jsonpath
jsonpath是使用一种简单的方法提取给定的json文档的部分内容,我们做接口测试时,目前主要流行的数据结构是json,遇到复杂的json格式,使用jsonpath提取数据
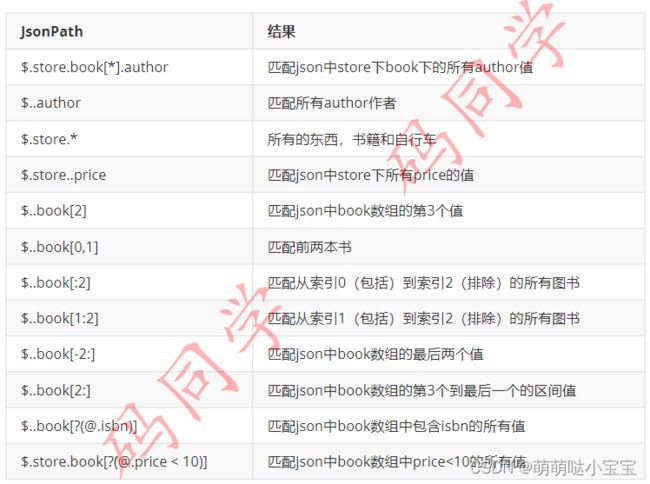
1、jsonpath操作符
| 操作 | 说明 |
|---|---|
| $ | 查询根元素, |
| @ | 当前接口由过滤词处理 |
| * | 通配符, |
| . . | 深度扫描 |
| . | 表示子节点 |
| [“(,”)] | 括号表示子项 |
| [(,)] | 数组索引或者索引 |
| [start:end] | 数组切片 |
| [?()] | 过滤表达式,表达式要求值为一个布尔值 |
2、过滤器运算符
过滤器是筛选数组的逻辑表达式,一个典型的过滤器是[[email protected]>18)],其中@正在处理的当前节点,可以使用逻辑运算符&&和||创建更复杂的过滤器,字符串文字必须用单引号或者双引号括起来,([email protected]==‘blue’)]或者[[email protected]==‘blue’)])
在线调试jsonpath:http://www.e123456.com/aaaphp/online/jsonpath/?
jsonpath示例:
提取token:
token = jsonpath.jsonpath(res.json(),'$.data')[0]
#1、第一个参数表示要解析的对象
#2、第二个参数你要提取的数据对应的jsonpath表达式
#3、如果表达式能够取到值,不管是1个还是多个,返回的都是列表,所以我们在后面加了[0]
#4、如果表达式匹配不到数据,那么它返回的值是False
接口数据驱动测试框架实战
1、数据驱动框架设计
1、框架结构
- common:这是一个package,主要用来存储所有底层的代码封装
- logs:这是一个目录,主要用来存储日志文件
- report:这是一个目录,data表示测试结果数据,htnl测试报告
- testcases:这是一个目录,用来存储excel文件,excel 文件时接口测试相关的数据
- conftest.py:重写pytest自带的内置函数,统一管理自定义的fixture
- pytest.ini:pytest相关的配置参数
- run.py:整个框架执行的入口
2、excel数据规则设计
按照一定的维度进行分类,每个分类可以当作一个sheet工作表
- 全局变量:主要用来管理我们的公共数据
| 变量名称 | 变量值 |
|---|---|
| host | http://82.156.74.26:9099 |
| username | 18866668888 |
| password | 123456 |
- 接口默认参数
通常在一个项目中,json参数如果有很多个的时候,我们针对测试用例去传递参数会很麻烦,所以我们针对每个接口的默认参数数据进行单独处理,在测试时只需要针对当前测试用例传递你要测试的某个字段值即可,其他字段统统采用默认值
填写参数的规则:对于接口参数可能会有好几种类型的,data类型、params类型、json类型、文件等
data类型:
{
"data":{
"xxx":"xxxxxxx"
}
}
params类型
{
"params":{
"xxx":"xxxxxxx"
}
}
json类型:
{
"json":{
"xxx":"xxxxxxx"
}
}
混合参数(既有data,也有params,有json
{
"data":{
"xxx":"xxxxxxx"
}
"json":{
"xxx":"xxxxxxx"
}
"params":{
"xxx":"xxxxxxx"
}
}
| 接口名称 | 默认参数 |
|---|---|
| 登录 | { “data”: { “username”: “ u s e r n a m e " , " p a s s w o r d " : " {username}", "password": " username","password":"{password}” }} |
| 新增客户 | { “json”: { “entity”: { “customer_name”: “沙陌001”, “mobile”: “18729399607”, “telephone”: “01028375678”, “website”: “http://mtongxue.com/”, “next_time”: “2022-05-12 00:00:00”, “remark”: “这是备注”, “address”: “北京市,北京城区,昌平区”, “detailAddress”: “霍营地铁口”, “location”: “”, “lng”: “”, “lat”: “” } }} |
| 新建联系人 | { “json”: { “entity”: { “name”: “沙陌001联系人”, “customer_id”: “${customerId}”, “mobile”: “18729399607”, “telephone”: “01028378782”, “email”: “[email protected]”, “post”: “采购部员工”, “address”: “这是地址”, “next_time”: “2022-05-10 00:00:00”, “remark”: “这是备注” } }} |
