非专业人士对特斯拉人工智能日的专业解释 ——记@Cosmacelf在Reddit.com上对于AI Day的评价...
推荐| 焉知智能汽车
来源 | 车右智能([email protected])
=====================
Tesla AI Day过去三周了,余波未尽……小编想可能很大的原因是因为终于浮出水面的Dojo(和她的超级规格),另一部分是八字还未有一撇的AIBot吧?毕竟有型的、具象的存在,才容易引发群体感知和共鸣。但小编其实更看重的是另一部分,那部分存在于无形之中思想和理念,对于Tesla自身也好,对于AI共同的进步也罢,当Karpathy终于完整呈现给我们Tesla的感知能力奥义的时候,这才是AI2021最大的奥秘。
本文主要的内容和框架都来自于对于技术博主@Cosmacelf于8月26日发表在reddit.com上的一篇精彩的技术博文,结构紧凑但不遗漏技术重点,且通俗易懂。小编争取了Cosmacelf本人的同意,做了完整翻译,并在关键章节和段落部分给出了自己的观点和补充。原文的url如下:
https://www.reddit.com/r/teslamotors/comments/pcgz6d/laymans_explanation_of_tesla_ai_day/如果有读者感兴趣,可以移步至此观看@Cosmacelf的更多文章和精彩观点。
(dear cosmacelf, thanks for your supporting and selflesssharing your viewpoints and article with us, hope to see your more view infuture. The below black words are all from your article and the red ones are mycomments and supplements. Fyi)
=====================
这篇文章是我(指原作者Cosmacelf)试图解释在 Tesla AI Day上观察到的技术信息。
第 1 部分:概述
特斯拉的自动驾驶系统可以理解为“通用的”自动驾驶系统,其理论上可以处理任何地点的任何驾驶情况。这与福特、通用、梅赛德斯等许多其他依赖预定义高清地图和地理锁定自动驾驶区域的自动驾驶系统相反。实现通用驾驶能力的底层特斯拉自动驾驶系统,一方面通过其八个摄像头实时感知车辆四周的驾驶环境,另一方面Tesla的视觉信号处理以及控制系统使用基于反向传播训练的神经网络与复杂的C++编码算法相结合,一同构成车辆的信息处理和决策中心。
“基于反向传播训练的神经网络”与当今整个AI行业所使用的神经网络相同。它同样可以为Alexa和Siri等语音助手、Netflix的视频节目推荐以及Apple的面部识别技术提供支持。
这些神经网络(NN)与我们人类大脑的工作方式存在一些差异和相似之处。生产系统将使用数百万个标记好的示例来训练这样的神经网络,这些示例明确地告诉神经网络它应该从这些示例中学习什么。例如,视觉神经网络将被显示数百万张图像,每张图像还带有一个或多个标识图像中内容的标签。如果需要训练神经网络进行复杂的场景分析,人类标记员需要在画面中的每一个有价值的对象周围画线区隔,并识别每个绘制的多边形中的内容(类别)。
例如,在下图中,针对您所希望自动驾驶系统可以了解的,每一个对象分配了标签。比如车辆类别、交通基础设施类别、参与交通流量的其它物体和行人等等,

图一【Tesla AI Day-2.png】来自Cosmacelf在Reddit.com上的个人评论文章,URL
https://www.reddit.com/r/teslamotors/comments/pcgz6d/laymans_explanation_of_tesla_ai_day/;
一旦您拥有数百万张带有标签的图像数据,您就可以在这些数据上训练NN。训练是计算密集型的,通常在巨大的GPU集群上完成。在规模非常大的GPU集群上训练大型数据集往往需要几天时间,这并不罕见。
训练后,您现在拥有一个包含数百万个训练期间生成的内部参数的神经网络。然后,您可以将这个 NN 下载到一个通常要小得多的“推理处理器”上,并运行 NN 来进行场景分析或您想做的任何事情。在具有训练有素的神经网络的推理处理器上运行场景分析通常需要几分之一秒的时间。当然,特斯拉构建了自己独有的AI推理芯片,每辆车都有两个。
现在,当Elon Musk说每个使用 Autopilot 的人都在客观上帮助训练神经网络时,这只是部分正确。首先,您的特定汽车本身没有学习任何东西。它只能运行下载的阶段性训练完毕的神经网络来理解视觉场景。但它可以做的是在特斯拉要求时,按照要求的具体内容上传匹配需求的10秒长的视频快照。
