JDK 1.8 的Stream
Stream
1.Stream概述
Java 8 是一个非常成功的版本,这个版本新增的Stream,配合同版本出现的 Lambda ,给我们操作集合(Collection)提供了极大的便利。
Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。
Stream可以由数组或集合创建,对流的操作分为两种:
1.中间操作,每次返回一个新的流,可以有多个。
(1)无状态:指元素的处理不受之前元素的影响
filter map flatMap peek
(2)有状态:指该操作只有拿到所有元素之后才能继续下去
distinct sorted limit skip
2.终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值。
**(1)非短路操作:**指必须处理所有元素才能得到最终结果(需要遍历全量数据)
forEach reduce collect max min count
**(2)短路操作:**指遇到某些符合条件的元素就可以得到最终结果,如 A||B,只要A为true,则无需判断B的结果(不需要遍历全量数据)
anyMatch allMatch noneMatch findFirst findAny
另外,Stream有几个特性:
1.Stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
2.Stream不会改变数据源,通常情况下会产生一个新的集合或一个值。
3.Stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
| Stream操作 | ||
|---|---|---|
| 中间操作(Interediate Operations) | 无状态(stateless) | filter()、map()、mapToInt()、mapToLong()、mapToDoubl()、flatMap()、flatMapToInt()、flatMapToLong()、flatMapToDouble()、peek()、eunordered() |
| 有状态(Stateful) | distinct()、sorted()、sorted(Comparator comparator)、limit()、skip() | |
| 终端操作(Terminal Operations) | 非短路操作(Unshort-circuiting) | forEach()、forEachOrdered()、toArray()、reduce()、collect()、max()、min()、count() |
| 短路操作(Short-circuiting) | anyMatch()、allMatch()、noneMatch()、findFirst()、findAny() | |
2.Stream的创建
Stream创建可以通过三种方式创建。
- 通过
java.util.Collection.stream()方法用集合创建流 - 使用
java.util.Arrays.stream(T[] array)方法用数组创建流 - 使用
Stream的静态方法:of()、iterate()、generate()
/**
* 创建Stream测试
*/
@Test
public void createStream() {
//1.通过 `java.util.Collection.stream()` 方法用集合创建流
List<String> list = Arrays.asList("d","a", "b", "c");
Stream<String> streamList = list.stream();
System.out.println("###############顺序流##############");
streamList.forEach(System.out::print);
System.out.println();
System.out.println("###############并行流##############");
// 创建一个并行流
Stream<String> parallelStream = list.parallelStream();
parallelStream.forEach(System.out::print);
System.out.println();
//2.使用`java.util.Arrays.stream(T[] array)`方法用数组创建流
int[] array={1,3,5,6,8};
IntStream streamint = Arrays.stream(array);
streamint.forEach(System.out::print);
System.out.println();
//3.使用`Stream`的静态方法:`of()、iterate()、generate()
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
stream.forEach(System.out::print);
System.out.println();
