春 字节题(五)
文章目录
- leetcode 55 跳跃游戏 && leetcode 45 跳跃游戏II
- 二分查找
- 剑指offer 61 扑克牌中的顺子
- leetcode 739 每日温度
- leetcode 162 寻找峰值
- leetcode 72 编辑距离H
- leetcode 1143 最长公共子序列
- leetcode 718 最长重复子数组
- 字节技术面
- 【重点】出现频率最高的k个数字(出现频率第1高==出现次数最多)
- leetcode 451根据字符出现的次数排序M
- leetcode 1 两数之和
- 数组中重复的数字
- leetcode 120 三角形最小路径和M
- leetcode10 正则表达式匹配 H
leetcode 55 跳跃游戏 && leetcode 45 跳跃游戏II
55
给定一个非负整数数组nums,你最初位于数组的第一个下标,数组中的每个元素代表你在该位置可以跳跃的最大长度;
判断是否能够到达最后一个下标;
例如:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
//贪心解法
//思路:
//i每次移动只能在cover的范围内移动,每移动一个元素,cover得到该元素数值(新的覆盖范围)的补充,让i继续移动下去。
//而cover每次只取 max(该元素数值补充后的范围, cover本身范围)。
//如果cover大于等于了终点下标,直接 return true 就可以了。
class Solution
{
public:
bool canJump(vector<int>& nums)
{
int cover = 0;//初始化一个变量用来表示可以跳跃的覆盖范围
if (nums.size() == 1)return true;
for (int i = 0; i <= cover; i++)//在当前可以遍历到的覆盖范围内进行遍历; i每次移动只能在cover的范围内移动,每移动一个元素,cover得到该元素数值(新的覆盖范围)的补充,让i继续移动下去。
{
cover = max(i + nums[i], cover);//更新最大的覆盖范围
if (cover >= nums.size() - 1)return true;//最终的问题转换为跳跃覆盖范围是不是可以覆盖到终点
}
return false;
}
};
//暴力遍历寻找 --- 效率和上述解法相当
//对任意一个点而言 由此点可以到达的最远距离是 i+nums[i],这块距离表示从起始位置到最远位置的距离 当这个距离小于i时 肯定是到不了终点的;
//k始终维护一个可以由任意点到达的最远距离;
//如果任意一个点可以到达的最远距离还是到不了终点 始终会存在一个位置i 使得k
class Solution {
public:
bool canJump(vector<int>& nums)
{
int k = 0;
for (int i = 0; i < nums.size(); i++)
{
if (i > k) return false;
k = max(k, i + nums[i]);
}
return true;
}
};
45
给定一个非负整数数组nums,你最初位于数组的第一个位置;
数组中的每一个元素代表你可以在该位置可以跳跃的最大长度;
你的目标是使用最少的跳跃次数达到数组的最后一个位置;
例如:
输入: nums = [2,3,1,1,4]
输出: 2
解释: 跳到最后一个位置的最小跳跃数是 2。
从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。
方法一–暴力遍历 效率也不错

小注:
class Solution
{
public:
int canJump(vector<int>& nums)
{
int ans = 0;//记录跳跃次数
int start = 0;//第一次肯定要跳跃 跳跃位置就是第一个位置
int end = 1;
while (end < nums.size())//循环结束的标志是当 end的范围超过数组的边界 end>=nums.size() 就结束循环 此时ans就是最少的跳跃次数;
{
int max_pos=0;//一定要进行赋值初始化 不能只写int max_pos
for (int i = start; i < end; i++)//[start,end]是一个起跳范围==在start和end的范围内进行遍历 不断的更新起始位置和终止位置
{
max_pos = max(max_pos, i + nums[i]);
}
start = end;//更新下一次起跳的起始位置:前一次跳跃的结束位置就是下一次跳跃范围的起始位置;
end = max_pos + 1;//更新下一次起跳的结束位置:前一次可以跳跃的最远距离+1 就是下一次跳跃范围的结束位置;
ans++;
}
return ans;
}
};
方法二 – 代码随想录解法 —算法思想:
核心:移动下标只要遇到当前覆盖最远距离的下标,直接步数加一,不考虑是不是终点的情况;
想要达到这样的效果,只要让移动下标,最大只能移动到nums.size - 2的地方就可以了。
