基于TF-IDF+KMeans聚类算法构建中文文本分类模型(附案例实战)

♂️ 个人主页:@艾派森的个人主页
✍作者简介:Python学习者
希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 点赞 收藏 加关注+
目录
1.TF-IDF算法介绍
2.TF-IDF算法步骤
3.KMeans聚类
4.项目实战
4.1加载数据
4.2中文分词
4.3构建TF-IDF模型
4.4KMeans聚类
4.5可视化
5.总结
1.TF-IDF算法介绍
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。简单来说就是:一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章。这也就是TF-IDF的含义。

TF(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。
这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。
公式:
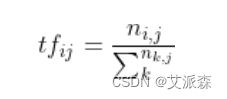
(术语 t 在文档中出现的次数) / (文档中的术语总数)
但是,需要注意, 一些通用的词语对于主题并没有太大的作用, 反倒是一些出现频率较少的词才能够表达文章的主题, 所以单纯使用是TF不合适的。权重的设计必须满足:一个词预测主题的能力越强,权重越大,反之,权重越小。所有统计的文章中,一些词只是在其中很少几篇文章中出现,那么这样的词对文章的主题的作用很大,这些词的权重应该设计的较大。IDF就是在完成这样的工作。
IDF(Inverse Document Frequency)
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
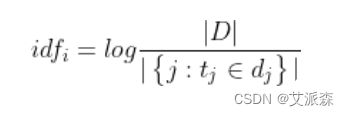
log_e(文档总数/包含术语 t 的文档数)
其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|。
IDF用于衡量一个术语的重要性。在计算 TF 时,所有项都被认为同样重要。然而,众所周知,某些术语,如"是","的"和"那个",可能会出现很多次,但并不重要。
TF-IDF(Term Frequency-Inverse Document Frequency)
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语,表达为 :
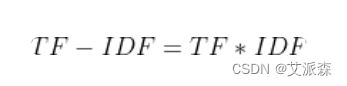
注: TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
2.TF-IDF算法步骤
第一步,计算词频:

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

第二步,计算逆文档频率:
这时,需要一个语料库(corpus),用来模拟语言的使用环境,
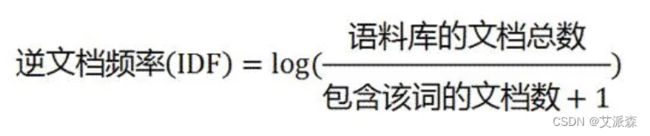
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF:
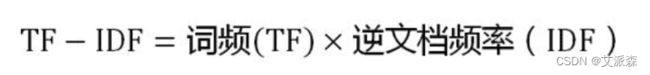
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
3.KMeans聚类
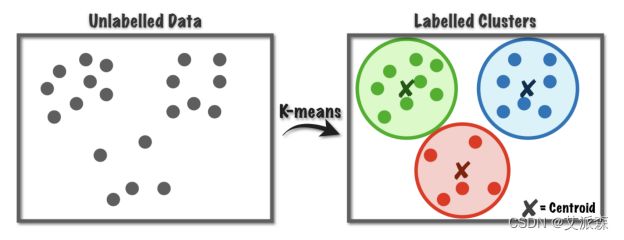
什么是聚类任务
- 1 无监督机器学习的一种
- 2 目标将已有数据根据相似度划分到不同的簇
- 3 簇内样本彼此之间越相似,不同簇的样本之间越不相似,就越好
为什么叫KMeans聚类
- 1 也可以叫K均值聚类
- 2 K是最终簇数量,它是超参数,需要预先设定
- 3 在算法计算中会涉及到求均值
KMeans流程
- 1 随机选择K个簇中心点
- 2 样本被分配到离其最近的中心点
- 3 K个簇中心点根据所在簇样本,以求平均值的方式重新计算
- 4 重复第2步和第3步直到所有样本的分配不再改变
如何计算样本到中心点的距离
1. 欧氏距离测度 Euclidean Distance Measure
欧氏距离越大,相似度越低
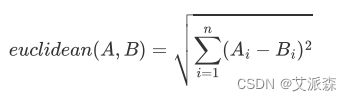
2. 余弦距离测度 Cosine Similarity Measure
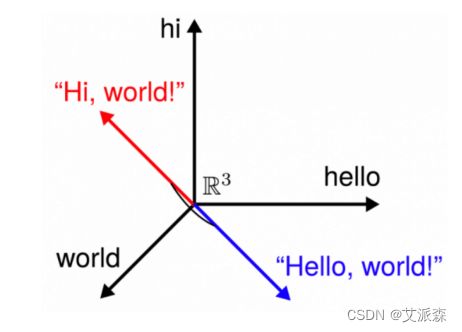
夹角越大,余弦值越小,相似度越低
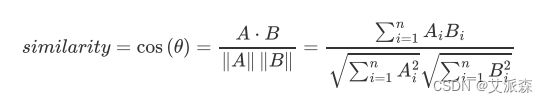
因为是cosine,所以取值范围是-1到1之间,它判断的是向量之间的 方向而不是大小;两个向量有同样的方向那么cosine相似度为1,两 个向量方向相对成90°那么cosine相似度为0,两个向量正相反那么 cosine相似度为-1,和它们的大小无关。
选择Cosine相似度还是欧氏距离
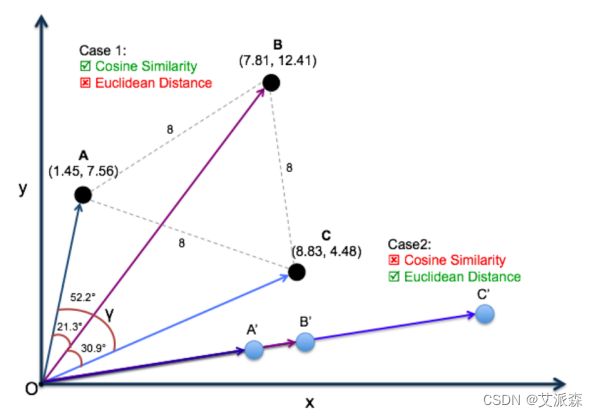
总体来说,欧氏距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。
例如,统计两部剧的用户观看行为,用户A的观看向量为(0, 1),用户B为(1,0);此时二者的余弦距离很大,而欧氏距离很 小;我们分析两个用户对于不同视频的偏好,更关注相对差异,显 然应当使用余弦距离。 而当我们分析用户活跃度,以登陆次数(单位:次)和平均观看时长 (单位:分钟)作为特征时,余弦距离会认为(1,10)、(10, 100)两个用户距离很近;但显然这两个用户活跃度是有着极大差 异的,此时我们更关注数值绝对差异,应当使用欧氏距离。
KMeans算法目标函数
上面的公式既是要去最小化的目标函数,同时也可以作为评价 KMeans聚类效果好坏的评估指标。
KMeans算法不保证找到最好的解
事实上,我们随机初始化选择了不同的初始中心点,我们或许会获 得不同的结果,就是所谓的收敛到不同的局部最优;这其实也就从事实上说明了目标函数是非凸函数。
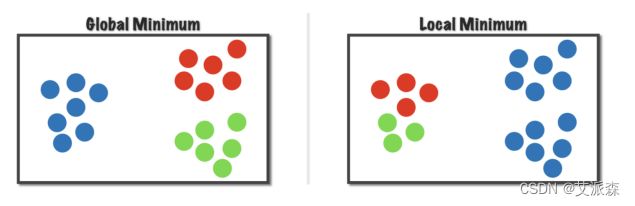
一个通常的做法就是运行KMeans很多次,每次随机初始化不同的 初始中心点,然后从多次运行结果中选择最好的局部最优解。
KMeans算法K的选择
没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题, 人工进行选择的。
肘部法则(Elbow method)
改变聚类数K,然后进行聚类,计算损失函数,拐点处即为推荐的聚 类数 (即通过此点后,聚类数的增大也不会对损失函数的下降带来很大的影响,所以会选择拐点)。
目标法则
如果聚类本身是为了有监督任务服务的(例如聚类产生features 【譬如KMeans用于某个或某些个数据特征的离散化】然后将 KMeans离散化后的特征用于下游任务),则可以直接根据下游任务的metrics进行评估更好。
4.项目实战
4.1加载数据
实验环境:Python3.9
编辑工具:jupyter notebook
首先导入实验用到的第三方库并加载数据
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
import jieba
import matplotlib.pyplot as plt
import pandas as pd
import re
import warnings
warnings.filterwarnings('ignore')
data = pd.read_csv('data.csv')
data.head()
查看各个类型新闻的大小
print(data.shape) # 查看数据大小
data['类型'].value_counts()
从结果中可以发现本次数据集共有25000条数据,其中有5个量相等新闻类型。
4.2中文分词
这一步需要构建语料库并进行中文分词(去除异常符号、分词、去停用词)
def chinese_word_cut(mytext):
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', mytext, re.S)
new_data = " ".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=True)
result_list = []
# 加载停用词库
with open('停用词库.txt', encoding='utf-8') as f: # 可根据需要打开停用词库,然后加上不想显示的词语
stop_words = set()
for i in f.readlines():
stop_words.add(i.replace("\n", "")) # 去掉读取每一行数据的\n
# 去除停用词
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
return " ".join(result_list)
data['分词结果'] = data['内容'].apply(chinese_word_cut)
data.head()
4.3构建TF-IDF模型
vectorizer = CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(data['分词结果']))
tfidf_weight = tfidf.toarray()运行上述代码时,如果你的磁盘分配内存不够会出现以下报错:
![]()
具体解决方法可以参考:成功解决Windows MemoryError: Unable to allocate 6.38 GiB for an array with shape (38_王壹浪的博客-CSDN博客_memoryerror: unable to allocate 240. mib for an ar
由于使用上述代码最后会造成词袋长度过大,导致维度灾难,所以我对上述代码进行修改,加上了降维的操作,使得离散的特征能集中化,也能提高最后模型分类的准确率。
from sklearn.decomposition import TruncatedSVD
from sklearn.preprocessing import Normalizer
from sklearn.pipeline import make_pipeline
vectorizer = CountVectorizer()
svd = TruncatedSVD(5000) # 降到5000维
normalizer = Normalizer(copy=False) # 标准化
lsa = make_pipeline(svd,normalizer)
X = lsa.fit_transform(vectorizer.fit_transform(data['分词结果']))
X.shape
接着再构建TF-IDF模型
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
tfidf_weight = tfidf.toarray()
tfidf_weight
4.4KMeans聚类
因为在前面我们已经知道了该数据集是分为5类的,所里这里的K选取5
# 指定分成5个类
kmeans = KMeans(n_clusters=5)
kmeans.fit(tfidf_weight)
# 打印出各个簇的中心点
print("中心点坐标:")
print(kmeans.cluster_centers_)
for index, label in enumerate(kmeans.labels_, 1):
print("index: {}, label: {}".format(index, label))
# 样本距其最近的聚类中心的平方距离之和,用来评判分类的准确度,值越小越好
# k-means的超参数n_clusters可以通过该值来评估
print("效果评估值:")
print("inertia: {}".format(kmeans.inertia_))