例如,当特斯拉想要改进对高速公路上“切入”或汽车并入您车道的检测时,他们会编写一个查询,并让该查询在特斯拉车队中的每辆车中运行。每一辆特斯拉汽车的计算机都会在看到汽车驶入您的车道时触发这个查询动作,然后将这些10秒左右的剪辑上传到特斯拉数据中心。几天后,特斯拉就会有 10,000 段视频剪辑。这些剪辑是“自动标记的”,因为它们每个都天然包含了汽车在高速公路上被“切入/Cut-in”的场景视频。然后,特斯拉在这些带标签的视频剪辑上加强训练他们的神经网络。NN将自己主动从视频中挑选并学习表征Cut-in的各种线索,例如:对方车辆何时打开闪光灯,或者对方车辆何时开始漂移,或者它的角度发生微妙的变化等等。这就是神经网络的基本力量——有了标记数据,它即可以自动进行,无需(很多)通过人工编程带入人类已有的认知,完全靠NN自己的力量构建对于Cut-in行为的认知和预测图谱。
因此,在重新训练神经网络后,特斯拉将以影子模式(Shadow mode)将新神经网络部署到特斯拉车队中,并要求车队继续观察何时对于切入Cut-in的预测不正确。例如,要么没有预测到汽车会执行了切入/Cut-in操作,要么预测到被标记处的目标汽车会执行切入但实际上并没有发生。然后将这些异常数据再次上传到数据中心,并根据此异常数据重复训练新的神经网络。然后部署一个更新的 NN,并在影子模式下再次运行。这个循环会重复很多次,直到网络变得非常擅长预测切入操作,届时它最终会作为工作版本更新部署到整个舰队中去。
当特斯拉说它的庞大车队是它与其他所有人相比的秘密武器时,它并不是在吹嘘。特斯拉实际上拥有100万个以上的移动Tesla AI芯片可供其进行此类训练。从这些方面考虑,特斯拉拥有迄今为止地球上最大的人工智能超级计算机。
好的,以此为背景,让我们来看看 Tesla NN 的实际工作原理。
第 2 部分:视觉架构
下图显示了特斯拉视觉系统的整体架构。这仅用于感知,即理解您所看到的。下图并未包含驱动和控制子系统,随后我们将会讨论。
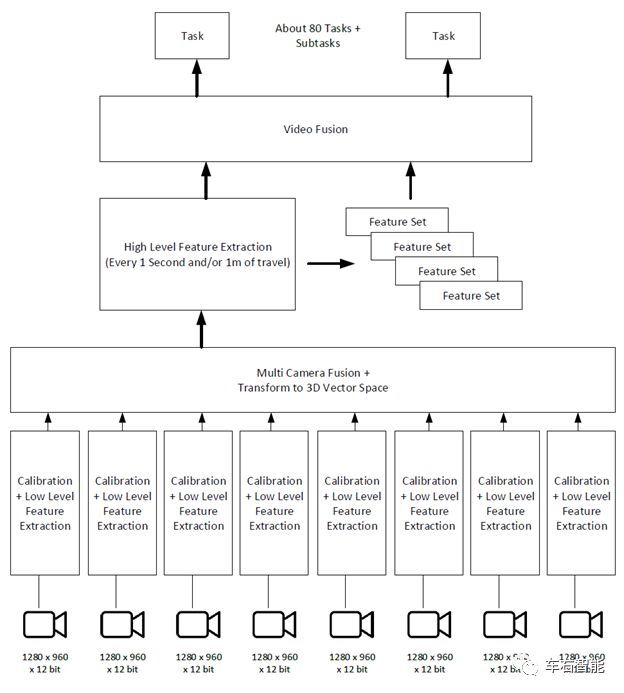
图二【Tesla AI Day-3.png】来自Cosmacelf在Reddit.com上的个人评论文章,URL
https://www.reddit.com/r/teslamotors/comments/pcgz6d/laymans_explanation_of_tesla_ai_day/;
这是非常high level的概要框架——这些框架中的每一个通常都包含几个到十几个神经网络,每个神经网络以各种复杂的方式连接。(小编:本次AI DAY应该最大的技术亮点还是Autopilot识别系统总监Karpathy基本上串讲了整个FSD系统的识别网络,没有藏着掖着地从头到尾过了一遍完整的系统框架和所涉及的具体技术。这样就基本联系起来从上次Tesla AI Day开始到现在的过去两年来,Karpathy所做出的各种技术演讲中所涉及的点点滴滴。Full picture在某种程度来说,对不是具体从事研发工作的技术爱好者来说,往往是更加重要的参考信息,对于我们理解Tesla这种典型的视觉自动驾驶系统来说,更重要也更直观。)
所有 8 台摄像机首先经过一个用于视觉系统校准的神经网络,该网络将每台摄像机所提供的视觉数据转换成一个“标准”图像,并保证该图像在特斯拉的整个机队中都应该是保持一致的。当您第一次购买汽车时,Autopilot 会进行为期数天的校准练习,它会训练车内神经网络去了解汽车中的每个摄像头是否偏离了基线(Basline)或者如何偏离了基线。每个摄像头都可能稍微扭曲,或者镜头指向太高的天空,或者其他什么方向,车辆需要了解这些要素与基线的偏差是什么,以便呈现给后台的 Autopilot 神经网络的图像与所有汽车的神经网络看起来保持一致. 这是唯一的真正的在汽车行驶过程中训练的神经网络。(小编:这个校准网络的部分在AI Day现场演讲时,顺序还给搞错了,Karpathy直到讲完Tesla使用Transformer网络用于图像融合并制造Birds-view视图后,才想起来Rectify network还没讲。但实际上如Cosmacelf在这里的顺序,相机的校准网络其实是整个识别过程的第一步。只有车身周边八个视像头的位置,在Tesla的整个车队中保持尽可能的一致性,才能让离线训练好的NN可以被顺利部署到每一辆车辆上并发挥正常功能。本质上讲,这里所谈到的“对于基线baseline”的偏离,实际上就是对于世界坐标对于相机坐标(所谓的外参)、再到相机坐标(所谓的内参)的转换规律要摸清楚,并且具备一定的自我调整能力。