因为当移动下标指向nums.size - 2时:
如果移动下标等于当前覆盖最大距离下标, 需要再走一步(即ans++),因为最后一步一定是可以到的终点。(题目假设总是可以到达数组的最后一个位置),如图:

如果移动下标不等于当前覆盖最大距离下标,说明当前覆盖最远距离就可以直接达到终点了,不需要再走一步。如图:

// 版本二
class Solution {
public:
int jump(vector<int>& nums) {
int curDistance = 0; // 当前覆盖的最远距离下标
int ans = 0; // 记录走的最大步数
int nextDistance = 0; // 下一步覆盖的最远距离下标
for (int i = 0; i < nums.size() - 1; i++) { // 注意这里是小于nums.size() - 1,这是关键所在
nextDistance = max(nums[i] + i, nextDistance); // 更新下一步覆盖的最远距离下标
if (i == curDistance) { // 遇到当前覆盖的最远距离下标
curDistance = nextDistance; // 更新当前覆盖的最远距离下标
ans++;
}
}
return ans;
}
};
二分查找
class Solution
{
public:
int search(vector<int>& nums, int target)
{
int l = 0, r = nums.size() - 1;
while (l <= r)
{
int mid = l + (r - l) / 2;
if (nums[mid] == target)
{
return mid;
}
else if (nums[mid] < target)l = mid + 1;
else if (nums[mid] > target)r = mid - 1;
}
return -1;
}
};
剑指offer 61 扑克牌中的顺子
题目:
从若干副扑克牌中随机抽 5 张牌,判断是不是一个顺子,即这5张牌是不是连续的。
2~10为数字本身,A为1,J为11,Q为12,K为13,而大、小王为 0 ,可以看成任意数字。A 不能视为 14。
例如:
输入 1 2 3 4 5
输出 true
输入 0 0 1 2 5
返回true
实现:
//随机抽取五张牌 判断是不是顺子
//因为只有五张牌 要想组成顺子 最大值和最小值之间差值只能小于等于4,若小于4,可以用0进行替;
class Solution
{
public:
bool isStraight(vector<int>& nums)
{
vector<int>map(14,0);//数组实现哈希集合 初始化一个数组
int minValue = INT_MAX, maxValue = INT_MIN;//一开始将最大值初始化为最小值 将最小值初始化为最大值 防止边界溢出
for (int num : nums)
{
if (map[num] >= 1)return false;//只有五张牌 若出现重复数字 肯定是不能组成顺子的
if (num == 0)continue;//大小王不作任何处理 需要的时候直接进行替换即可
minValue = min(minValue, num);//第一次比较的结果是num;不断的更新遍历到的最小值, 最终返回的是整个数组中的最小值
maxValue = max(maxValue, num);//第一次比较的结果是num ;不断的更新遍历到的最大值,最终返回的是整个数组中的最大值
map[num]++;//统计出现次数
}
return maxValue - minValue <= 4;
}
};
leetcode 739 每日温度
题目:
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指在第 i 天之后,才会有更高的温度。如果气温在这之后都不会升高,请在该位置用 0 来代替。
例如:
输入: temperatures = [73,74,75,71,69,72,76,73]
输出: [1,1,4,2,1,1,0,0]

核心思路:下标差就是二者之间的距离 也就是需要返回的天数
class Solution
{
public:
vector<int>dailyTemperatures(vector<int>& T)
{
int n = T.size();
vector<int>ans(n);//初始化一个容器存储需要间隔的天数
stack<int>s;//初始化一个辅助栈存储下标,进行栈顶元素和当前遍历到的元素的比较
for (int i = 0; i < n; i++) //i是当前遍历到的元素的下标
{
while (!s.empty() && T[i] > T[s.top()])//栈中不为空并且当前遍历到的元素大于之前的元素;
{
auto t = s.top();//t代表前一个较小元素的下标
s.pop();//将之前那个较小的元素从栈顶删除
ans[t] = i - t;//将之前位置的元素更新为需要间隔的天数=当前遍历到那一天的下标-前一天的下标;ans[t]是前一天距离升温间隔的天数
