文章目录
- 背景
- 总体架构
- 类与方法
-
- BlockingConnection
-
- BlockingChannel
-
- queue_declare
- queue_delete
- exchange_declare
- basic_publish
- basic_consume
- 实验验证
-
- 安装
-
- erlang
- pika
- rabbitmq_server
- 启动
- RPC示例
-
背景
- Linux平台提供了各种进程间通信的机制,包括:套接字(socket)、管道(pipe)、消息队列等。这些机制基于Linux内核提供的接口实现。可以实现一台节点(服务器)上的两个应用程序的通信以及跨节点的应用程序通信。在不同的操作系统上,比如windows、Linux、FressBSD,这些应用程序间的通信实现与底层操作系统强相关。
- 如果有一个组件,它定义了进程消息通信的规范,所有的应用程序都按照这个规范实现消息收发,那么这个组件可以就可以实现跨平台、跨架构、跨语言的消息传递,任何应用只要按照这样的规范来实现消息收发,就可以最大程度地减少在消息通信组件上的开发量。
- AMQP(Advanced Message Queuing Protocol)就是这样一个规范,它规定了要实现一个消息中间件的标准规范。rabbitmq是这个规范的其中一个实现。有了rabbitmq,只要两个应用程序按照AMQP规范和rabbitmq server交互,就可以轻易的完成消息通信并基于此通道定制更高级的通信功能比如RPC。
- 更进一步,应用程序需要按照AMQP规范来和rabbitmq server交互,这部分的工作可以单独摘出来实现,不同编程语言有各自的软件实现,比如pika模块,就是rabbitmq推荐的python实现,java、go也有也有基于AMQP规范的工具包和库。
总体架构
- rabbitmq server提供进程间消息传递的通道,无论是消息发送者还是消息的接收者,在rabbitmq server看来都是客户端,使用rabbitmq server提供的队列传递消息前,都需要先连接rabbitmq server。如下:
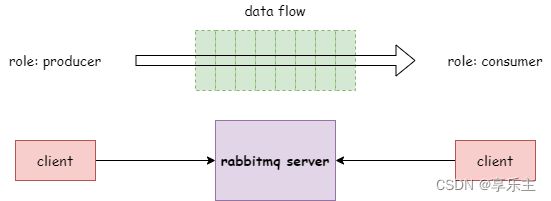
- 而客户端和rabbitmq server之间的通信遵守AMQP规范,只要实现该规范就可以用于连接rabbitmq server,我们本文中使用的pika逐渐,就是按照AMQP协议实现的一个与rabbitmq server通信的工具。这里我们以python客户端pika为例。
- 下图是AMQP(Advanced Message Queuing Protocol)规范中定义的AMQ(Advanced Message Queuing)具体模型:
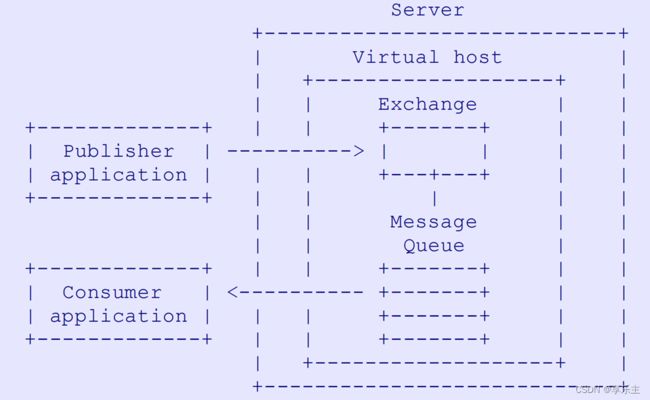 - AMQ模型包含了下面3个主要的实体:
- AMQ模型包含了下面3个主要的实体:
- message queue: 消息队列,这是AMQP规范的核心实体,它负责存储客户端消息的存储和转发,这些消息可以在内存中,也可以在磁盘上,消息队列根据应用场景定义了各种属性,比如消息私有/共享属性,暂态/持久化属性等。通过对消息队列各种属性的组合,AMQP可以实现传统的消息中间件实体,比如共享队列,可以将消息转发给多个消费者;私有队列,将消息转发给特定的一个队列等。
- exchange: 交换机,这是先于消息队列处理消息的实体,它负责路由客户端发来的消息到交换机绑定的消息队列上,交换机根据客户端设置的路由地址(routing key)将消息发送到正确的消息队列上。
- routing key:路由关键字,它扮演路由地址的角色,在点对点的路由场景下,routing key通常就是队列的名字。在基于标题的订阅的场景下,生产者的routing key通常是消费者routing key的子集,消费者的routing key通常用字符串匹配模型描述。
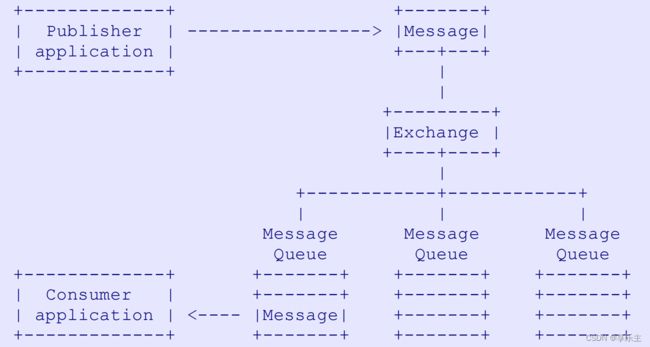
- 下图描述了一个消息通过rabbitmq server传输时的流向:
类与方法
BlockingConnection
BlockingConnection类声明的全路径为pika.BlockingConnection,它抽象了pika客户端工具和rabbitmq server的连接,封装了连接客户端的方法(__init__函数)以及通过客户端建立通信通道的方法(channel函数)。
init
BlockingConnection的初始化函数用来与rabbitmq server建立连接,传入pika.connection.Parameters类的实例作为参数,下面的代码用于连接本机上的rabbitmq server,返回一个BlockingConnection类的实例。