- 测试集合管理
测试集合管理主要是为了控制要执行那些测试集合,以及测试集合执行的顺序
测试集合名称:对应的就是某个测试集合的sheet工作表名称
是否执行:只有值是y时才会被执行,其他的不会被执行
| 测试集合名称 | 是否被执行 |
|---|---|
| 新增客户接口测试集合 | y |
| 新增联系人接口集合 | y |
- 测试集合
每个测试集合在excel里面是一个单独的sheet工作表,它负责某个模块或者某个接口相关的测试用例数据管理,一个测试集合中是可以存在多个测试用例的- 序号:仅仅是一个标识,没有任何作用
- 用例名称:一个用例可能会有多个接口的先后调用,在excel里一行数据就是针对一个接口的调用,多行数据就是多接口的调用,如果一个用例需要用多行数据,那么这几行的用例名称保持一致
- 接口名称:该列主要是为了和接口默认参数中的接口名称相关联,通过接口名称得到该接口对应的默认参数,然后再根据测试数据来决定参数是什么
- 接口地址:表示接口地址,在接口地址里域名几乎都是相同的,都都是公用的,所以将域名作为一个公共变量进行存储,调用方式${host},host就是公共变量里面的一个变量
- 请求方式:get、post、put、delete
- 请求头信息:指的就是headers,对于一个接口来说不一定有特殊的信息头,那么就不填,如果有,需要按照下面格式填写,以json格式字符串方式
token就是从登录接口返回值中提取的,提取之后保存在一个变量中,保存的变量名叫token,所以在这里引用变量token,采用${token}

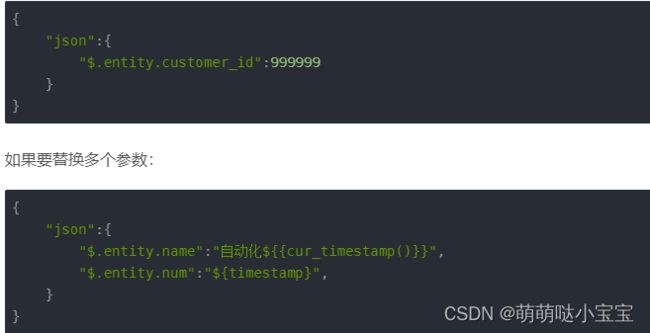
- 测试数据:指的是接口发起调用时传递的你要测试的某个数据,对于一个接口来说参数有很多个,但是我们每次测试的时候,可能只是针对一两个参数进行测试,可以借助jsonpath去匹配某些参数,并且替换它们的值
设计思路:
一个json格式的字符串,其中参数类型分为data、json、params、files
其中的key是要替换的目标参数对应的jsonpath,value就是对应的新值,也就是测试数据
- 响应提取:相应提取是为了从当前接口返回值中提取某些信息,保存在变量中,以便后续接口使用时进行变量引用,这就是关联
比如每个接口都用到token,token是登录接口产生的,所以登陆的响应提取里面要提取的内容,规则就是以json格式的字符串作为标准格式,其中key为变量名称,value是要提取的参数对应的jsonpath表达式

- 期望响应状态码:http状态码期望值
- 期望响应信息:表示我们针对接口的响应信息中的某些参数进行断言,设计规则如下:
是一个json格式的字符串,最外层是一个列表,里面嵌套多个字典,一个字典就是一个参数的断言,每个字段必须包括两个键值对,一个是actual(实际值)的key,实际值的value对应参数jsonpath表达式,一个except(期望值)的key,期望值的value标识期望内容

3、数据驱动框架底层代码实现
1、创建项目
依赖于设计去创建项目结构
2、excel数据读取
在common这个package下新建excel_util.py文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Time : 2022/6/16 16:40
@Author : liudan
@File : excel_util.py
@Desc :
"""
import openpyxl
#读取全局变量sheet工作表
def get_variables(wb):
sheet_data = wb['全局变量']
variables = {} #用来存储读取到的变量,名称是key,值是value
line_count = sheet_data.max_row #获取总行数
for l in range(2,line_count+1):
key = sheet_data.cell(l,1).value
value = sheet_data.cell(l,2).value
variables[key] = value
return variables
#读取接口默认参数
def get_api_default_params(wb):
sheet_data = wb['接口默认参数']
api_default_params = {} # 用来存储读取到的变量,名称是key,值是value
line_count = sheet_data.max_row # 获取总行数
for l in range(2, line_count + 1):
key = sheet_data.cell(l, 1).value
value = sheet_data.cell(l, 2).value
api_default_params[key] = value
return api_default_params
#读取要执行的测试集合
def get_casesuitename(wb):
sheet_data = wb['测试集合管理']
case_suite_name = [] # 用来存储读要执行的测试集合名称