}
s.push(i);//如果当前遍历到的元素比栈顶元素小 就一直入栈
}
return ans;
}
};
int main()
{
Solution so;
vector<int>nums = { 30,40,50,60};
vector<int>res;
res = so.dailyTemperatures(nums);
for (vector<int>::iterator it=res.begin(); it!=res.end(); it++)//迭代器的遍历输出vector中所有元素
{
cout << "输出结果是;" << *it << endl;
}
system("pause");
return 0;
}
leetcode 162 寻找峰值
给你一个整数数组 nums,找到峰值元素并返回其索引。数组可能包含多个峰值,在这种情况下,返回 任何一个峰值 所在位置即可。
输入:nums = [1,2,3,1]
输出:2
解释:3 是峰值元素,你的函数应该返回其索引 2。

核心思路:二分查找
class Solution
{
public:
int findPeakElement(vector<int>& nums)
{
if (nums.size() == 1)return 0;
int l = 0, r = nums.size() - 1;
while (l < r)
{
int mid = l + (r - l) / 2;
if (nums[mid] > nums[mid + 1]) //下降 左侧必有峰
{
r = mid;//更新右边界
}
else if (nums[mid] < nums[mid + 1]) //如果上升 则右侧必有峰
{
l = mid + 1;//更新左边界
}
}
return r;//return l 一样的结果
}
};
leetcode 72 编辑距离H


class Solution
{
public:
int minDistance(string word1, string word2)
{
int m = word1.length();
int n = word2.length();
//dp[i][j]表示word1中的前i个字符转换成word2中的前j的字符 最少的操作次数;
vector<vector<int>>dp(m + 1, vector<int>(n + 1));
for (int i = 0; i <= m; i++)
{
dp[i][0] = i;//word2为空串的情况
}
for (int j = 0; j <= n; j++)
{
dp[0][j] = j;//word1为空串的情况
}
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
if (word1[i - 1] == word2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1];//直接继承上一个状态即可
}
else
{
dp[i][j] =1+min(dp[i - 1][j - 1], min(dp[i][j - 1], dp[i - 1][j]));//三种情况取最小的即可
}
}
}
return dp[m][n];
}
};
leetcode 1143 最长公共子序列
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度这个子序列可以不是连续的,但是不能打破原来的顺序。如果不存在 公共子序列 ,返回 0 。
例如:
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 “ace” ,它的长度为 3 。
算法思路:
动态规划


小注:
dp[i][j]表示遍历到(i,j)这个位置的时候,最长的公共子序列的长度是多少;
代码实现:
//代码随想录 DP解法
class Solution
{
public:
int longestCommonSubsequence(string text1, string text2)
{
vector<vector<int>>dp(text1.size() + 1, vector<int>(text2.size() + 1, 0));//初始化一个text1.size()+1行 text2.size()+1列的二维数组
for (int i = 1; i <= text1.size(); i++)
{
for (int j = 1; j <= text2.size(); j++)
{
if (text1[i - 1] == text2[j - 1])//比较两字符串当前位置的元素是否相等 相等的情况下 从上一个状态+1转换而来
{
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else //两字符串当前位置的元素不等的情况下 继承自上一个状态 取二者中最长子序列的较大值
{
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[text1.size()][text2.size()];