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 3).limit(4);
stream2.forEach(System.out::print);
System.out.println();
Stream<Double> stream3 = Stream.generate(Math::random).limit(3);
stream3.forEach(System.out::print);
System.out.println();
}
3.Stream的中间操作
3.1 无状态操作
无状态操作:指元素的处理不受之前元素的影响。
3.1.1 筛选
筛选(filter)是按照一定的规则校验流中的元素,将符合条件的元素提取到新的流中的操作。
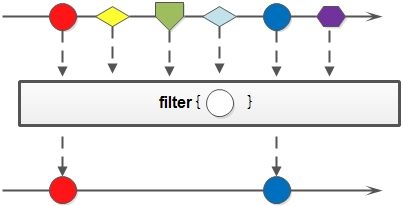
filter(Predicate predicate)参数Prediacte是接受一个参数,返回布尔值。
示例:筛选员工中工资高于8000的人,并形成新的集合
List<Person> personList = new ArrayList<>();
@Before
public void initPerson() {
personList.add(new Person("Tom", 8900, 18, "male", "New York"));
personList.add(new Person("Jack", 7000, 20, "male", "Washington"));
personList.add(new Person("Lily", 7800, 33, "female", "Washington"));
personList.add(new Person("Anni", 8200, 40, "female", "New York"));
personList.add(new Person("Owen", 9500, 46, "male", "New York"));
personList.add(new Person("Alisa", 7900, 46, "female", "New York"));
}
@Test
public void filterPerson() {
Stream<Person> personStream = personList.stream().filter((s) -> s.getSalary() > 8000);
personStream.forEach(System.out::println);
}
Person{name=‘Tom’, salary=8900, age=18, sex=‘male’, area=‘New York’}
Person{name=‘Anni’, salary=8200, age=40, sex=‘female’, area=‘New York’}
Person{name=‘Owen’, salary=9500, age=46, sex=‘male’, area=‘New York’}
3.1.2 映射
映射(map、flatMap、peek):映射,可以将一个流的元素按照一定的映射规则映射到另一个流中。
map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
简言之:将集合中的元素A转换成想要得到的B
<R> Stream<R> map(Function<? super T, ? extends R> mapper)
flatMap:接收一个函数作为参数返回值是流,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
简言之:与Map功能类似,区别在于将结合A的流转换成B流
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)
peek:操作接收的是一个Consumer函数。顾名思义 peek 操作会按照Consumer函数提供的逻辑去消费流中的每一个元素,同时有可能改变元素内部的一些属性。
Stream<T> peek(Consumer<? super T> action);
peek和map区别:peek主要用来修改数据,map用来进行数据转换。
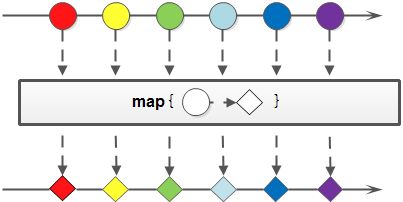
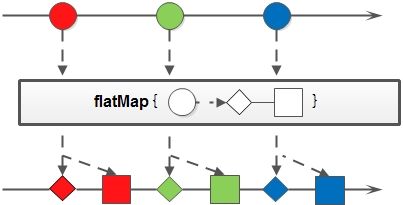
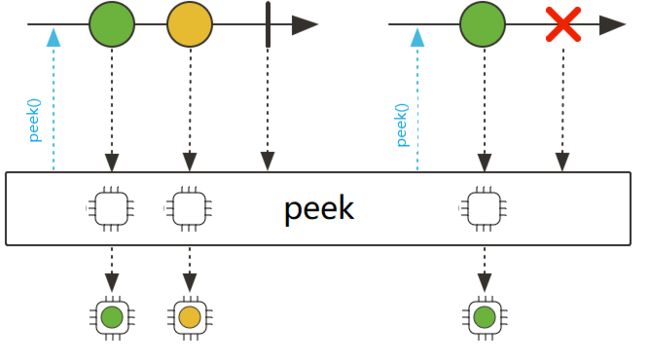
示例1:英文字符串数组的元素全部改为大写
@Test
public void mapPerson() {
List<String> list = Arrays.asList("abcd", "bc-dd", "def-de", "def-de");
Stream<String> stream = list.stream();
Stream<String> stringStream = stream.map(s -> s.toUpperCase());
System.out.println("处理前:" + list);
System.out.println("处理后:" + stringStream.collect(Collectors.toList()));