line_count = sheet_data.max_row # 获取总行数
for l in range(2, line_count + 1):
flag = sheet_data.cell(l, 2).value
if flag == 'y':
suite_name = sheet_data.cell(l, 1).value
case_suite_name.append(suite_name)
return case_suite_name
#需要根据要执行的测试用例集合名称来读取对应的测试用例数据
def read_testcases(wb,suite_name):
sheet_data = wb[suite_name]
line_count = sheet_data.max_row #总行数
cols_count = sheet_data.max_column #总列数
"""
规定读取出来的测试数据存储结构如下:
{
“新增客户正确”:[
['apiname','接口地址','请求方式',...],
['apiname','接口地址','请求方式',...],
]
’新增客户失败“:[
['apiname','接口地址','请求方式',...],
]
'新增客户失败-手机号格式不正确‘[
['apiname','接口地址','请求方式',...],
]
}
"""
cases_info = {} #用来存储当前测试集合中的所有用例的信息
for l in range(2,line_count+1):
case_name = sheet_data.cell(l,2).value #测试用例名称
lines = [] #用来存储当前行的测试数据
for c in range(3,cols_count+1):
cell = sheet_data.cell(l,c).value #单元格数据
if cell == None:
cell = ''
lines.append(cell)
#判断当前用例名称是否已存在与case_info中
#如果不存在,那就直接赋值
#如果存在,在原来的基础上赋值
if case_name not in cases_info:
cases_info[case_name] = [lines]
else:
cases_info[case_name].append(lines)
return cases_info
#整合所有要执行的测试用例数据,将其转换成pytest参数化需要的数据个够格式
def get_all_testcases(wb):
"""
整合后的数据结构是
[
['新增客户接口测试集合','新增客户正确',[[],[]]]
['新增客户接口测试集合','新增客户失败-用户名为空',[[],[]]]
]
:param wb:
:return:
"""
test_data = [] #用来存储所有测试数据
#获取所有要执行的测试用例集合名称
case_suite_name = get_casesuitename(wb)
for suite_name in case_suite_name:
#遍历读取每个要执行的测试集合sheet工作表中的测试用例数据
cur_cases_info = read_testcases(wb,suite_name) #是字典
for key,value in cur_cases_info.items():
#key是测试用例名称,value是测试用例多行数据信息
case_info = [suite_name,key,value]
test_data.append(case_info)
return test_data
if __name__ == '__main__':
wb = openpyxl.load_workbook(r'../testcases/CRM系统接口测试用例.xlsx')
print(get_variables(wb))
print(get_api_default_params(wb))
print(get_casesuitename(wb))
print(read_testcases(wb, '新建联系人接口测试集合'))
print('-------------------------------------')
print(get_all_testcases(wb))
3、接口调用底层方法封装
在common这个package下新建requests_util.py文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Time : 2022/6/16 18:55
@Author : liudan
@File : requests_util.py
@Desc :
"""
import requests
import jsonpath
session = requests.session()
class RequestsClient:
def send(self,url,method,**kwargs):
try:
self.resp = session.request(url=url,method=method,**kwargs)
except BaseException as e:
raise BaseException(f'接口发起异常:{e}')
return self.resp
