PYTHON的数据分析CUBES框架基础学习
一、什么是Cubes
Cubes是一个轻量级的Python框架和一套工具,用于开发报告和分析应用程序,在线分析处理(OLAP),多维分析和聚合数据的浏览(aggregated data)。主要包括几个内容:
1、工作区–多维数据集分析工作区
2、模型-数据描述(元数据):多维数据集,维度,概念层次结构,属性,标签,本地化。
3、浏览器-聚合浏览,切片和切块,下钻。
4、后端-实际的聚合实施和实用程序功能。
5、服务器-用于多维数据集的WSGI HTTP服务器。
6、格式化程序-数据格式化程序。
7、切片器-命令行工具-命令行工具。
二、Cubes主要能做什么
1、在线分析处理(OLAP) 和聚合浏览(默认后端用于关系数据库 – ROLAP)
2、多维分析
3、分析数据的逻辑视图 – 分析师如何看待数据,他们如何看待数据,而不是如何在数据存储中实际实现数据
4、层次维度(具有层次依赖性的属性,例如类别子类别或国家/地区)
5、可本地化的元数据和数据
6、多维聚合查询的 SQL 查询生成器
7、OLAP 服务器
三、各组件功能介绍
1、分析工作区
“多维数据集”中的所有内容都发生在分析工作区中。它包含多维数据集,维护与数据存储的连接(带有多维数据集数据),提供与外部多维数据集的连接等等。
工作空间属性在配置文件中指定slicer.ini(默认名称)。我们要做的第一件事是指定一个数据存储——包含多维数据集数据的数据库:
[store]
type: sql
url: sqlite:///data.sqlite
在Python中,可以使用初始化设置文件的后缀名配置:
from cubes import Workspace
workspace = Workspace(config=”slicer.ini”)
或者通过编程:
workspace = Workspace()
workspace.register_default_store(“sql”, url=”sqlite:///data.sqlite”)
 2、模型
2、模型
在slicer.ini文件指定型号:
[workspace]
model: tutorial_model.json
文件内容例子如下:
{
“dimensions”: [
{
“name”:”item”,
“levels”: [
{
“name”:”category”,
“label”:”Category”,
“attributes”: [“category”, “category_label”]
},
{
“name”:”subcategory”,
“label”:”Sub-category”,
“attributes”: [“subcategory”, “subcategory_label”]
},
{
“name”:”line_item”,
“label”:”Line Item”,
“attributes”: [“line_item”]
}
]
},
{“name”:”year”, “role”: “time”}
],
“cubes”: [
{
“name”: “ibrd_balance”,
“dimensions”: [“item”, “year”],
“measures”: [{“name”:”amount”, “label”:”Amount”}],
“aggregates”: [
{
“name”: “amount_sum”,
“function”: “sum”,
“measure”: “amount”
},
{
“name”: “record_count”,
“function”: “count”
}
],
“mappings”: {
“item.line_item”: “line_item”,
“item.subcategory”: “subcategory”,
“item.subcategory_label”: “subcategory_label”,
“item.category”: “category”,
“item.category_label”: “category_label”
},
“info”: {
“min_date”: “2010-01-01”,
“max_date”: “2010-12-31”
}
}
]
}
有关如何向工作区添加更多模型的更多信息,请参见https://cubes.readthedocs.io/en/latest/configuration.html
Python中的等价形式是:
>>> workspace.import_model(“tutorial_model.json”)
唯一的限制是公共多维数据集和公共维度应该有唯一的名称。
3、浏览器-聚合浏览
 聚合浏览的抽象(具体实现由包中的一个后端提供backend或者定制后端)。
聚合浏览的抽象(具体实现由包中的一个后端提供backend或者定制后端)。
创建并初始化聚合浏览器。子类应该覆盖这个方法。
aggregate(cell=None, aggregates=None, drilldown=None, split=None, order=None, page=None, page_size=None, **options)
cell:要聚合的单元格。可以是cubes.Cell对象或与切片器语法相同的字符串计算机网络服务器
aggregates :汇总措施列表。默认情况下,所有多维数据集的聚合都包含在结果中。
drilldown:向下钻取的维度和级别
split:替代“分割”维度的单元格。与相同类型的论证细胞.