}
处理前:[abcd, bc-dd, def-de, def-de]
处理后:[ABCD, BC-DD, DEF-DE, DEF-DE]
示例2:
@Test
public void flatmapPerson() {
List<String> list = Arrays.asList("abcd", "bc-dd", "def-de", "def-de");
Stream<String> stream = list.stream();
Stream<String> stringStream = stream.flatMap(s -> Arrays.stream(s.toUpperCase().split("-")));
System.out.println("处理前:" + list);
System.out.println("处理后:" + stringStream.collect(Collectors.toList()));
}
处理前:[abcd, bc-dd, def-de, def-de]
处理后:[ABCD, BC, DD, DEF, DE, DEF, DE]
示例3:
@Test
public void peekPerson() {
List<String> list = Arrays.asList("abcd", "bc-dd", "def-de", "def-de");
Stream<String> stream = list.stream();
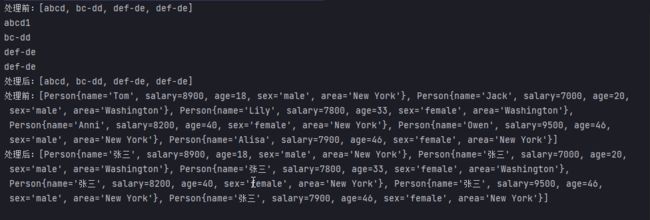
Stream<String> stringStream = stream.peek(s -> {
s = "abcd".equals(s) ? "abcd1" : s;
System.out.println(s);
});
System.out.println("处理前:" + list);
System.out.println("处理后:" + stringStream.collect(Collectors.toList()));
Stream<Person> personStream = personList.stream();
Stream<Person> personStreamnew= personStream.peek(s -> s.setName("张三"));
System.out.println("处理前:" + personList);
System.out.println("处理后:" + personStreamnew.collect(Collectors.toList()));
}
3.1.4 无序化
无序化(unordered):明确地对流进行去除有序约束可以改善某些有状态或终端操作的并行流的性能。
对于顺序流,顺序的存在与否不会影响性能,只影响确定性。如果流是顺序的,则在相同的源上重复执行相同的流管道将产生相同的结果;
如果是非顺序流,重复执行可能会产生不同的结果。 对于并行流,放宽排序约束有时可以实现更高效的执行。
在流有序时, 但用户不特别关心该顺序的情况下,使用
unordered明确地对流进行去除有序约束可以改善某些有状态或终端操作的并行性能。
3.2 有状态操作
3.2.1 排序
排序分为两种排序方式:
- sorted 自然排序,流中元素需实现Comparable接口
- sorted(Comparator com):Comparator排序器自定义排序
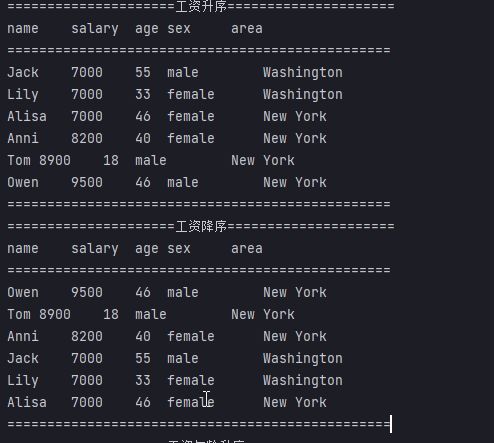
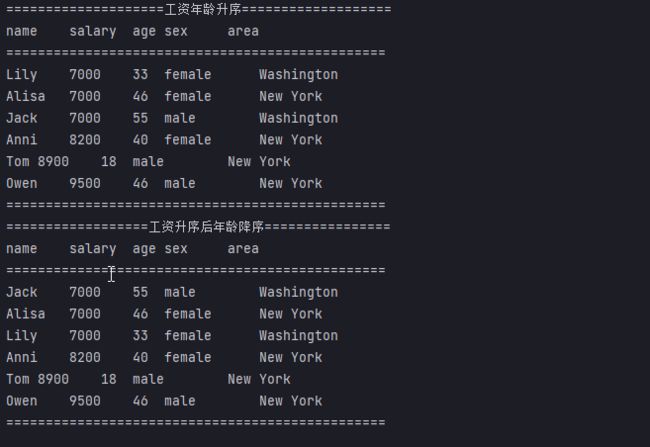
案例:将员工按工资由高到低(工资一样则按年龄由大到小)排序
-
sortedSalaryAgePerson.forEach(System.out::println);
System.out.println("================================================");
System.out.println("==================工资升序后年龄降序================");
System.out.printf("name" + "\t" + "salary" + "\t" + "age" + "\t" + "sex" + "\t\t" + "area" + "\t\n");
System.out.println("================================================");
sortedSalaryAscAgeDescPerson.forEach(System.out::println);
System.out.println("================================================");
}
3.2.2 提取/组合
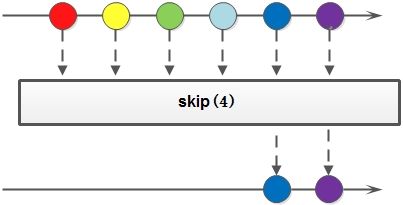
distinct()、limit()、skip()
distinct()使用hashCode()和equals()方法来获取不同的元素。因此,我们的类必须实现hashCode()和equals()方法。

distinct去重示例:
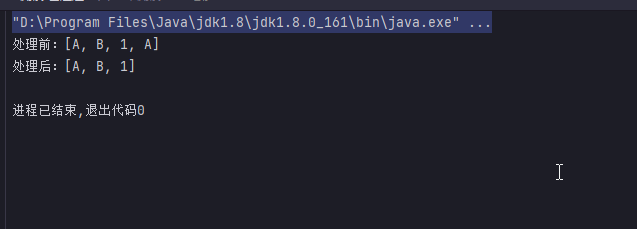
@Test
public void distinctStream(){
List<String> list = Arrays.asList("A", "B", "1", "A");
Stream<String> stream = list.stream();
Stream<String> stringStream = stream.distinct();
System.out.println("处理前:" + list);
System.out.println("处理后:" + stringStream.collect(Collectors.toList()));
}
使用disntinct处理对象流时,对象需要实现hashCode和equals方法才可使用。
@Override
public int hashCode() {
int result = 1;
result = 31 * result + (this.name == null ? 0 : this.name.hashCode());
result = 31 * result + (this.name == null ? 0 : this.salary);
result = 31 * result + (this.name == null ? 0 : this.age);
result = 31 * result + (this.name == null ? 0 : this.sex.hashCode());
result = 31 * result + (this.name == null ? 0 : this.area.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (obj == this)
return true;
if (!(obj instanceof Person))
return false;
Person p = (Person) obj;
return p.name.equals(this.name)
&& p.salary == this.salary
&& p.age == this.age
&& p.sex.equals(this.sex)
&& p.area.equals(this.area);
}
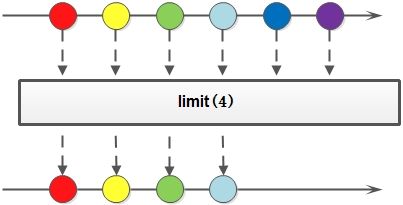
limit示例
@Test
public void limitStream() {
List<String> list = Arrays.asList("A", "B", "C", "D", "E", "F", "G", "H");
Stream<String> stream = list.stream();
Stream<String> stringStream = stream.limit(3);
System.out.println("处理前:" + list);
System.out.println("处理后:" + stringStream.collect(Collectors.toList()));
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a8zE9097-1654755792880)(C:/Users/git/AppData/Roaming/Typora/typora-user-images/image-20220530162847100.png)]
4.Stream的终端操作
4.1 短路操作
4.1.1 查找
-
findFirst:用于返回满足条件的第一个元素(但是该元素是封装在Optional类中)
-
findAny:返回流中的任意元素(但是该元素也是封装在Optional类中)
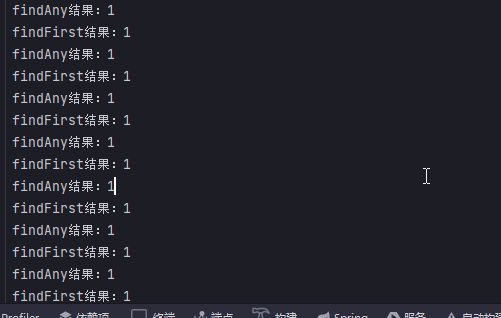
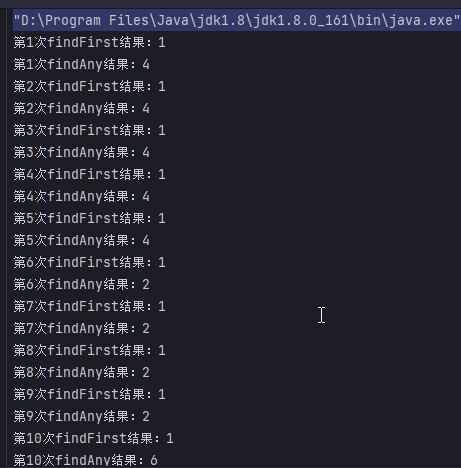
在Stream中,findFirst和findAny等同。
在并行流parallelStream中,findFirst会返回流中的第一个元素,findAny会随机返回一个元素。
@Test public void findStream() { List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5, 6); int i = 0; while (i < 20) { i++; Stream<Integer> stream = integerList.stream(); Optional<Integer> first = stream.findFirst(); Optional<Integer> any = integerList.stream().findAny(); System.out.println("findFirst结果:" + first.get()); System.out.println("findAny结果:" + any.get()); } } @Test public void findParallelStream() { List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5, 6); int i = 0; while (i < 20) { i++; Optional<Integer> first = integerList.parallelStream().findFirst(); Optional<Integer> any = integerList.parallelStream().findAny(); System.out.println("第" + i + "次findFirst结果:" + first.get()); System.out.println("第" + i + "次findAny结果:" + any.get()); } }