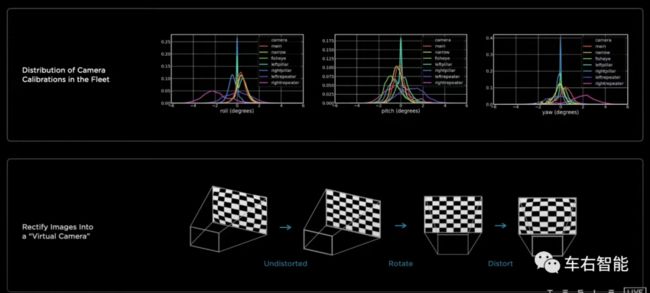
图三【Tesla AI Day-8.png】来自Tesla AI Day现场视频截图,URL
https://www.youtube.com/watch?v=j0z4FweCy4M&t=3749s;
Karpathy在演讲中给出了现行Tesla车队的摄像头基准数据,上图的上半部分,我们可以明显地看到,在俯仰、滚动和偏航三个方向上,车辆的肩部摄像机(pillar camera)即在中部A柱上的摄像头数据一致性最好,蓝色和绿色;而前向的主摄像头和远距离摄像头,以及Repeater camera两侧,表现出来的一致性表现不算特别好。小编的个人理解,应该是摄像头的安装位置,以及安装位置的车体强度和安装强度、刚度,都会影响到车身摄像头偏离基线baseline的程度。这意味着,在这些方向上的视觉数据的置信度相对偏低。但应该还是有办法纠正回来的,具体细节就不揣测了。)
一旦过了这个校准(变形)阶段,车辆的视觉系统功能将得到保证,后台的NN就会从源源不断地图像流中提取标准的低级特征,以减少或压缩大量图像数据,使其更易于管理,而不会丢失任何重要信息,并进入到后续的识别、预测和控制阶段。
下一步是将所有八个摄像机合并为一个视图,同时构建世界的 3D 向量空间表示。
根据2D平面图像创造3D向量空间表示,是我们的人类视觉皮层自动完成的工作,您甚至可能没有意识到自己正在这样做。当您查看这样的图像时:

图四【Tesla AI Day-4.png】来自Cosmacelf在Reddit.com上的个人评论文章,URL
https://www.reddit.com/r/teslamotors/comments/pcgz6d/laymans_explanation_of_tesla_ai_day/;
你立刻就会知道红色商店标志比那三辆车距离你更远,美国国旗和打开大灯的车距离差不多,都在那辆白色面包车的后面。Autopilot NN也必须解决这个问题,结果输出是一个3D世界模型,其关键特征位于该3D空间中。
Tesla 的 3D 矢量空间模型是一个相当密集的栅格,每个点都有一个距主车ego的距离测量值。它类似于激光雷达系统将生成的点云:

图五【Tesla AI Day-5.png】来自Cosmacelf在Reddit.com上的个人评论文章,URL
https://www.reddit.com/r/teslamotors/comments/pcgz6d/laymans_explanation_of_tesla_ai_day/;
Tesla的3D矢量空间内还增加了预测移动物体的速度、定位路缘、识别可行驶区域等,彩色并具有更高的分辨率。它也比 LIDAR 绘图复杂得多,因为它还可以制作包含被遮挡物体的3D图像——例如,当前位于汽车后面且在当前视频帧中看不到的行人。网络使用将在下面描述的基于内存的视频模块来跟踪这些被遮挡的对象。
请注意,特斯拉位于底层的低级NN视觉系统非常复杂。就像人类的大脑皮层一样,这些网络从层次结构的顶层到最低层共享信息。如下提供一个示例,您能找出10x10像素图像是什么嘛?(左侧)

图六【Tesla AI Day-6.png】来自Cosmacelf在Reddit.com上的个人评论文章,URL
https://www.reddit.com/r/teslamotors/comments/pcgz6d/laymans_explanation_of_tesla_ai_day/;
神经网络“知道”(已经从全局信息学习到全场景信息)10x10 的模糊像素位于右侧全景图像的道路消失点,因此它可以推断它们是汽车的前灯(小编:由此而判定这些模糊的光斑像素实际上很大概率代表一辆车辆实体)。
(小编:原文在Autopilot神经网络关于这一部分的介绍涉及比较少,实际上Karpathy还是介绍了不少相关内容,而且比较具体指出了在这一阶段Tesla所使用的神经网络类别,比如RegNet:
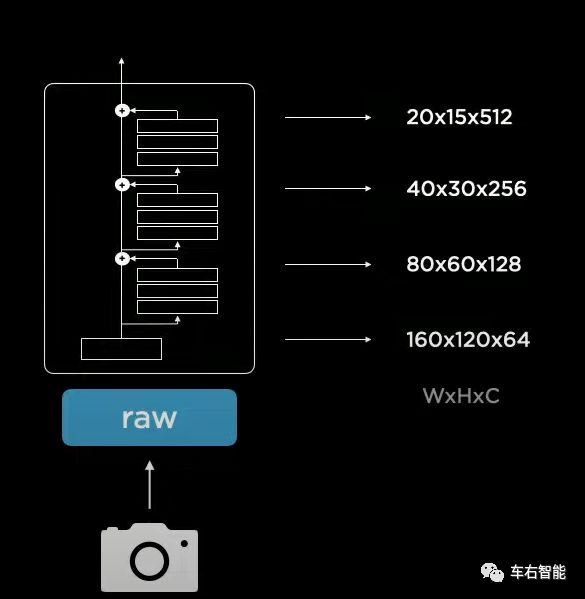
图七【Tesla AI Day-9.png】来自Tesla AI Day现场视频截图,URL
https://www.youtube.com/watch?v=j0z4FweCy4M&t=3749s;
在2019年的演讲中,Karpathy当时指出Autopilot的CNN网络backbone还是采用的ResNet-50的,但本次AI Day上明确下来的是最近冒出来的另一个CNN架构,RegNet。Karpathy给出的理由是RegNet更加简洁和有规则,可以在信息处理的复杂度和时延之间找到平衡。上图给出了RegNet的标准架构,Raw视觉数据被送入CNN主干网络之后,从底部到顶部,经历了从分别率越来越低和图像内上下文数据Channel越来越丰富的梯次变化过程,符合我们的直观感受,肯定是要从丰富细节的自然图像中捕捉到语义信息越来越强烈的目标信息,才是自动驾驶所需要的。
