 1.62227 -0.6138319 -0.52614164]
diff = [-0.00207543 -0.00207549 0.00203013]
2.3 原理分析
2.3.1 动态量化范围
上述方法通常被称为动态范围量化(Dynamic Range Quantization)中的校准过程(Calibration)。它属于非对称量化的一种形式。由于量化参数(比如量化因子Scale)是通过数据集的统计量来估计的,因此称之为动态范围量化。它能够减少量化误差的原因是,引入了一个偏移量Z,使得量化后的数值在更小的范围内,进而减小量化误差。同时,偏移量Z的计算使得量化后的最大值Rmax落在了Qmax上,保证了最大值的精度。
2.3.2 偏移量Z
我们来分析下为什么偏移量Z的定义是 Z = Q m a x − R o u n d ( R m a x S c a l e ) Z = Qmax - Round(\frac{Rmax}{Scale}) Z=Qmax−Round(ScaleRmax)(from ChatGPT,不知道是否准确)
偏移量Z的公式来源于将Rmax和Rmin映射到量化后的Qmax和Qmin的过程中,可能会出现浮点数误差带来的截断误差,进而导致量化误差的累积(也就是截断误差带来的影响)。为了消除这种误差,我们引入了偏移量Z,即将Rmax映射到Qmax所需要的偏移量。那么,这个偏移量Z应该怎么计算呢?推导过程如下:
首先,将实数Rmax映射到量化后的整数Qmax的公式为:
Q m a x = ⌊ R m a x S c a l e ⌋ Qmax=\lfloor\frac{Rmax}{Scale}\rfloor Qmax=⌊ScaleRmax⌋
其中Scale表示量化的尺度,即:
S c a l e = R m a x − R m i n Q m a x − Q m i n Scale = \frac{Rmax-Rmin}{Qmax-Qmin} Scale=Qmax−QminRmax−Rmin
类似的,我们将Rmin映射到Qmin:
Q m i n = ⌊ R m i n S c a l e ⌋ Qmin=\lfloor\frac{Rmin}{Scale}\rfloor Qmin=⌊ScaleRmin⌋
于是,我们可以将Qmax和Qmin带入上面的Scale公式中,得到:
S c a l e = R m a x − R m i n ⌊ R m a x S c a l e ⌋ − ⌊ R m i n S c a l e ⌋ Scale=\frac{Rmax-Rmin}{\lfloor\frac{Rmax}{Scale}\rfloor-\lfloor\frac{Rmin}{Scale}\rfloor} Scale=⌊ScaleRmax⌋−⌊ScaleRmin⌋Rmax−Rmin
注意到这个Scale是一个带有floor函数的分式,其中floor函数会对Rmax和Rmin进行取整操作。这个取整操作带来的误差是我们想要消除的。我们假设将Rmax映射到Qmax需要的偏移量为Z,则:
Q m a x = ⌊ R m a x S c a l e + Z ⌋ Qmax=\lfloor\frac{Rmax}{Scale}+Z\rfloor Qmax=⌊ScaleRmax+Z⌋
将Scale带入上式中,得到:
Q m a x = ⌊ R m a x R m a x − R m i n ⌊ R m a x S c a l e ⌋ − ⌊ R m i n S c a l e ⌋ + Z ⌋ Qmax=\lfloor\frac{Rmax}{\frac{Rmax-Rmin}{\lfloor\frac{Rmax}{Scale}\rfloor-\lfloor\frac{Rmin}{Scale}\rfloor}}+Z\rfloor Qmax=⌊⌊ScaleRmax⌋−⌊ScaleRmin⌋Rmax−RminRmax+Z⌋
对上式进行简化:
Q m a x = ⌊ R m a x ⌊ R m a x S c a l e ⌋ − R m a x [ R m i n S c a l e ⌋ R m a x − R m i n + Z ⌋ Qmax=\lfloor\frac{Rmax\lfloor\frac{Rmax}{Scale}\rfloor-Rmax[\frac{Rmin}{Scale}\rfloor}{Rmax-Rmin}+Z\rfloor Qmax=⌊Rmax−RminRmax⌊ScaleRmax⌋−Rmax[ScaleRmin⌋+Z⌋
由于我们希望Z是一个整数,因此我们对Z进行取整,得到:
Z = Q m a x − ⌊ R m a x ⌊ R m a x S c a l e ⌋ − R m a x [ R m i n S c a l e ⌋ R m a x − R m i n ⌋ Z = Qmax - \lfloor\frac{Rmax\lfloor\frac{Rmax}{Scale}\rfloor-Rmax[\frac{Rmin}{Scale}\rfloor}{Rmax-Rmin}\rfloor Z=Qmax−⌊Rmax−RminRmax⌊ScaleRmax⌋−Rmax[ScaleRmin⌋⌋
将Scale代入其中,得到:
Z = Q m a x − ⌊ R m a x S c a l e ⌋ Z= Qmax - \lfloor\frac{Rmax}{Scale}\rfloor Z=Qmax−⌊ScaleRmax⌋
即:
Z = Q m a x − R o u n d ( R m a x S c a l e ) Z = Qmax - Round(\frac{Rmax}{Scale}) Z=Qmax−Round(ScaleRmax)
其中, Q m a x Qmax Qmax是量化后的取值范围的最大值, R o u n d ( R m a x S c a l e ) Round(\frac{Rmax}{Scale}) Round(ScaleRmax)是 R m a x Rmax Rmax映射为量化后取值范围的最大值后再取整的结果。实际上,偏移量Z就是将实数空间的最大值 R m a x Rmax Rmax与量化空间的最大值 Q m a x Qmax Qmax对齐的结果。
2.3.3 图例分析
说下我个人的理解吧(不一定正确)。简单来说原本Rmax映射回Qmax通过Scale,但是存在截断操作,我们考虑将映射放在二维平面给考虑,其实就是一条直线即 Q = k R Q=kR Q=kR,其中 k k k为斜率其值为 1 S c a l e \frac{1}{Scale} Scale1。由于R通过k映射回Q会有截断操作导致误差,现在考虑去减小这个误差,也就是通过偏移量来实现即 Q = k R + b Q=kR+b Q=kR+b,其中 b b b为截距也就是偏移量 Z Z Z。
通过引入偏移量Z,我们可以将量化后的数值范围向中心偏移,从而在整个量化数值范围内分布得更加均匀,减小了误差得积累。虽然最终仍然会有截断操作,但是这种偏移可以在整个数值分布上起到更好得平衡作用,从而减小了误差的影响。(from ChatGPT)
从下图分析,绿色区域代表int8量化后的取值范围即[-128 127],我们都希望R实数通过Scale映射后的Q值尽量都落在这个区域,这样保证不被截断,反量化时不存在截断误差。
现在输入考虑之前的三个实数即R为[ 1.6243454 -0.6117564 -0.5281718],其中黑色的线代表常规量化即 Q = R S c a l e Q=\frac{R}{Scale} Q=ScaleR,可以看到实数1.62映射到Q时超出其范围将被截断,从而导致误差。红色的线代表非对称量化即加上偏移量Z的结果 Q = R S c a l e + Z Q=\frac{R}{Scale}+Z Q=ScaleR+Z,可以看到偏移量的引入导致映射直线向下平移了Z个单位,导致实数1.62映射到Q时无需截断,减少了量化产生的误差。
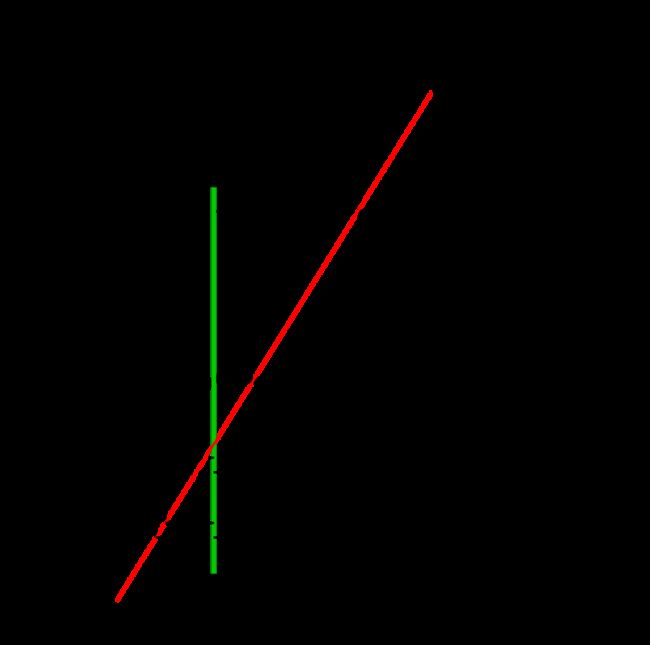
说明:可以将偏移量Z理解为对截断误差的补偿,将误差向中心偏移,从而使得整个量化的结果在一定程度上能够更加集中在实际取值范围内,减少截断误差的影响。可以观察R的三个实数[-0.6 -0.5 1.6],在常规量化中[-0.6 -0.5]都正常落在Q取值范围内即[-128 127],但是1.6超出范围,可以从数据分布来进行分析,[-0.6 -0.5 1.6]的R实数中心点不是在0处的,而映射Q的取值范围[-128 127]的中心点是接近0的,此时要对Q进行一定的修正,使其数据向R实数的中心点进行偏移,更加接近R的数据分布。在非对称量化中,Z的引入使得取值范围向中心点偏移,Z=-58,实际上Q的取值范围变到了[-70 185],能够满足[-0.6 -0.5 1.6]通过Scale映射回到Q的分布(个人想法)。
3.对称量化
3.1 相关知识
对称量化是一种量化方法,其中量化步长在正负之间对称,即使得所有值域范围内的数据点都在对称轴的两侧,这样可以避免出现由于量化导致的误差。(from ChatGPT)
在之前的非对称量化中我们通过引入偏移量 Z Z Z的方式解决量化过程中值域截断的问题,那么还有没有其它的方式呢?