4.1.2 匹配
- anyMatch:Stream 中只要有一个元素符合传入的 predicate,返回 true
- allMatch:Stream 中全部元素符合传入的 predicate,返回 true
- noneMatch:Stream 中没有一个元素符合传入的 predicate,返回 true
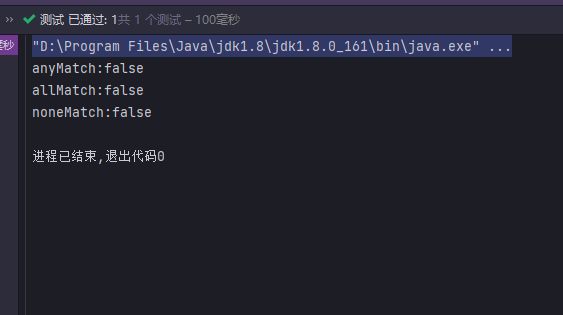
@Test
public void matchStream() {
Stream<Integer> stream = Stream.of(3, 1, 10, 16, 8, 4, 9);
System.out.println("anyMatch:" + stream.anyMatch(s -> s == 2));
stream = Stream.of(3, 1, 10, 16, 8, 4, 9);
System.out.println("allMatch:" + stream.allMatch(s -> s == 3));
stream = Stream.of(3, 1, 10, 16, 8, 4, 9);
System.out.println("noneMatch:" + stream.noneMatch(s -> s == 3));
}
4.2 非短路操作
4.2.1 遍历
- forEach:该方法接收一个Lambda表达式,然后在Stream的每一个元素上执行该表达式
- forEachOrdered:该方法接收一个Lambda表达式,然后按顺序在Stream的每一个元素上执行该表达式
两者基本可以等同,区别在forEachOrdered在Stream中实现顺序执行,但是在parallelStream两者等同,均无法实现顺序执行。
forEach是并行处理,而forEachOrdered顺序执行,因此forEach的速度更快
@Test
public void forEachSteam() {
System.out.println("forEach执行结果:");
Stream.of(3, 1, 10, 16, 8, 4, 9).forEach((s) -> System.out.print(s + " "));
System.out.println();
System.out.println("forEachOrdered执行结果:");
Stream.of(3, 1, 10, 16, 8, 4, 9).forEachOrdered((s) -> System.out.print(s + " "));
}
4.2.2 统计
- count:返回此流中的元素计数
- max:根据提供的Comparator返回此流的最大元素
- min:根据提供的Comparator返回此流的最小元素
@Test
public void countStream() {
long count = Stream.of(3, 1, 10, 16, 8, 4, 9).count();
System.out.println("count:"+count);
}
@Test
public void maxStream() {
Optional<Integer> max = Stream.of(3, 1, 10, 16, 8, 4, 9).max(Integer::compareTo);
System.out.println("max:" + max.get());
Optional<Person> person = personList.stream().max(Comparator.comparing(Person::getSalary));
System.out.println("maxPerson:" + person.get());
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YspwKOg3-1654755792886)(C:/Users/git/AppData/Roaming/Typora/typora-user-images/image-20220601163618869.png)]
@Test
public void minStream() {
Optional<Integer> min = Stream.of(3, 1, 10, 16, 8, 4, 9).min(Integer::compareTo);
System.out.println("min:" + min.get());
Optional<Person> person = personList.stream().min(Comparator.comparing(Person::getSalary));