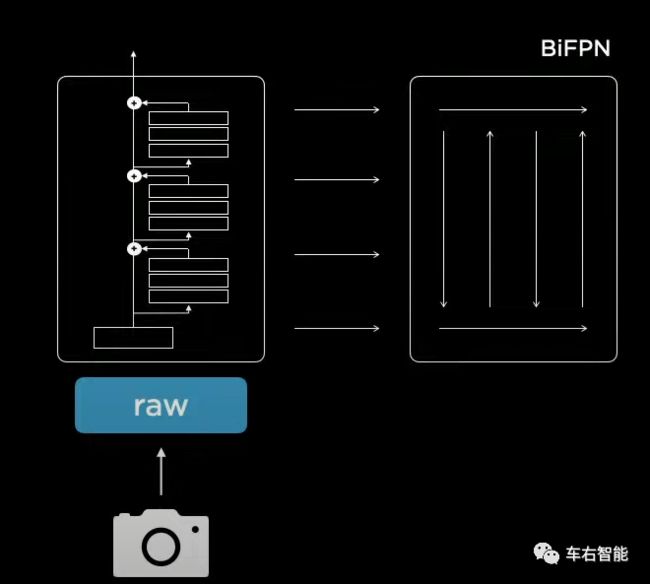
图八【Tesla AI Day-10.png】来自Tesla AI Day现场视频截图,URLhttps://www.youtube.com/watch?v=j0z4FweCy4M&t=3749s;
当然在这个feature信息提取的过程当中,梯次分布的各种视觉数据类型都是我们所需要的,从分别率到目标识别率,将这些信息一揽子送入BiFPN网络之后,Autopilot就可以从其中提出各种规模的feature组合信息。这样就回到了上面那个识别路面尽头模糊灯光的实际例子。正是这种RegNet+BiFPN的组合网络结构,确保了高可靠性的识别准确度。)
一旦进入创建了相机融合信息和3-D矢量空间的阶段,Tesla就会在内存中添加基于时间和位置的信息检索空间。他们举的例子是,当您驾驶车辆驶向十字路口时,您可能会根据导航需要调整车辆进入指示最左侧车道,那是标记有转弯车道的左转车道。

图九【Tesla AI Day-7.png】来自Cosmacelf在Reddit.com上的个人评论文章,URL
https://www.reddit.com/r/teslamotors/comments/pcgz6d/laymans_explanation_of_tesla_ai_day/;
当您到达十字路口时,经过左转车道标记往往已经过了几秒钟,因此当您经过这些特征时,车辆自动驾驶系统的识别模块需要对这些特征有某种记忆能力。视觉识别引擎将在每段时间内部比如1m为单位的旅行中,对它所看到的提取特征进行快照,并创建最近看到的视觉线索列表。同样,这与人类的驾驶方式非常相似——我们可能不会有意识地记得我们翻过左转标记,但我们自己的神经网络会这样做并使用该信息来指导我们的驾驶。
这个“视频模块”还用于跟踪被临时遮挡的对象。例如,当您在多车道高速公路上行驶时,两条车道上直接位于您左侧或右侧的汽车可能会被您旁边的汽车隐藏,但在汽车挡路前三秒钟就可以看到它们。视频模块允许神经网络记住这些汽车曾经和可能现在在哪里,而这些信息对于规划至关重要。
特斯拉在运行内存中增加的“视频模块video module”非常之强大,我不知道有任何其他自动驾驶系统可以执行此类操作。
最后,这个视频网络的输出是,当前的即时视觉场景和近期视觉线索的组合,并将其投影到 3D 向量空间内,然后被特斯拉称为“任务”的大约80个其他神经网络消耗。每个任务都做一个非常具体的事情,比如定位和理解交通信号灯,或者感知交通锥,或者看到停车标志,或者识别汽车及其速度等。这些任务的输出是高级语义信息,比如:在 30m 中,有一个红色的交通灯,或者我前面 30m 处的这辆车很可能在那里处于停车状态。(小编:基本上看,这就是视觉识别模块的全部,这篇文章在讨论Transformer和video module这两个模块上还是比较粗糙的,没有涉及过多细节。小编会在之后找专门的篇幅对其进行介绍。我们这次第一次看到的内容,其实就是这个整合摄像头信息进入3D的矢量空间,Tesla采用了Transformer技术,这是一个没有先例的亮点。其实我们从一贯的对于Tesla的观察来看,如果仅从识别功能出发,Karpathy确实做到了绞尽脑汁尝试不同的深度学习技术、模型来尝试各种可能,
图十【Tesla AI Day-11.png】来自Karpathy的个人推特,URL:
https://twitter.com/karpathy/status/1305302243449516032;
从去年开始,我们已经可以看到Karpathy在尝试评估和使用Transformer技术了。跨越NLP领域到Vision领域都有良好表现的Transformer,可以从图像本身像素之间的自注意力角度出发,采用了和CNN完全不同的思路来实现对于图像数据的分析,这是推动Tesla快速使用和部署Transformer上车的主要动力。小编也希望,经过Tesla fleet的数据洗礼,Transformer可以变得更好更强大。