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
- 通过
rabbitmqctl list_connections可以看到连接到rabbitmq server的连接数,如下所示,pika客户端工具和rabbitmq server监听的5672端口建立了连接,客户端的端口为57428

channel
BlockingConnection的channel函数用于和rabbitmq server建立一个消息通信通道,这个方法返回pika.adapters.blocking_connection.BlockingChannel类的实例。客户端和rabbitmq server的所有通信都通过此通道展开,因此客户端利用rabbitmq通信的编程模型都基于这个类提供的方法展开。下面的代码创建了一个通道:
channel = connection.channel()
- 通过
rabbitmqctl list_channels可以看到连接到serverde channel信息:

BlockingChannel
BlockingChannel类声明的全路径为pika.adapters.blocking_connection.BlockingChannel,是对客户端与rabbitmq server通道的抽象,无论客户端作为生产者还是消费者,向rabbitmq server提供的队列发送消息基本都通过操作该对象的实例完成。这是rabbitmq 消息通信的核心类。
queue_declare
queue_declare是向rabbitmq server声明一个队列,如果这个队列不存在,rabbitmq server会创建,因此queue_declare可以说是创建rabbitmq的方法。下面的代码如果第一次调用,在rabbitmq server中会创建一个名为hello的消息队列:
channel.queue_declare(queue='hello')
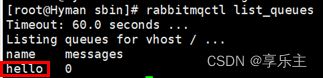
- 通过
rabbitmqctl list_queues可以看到rabbitmq server中创建的队列信息:
queue_delete
channel.queue_delete(queue='hello')
exchange_declare
- 声明一个用于路由消息的交换机,客户端通过这个函数来自定义自己的交换机,如果不定义则rabbitmq server会使用默认的交换机。该接口通常用来实现针对某个交换机订阅消息的模型,或者基于交换机的某个标题订阅消息的模型。下面订阅了一个fanout类型的的交换机,这种类型的交换会将它接收到的消息转发给所有绑定到该交换机的消息队列上。
channel.exchange_declare(exchange='logs', exchange_type='fanout')
basic_publish
- rabbitmq server是专为消息传递开发的开源组件,通常一个客户端发送消息,称生产者 —— producer ,另一个客户端接收消费,称消费者 —— consumer。当生成者准备好消息后,通过
basic_publish方法发送。basic_publish函数根据AMQP规范实现了消息发送,其具体用法参考AMQP手册。
basic_publish函数有两个重要的参数,分别是exchange和routing_key,exchange指定将本条消息发送到哪个交换机,routing_key设置该交换机在路由匹配时使用的关键字。- 下面的代码将message消息发送到rabbitmq server默认使用的交换机,并设置rabbitmq server通过"hello"关键字进行路由,这种情况下关键字通常为队列的名字。
channel.basic_publish(exchange='', routing_key='hello', body=message)
- 下面代码定义了一个
扇出类型的交换机,命令logs,然后将message消息发送到logs交换机,
channel.exchange_declare(exchange='logs', exchange_type='fanout')
channel.basic_publish(exchange='logs', routing_key='', body=message)
basic_consume
basic_consume方法是消费者接收rabbitmq消息的函数,它的核心参数是指定消费者感兴趣的队列名,以及消息到达时的处理函数,下面是客户端为消费者的代码,所有绑定到logs交换机上的队列,都会收到此消息,消息到达后通过callback函数处理,将其打印出来