} //dp[i][j]表示text1的[1,i]区间和text2的[1,j]区间的最长公共子序列的长度;
};
leetcode 718 最长重复子数组
给定两个整数数组nums1和nums2 返回两个数组中公共的、长度最长的子数组的长度这个子数组必须是连续的;
例如:
输入:nums1 = [1,2,3,2,1], nums2 = [3,2,1,4,7]
输出:3
解释:长度最长的公共子数组是 [3,2,1] 。
动态规划解法:

//理解一下这俩题的区别:
//最长重复子数组和最长连续子序列的两个题的区别在于所找数组是不是可以连续
//对于连续的重复子数组 其末尾元素必须相等 若末尾不相等 则就没有比较的必要了 末尾元素不等 最长重复子数组的长度肯定为0
//对于重复子序列 因为要求可以不连续 即使末尾元素不等 还要继续向前比较
class Solution
{
public:
int findLength(vector<int>& nums1, vector<int>& nums2)
{
vector<vector<int>>dp(nums1.size() + 1, vector<int>(nums2.size() + 1, 0));//可以理解为一个二维数组的 行和列
int res = 0;
for (int i = 1; i <= nums1.size(); i++)
{
for (int j = 1; j <= nums2.size(); j++)
{
if (nums1[i - 1] == nums2[j - 1])//当前位置遍历到的数字是相同的
{
dp[i][j] = dp[i - 1][j - 1] + 1;
} //这个题和最长连续子序列的区别就是可以不是连续的 因此无需对数字不等的情况进行处理 当前数字不等 当前为的数字就不能算在连续数组内了
if (dp[i][j] > res)res = dp[i][j];//始终更新res为一个最大值
} //dp[i][j]表示在nums1中的(1,i)区间中和nums2中的(1,j)区间中的最长重复子数组的长度;
}
return res; //返回这个最大值
}
};
字节技术面
- 等概率返回数组中出现最多的元素的下标
- 等概率返回数组中出现的最多的元素的下标,以数组形式,给定数组大小
- 判断树a是否是树b的子树
- 判断多个链表是否具有公共子节点
【重点】出现频率最高的k个数字(出现频率第1高==出现次数最多)
给定一个数组nums和一个整数k,返回其中出现频率前k高的元素
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
小顶堆实现
小注:
//在C++开发过程中,我们经常会用STL的各种容器,比如vector,map,set等,这些容器极大的方便了我们的开发。
//在使用这些容器的过程中,我们会大量用到的操作就是插入操作,比如vector的push_back,map的insert,set的insert。
//这些插入操作会涉及到两次构造,首先是对象的初始化构造,接着在插入的时候会复制一次,会触发拷贝构造。
//但是很多时候我们并不需要两次构造带来效率的浪费,如果可以在插入的时候直接构造,就只需要构造一次就够了。
//C++11标准已经有这样的语法可以直接使用了,那就是**emplace。只构造一次,节约内存,减少开销**;
vector有两个函数可以使用:emplace,emplace_back。emplace类似insert,emplace_back类似push_back。
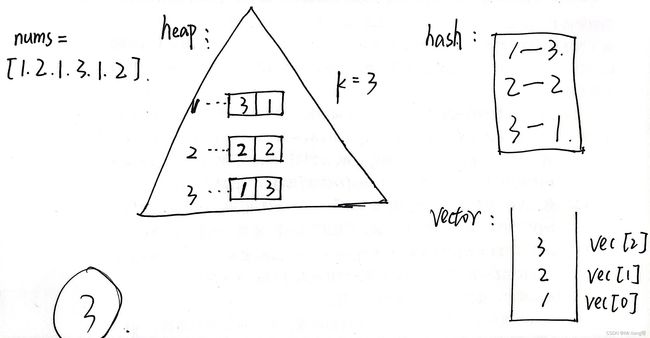
priority_queue首先是一个队列,先进先出,在队尾增加元素,在队首删除元素;
小顶堆:队首元素最小;
大顶堆:队首元素最大;
代码实现:
更简洁的代码:
class Solution3 {
public:
vector<int> topKFrequent(vector<int>& nums, int k)
{
unordered_map<int, int> mp;//哈希表统计出现次数
for (int i : nums) ++mp[i];
priority_queue<pair<int, int> > p;//默认大顶堆 降序排列 队首元素最大 堆里存放的是pair类型的数据
for (auto iter=mp.begin();iter!=mp.end();iter++) //迭代器遍历哈希表
{
p.push({ iter->second, iter->first });//这里把堆中元素的排序改为 按数字出现的次数排列,出现次数最多的元素在队首;
}
vector<int> ans;
while (k--)
{
ans.push_back(p.top().second);//把出现频率前k高的数字存入到容器中
p.pop();
}
return ans;
}
};
//哈希+小顶堆实现
class Solution
{
public:
struct cmp
{
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) //pair 参数一 数字 参数二 数字出现次数