System.out.println("minPerson:" + person.get());
}
4.2.3 集合
4.2.3.1 归集
因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。toList、toSet和toMap比较常用,另外还有toCollection、toConcurrentMap等复杂一些的用法。
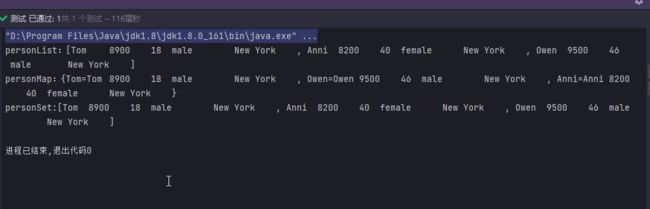
@Test
public void collectStream() {
List<Person> personLists = this.personList.stream().filter(p -> p.getSalary() > 8000).distinct().collect(Collectors.toList());
Set<Person> personSet = this.personList.stream().filter(p -> p.getSalary() > 8000).collect(Collectors.toSet());
Map<String, Person> personMap = this.personList.stream().filter(p -> p.getSalary() > 8000).distinct().collect(Collectors.toMap(p -> p.getName(), person -> person));
System.out.println("personList:" + personLists);
System.out.println("personMap:" + personMap);
System.out.println("personSet:" + personSet);
}
4.2.3.2 分组
-
分区(
partitioningBy):将stream按条件分为两个Map,比如员工按薪资是否高于8000分为两部分public static <T> Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) -
分组(
groupingBy):将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。public static <T, K> Collector<T, ?, Map<K, List<T>>> groupingBy(Function<? super T, ? extends K> classifier)
分区和分组的区别在于传入参数一个为断言Predicate和Function,因此partitionBy只能实现两个分组,而groupingBy可以实现多个分组。
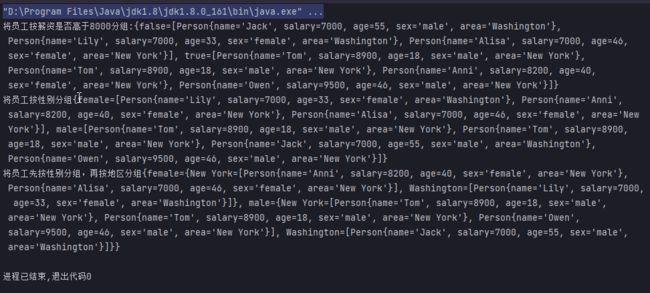
@Test
public void collectPartitioningByStream() {
// 将员工按薪资是否高于8000分组
Map<Boolean, List<Person>> salaryMap = personList.stream()
.collect(Collectors.partitioningBy(person -> person.salary > 8000));
// 将员工按性别分组
Map<String, List<Person>> sexMap = personList.stream().collect(Collectors.groupingBy(Person::getSex));
// 将员工先按性别分组,再按地区分组
Map<String, Map<String, List<Person>>> par =
personList.stream().collect(Collectors.groupingBy(Person::getSex,
Collectors.groupingBy(Person::getArea)));
System.out.println("将员工按薪资是否高于8000分组:" + salaryMap);
System.out.println("将员工按性别分组" + sexMap);
System.out.println("将员工先按性别分组,再按地区分组" + par);
}
4.2.3.3 统计
Collectors提供了一系列用于数据统计的静态方法:
- 计数:counting
- 平均值:averagingInt、averagingLong、averagingDouble
- 最值:maxBy、minBy
- 求和:summingInt、summingLong、summingDouble
- 统计以上所有:summarizingInt、summarizingLong、summarizingDouble
@Test
public void collectCountingStream() {
//统计总数
Long personnums = personList.stream().collect(Collectors.counting());
//平均工资
