mysql 使用order by存在的问题与优化思考
目录
前言:
一 limit分页
二 order by和limit数据不一致的问题
三 ordey by与filesort
总结:
思考:
补充:
前言:
在很多实际业务中,往往需要涉及分页和排序,还存在where和order by一起使用的场景。开发人员往往没有关心mysql背后的逻辑,导致这部分查询在数据量大的情况下,存在查询缓慢的问题,即使部分开发针对这部分查询建立了索引,但是索引使用不恰当,也会带来额外的IO开销。当然,在业务体量不大的情况下,“乱用” ordey by,where, 分页问题不大。但是,个人觉得,事情应该尽可能做到极致,懂背后的逻辑才有意思。
一 limit分页
limiti 不是本文讲述的重点,但往往order by和limit经常一起使用,这里就探讨下。以下的limit优化主要针对数据量大的情况下,
limit大数据下分页慢的本质:limit语句的查询时间与起始记录(offset)的位置成正比
测试数据量:300W,测试的数据id是主键,连续递增,以下的优化的前提是ordey by的字段是连续单调的,至少一定要保证是单调的,不连续的话就是不太优雅。
以下的测试均是建立在id连续的情况下进行的,默认递增排序
表结构如图1所示:

图1 测试表结构
测试语句1:select * from test order by id limit m, n;
语句的意思是查询m+n条记录,去掉前m条,返回后n条。这样的查询会存在一个问题,当m越大,查询性能会越低,因为MySQL需要扫描全部m+n条记录该分页查询方式会从数据库第一条记录开始扫描,越往后,查询速度越慢,而且查询的数据越多,也会拖慢总查询速度。

图 2 测试语句1
返回1000001到1100001的数据,耗时0.863s
测试语句2:select * from test where id > max_id order by id limit n;
能不能避免从头开始扫表呢,答案是可以的,前提需要知道上一页的最大或最小id是什么(升序需要知道最大,降序需要知道最小)。相比于测试语句1,无需扫描前m条记录,但必须在每次查询时拿到上一次查询(上一页)的最大id(或最小id)。问题在于在实际中可能不好拿到这个id,比如当前在第5页,现在需要查第10页,就做不到了。注意:这里id需要是单调连续的

图3 测试语句2
返回1000001到1100001的数据,耗时0.192s,可以看出,通过指定当前页起始id的情况,速度相比于测试语句1提升了接近5倍。
测试语句3:select * from test where id > max_id order by id limit m, n;
有没有方法解决测试语句2的问题呢,答案是有的。将测试语句1和测试语句2结合起来,就能解决测试语句2中的问题。 比如当前在第3页,需要查询第5页,每页10条数据,而当前第3页的最大id为maxId,则:
select * from table where id > maxId order by id limit 10, 10;
但是,如果当前在第3页,要查询1000页后的数据,也不太好使。
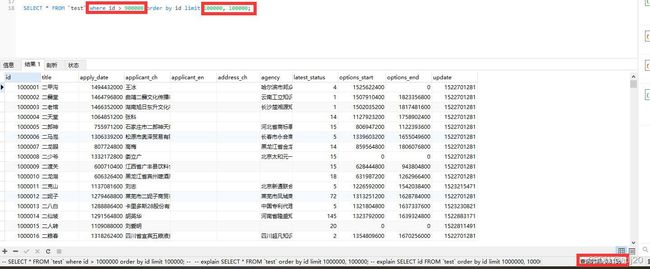
图 4 测试语句3
返回1000001到1100001的数据,耗时0.315s,比测试1块,比测试2慢。比1块的原因是避免了1到900001这部分数据的逐个扫描,比2慢的原因是多个900000到1000000这部分数据的扫描。
测试语句4:select * from table where id > (select id from table limit m, 1)
通过子查询的方式,在不知道上一页id的情况下,这种方案是比较可行的。