后续我们再深度介绍这一部分网络。至此,不算具体的业务Head结构,这就是识别模块的全部堆栈了,还是相当优美和有力量的。我们都知道code2.0的具体含义,其实从Karpathy亲自操刀打造的Tesla识别模块中,我们可以淋漓尽致地看到code2.0的魅力和威力,对于程序员特别是新一代程序员来说,衡量水平的高低将转向另外一个战场,如何尽可能多地掌握越来越丰富的NN网络结构,甚至跨界(比如从vision跨界到NLP),如何能拿到更多有效数据,这都是全新的课题。所以Tesla是不怕公布整个识别模块的协议堆栈的,无所谓,因为真正的核心技术还是在于数据的处理、训练和参数如何调整这些细节上,NN的网络架构都是公开的,就好比code1.0中的各种函数已经被随着编程工具和各种库一同提供。

图十一【Tesla AI Day-12.png】来自Tesla AI Day现场视频截图,URLhttps://www.youtube.com/watch?v=j0z4FweCy4M&t=3749s;)
第 3 部分:计划和控制
截至到现在,神经网络已经可以了解所有经由视觉系统所捕获的:交通参与物体的位置、它们是什么、它们移动的速度和方向、路面是什么性质、路缘石在哪里、信号环境(交通、道路标志)是什么,以及最近发生了什么,现在自动驾驶必须做三件事:
首先,它必须预测所有其他移动物体在接下来的短时间内会做什么。其次,它必须根据整体计划(例如遵循GPS所定义的导航路线)来计划要做什么,第三,它必须告诉汽车要做什么。
这可能会变得非常复杂。让我们用一个简单的例子来解释一下,汽车在三车道道路的最右边车道,需要在中间车道上有汽车的情况下左转。为了正确地做到这一点,汽车必须在中间车道的两辆车之间并入,然后并入最左侧的车道,并且不要开得太快或太慢,或者加速或减速太多。
目前,特斯拉使用用C++编码的搜索算法来解决这个问题。它本质上模拟了数千种不同的场景,在这些场景中,汽车和道路上的其他汽车都相互作用。它在相当粗粒度的级别上执行此操作,并且他们给出的数字是模拟器/搜索系统可以在1.5毫秒内模拟/搜索 2,500 种不同的场景。所有这些模拟都使用基于物理的模型,这意味着它们是道路上汽车的理想化表示,道路也是以车道和分隔线等的简单道路表示。
在理想路径的选择阶段结束时,路径规划器对接下来15秒的行程有一个粗略的计划,并在此时创建一个非常详细的计划,准确地绘制出所需的特定转弯半径、行程路径和速度变化,以使得驾驶动作尽可能顺畅。这也是使用基于C++的搜索算法完成的,但使用了一种不同的技术,该技术考虑了横向加速度、横向冲击、碰撞风险、遍历时间,并将所有这些合并到一个总成本函数中,以最小化“总成本”为目标去细化规划路线。在演讲中,他们所展示的长度为10秒的驾驶规划平滑路径的示例,显示通过此搜索功能进行了大约 100 次迭代。
此规划功能以及之前的所有视觉感知系统,大约每27毫秒(即每秒36次)发生一次。因此,自动驾驶仪每秒感知并重新制定计划 36 次,以确保没有任何事情可以让汽车周围发生的任何奇怪的事情时汽车本身没有做好准备。Autopilot并非无所不知,无法判断您正在合并进入的道路上是否有白痴司机正在愤怒地发推特回复,但它可以更快地注意到所说的驾驶员的汽车,和正在发生碰撞的趋势,从而Autopilot会从而做出相应的反应。
特斯拉正在研究一种新的规划算法,该算法主要使用规划神经网络(所谓的code2.0方式),而不是目前所做的手工编码C++(code1.0方式)。NN算法的好处可能是速度更快,但它也可能提供一些更好的计划。
作为最难规划的场景之一,是在停车场周围或者内部导航(因为往往没有参考地图)。Tesla 展示了他们正在开发的NN规划器如何在比他们当前的规划器更短的时间内完成这项任务。
第 4 部分:训练
好的,我们已经讨论了各种特斯拉神经网络在感知世界时如何工作,并最终规划、驾驶它,但是你如何教授和训练神经网络呢?正如我在第1部分中所描述的,您需要为待训练的NN提供数百万个带标签的示例,以便它了解您要教它的内容。
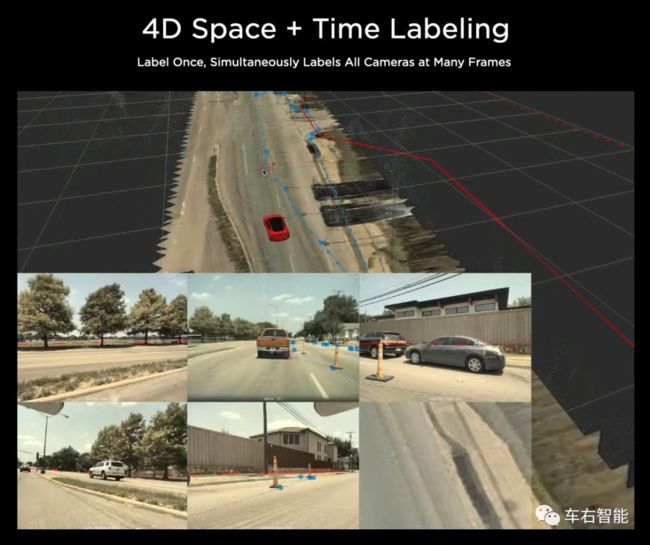
在最开始的阶段,特斯拉采用与行业内相同的方式进行此网络的训练操作,即让人类标注工作人员围绕所获取的海量图像中的特征,来绘制多边形(以便在结构上和语义上定义视觉目标)。这种操作方法并不具备规模扩展的能力和潜力。特斯拉很快就创建了在他们的可以在矢量空间vector space中标记的工具。如前所述,这是一个由 8 个摄像头拼接在一起的、并且转换为高阶语义所表述的外部世界的3D表示。在此vector space增强视图中标记路缘石,现在它会自动地在三个摄像头(也许更多)的相应视觉原始图像中自动标记指定目标(或者范围)。(小编:某种程度上讲,这是一种反向工具,其工作原理和识别模块当中的缝合+transformer工具相同,但是方向相反:
图十二【Tesla AI Day-13.png】来自Tesla AI Day现场视频截图,URL
https://www.youtube.com/watch?v=j0z4FweCy4M&t=3749s;
