基于亚马逊云科技 Serverless架构的实时数仓架构
近年来,各级政府和企业响应数字化转型的号召,都已开始或者即将开始数字化转型。各类企业通过前期的业务线上化、信息化,积累了大量数据,而数字化转型就是要聚合这些数据,进行深入挖掘分析,用数据来驱动业务,用数据来支撑决策、用数据来推动业务和商业模式创新、推动业务流程优化,进而实现降本增效。
要实现数据价值,建设数据仓库是在数字化转型过程中不得不面对的一项任务。数据仓库汇聚各个业务部门数据,避免数据孤岛,使数据真正成为整个企业的数据,而不是某个部门的数据。
数据仓库的技术架构包括离线数仓和实时数仓或准实时数仓。离线数仓已发展多年,当前已无法完全满足企业在竞争中脱颖而出的发展需求,实时数仓越来越多成为企业建设数据仓库的首选。然而由于实时数仓对实时性的严格要求,实现实时数仓的技术难度远远大于离线数仓,一些现有的实时数仓架构,只能实现准实时,而且无法解决削峰平谷、无感扩展等问题。
本文为大家提供一种高效的实时数仓架构:基于亚马逊云科技 Serverless 架构的实时数仓架构。
实时数仓常见场景与亚马逊云科技的做法赏析
我们先来赏析一下常见的实时数仓场景,以及亚马逊云科技Serverless架构的实时数仓成功落地的案例:
1、APP 埋点数据实时采集与分析(比如:实时智能推荐、实时欺诈检测)
在此,我们以智能推荐场景为例:根据用户历史的购买或浏览行为,通过推荐算法预测用户兴趣与需要,并从海量推荐资产(可能是短视频、广告、动图)中挑选最合适的进行推送。推荐系统在飞速发展,对时延的要求也越来越苛刻和实时化。往往业务方希望客户在使用App(或浏览网页)时,就能基于当前行为和历史数据进行动态推荐。
数据来源一般为App埋点采集和历史浏览数据、消费数据、和广告资产等。
常见做法:流式ETL与数据同步与传输可能会用到Flume、Kafka等工具,计算有可能会采用ClickHouse、Flink、Spark等大数据计算工具。数据源端和数据消费端就五花八门一些,在此不作展开。(同样的技术架构也出现在实时欺诈检测等场景中)
我们来看一下亚马逊云科技的案例:使用 Amazon Kinesis Data Streams (流式数据接入产品,Amazon KDS)实时接入 APP 埋点数据到 Amazon Redshift(云原生数据仓库) 中,用于指标分析和 BI 展现。支持高达30万/秒的数据摄入速率,延迟小于10秒;在数据实时摄入数仓的同时,支持高并发实时查询,支持大宽表多表关联,复杂聚合等各种 SQL 查询,查询结果秒级响应。
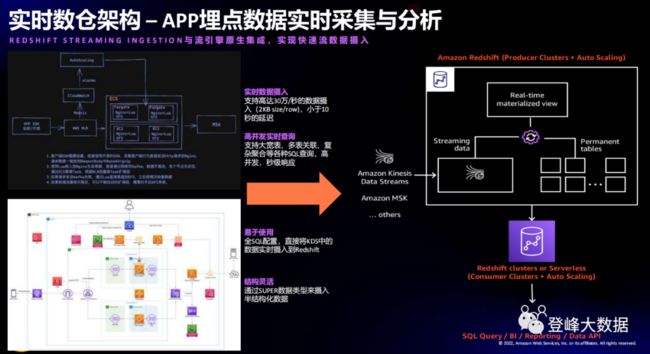
图1 实时数仓架构--APP 埋点数据实时采集与分析
2、RDBMS CDC+KDS+Amazon Redshift Serverless(实时BI报表、复杂事件处理)
在这个案例中,主要采集源头日志数据和 RDS 结构化数据的变更数据动态捕获(Change Data Capture,CDC)。这是一个数据仓库非常常见的需求,外部数据库系统(账户、存款、制造、人力资源等)作为数据源时,业务团队需求需要CDC日志数据动态接入数据仓库,实现实时的分析需求,比如实时BI报表、复杂事件处理(应急响应)。
CDC日志数据通过 Amazon Kinesis 实时发送到 Amazon KDS,经过流处理后,结果写入 RDS,并提供 API 的方式供第三方查询。同时,Amazon Redshift可以直接消费 Kinesis 数据,用于查询分析,整体延迟小于30秒。
CDC日志采集方式支持多种,包括 Amazon DMS、Debezium、Flink CDC、Canal 等,采集数据写入Kinesis后,接着使用 Amazon Redshift Streaming Ingestion 功能将CDC数据实时写入 Amazon Redshift。

图2 实时数仓--RDBMS CDC+KDS+Amazon Redshift Serverless