图 5 测试语句4
返回1000001到1100001的数据,耗时0.192s, 很明显的看到,通过子查询的方式速度和测试语句2是相当的,但是子查询的方式比语句2更灵活。
注意,以上的测试需要order by的字段是连续单调的情况下,下面以update_time(建立了索引)为例,来说明order by的字段不连续不单调的情况下,会有什么现象。update_time有相同值
从时间角度:
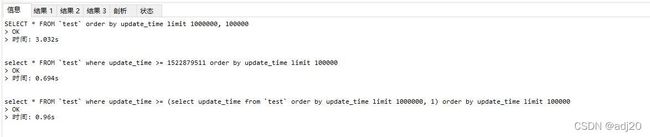
图 6
可能有读者会问,limit 1000000, 1不也要扫描1000000条数据吗,那为什么会比语句1快呢,分析如下:
语句1为select * from test order by update_time limit 1000000, 100000, update_time不是主键,必定是一个非聚簇索引,只有主键才是聚簇索引。由于是select *, 也无法用到索引覆盖,那么必然会回表。首先,先根据update_time这个索引找到1100000条数据的id, 再拿着这1100000条id去回表找到1100000条数据,再丢弃掉前面的1000000条。
语句3中的子查询为select update_time from test ordey by update_time limit 1000000, 1。注意这里用到了索引覆盖,查询的字段就是update_time,直接在非聚餐索引的B+树中就能找到,不需要回表了。然后再通过这个>=的id,找到这100000条数据对应的id, 再用这个id去回表,继续找100000条数据。
粗略的看,语句1共查询数据2200000条,语句2共查询数据110000条。
同样的,where和子查询的速度明显快于普通的limit m, n。但是数据会存在问题,见图 7
从数据准确性:



图 7
可以看出,通过where 和 子查询的方式查出来的数据和limit m, n的数据不一致。这是因为update_time是不连续导致的,造成这种现象的原因我认为是ordey by和limit混用的一个bug,这个会在第二小节探讨。
针对ordey by“不连续不单调字段”的情况下如何优化,我能想到的有如下2条:
1. 超过一半数据的查询,就倒序查。比如,要查询51页的数据(共100页),那就从100页的数据往回查
2.通过新建一张表,将order by的字段和这张表进行关联,在这张表中对每一个order by的值都有一个连续的值与之对应,总之就是想办法将order by的字段映射成连续的。
二 order by和limit数据不一致的问题
1.问题现象
使用order by排序并limit后和单独使用ordey by的结果不一致
仅使用order by:
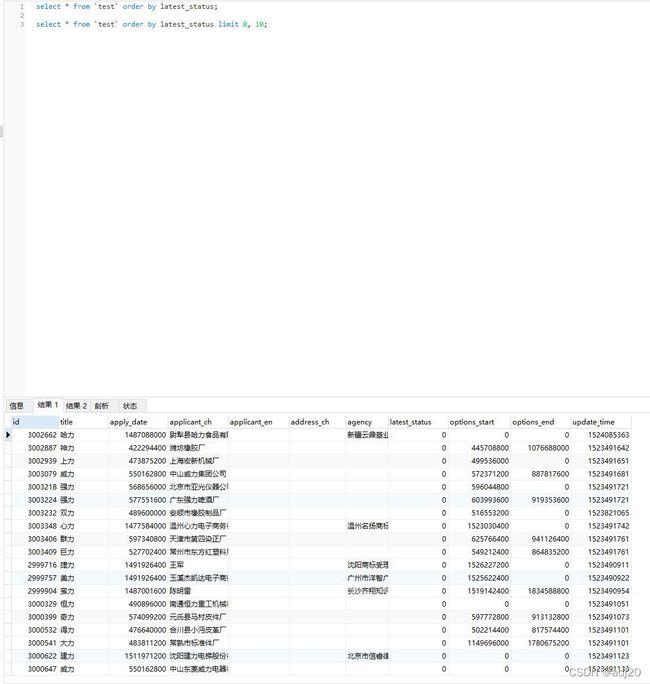
图 8
使用ordey by + limit

图 9
会发现,使用order by查询出来的数据和使用ordey by + limit查询出来的数据的前10个数据不一致。原因在官方文档中有说明,如图10 https://dev.mysql.com/doc/refman/8.0/en/limit-optimization.html
https://dev.mysql.com/doc/refman/8.0/en/limit-optimization.html