{
return lhs.second > rhs.second;//按照数字出现次数实现从小到大的排列
}
};
vector<int>topKFrequent(vector<int>& nums, int k)
{
unordered_map<int, int>mp;//哈希统计数字出现的次数
for (auto& num : nums)
{
mp[num]++;
}
//Lamda表达式实现排序
//auto cmp = [](const pair& lhs, const pair& rhs) {return lhs.second > rhs.second; };
//小顶堆实现
//priority_queue, vector>,greater>>heap;// 数据类型 保存数据的容器 元素比较方式
priority_queue<pair<int, int>, vector<pair<int, int>>, cmp>heap;// 数据类型 保存数据的容器 元素比较方式(默认大顶堆 降序排列)
for (auto it = mp.begin(); it != mp.end(); it++)//遍历哈希的方式
{
if (heap.size() < k) //先放入k个元素到堆中,堆中始终维护的是k个元素
{
heap.emplace(*it);//*it 表示当前遍历到的元素
}
else if (it->second > heap.top().second)//堆顶元素出现次数小于当前遍历到的元素的出现次数,始终保证堆中有k个出现频率最高的元素
{
heap.pop();//删除堆顶元素
heap.emplace(*it);//插入当前遍历到的元素
}
}
vector<int>res(k, 0);
for (int i = k - 1; i >= 0; i--)//到序遍历堆 最后容器中元素是按从大到小的出现次数排布的 依次是出现次数第一高、第二高.....
{
res[i] = heap.top().first;
heap.pop();
}
return res;
}
};
int main()
{
Solution so;
vector<int>nums = { 1,2,9,7,9,9,1,2,6 };
//int n = nums.size();
vector<int>ans;
ans = so.topKFrequent(nums, 2);
for (int i = 0; i < ans.size(); i++)
{
cout << "出现频率最高的k个元素是:"<<ans[i] << endl;
}
//cout << "出现频率最高的的元素是:" << ans[0] << endl;
system("pause");
return 0;
}
leetcode 451根据字符出现的次数排序M
给定一个字符串 s ,根据字符出现的 频率 对其进行 降序排序 。一个字符出现的 频率 是它出现在字符串中的次数。
返回 已排序的字符串 。如果有多个答案,返回其中任何一个。
例如:
输入: s = "tree"
输出: "eert"
解释: 'e’出现两次,'r’和’t’都只出现一次。
因此’e’必须出现在’r’和’t’之前。此外,"eetr"也是一个有效的答案。
实现思路:大顶堆+哈希表实现
class Solution
{
public:
string frequencySort(string s)
{
unordered_map<char, int>mp;
string ans;
priority_queue<pair<int, char>>q;//大顶堆实现
for (auto str : s)mp[str]++;
for (auto it = mp.begin(); it != mp.end(); it++)
{
q.push({ it->second,it->first });//堆中第一个元素就是出现次数 第二个元素是对应的字符;
}
while(!q.empty())//遍历哈希中每一个元素
{
//这个for循环就是用来拼接某一个字符的 出现几次就循环几次
for (int i = 0; i < q.top().first;i++) //对于多次出现的字符 实现重复拼接 避免只存储一次
{
ans+=q.top().second;
}
q.pop();
}
return ans;
}
};
leetcode 1 两数之和
返回这两个数字的下标
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target){
int n=nums.size();
vector<int>ret(2,0);
unordered_map<int,int>table;//哈希表存储的数字和对应的下标
for(int i=0;i<n;i++)
{
if(table.count(target-nums[i])>0)
{
ret[0]=i,ret[1]=table[target-nums[i]];
return ret;
}
table[nums[i]]=i;
}
return ret;
}
};
返回这两个数字