经典解决方案—借助Amazon Redshift打造云原生数仓
在继续开展下文前,需要介绍一个无法绕过的产品——Amazon Redshift ,一种快速、可扩展、安全且完全托管的云数据仓库,可以帮助用户通过标准 SQL 语言简单、经济地分析各类数据。
无论是构建传统数据仓库架构还是实时数仓架构,借助Amazon Redshift用户都可以一站式的进行部署。相比其他云数据仓库,Amazon Redshift 可实现高达三倍的性能价格比。数万家客户正在借助 Amazon Redshift 每天处理 EB 级别的数据,借此为高性能商业智能(BI)报表、仪表板应用、数据探索、实时分析和等分析工作负载以及机器学习、数据挖掘提供强大动力。Amazon Redshift支持ACID事务特性、ANSI SQL标准、JDBC/ODBC 连接协议的 MPP 架构列式存储数据仓库。Amazon Redshift 不仅可以基于自身内部表进行数据分析,还可以查询 Amazon S3 中的数据,S3 是一项具备极致弹性的对象存储,它已经成为了云上数据湖事实上的标准,既可以存储结构化数据,也可以是半结构化数据、非结构化数据。Redshift与S3 可以无缝结合,实现智能湖仓架构。

图3 Amazon Redshift Serverless 架构
实时数仓架构要解决的问题
良好的实时数仓架构,可以解决以下四方面的问题:数据实时接入、数据实时分析、数据实时输出。
-
数据实时接入:数据仓库主要用来存储来自各个业务系统的数据。实时数仓的第一步,就是要解决数据如何实时进入数据仓库的问题。
-
数据实时分析:实时接入的数据,要能够立即可用,满足即席查询、报表分析和挖掘预测的需求,数据准,延迟低。
-
数据实时输出:数据实时分析的结果,要能够及时进行 BI 报表展现、及时以数据服务的形式提供给第三方。
-
实时数仓智能化:数据分析解决的是过去发生了什么,数仓智能化要解决的是未来要发生什么。让实时数仓具备机器学习、智能预测能力,是实现智能湖仓的必备功能。
Serverless 架构不仅弥补了传统离线数仓的不足,而且完美解决了上述四方面的问题,先看下整体实时数仓架构图:
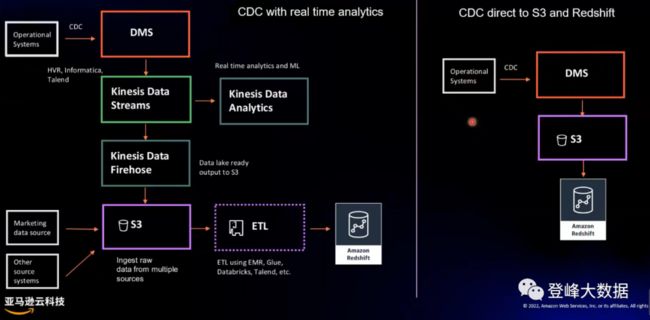
图4 亚马逊云科技 Serverless实时数仓架构图
Serverless 实时数仓架构采用 Amazon KDS(Amazon Kinesis Data Streams) + Amazon Redshift Serverless+Redshift ML+S3 技术产品组合,KDS 负责数据的实时接入,Redshift Serverless+Redshift ML+S3 负责"智能湖仓"的落地,实现数据实时分析、实时输出、实时预测。同时,Redshift Serverless 架构,运维简单,按需计费,降本增效,将客户从纷繁复杂的架构搭建、监控、运维中解放出来,专注于数据查询分析,数据价值挖掘,实现数据驱动决策。
-
数据实时接入:接入的数据,可以分为三大类:结构化数据(数据库数据)、半结构化数据(Json、CSV数据)和非结构化数据(图片视频数据)。
对于源自数据库的结构化数据,通用的实时接入方式是使用 CDC 技术增量接入。在亚马逊云科技实时数仓架构中,采用Amazon DMS产品接入CDC数据到Amazon KDS。Amazon DMS支持同构迁移、不同数据库平台之间的异构迁移和CDC数据接入,可以从任何支持的源中将数据低延迟、持续地复制到任何支持的目标。此外,利用 Amazon Redshift 流式摄取功能可以将 Kinesis 中的数据以极低延迟摄取到 Amazon Redshift 中。

图5 Amazon Database Migration Service (Amazon DMS) 迁移数据到智能湖仓