channel.exchange_declare(exchange='logs', exchange_type='fanout')
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='logs', queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(
queue=queue_name, on_message_callback=callback, auto_ack=True)
实验验证
安装
erlang
- erlang语言是rabbitmq的实现语言,下载erlang零依赖源码并编译成rpm包
wget https://github.com/rabbitmq/erlang-rpm/archive/refs/heads/master.zip
unzip master.zip
cd erlang-rpm-master
make prepare
make erlang
cd RPMS/x86_64/ && rpm -ivh erlang-xxx-x.el7.x86_64.rpm
pika
- rabbitmq适配了多种消息队列协议,AMQP是其中一个,它是一个通用的开源消息传递协议。pika组件作为AMQP协议的实现,可以作为工具方便地与rabbitmq的队列交互,收发消息,这里需要安装,方便后续编程使用
python3.6 -m pip install pika --upgrade
rm -f /usr/bin/python && ln -s /usr/bin/python3.6 /usr/bin/python /* 将python软链接到python3.6 */
rabbitmq_server
- rabbitmq_server实现了消息队列,它作为server的形式供应用使用。客户端和服务端通过rabbitmq传递消息时,首先需要先和rabbitmq_server建立连接,我们需要下载该server并部署到本地。
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.10.6/rabbitmq-server-generic-unix-3.10.6.tar.xz
xz -d rabbitmq-server-generic-unix-3.10.6.tar.xz
tar -xf rabbitmq-server-generic-unix-3.10.6.tar
echo "export PATH=${PATH}:/path/to/rabbitmq_server-3.10.6/sbin" >> /etc/profile && source /etc/profile
启动
- 后台启动rabbitmq_server,其监听的端口默认为5672。
rabbitmq-server -detached

RPC示例
- 基于rabbitmq server的RPC的通用框架如下:
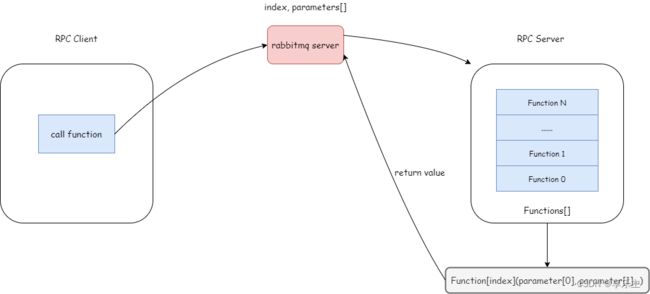
- 客户端将要调用的远程例程索引和函数通过rabbitmq server传递给服务端,服务端解析索引后在函数列表中匹配对应函数,执行例程,将例程的返回值再通过rabbitmq server返回给客户端。
- 我们将rabbitmq官网的RPC例子摘出,结合上面的rabbitmq基础支持分析其流程,我们的RPC服务端实现一个函数,接受一个整数n,返回整数n作为索引在斐波那契数列的值,函数如下:
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
- 客户端通过rabbitmq传输函数的输入n,服务端收到后执行函数并返回结果。
Server
#!/usr/bin/env python3.6
import pika
# 连接rabbitmq server,这里我们的rabbitmq server部署在本地,pika工具通过5672端口连接
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
# 建立和rabbitmq server的通道
channel = connection.channel()
# 声明一个名为rpc_queue的队列,如果rabbit sever没有会创建
channel.queue_declare(queue='rpc_queue')
# 实现客户端要调用的例程函数
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