图 10
意思就是,如果将LIMIT 与ORDER BY子句组合在一起使用的话,如果order by的字段有多个值,那么对这这些相同值返回的顺序是不确定的。也就是说,根据总体执行计划可能以不同的方式返回,这些行的排序顺序是无序的。
如果要保证用或不用limit的时候,要保证顺序是一致的话,需要在排序的字段中加一个唯一的字段,比如主键这种唯一值,见官方原话,如图11
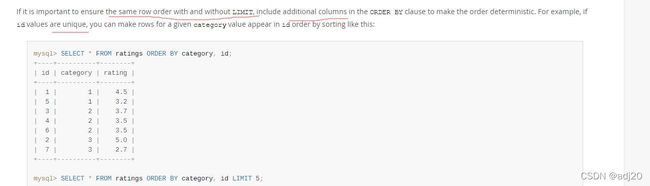
图 11
三 ordey by与filesort
这里不详细阐述fileSort的实现,仅简单介绍file sort。
filesort是mysql在处理order by的时候,在用不上索引进行排序的条件下,会利用filesort进行辅助排序。如果用到了filesort,就一定会有额外的IO开销和内存开销。filesort通过相应的排序算法,将取出的数据在内存中进行排序。
filesort目前有两种排序算法,双路排序和单路排序。单路排序相比于双路排序,会一次性将数据查出,IO开销理论上比双路小。单路排序一次性将数据全部查询到内存中,内存开销比双路排序大。但是,有一种说法是当单路排序需要的内存不够时,单路排序也需要多次取数据,可能实际上IO的开销会比双路排序大。
1.单order by
下面看下出现filesort和不出现filesort的区别,排序的字段为update_time
(1)不给update_time建立索引,进行全查询,查看耗时和执行计划
耗时如图12:
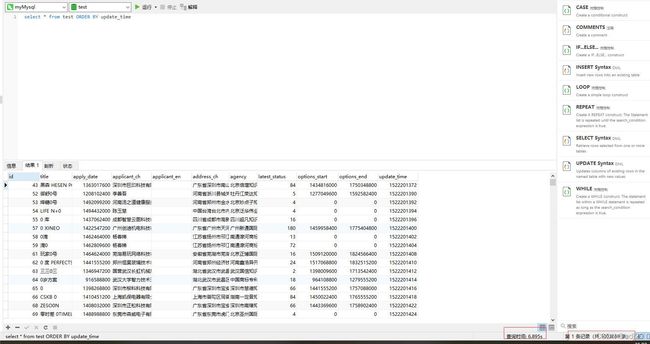
图 12
300W+条数据,耗时6.895s。执行计划如图13:

图 14
type字段为all,表示全表扫描;key字段为null,表示没有用到任何索引;extra字段为using filesort表示用到了filesort。
select update from test order by update_time同样也会出现filesort,耗时4.886s
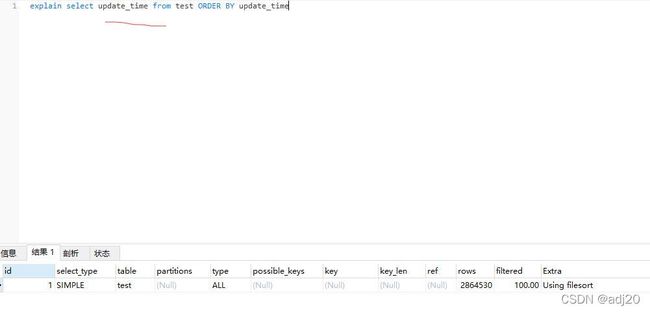
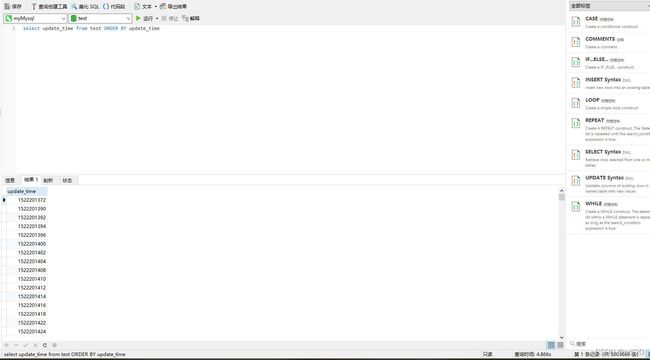
图 15
(2)接下来为update_time建立索引:
执行select * from test order by update_time,发现依然慢的惊人,并且也出现了filesort,如图:


图16
这是为什么呢?原因是select *,select 的字段需要索引覆盖,否则order by字段的索引会失效。
这里看看select update_time from test order by update_time, 耗时大幅减少,且用到了索引,没有走filesort:

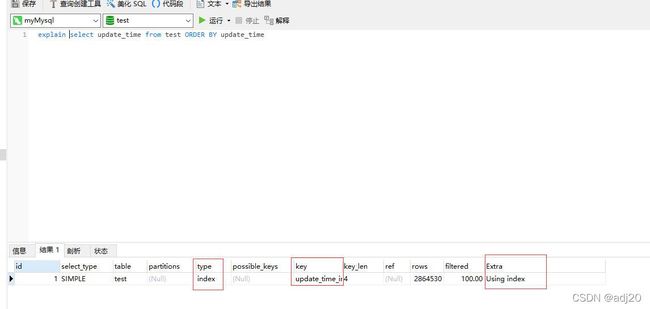
图 17
2.where + order by
(1) where 字段无索引,order by有索引且走索引覆盖
select update_time from test where ,耗时4s,且全表扫描还出现了filesort
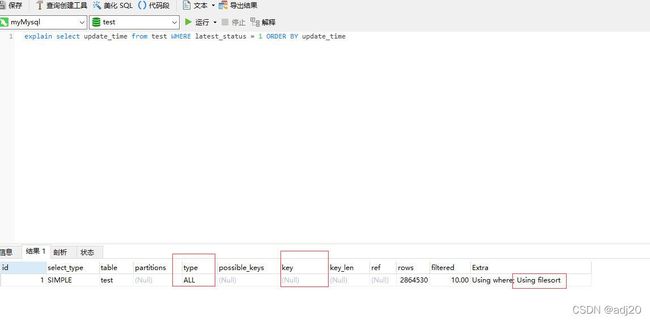

图 18
(2) where 字段有索引,order by有索引且走索引覆盖
select update_time from test where ,耗时1.7s,用到了latest_status索引,没用到update_time索引,且出现了filesort,如图。原因是当where和order by一起使用的时候,order by的索引会失效,这里需要通过建立联合索引来解决。
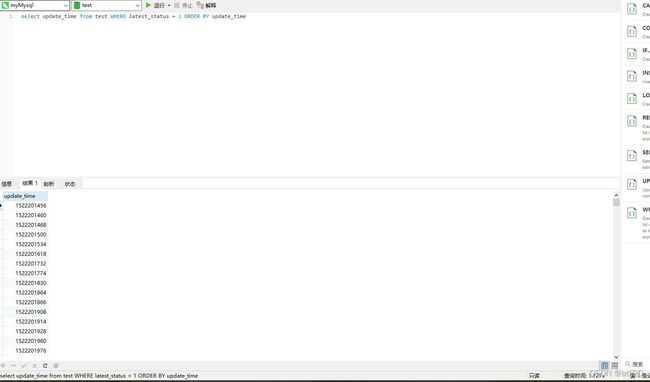