对于非结构化数据,传统实时接入方式是扫描指定目录,将新增文件写入文件系统(HDFS、Amazon S3 等),然后开发程序解析文件,写入数据库表中。然而,采用亚马逊云科技提供的 DMS+S3+Redshift 方式,无需开发数据解析程序,只需通过简单的配置,即可实现数据入写 S3,Redshift 可与 S3 完美集成,即数据进入 S3,即可在 Redshift 中查询分析。
-
数据实时分析:数据的实时分析,由 Amazon Redshift Serverless 提供,智能湖仓的各个分层都创建在 Redshift 数据库中,使用 SQL 语句做数仓指标计算,采用 ETL 工具调度指标计算任务,兼容开源 ETL 工具,也可以使用亚马逊的 ETL 工具。
-
数据实时输出:Amazon Redshift 支持 JDBC 协议,可以作为各类 BI 报表产品的数据源,实现数据的实时输出;Amazon Redshift Data API 可以将数据以 API 的方式提供给第三方,Amazon Redshift Data API 不需要与集群的持久连接。提供了安全 HTTP 终端节点以及与亚马逊云科技开发工具包的集成。使用终端节点运行 SQL 语句,无需管理连接。对 Data API 的调用是异步的。

图6 Amazon Redshift Data API
-
Amazon Redshift 实时数仓+ML:为实时数仓增加机器学习和人工智能的能力,是大多数企业在建设实时数仓过程中面临的一个难题,主要问题在于:1、机器学习的门槛高;2、机器学习开发人员招聘困难。Amazon Redshift实时数仓架构利用 Amazon Redshift ML 产品解决了上述难点,大大降低了建设智能湖仓的难度。
Amazon Redshift ML 使 SQL 用户可以轻松地使用熟悉的 SQL 命令创建、训练和部署机器学习模型。通过使用 Amazon Redshift ML,可以使用 Redshift 集群中的数据来通过 Amazon SageMaker 训练模型。随后,模型将会本地化,并可在 Amazon Redshift 数据库中进行预测。借助 Amazon Redshift ML,无需移动数据或学习新技能,即可利用 Amazon SageMaker 这种完全托管的机器学习服务。
借助由 Amazon SageMaker 提供支持的 Amazon Redshift ML,使用 SQL 语句从 Amazon Redshift 中的数据创建和训练机器学习模型,然后将这些模型用于多种使用案例场景,例如直接在查询和 BI 报表中进行流失预测和欺诈风险评分。
用写 SQL 语句的方式,开发机器学习功能,底层各种机器学习算法的复杂性,交由 Amazon Redshift ML 解决,客户可以将更多的精力专注在业务上面。
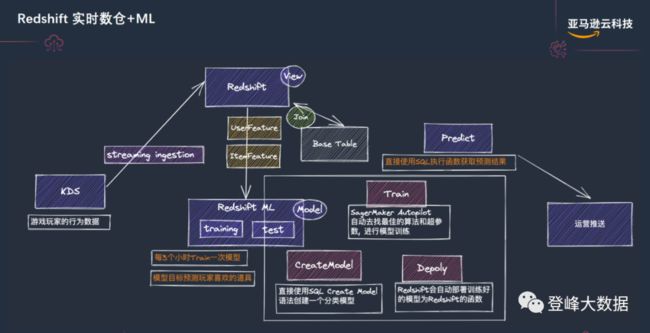
图7 Amazon Redshift 实时数仓+ML
Serverless 实时数仓架构的优势
成熟的技术架构,可以大大降低企业的人力和财力成本。传统的实时数仓架构(采用托管服务器的方式),无法实现削峰平谷。以电商行业为例,实时数仓架构的服务器资源,必须能够应对数据高峰(各类大型活动、促销与其他不可预测的工作负载)带来的压力,所以硬件采购往往是按资源峰值采购的,结果是大部分资源在大部分时间都是闲置的,无形提高了企业成本;传统实时数仓架构,无法实现无感扩展,即服务器集群节点的增加和减少,会增加运维人员工作量,可能会带来业务的暂停。总的来说,Serverless 实时数仓架构的优势包括如下几点:
-
Serverless 实时数仓架构让数据仓库优雅的具备实时数据分析能力(实时 OLAP 看板,实时业务监测);
-
Serverless 实时数仓架构让实时智能分析成为可能(基于实时数据与历史数据的实时风控/实时推荐/实时机器学习);
-
亚马逊云科技提供了云上实时数仓搭建最全面的功能组件,让用户可以敏捷,高效,低成本的构建自己的实时数仓;
-
使用 Serverless 实时数仓云平台,自动拥有削峰平谷、无感扩展、运维简单、易于使用等优势。