# 实现rabbitmq server消息到达时的回调函数,处理客户端发送来的消息
def on_request(ch, method, props, body):
# 取出消息体并转化为整数
n = int(body)
print(" [.] fib(%s)" % n)
# 执行例程函数,获取函数返回值
response = fib(n)
# 将函数的返回值封装成消息体,发送到RPC的客户端
#
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag=method.delivery_tag)
# 设置通道的qos,规定客户端最多预取1条消息,防止客户端在处理完当前消息之前又接收到新的消息,造成消息的积压
channel.basic_qos(prefetch_count=1)
# 设置当rpc_queue队列有消息到达时,通过on_request函数进行处理
channel.basic_consume(queue='rpc_queue', on_message_callback=on_request)
print(" [x] Awaiting RPC requests")
# 开始监听rpc_queue队列
channel.start_consuming()
Client
#!/usr/bin/env python3.6
import pika
import uuid
# 实现一个远程调用的类
class FibonacciRpcClient(object):
# 实现类的初始化函数
def __init__(self):
# 连接到rabbitmq server
self.connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
# 创建到rabbitmq server的消息通道
self.channel = self.connection.channel()
# 声明队列,队列名由rabbitmq server自动生成
# 由于这个队列用于传输参数和返回结果,只需要RPC的调用者知道这个队列的存在
# 因此exclusive设置为true表示不允许其它客户端消费此队列的消息
result = self.channel.queue_declare(queue='', exclusive=True)
# 通过返回结果中的method属性,可以获取rabbitmq server自动生成的队列名
self.callback_queue = result.method.queue
# 将上面创建的队列设置为我们感兴趣的队列,将on_response函数作为消息到达时的处理函数
self.channel.basic_consume(
queue=self.callback_queue,
on_message_callback=self.on_response,
auto_ack=True)
self.response = None
self.corr_id = None
# RPC Server执行完例程后通过rabbitmq发送返回结果,消息到达时的处理函数
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
# 远程过程调用函数,接受n作为斐波那契数列索引
def call(self, n):
self.response = None
# 产生随机的uuid,用来标识RPC的每条消息
self.corr_id = str(uuid.uuid4())
# 将消息发送到rabbitmq server的默认交换机
# 交换机使用RPC服务端监听的队列名rpc_queue作为路由关键字
# 消息从交换机出来后会分发到rpc_queue队列,所有监听rpc_queue队列的客户端都会收到此消息
# 设置本次消息的属性:一是设置客户端在收到本次消息后的回调队列,二是标记本条消息的uuid
self.channel.basic_publish(
exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body=str(n))
# 阻塞等待直到发送的消息被处理
self.connection.process_data_events(time_limit=None)
# 返回RPC Server处理后的消息
return int(self.response)
# 初始化一个远程调用实例
fibonacci_rpc = FibonacciRpcClient()
# 调用RPC
print(" [x] Requesting fib(6)")
response = fibonacci_rpc.call(6)
print(" [.] Got %r" % response)