上图中我们可以看到,当在顶部的vector space空间中进行标记操作时,比如用线条勾勒出施工区域,同步地,你立刻可以在底部的多视角摄像头数据中同步观察到标记区域。本质上将这是一种“反向投影”的操作,但却是大大方便了标记人员,做到一次标记关键目标物体或者地理范围,同时在多视角视觉数据中生效,从而提升标记效率,做到了标记一次,可以生成多个标记video clip的效果。)
Tesla意识到他们庞大的车队可以在同一个十字路口行驶了数千次(这样的重叠场景一定非常频繁),因此如果通过使用 GPS 坐标标记十字路口,单个的矢量空间标记工作(由人类标记员完成)现在可以自动批量被标记在各种天气条件和一天中的各种时间拍摄的数千张图像和视角。所以,在3D矢量空间中,一旦你在vector space中确定知道一个红绿灯是红绿灯,那么成千上万次的未来驾驶通过同一个路口,从多个不同的方向,一天中的时间,天气和照明都可以自动将同一个红绿灯标记为红绿灯,而不需要更多的人力投入。(小编:这正是自动化精神的体现,在手动操作的基础上一步一步赋予越来越多的自动化要素,直到实现完全的自动化……

图十三【Tesla AI Day-14.png】来自Tesla AI Day现场视频截图,URL
https://www.youtube.com/watch?v=j0z4FweCy4M&t=3749s;
在上图中,不同的车辆在不同的时间段内行驶过同一个路口,拜GPS所赐,系统很容易明白这是同一个地理位置的路口。因此后台仿真系统可以将这16台车辆的16次对于同一路口的视觉信息分别捕捉,并在vector space向量空间内的俯视图中,对16张birds view矢量图进行拼接和重叠操作。我们可以将其理解为计算机视觉在矢量空间的投影+对齐,完成之后可以得到确定的vector space,并在其上进行人工标记,那些有价值的标记结果将会被反映到这参与投影和对齐操作的16辆车辆在不同时段和不同光照、不同气候条件下对于同一目标的视觉raw信息标记,同步地、几乎是瞬间地,Tesla接近实现自动化。
图十四【Tesla AI Day-15.png】来自Tesla AI Day现场视频截图,URL
https://www.youtube.com/watch?v=j0z4FweCy4M&t=3749s;
上图已经充分展示了这个所谓Birds view的矢量图的对齐过程,在对齐过程中显著的道路边界,即那些在经由transformer网络转换到矢量图中置信度最高的那些道路边界线条,将会被优先用于对齐的基准线;除此之外,显著的交通标识物体,比如车道线,也可以被用作对齐标线。
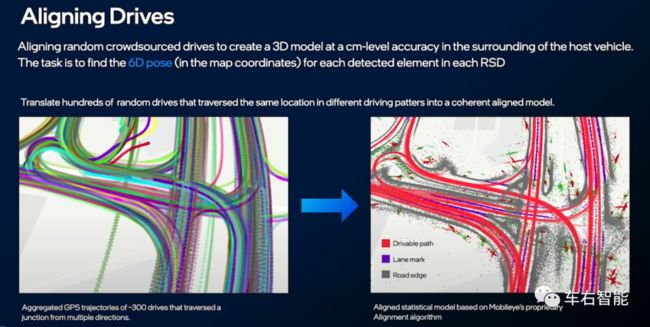
如果小编没有记错,年初Mobileye在CES2021上,Shashua教授也展示过类似的技术,如下二图:

图十五【Tesla AI Day-16.png】来自Mobileye CES2021演讲现场视频截图,URL
https://www.youtube.com/watch?v=B7YNj66GxRA&t=1745s;
图十六【Tesla AI Day-17.png】来自Mobileye CES2021演讲现场视频截图,URL
https://www.youtube.com/watch?v=B7YNj66GxRA&t=1745s;
Mobileye通过RSD(Road Segment Detect)技术在单车级别搜集交通道路设施的基本视觉信息,同样是纯视觉技术,同样是有一个到俯视图Birds view的转换。之后上传到服务器,据Mobileye说数据量非常小,一公里就是几十Kbps这个级别。离线的云端服务器在拿到大量类似数据之后,会找到地理位置相同的区域,然后在这个范围内进行多个车辆上报数据“Aligning Drives”的对齐操作。这个过程和Tesla在仿真中所提到的对齐操作基本是一致的。Shashua教授说这个操作的本质是,把每辆车上报的RSD数据,在标准的地图坐标系中,找到对应的6D位姿,即可完成对齐。小编相信这也各自是Mobileye和Tesla的核心技术之一,读者的注意力不要放在高精地图HDmap这个level之上,现在可以肯定的是,不论是Mobileye还是Tesla的自动驾驶系统,其设计目标都是不依赖全程全网的HDmap,对于高度依赖视觉系统的两家来说,这更类似一个AD map。)
在此之上,特斯拉又添加了全自动的自动标记功能。一辆汽车的AI芯片只能识别有限的数据,但1000个GPU的集群功能要强大得多,而且没有在实时驾驶过程中毫秒级的时间限制,所以这样的集群可以用来自动标记更多更新颖的场景图像。