order:属性顺序规范(见下文)
page:请求分页页号
page_size:每页的记录数
4、后端
两个对象在多维数据集后端中起主要作用:
1)aggregation browser(聚合浏览器)
负责聚合、事实列表、维度成员列表
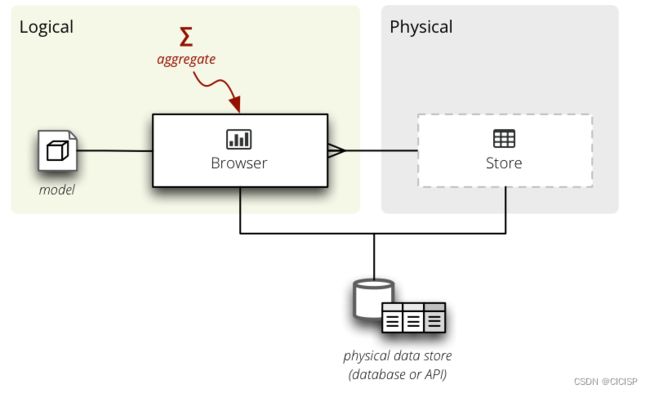
2)store
表示由多个浏览器共享的数据库连接
多维数据集的数据由数据存储–每个立方体都有一个。

5、服务器
部署多维数据集OLAP Web服务服务器(用于分析API)可以通过四个非常简单的步骤来完成:
- 创建切片器服务器配置文件
- 创建WSGI脚本
- 准备apache站点配置
- 重新加载apache配置
将该文件放在与下面的WSGI脚本相同的目录中(为了方便)。
创建一个WSGI脚本/var/www/wsgi/olap/procurements.wsgi:
import os.path
from cubes.server import create_server
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
# Set the configuration file name (and possibly whole path) here
CONFIG_PATH = os.path.join(CURRENT_DIR, “slicer.ini”)
application = create_server(CONFIG_PATH)
Apache站点配置(例如在/etc/apache2/sites-enabled/):
ServerName olap.democracyfarm.org
WSGIScriptAlias /vvo /var/www/wsgi/olap/procurements.wsgi
WSGIProcessGroup olap
WSGIApplicationGroup %{GLOBAL}
Order deny,allow
Allow from all
ErrorLog /var/log/apache2/olap.democracyfarm.org.error.log
CustomLog /var/log/apache2/olap.democracyfarm.org.log combined
重新加载apache配置:
sudo /etc/init.d/apache2 reload
6、格式化程序-数据格式化程序
聚合结果中的数据和元数据可以使用格式化程序转换为多种形式之一:
formatter = cubes.create_formatter(“text_table”)
result = browser.aggregate(cell, drilldown=”date”)
print formatter.format(result, “date”)
可用模板:
文本_表格–向下钻取一个维度的结果的文本输出
简单数据表格–返回包含以下内容的字典页眉和行
简单_ html _表格–返回结果表格单元格的HTML表格表示形式
交叉表–带属性的交叉表结构行–行标题,列–列标题和数据有一排排的细胞
html _交叉_表格–HTML版本的交叉表格式程序
7、切片服务器

可以使用切片器服务器后端从其他切片器服务器插入多维数据集。
Store 配置和模型
Slicer
url–切片器URL
authentication–源服务器的身份验证方法(仅支持none和pass_parameter)
auth_identity–身份验证身份(或API密钥)用于pass_parameter认证。
Model
切片器后端从源服务器动态生成模型。您必须指定提供者是slicer:
{
“provider”: “slicer”
}
对于多个切片器,请为每个源切片器服务器创建一个文件,并指定数据存储:
{
“provider”: “slicer”,
“store”: “slicer_2”
}
四、参考材料:
https://cubes.readthedocs.io/en/latest/tutorial.html