还是考虑原始数组[1.6243454 -0.6117564 -0.5281718],需要将其量化到int8范围即[-128,127],考虑对称量化,我们在原始数组中虚拟添加一个值,该值的大小为原始数组R中绝对值最大值的那个数的相反数(有点拗口),为了实现对称嘛,例如上述数组中添加的值就是-1.6243454,那么现在的输入数组就变成了[-1.6243454 -0.6117564 -0.5281718 1.6243454],同时考虑对称,我们将其量化到[-127,127]范围内(实际工程量化用的时候不会考虑-128),此时的Scale计算如下:
S c a l e = R m a x − R m i n Q m a x − Q m i n = ∣ R m a x ∣ Q m a x Scale = \frac{Rmax-Rmin}{Qmax-Qmin}=\frac{|Rmax|}{Qmax} Scale=Qmax−QminRmax−Rmin=Qmax∣Rmax∣
Q m a x Qmax Qmax不用讲, R m a x Rmax Rmax为什么加绝对值呢?因为要确保 R m a x Rmax Rmax为添加虚拟值后的最大值(说人话),比如 R R R全为负数的情况。此时我们再通过公式计算偏移量 Z Z Z发现其值为0.
Z = Q m a x − R o u n d ( R m a x S c a l e ) = 0 Z = Qmax - Round(\frac{Rmax}{Scale}) = 0 Z=Qmax−Round(ScaleRmax)=0
那么最终对称量化的计算公式如下:
S c a l e = ∣ R m a x ∣ ∣ Q m a x ∣ Q = R o u n d ( R S c a l e ) Q = C l i p ( Q , − 127 , 127 ) R ′ = Q ∗ S c a l e (3) \begin{aligned} Scale &= \frac{|Rmax|}{|Qmax|} \\ Q &= Round(\frac{R}{Scale}) \\ Q &= Clip(Q,-127,127) \\ R' &= Q * Scale \end{aligned} \tag3 ScaleQQR′=∣Qmax∣∣Rmax∣=Round(ScaleR)=Clip(Q,−127,127)=Q∗Scale(3)
3.2 代码实现
完整示例代码如下:
import numpy as np
def saturete(x):
return np.clip(x, -127, 127)
def scale_cal(x):
max_val = np.max(np.abs(x))
return max_val / 127
def quant_float_data(x, scale):
xq = saturete(np.round(x/scale))
return xq
def dequant_data(xq, scale):
x = (xq * scale).astype('float32')
return x
if __name__ == "__main__":
np.random.seed(1)
data_float32 = np.random.randn(3).astype('float32')
print(f"input = {data_float32}")
scale = scale_cal(data_float32)
print(f"scale = {scale}")
data_int8 = quant_float_data(data_float32, scale)
print(f"quant_result = {data_int8}")
data_dequant_float = dequant_data(data_int8, scale)
print(f"dequant_result = {data_dequant_float}")
print(f"diff = {data_dequant_float - data_float32}")
输出如下:
input = [ 1.6243454 -0.6117564 -0.5281718]
scale = 0.012790121431425801
quant_result = [127. -48. -41.]
dequant_result = [ 1.6243454 -0.6139258 -0.524395 ]
diff = [ 0. -0.00216943 0.00377679]
3.3 思考
在tensorRT中INT8量化使用的方法就是对称量化。对称量化方法不用计算偏移量 Z Z Z,计算量小,是一种非饱和量化。如下图所示,红色的区域由于对称量化被浪费掉,没有做真实值的一个表达。

在对称量化中还存在一个问题,比如目前原始数组中有1000个点分布在[-1,1]之间,突然有个离散点分布在100处,此时做对称量化时Scale会被调整得很大,使得上下限超出[-127,127]的范围,从而导致量化误差增大,对精度的影响也会相应增大。
因此,在对称量化中,需要谨慎处理数据中的极端值,以免对量化精度造成不利影响,下节课将会介绍利用直方统计图去除离散点,让max的选取更加的合理,让我们一起期待下次的课程吧
4.对称量化 vs. 非对称量化
在这里阐述下对称量化和非对称量化的优缺点(from chatGPT)
对称量化的优点:
- 没有偏移量,可以降低计算量
- 分布在正负半轴的权值数值均可被充分利用,具有更高的利用率;
- 对于深度学习模型,可以使用int8类型的乘法指令进行计算,加快运算速度;
- 能够有效的缓解权值分布在不同范围内的问题。
对称量化的缺点:
- 对于数据分布在0点附近的情况,量化的位数可能不够;
- 数据分布的范围过于分散,如果缺乏优秀的统计方法和规律,会导致量化效果不佳。
非对称量化的优点:
- 通过偏移量可以保证量化数据分布在非负数范围内,可以使得分辨率更高;
- 适合数据分布范围比较集中的情况。
非对称量化的缺点:
- 对于偏移量的计算需要额外的存储空间,增加了内存占用;
- 偏移量计算需要加减运算,会增加运算的复杂度;
- 对于深度学习模型,要使用int8类型的乘法指令进行计算,需要进行额外的偏置操作,增加了运算量。
总结
课程有些抽象,逻辑不太清晰,学生朽木。希望能多介绍下基础概念,理论相关,原理相关知识。目前自己结合ChatGPT再加上老师讲课感觉还好。