Double salaryavg = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
// 求最高工资的人
Optional<Person> collect = personList.stream().collect(Collectors
.maxBy(Comparator.comparing(Person::getSalary)));
// 求工资之和
Integer sum = personList.stream().collect(Collectors.summingInt(Person::getSalary));
// 一次性统计所有信息
DoubleSummaryStatistics summaryStatistics = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
System.out.println("员工总数:" + personnums);
System.out.println("员工平均工资:" + salaryavg);
System.out.println("员工最高工资的人" + collect.get());
System.out.println("员工工资总和:"+sum);
System.out.println("员工工资所有统计:"+summaryStatistics);
}
员工总数:7
员工平均工资:8071.428571428572
员工最高工资的人Person{name=‘Owen’, salary=9500, age=46, sex=‘male’, area=‘New York’}
员工工资总和:56500
员工工资所有统计:DoubleSummaryStatistics{count=7, sum=56500.000000, min=7000.000000, average=8071.428571, max=9500.000000}
4.2.3.4 接合
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
@Test
public void joiningStream() {
String collect = personList.stream().map(Person::getName).collect(Collectors.joining("----"));
System.out.println(collect);
}
Tom----Tom----Jack----Lily----Anni----Owen----Alisa
4.2.3.5 规约
4.2.4 规约
归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。
reduce提供了三个重载方法:
Optional<T> reduce(BinaryOperator<T> accumulator);
其中BinaryOperator的定义如下:
public interface BinaryOperator<T> extends BiFunction<T,T,T>
可以看出该对象继承了BiFunction(R apply(T t, U u);)传入两个同类型的值返回同一种数据类型的值。
第二个重载方法
T reduce(T identity, BinaryOperator<T> accumulator);
@Test
public void reduceStream() {
//求和方式1
Integer salarysum1 = personList.stream().collect(Collectors.summingInt(Person::getSalary));
//求和方式2
Optional<Integer> salarysum2 = personList.stream().map(Person::getSalary).reduce(Integer::sum);
//求和方式3
Integer salarysum3 = personList.stream().map(Person::getSalary).reduce(1, Integer::sum);//初始值为1会比正常结果大1
//求和方式4
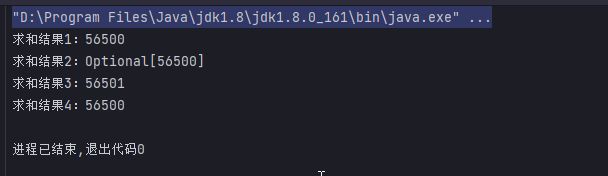
Integer salarysum4 = personList.stream().reduce(0, (sum, p) -> sum += p.getSalary(), (sum1, sum2) -> sum1 + sum2);
System.out.println("求和结果1:"+salarysum1);
System.out.println("求和结果2:"+salarysum2);
System.out.println("求和结果3:"+salarysum3);
System.out.println("求和结果4:"+salarysum4);
}
参考链接:
Java8 Stream:2万字20个实例,玩转集合的筛选、归约、分组、聚合_云深i不知处的博客-CSDN博客_java stream 聚合
【Java 8系列】Stream详解,看这一篇就够啦_善良勤劳勇敢而又聪明的老杨的博客-CSDN博客_stream