图 19
(3) where 字段和order by字段建立联合索引,且 select *
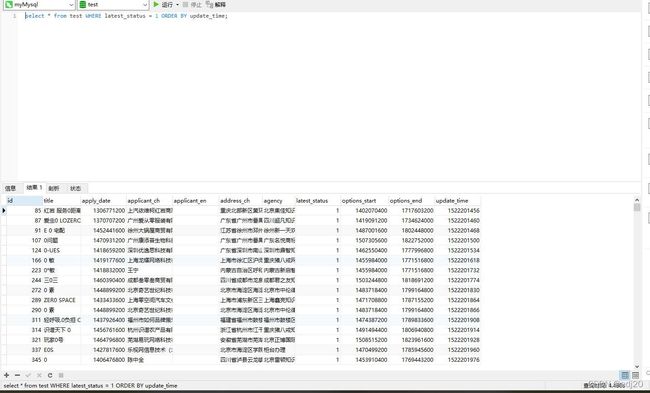
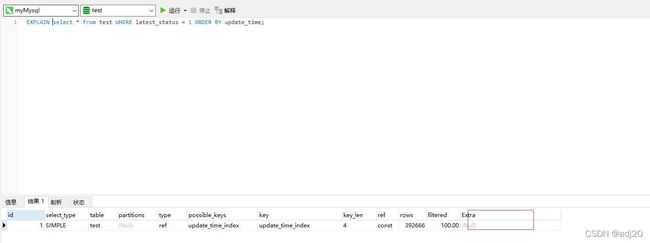
图 20
虽然没有用到filesort, 但耗时4+s。原因是select的字段含有不在索引中的字段,会有回表的问题
(4) where 字段和order by字段建立联合索引,索引顺序为(lastest_status, update_time)和where, order by字段的顺序一致,且 select 的字段仅为索引中的字段
耗时0.05s,有了质的飞越,且extra出现了喜闻乐见的index
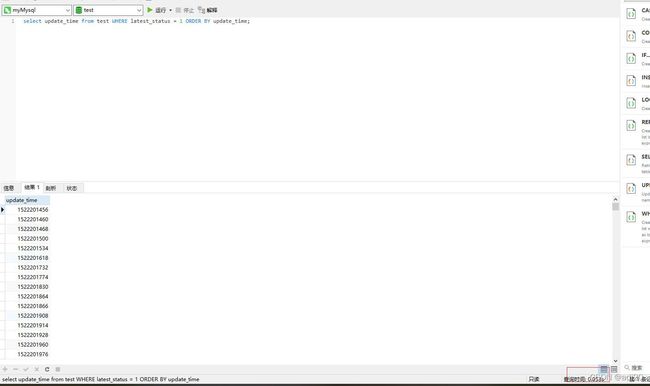

图 21
(5) where 字段和order by字段建立联合索引,索引顺序为(update_time, lastest_status,)和where, order by字段的顺序不一致,且 select 的字段仅为索引中的字段
耗时0.3s+,比(4)慢,也没filesort


还有几种情况这里就不列举了,简单说明下结果:
1. order by多个字段,其中任何一个字段没有索引,都会出现filesort
2.order by多个字段,这几个字段必须建立联合索引,且出现在order by后的顺序必须满足最佳左前缀规则,否则会出现filesort
总结:
1.对于连续单调的字段用limit时,可以采用子查询的方式来提升在大数据量下的分页性能
2.对于不连续单调的字段用limit时,可以采用正序查询和倒序查询,或者做连续单调映射表的方式来提升大数据量下的分页性能
3.当order by和limit混合使用时,可能会出现排序结果和预期不一致,这个时候需要按照官方文档的说明,在order by的字段中加上一个唯一字段。
4.order by的字段无索引,必出现filesort
5.order by的字段有索引且走索引覆盖才不会出现filesort
6.where 和 order by一起使用时,where的字段和order by的字段都建立了索引,且不是联合索引,会导致order by的索引失效,出现filesort
7.where 和 order by一起使用时,where的字段和order by的字段应该建立了索引,且索引顺序和where 和 order by的顺序一致,且select的字段不包含不在索引中的字段,这样的性能是最优的
思考:
在我们实际业务中,不太可能为每一个select的字段都建立索引,如果当数据量很大的情况下,可以先查出主键,再拿主键去查数据。
比如 select 主键 ,update_time from xxx order by update_time(主键通过非聚集索引能直接获取到,所以不需要回表,这种查询是不会出现filesort的,但是如果是select 非主键,update_time, 又不满足联合索引且最佳左原则,就会有filesort)。然后再用主键去查其他字段(待验证),这里只是举个例子,实际工作中可以根据具体业务实操以下,对比性能。
补充:
如果必须要filesort(就是不建立索引,索引失效等),如何优化了。
1.加大 max_length_for_sort_data和sort_buffer_size(这里不讨论为什么,后续有空写一个单独的filesort时来讲解)
2.去掉不必要的返回字段
文章中如有错误的地方,欢迎指正,一起探讨一起学习