class Solution2
{
public:
vector<int>twoSum(vector<int>& nums, int target)
{
unordered_map<int, int>mp;
vector<int>res(2, 0);
for (auto num : nums)
{
mp[num]++;
}
int n = nums.size();
for (int i = 0; i < n; i++)
{
if (mp.count(target - nums[i]))
{
res[0]=nums[i];
res[1] = target - nums[i];
}
}
return res;
}
};
int main()
{
vector<int>nums = { 2,5,8,9,1,9,3,7 };
Solution2 so;
vector<int>ans;
ans = so.twoSum(nums, 10);
cout << "这两个数字是:" << endl;
cout<< ans[0] << endl;
cout<< ans[1] << endl;
system("pause");
return 0;
}
数组中重复的数字
class Solution {
public:
int findRepeatNumber(vector<int>& nums)
{
unordered_map<int,bool>map;//bool 初始化为false
for(int num:nums)
{
if(map[num])return num;//第二次出现才会置为true
map[num]=true;
}
return -1;
}
};
leetcode 120 三角形最小路径和M
给定一个三角形triangle 找出自顶向下的最小路径和;
每一步只能移动到下一行中相邻的结点上。相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。也就是说,如果正位于当前行的下标 i ,那么下一步可以移动到下一行的下标 i 或 i + 1 。
例如:
输入:triangle = [[2],[3,4],[6,5,7],[4,1,8,3]]
输出:11
解释:如下面简图所示:
2
3 4
6 5 7
4 1 8 3
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
动态规划的变形解法 从下向上找(从倒数第二行开始找)
class Solution
{
public:
int miniumTotal(vector<vector<int>>& triangle)
{
int m = triangle.size();//三角形的行数
for (int i=m-2; i >= 0; i--)//从倒数第二行开始遍历
{
int n = triangle[i].size();//三角形每一行的元素
for (int j = 0; j < n; j++)//遍历每一行的每个元素
{
triangle[i][j] += min(triangle[i + 1][j], triangle[i + 1][j + 1]);//第一次遍历就是从倒数第二行开始 寻找最后一行的最小值;
}
}
return triangle[0][0];//返回三角形顶尖的元素就是存储的最小路径
}
};
leetcode10 正则表达式匹配 H
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 ‘.’ 和 ‘*’ 的正则表达式匹配。
'.' 匹配任意单个字符
'*' 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
动态规划解法
class Solution
{
public:
bool isMatch(string s, string p)
{
int m = s.size();
int n = p.size();
//Lamda表达式
auto matches = [&](int i, int j) {
if (i == 0)return false;
if (p[j - 1] == '.')return true;
return s[i - 1] == p[j - 1];
};
vector<vector<int>>dp(m + 1, vector<int>(n + 1));//创建一个m+1行 n+1列的二维数组
dp[0][0] = true;
for (int i = 0; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
if (p[j - 1] == '*')
{
dp[i][j] |= dp[i][j - 2]; // |=按位或并赋值 按位或 | 按位或只要有一位为1,结果就为1,都为0就为0
if (matches(i, j - 1))
{
dp[i][j] |= dp[i - 1][j];
}
}
else
{
if (matches(i, j))
{
dp[i][j] |= dp[i - 1][j - 1];
}
}
}
}
return dp[m][n];
}
};