特斯拉在2021年初用了3个月的努力,使用这种自动标记功能协助Autopilot移除了对于雷达的依赖。他们在移除雷达时遇到的首要问题是如何面对部分场景中视频数据质量下降的挑战。例如,当一辆路过的扫雪车将成吨的雪倾倒在汽车上时,一切都被遮挡了,这种严苛的局面下,纯视觉系统如何应对?特斯拉意识到他们需要对低能见度情况进行自动标记,从而低成本地获取大量类似极限场景的视觉标注数据。因此他们向庞大的特斯拉车队发出询问,关于汽车NN何时面临临时的零能见度的示例。他们在一周内自动标记了10,000个能见度低的视频数据(video clip),特斯拉说如果由人类标记来完成这项工作,至少需要几个月的时间。
在使用这批标记的低能见度视频重新训练视觉神经网络后,Autopilot系统终于能够记住并预测场景中的所有内容(在您经历临时低能见度时的场景),仿佛类似于人类处理此类情况的应对方式。(小编:其实很难界定的是,我们人类在面临低能见度的场景时,视觉和大脑是如何配合而克服这种极端状态的。以下图所示场景为例,能总结出来的,一个是要视觉上做到盯紧前向细节变化,另一个是需要大脑可以记住前方车辆在位置上处于消失-完全消失-半消失等临界状态时的关联关系,因为我们的世界知识体系告诉我们,前向车辆不论是否被浓雾、大雪所遮挡,其物理特性都不会允许它顺势加速或者瞬时减速,尤其是大型车辆,这是人类驾驶员在这种驾驶条件下敢于踩油门跟踪前进的勇气来源。

图十七【Tesla AI Day-18.png】来自Tesla AI Day现场视频截图,URL
https://www.youtube.com/watch?v=j0z4FweCy4M&t=3749s;
而我们目前看Tesla的视觉识别模块,基本在逻辑上可以模仿人类的思考方式和视觉观察方式。随着Tesla Vision技术的推广,在越来越大量数据的激励下,也许在某些特定的驾驶场景下,是可以逼近人类驾驶水准的。)
关于仿真
仿真,就像在详细的视频游戏中一样创建3D世界,是特斯拉开始主要用于边缘情况corner case构建的技术手段。特斯拉展示了在高速公路上奔跑的人或狗的例子(这种极端案例你在现实世界中捕捉到的次数会很有限,但它确实在构建自动驾驶系统的风险控制体系时有很有价值),有数百名行人的场景,或者一种前所未见的新型卡车(cybertruck!)。即使是自动的标记机制也很难处理数百名行人(因为数据量实在太大了),就像在香港或纽约一样,因此创建一个仿真平台,让系统准确了解每个人的位置以及他们的步行速度是更好的训练解决方案。(小编:创立仿真平台的人或者系统,本身可以在仿真的范围内扮演“上帝”角色,因此不存在标记难、遗漏等问题,如同下图:

图十八【Tesla AI Day-19.png】来自Tesla AI Day现场视频截图,URL
https://www.youtube.com/watch?v=j0z4FweCy4M&t=3749s;
我们可以看到在右下角的实例分割segmentation图中,我们甚至可以看到集卡车头的反光镜和排气管细节分割,这种准确的数据并非标记和实例分割网络的强大,而是仿真在生成这辆虚拟的集卡之前,就已经掌握这些所有的数据了。小编回忆起the Matrix骇客帝国第一集中,那个在虚拟的Matrix中创立红衣女郎的hacker。还有续集中的那个法国人,他在他创立的非法空间中,火车人的能量甚至比Neo还大,就是这个意思。)
特斯拉非常努力地进行准确的模拟。他们必须模仿相机在现实世界条件下看到的内容。照明和光线追踪必须非常准确。必须引入路面中的噪声,它们甚至有一个特殊的神经网络,用于向生成的图像添加噪声和纹理。
特斯拉现在在其模拟引擎中拥有数千种独特的车辆、行人、动物和道具。每一个动作或看起来都是真实的。他们还有2,000英里的非常多样化和独特的道路。当他们想要创建场景时,场景通常是通过计算机算法按程序创建的,而不是让艺术家创建场景。他们可以要求夜间、白天、下雨、下雪等。最后,因为他们可以自动构建他们想要的任何类型的视觉世界,他们现在可以使用对抗性机器学习技术,其中一个计算机系统试图创建一个会破坏汽车视觉感知系统的场景,然后这种破坏可用于更好地训练视觉系统,然后返回到闭环训练系统。(小编:其实仿真平台的技术设计感觉上和Autopilot视觉感知系统里的vector space的构建网络技术,没有本质区别。而Tesla构建这个能力并非按照明确的C++代码路线来实现的,而是大量借助了深度学习的NN路线。因此这个技术可以很容易在仿真和被仿真的两端同时得到部署和应用,只要训练得完善。

图十九【Tesla AI Day-20.png】来自Tesla AI Day现场视频截图,URL