#针对jsonpath的数据提取
#第一个参数指的是匹配的数据jsonpath表达式
#第二个参数指的是想要返回匹配到的第几个,默认是0,表示第一个
def extract_resp(self,json_path,index=0):
#注意有的接口是没有返回信息的,返回信息为空
text = self.resp.text #获取返回信息的字符串形式
if text != '':
resp_json = self.resp.json() #获取响应信息的json格式
#如果能匹配到值,那么res就是个列表
#如果匹配不到res就返回False
res = jsonpath.jsonpath(resp_json,json_path)
if res:
#如果index<0,我认为你想要匹配所有的结果
if index < 0:
return res
else:
return res[index]
else:
print("没有匹配到任何数据")
else:
raise BaseException('接口返回信息为空,无法提取')
if __name__ == '__main__':
client = RequestsClient()
client.send(
url = 'http://82.156.74.26:9099/login',
method = 'post',
data = {
"username":"18866668888",
"password":123456
},)
print(client.extract_resp('$.Admin-Token'))
4、辅助函数封装及引用定义
在我们测试的时候,有的参数并不能够写死,所以这个时候我们希望某些参数在每次执行的时都是动态变化的,那么就需要我们封装一些辅助随机函数来帮助我们完成数据的动态变化
在common下新建一个 util_func.py文件,在其中写上我们所需要的辅助该函数
随机数生成可以用第三方库:faker
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Time : 2022/6/17 10:59
@Author : liudan
@File : util_func.py
@Desc :
"""
import hashlib
import time
from faker import Faker
fake = Faker(locale='zh_CN')
def rdm_phone_number():
return fake.phone_number()
def cur_timestamp(): #到毫秒级的时间戳
return int(time.time()*1000)
def cur_date(): #2022-12-25
return fake.date_between_dates()
def cur_date_time(): #2022-12-25 10:4:2
return fake.date_time_between_dates()
def rdm_date(pattern="%Y-%m-%d"):
return fake.date(pattern=pattern)
def rdm_date_time():
return fake.date_time()
def rdm_future_date_time(end_date): #未来30天
return fake.future_datetime(end_date=end_date)
def md5(data):
data = str(data)
return hashlib.md5(data.encode('UTF-8')).hexdigest()
if __name__ == '__main__':
print(rdm_phone_number())
print(cur_date())
print(cur_date_time())
print(rdm_date())
print(rdm_date_time())
print(rdm_future_date_time('+60d'))
print(md5('admin'))
在excel中需要动态函数的时候,调用规则是 m d 5 ( a d m i n ) , {{md5(admin)}}, md5(admin),{{rdm_future_date_time(‘+60d’)}}
5、正则表达式基本规则
| 元字符 | 描述 |
|---|---|
| \ | 转义字符 |
| * | 匹配前面的子表达式任意次,0~n |
| + | 匹配前面的子表达式一次或多次(大于等于1次) |
| ? | 匹配前面的子表达式零次或一次 {0,1} |
| {n} | 匹配确定的n次 |
| {n,m} | 最少匹配n次且最多匹配m次 |
| .点 | 匹配除“\n”和"\r"之外的任何单个字符 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多地匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少地匹配“o”,得到结果 [‘o’, ‘o’, ‘o’, ‘o’] |
| \d | 匹配一个数字字符。等价于[0-9] |
| [a-z] | 字符范围。匹配指定范围内的任意字符 |