我们还可以将聚类的结果保存为excel文件
# 保存结果至excel
data['label'] = kmeans.labels_
data.to_excel("data_labeled.xlsx",index=False)
4.5可视化
前面我们已经使用了KMeans进行了聚类,现在我们将聚类的结果进行可视化。由于聚类结果是5类,如果需要在二维平面展示,则先要降到2维。
# 使用T-SNE算法,对权重进行降维,准确度比PCA算法高,但是耗时长
tsne = TSNE(n_components=2)
decomposition_data = tsne.fit_transform(tfidf_weight)
x = []
y = []
for i in decomposition_data:
x.append(i[0])
y.append(i[1])
fig = plt.figure(figsize=(10, 10))
ax = plt.axes()
plt.scatter(x, y, c=kmeans.labels_, marker="x")
plt.xticks(())
plt.yticks(())
plt.show() 
从可视化图中可以大致看出,聚类效果还可以,5个类别5种颜色。
因为本数据集中原始就有类别,所以我们可以将分类的类别和原始类别进行比较得出模型的分类准确率。从前面保存的ecxel文件中可以看出,0是科技类,1是财经类,2是时政类,3是体育类,4是娱乐类。
data['类型'].replace(to_replace={'科技':0,'财经':1,'时政':2,'体育':3,'娱乐':4},inplace=True)
right = 0
error = 0
for i,j in zip(data['类型'],data['label']):
if i == j:
right+=1
else:
error+=1
print('模型分类准确率:',right/(right+error))
从结果看出模型的准确率为70%,模型效果一般,还有待提高。
5.总结
本次实验使用TF-IDF+KMeans聚类实现文本分类,聚类是一种无监督学习,数据集中只保留文本数据就可以训练得出类别,实验中我保留原始类别是最后可以通过原始类别来检测模型的准确率。最后的模型准确率为70%,效果还有待提高。在词向量后降维那里,5000是我随便想的数字,通过调节这个数字可以提高模型准确率。还有就是调节KMeans模型的参数,实验中我全都用的是默认参数。
以上就是本次项目实战的分享,过程中有疑问的小伙伴可以随时来联系我。