https://www.youtube.com/watch?v=j0z4FweCy4M&t=3749s;
比如在上图中的场景重构技术,在这个pipeline中从左到右,其本质和transformer在autopilot识别模块中构建适量空间的方法并无二至。但迁移到仿真平台上,就可以发挥全新的场景合成和构建作用。)
说特斯拉通过仿真技术构建的学习pipeline是更上一层楼是轻描淡写。它现在非常复杂,完全可以说是世界上最强大的。
关于Dojo
DoJo是特斯拉的下一代训练数据中心。现在,他们“凑合”使用了数千个当前最先进的 Nvidia A100 GPU集群在一起。特斯拉认为他们可以做得更好,所以他们定制了自己的人工智能训练芯片(不要与每辆特斯拉汽车内的人工智能推理芯片混淆)。训练芯片的功能要强大得多,它被设计成作为一个巨大的超级计算机集群的一部分工作。
我不会对DoJo说太多,但AI Day上的信息披露足以说明它在封装、冷却、电源集成和巨大的通信带宽(很容易是当前功能的10倍)等诸多方面都是世界一流的。Dojo仍在构建中,我猜它距离在生产环境中使用还有4-6个月的时间。当它开始被使用时,特斯拉的生产力将会提高——他们基本上能够做得更多、更快。
第 5 部分:未来工作和结论
通过观看此视频和过去两年的其他特斯拉AI视频,您可以看出特斯拉一直在全力开发可工作的FSD视觉系统。当特斯拉发布他们的 v10 FSD Beta 时(仅几周之后,大概是九月底),这将是一个很棒的系统,但特斯拉仍然正在进行很多优化,这些优化将在明年左右推出。以下是他们谈到的一部分:
您可能已经注意到,Karpathy说特斯拉的视觉系统在处理过程中,直到很晚的阶段才合并了所有八个摄像头所提供的数据内容。Tesla考虑可以在管道的早期阶段即执行此合并操作,从而可能节省大量的处理时间。(小编理解就是尽早将raw data转化为特征内容的vector space)
Tesla现有的视觉系统生成相当密集的3D世界栅格(Raster)。然后,视觉数据处理系统的其余部分(如那些80多个子任务的Head结构)则必须解释此信息栅格。特斯拉正在探索产生更多基于对象的简单世界表征的方法(可以理解为尽可能降低信息密度但不失真),这将更容易后续的处理识别任务。顺便说一句,这是那些听起来很容易但实际上却极具挑战性的问题之一。
如前所述,特斯拉正在开发一种神经网络规划器planner networks,它将显着减少路径规划计算时间。
他们的核心车载神经网络NN使用高精度浮点数,但有机会使用低精度浮点数,并且在某些情况下可能会一直下降到8位整数计算。(小编感觉Tesla对于其完全视觉化的Tesla Vision系统,现在真是处在极度自信的阶段。在所有的竞争对手都在靠堆叠硬件传感器规格和数量及后台处理能力的时候,Tesla却在思考如何降低负荷和数据通量,包括处理硬件资源和对于数据的要求,逆风而动。)
这些只是一些正在研究的广泛领域。毫无疑问,每个单独的神经网络和一段代码都可以使用一些优化的关怀和爱(原文是Nodoubt each individual NN and piece of code could use some optimization care andlove. 小编也没明白具体含义)。
结论
所有这些话,我只是提供给你一个关于特斯拉人工智能日展示内容的概要性总结。特斯拉真的打开了他们的和服(原文是open theirkimono,意思是指真诚地交流而不隐藏任何信息)并露出真实面目了,比我这里技术层面上所写的东西要详细得多。实际上,您实际上必须是AI研究人员或程序员才能真正理解所说的一切。
公司根本不会向公众提供这样的深入技术路线图。显然,特斯拉是在试图招募人工智能研究人员,但即便如此,暴露如此多的架构也是真正的冒险之举。潜台词是,特斯拉不在乎你是否试图复制它们,因为当你重新创造一切的时候,它们会更进一步。(小编:在code2.0时代,你永远写不出比NN架构更好的功能。这不是我说的,“Gradient descent can write code better than you,I’m sorry。”by karpathy。Tesla敢于开放自己的NN网络整体框架的底气来自于此。)
最重要的是,在我看来,特斯拉确实可以通过这种架构实现全自动驾驶。“何时”总是很难预测,但似乎所有部分都已就位,当然我们已经看到了一些令人印象深刻的FSD测试视频。
备注:
1 封面插图来自于互联网,参考URL:
https://vnexplorer.net/?#tesla-ai-day-how-to-watch-elon-musks-latest-event-er2021622295.html;
