SpringBoot 整合 Neo4j,图数据库 YYDS!
前一段时间,boss 交给我个任务,让我调研一下知识图谱技术。虽说有点 NLP 的底子,不过研究起这个来还是满头的包,终于还是在搜集了不少资料后划拉出来 50 多页的 PPT。
今天先浅浅的给大家分享一下知识图谱的相关知识,再带着大家实战一下 Neo4j,讲讲如何在 Spring Boot 项目中实现并呈现这张雷神中复杂的人物关系图谱。

知识图谱技术
概述
诞生
知识图谱的概念诞生于 2012 年,由谷歌公司首先提出。大家都知道,谷歌是做搜索引擎的,所以他们最早提出了Google Knowledge Graph后,首先利用知识图谱技术改善了搜索引擎核心。
注意上面的说法,虽然知识图谱诞生于 2012 年,但其实在更早的时间它还有另外一个名字,那就是语义。那么语义又是什么呢?引用《统计自然语言处理基础》中的两句话来解答这个问题:
语义可以分成两部分,研究单个词的语义(即词义)以及单个词的含义是怎么联合起来组成句子(或者更大的单位)的含义。
语义研究的是词语的含义、结构和说话的方式。
那么,知识图谱究竟是个什么东西呢?
你可以将它理解为是在自然界建立实体关系的知识数据库,它的提出是为了准确地阐述人、事、物之间的关系。
目前在学术界还没有给知识图谱一个统一的定义,但是在谷歌发布的文档中有明确的描述:“知识图谱是一种用图模型来描述知识和建模世界万物之间关联关系的技术方法”。
演进
谷歌的 Singhal 博士用三个词点出了知识图谱加入之后搜索发生的变化:
“Things,not string.”
这寥寥的几个单词,点出了知识图谱的核心。以前的搜索,都是将要搜索的内容看作字符串,结果是和字符串进行匹配,将匹配程度高的排在前面,后面按照匹配度依次显示。而利用知识图谱之后,将搜索的内容不再看作字符串,而是看作客观世界的事物,也就是一个个的个体。
举个例子,当我们在搜索比尔盖茨的时候,搜索引擎不是搜索“比尔盖茨”这个字符串,而是搜索比尔盖茨这个人,围绕比尔盖茨这个人,展示与他相关的人和事。

图片
在上面的图中,左侧百科会把比尔盖茨的主要情况列举出来,右侧显示比尔盖茨的微软产品和与他类似的人,主要是一些 IT 行业的创始人。这样,一个搜索结果页面就把和比尔盖茨的基本情况和他的主要关系都列出来了,搜索的人很容易找到自己感兴趣的结果。
三要素
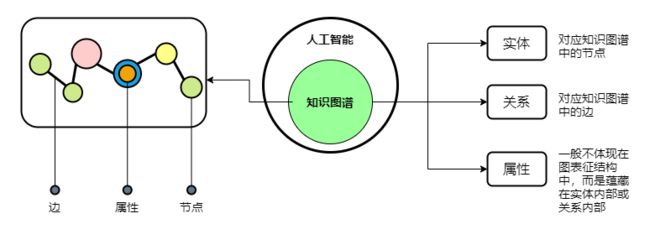
在知识图谱中,通过三元组 <实体 × 关系 × 属性> 集合的形式来描述事物之间的关系:
-
实体:又叫作本体,指客观存在并可相互区别的事物,可以是具体的人、事、物,也可以是抽象的概念或联系,实体是知识图谱中最基本的元素
-
关系:在知识图谱中,边表示知识图谱中的关系,用来表示不同实体间的某种联系
-
属性:知识图谱中的实体和关系都可以有各自的属性
这里所说的实体和普通意义上的实体略有不同,借用 NLP 中本体的概念来理解它会比较好:
本体定义了组成主题领域的词汇表的基本术语及其关系,以及结合这些术语和关系来定义词汇表外延的规则。
例如我们要描述大学这一领域时,对它来说教工、学生、课程就是相对比较重要的概念,并且教工和学生之间也存在一定的关联关系,此外对象之间还存在一定的约束关系,例如一个系的教职员工数量不能少于 10 人。
在了解了上面的三元组后,我们可以基于它构建下面这样的一个关系:

可以看到,女王和王储通过母子关系关联在一起,并且每个人拥有自己的属性。
当知识图谱中的节点逐渐增多后,它的表现形式就会类似于化学分子式的结构,一个知识图谱往往存在多种类型的实体与关系。
知识图谱将非线性世界中的知识信息进行加工,做到这样的结构化、可视化,从而辅助人类进行推理、预判、归类。
到这里,可以简单概括一下知识图谱的基本特征:
-
知识结构网络化
-
网络结构复杂
-
网络由三元组构成
-
数据主要由知识库承载
场景
搜索
前面提到过,以前的搜索引擎是从海量的关键词中找出与查询匹配度最高的内容,按照查询结果把排序分值最高的一些结果返回给用户。在整个过程中,搜索引擎可能并不需要知道用户输入的是什么,因为系统不具备推理能力,在精准搜索方面也略显不足。而基于知识图谱的搜索引擎,除了能够直接回答用户的问题外,还具有一定的语义推理能力,大大提高了搜索的精确度。
推荐
在传统的推荐系统中,存在两个典型问题:
-
数据稀疏问题:在实际应用场景中,用户和物品的交互信息往往是非常稀疏的,预测会产生过拟合风险
-
冷启动问题:对于新加入的用户或者物品,由于系统没有其历史交互信息,因此无法进行准确地建模和推荐
例如,在一个电影类网站中可能包含了上万部电影,然而一个用户打过分的电影可能平均只有几十部。使用如此少量的已观测数据来预测大量的未知信息,会极大地增加算法的过拟合风险。
因此在推荐算法中会额外引入一些辅助信息作为输入,这些辅助信息可以丰富对用户和物品的描述,从而有效地弥补交互信息的稀疏或缺失。在各种辅助信息中,知识图谱作为一种新兴类型的辅助信息,这几年的相关研究比较多。
下面就是一个基于知识图谱的推荐例子:

在将知识图谱引入推荐系统后,具有以下优势:
-
精确性:知识图谱为物品引入了更多的语义关系,可以深层次地发现用户兴趣
-
多样性:知识图谱提供了实体之间不同的关系连接种类,有利于推荐结果的发散,避免推荐结果局限于单一类型
-
可解释性:知识图谱可以连接用户的历史记录和推荐结果,从而提高用户对推荐结果的满意度和接受度,增强用户对推荐系统的信
此外,知识图谱技术还在问答与对话系统、语言理解、决策分析等多个领域被广泛应用,它被挂载在这些系统之后,充当背景知识库的角色。总的来说,在这些场景下的应用,可以概括整个 AI 的发展趋势,就是从感知到认知的一个过程。
架构
知识图谱的构建目前已有一套比较完善的架构体系,可以先来看一下下面这张图,然后我们再慢慢解释:

总的来说,整体过程可以分为下面 5 步:
-
1.数据获取:主要获取半结构化数据,为后续的实体与实体属性构建做准备。结构化数据则为数值属性做准备
-
2.知识获取:从文本数据集中自动识别出命名实体,包括抽取人名、地名、机构名等;从语料中抽取实体之间的关系,形成关系网络;从不同的信息源中采集特定的属性信息
-
3.知识融合:完成指示代词与先行词的合并;完成同一实体的歧义消除;将已识别的实体对象,无歧义地指向知识库中的目标实体
-
4.知识加工:构建知识概念模块,抽取本体;进行知识图谱推理,并对知识图谱的可信度进行量化评估,评估过关的知识图谱流入知识图谱库中存储,评估不过关的知识图谱返回一开始的数据环节进行调整,而后重复相同环节直到评估过关
-
5.知识存储与计算:存储是为了快速查询与运用知识,需支持底层数据描述与上层计算,有的主体计算包含在存储中
下面,我们拆解其中部分重要核心细节,来具体描述。
知识获取
数据是知识图谱的根基,直接关系到知识图谱构建的效率和质量。所以我们先从数据源进行分析它们的优势与劣势:
-
站内数据:优势在于类别明确,结构化好,易于获取;而劣势在于类型有限,已有数据并不是广义上的知识类型
-
垂直网站数据:优势在于类别明确;而劣势在于获取解析成本高,数据质量参差不齐
-
百科类网站数据:优势在于数据量大,内容丰富;而劣势在于没有分类信息,结构不完全固定
-
人工创建的数据:优势在于类别明确;而劣势在于类别明确
实体抽取
实体抽取,是指从数据中识别和抽取实体的属性与关系信息,这一过程还是针对不同结构的数据来看:
-
结构化数据:包括站内/垂直网站信息、部分百科网站信息,可以利用策略模式,将抽取的具体规则用 groovy 脚本来实现
-
半结构化数据:包括百科网站中的表格以及列表,可以利用基于监督学习的包装器归纳方法进行抽取
-
非结构化数据:包括百科网站中的文本以及站内文本,可以利用自然语言处理的手段处理
关系抽取
回顾一下我们前面提到过的知识图谱三要素,分别是实体、关系和属性。关系抽取我们同样可以用一个三元组表示的RDF graph:

这样的一个(S,P,O)三元组,就可以将一份知识分解为主语、谓语、宾语。这样的 SPO 结构,在配合知识图谱进行存储时可以被用来当做存储单元。
在 RDF 中可以声明一些规则,从一些关系推导出另一些关系,这些规则被称为RDF Schema。规则可以用一些词汇表示,如class、subClassOf、type、property、subPropertyOf、domain、range等。
下面这个例子中,节点到节点之间的关系就可以理解为前面提到的本体中的联系,而这一关联过程就可以被称为知识图谱中的推导或关联推理:

图片
知识融合
知识融合这一过程中,主要包括指代消解、实体对齐、实体链接等过程,我们主要来看一下这个过程中比较重要的实体对齐(Object Alignment)。
完成实体抽取后,存在实体 ID 不同但代表真实世界中同一对象的情况。知识融合即是将这些实体合并成一个具有全局唯一标识的实体对象,添加到知识图谱中。
-
首先在索引中根据名字、别名等字段查询出若干个可能是相同实体的候选列表,这个步骤的目的是减少接下来流程的计算量
-
然后经过实体判别模型,根据模型得分识别出待合并对齐的原始实体
-
最后经过属性融合模型,将各原始实体的属性字段进行融合,生成最终的实体。
这一过程可以用下面的图来表示:

实际上,这个流程中的合并判断模型大家都比较熟悉,它就是通过机器学习训练生成的二分类器。
知识图谱构建与补全
知识图谱普遍存在不完备的问题,在这一步需要做的,就是基于图谱里已有的关系,去推理出缺失的关系。
在下面的这张知识图谱的实体网络中,黄色的箭头表示已经存在的关系,红色的虚线则是缺失的关系。我们可以根据实体之间的关系,来补全缺失的 e3 到 e4 之间的关系。
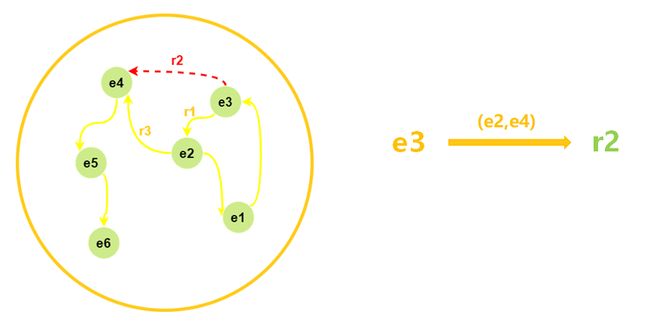
至于这一补全的过程,有很多现成的算法可以使用,例如基于路径查找的方法,基于强化学习的方法,基于推理规则的方法,基于元学习的方法等等。
知识存储
知识图谱的存储依赖于图数据库及其引擎,不同厂商的实现可能大有不同,例如可以选用的图数据库有 RDF4j、Virtuoso、Neo4j 等。例如爱奇艺的图数据库引擎选择了 JanusGraph,借助云平台的 Hbase 和 ES 集群,搭建了自己的 JanusGraph 分布式图数据库引擎。

图片
JanusGraph 通过借助外部的存储系统与外部索引系统的支持,支撑了上游的在线查询服务。
补充
底层存储数据三元组的逻辑层次可以被称为数据层,通常通过本体库来管理数据层,本体库的概念相当于对象中“类”的概念。而建立在数据层之上的模式层,是知识图谱的核心,它借助本体库来管理公理、规则和约束条件,规范实体、关系、属性这些具体对象间的关系。
从不同的视角去审视知识图谱,可以更方便我们对其进行了解:
-
在 Web 视角下,知识图谱如同简单文本之间的超链接一样,通过建立数据之间的语义链接,支持语义搜索
-
在自然语言处理视角下,知识图谱就是从文本中抽取语义和结构化的数据
-
在知识表示视角下,知识图谱是采用计算机符号表示和处理知识的方法
-
在人工智能视角下,知识图谱是利用知识库来辅助理解人类语言的工具
-
在数据库视角下,知识图谱是利用图的方式去存储知识的方法
下面,就是一张构建完备后,比较易于我们理解的知识图谱举例:

看到这里,是不是感觉知识图谱的构建过程比较复杂,让我们难于上手?
其实近些年来,深度学习和相关自然语言处理技术的迅猛发展使得非结构化数据的自动知识抽取少人化、乃至无人化成为了可能,现在已经提出了一些前沿的知识图谱自动构建技术。
在深度学习的基础上,艾伦人工智能实验室和微软的研究人员结合自然语言处理领域较为成功的预训练语言模型,提出了自动知识图谱构建模型 COMET(COMmonsEnse Transformers)。
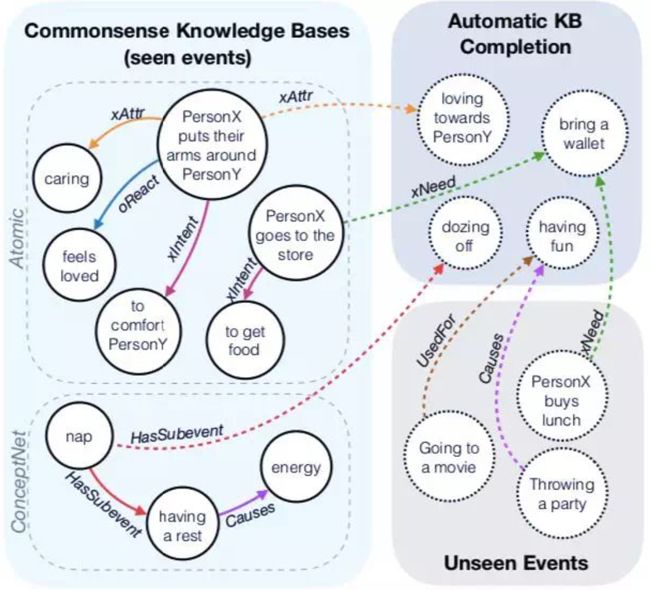
该模型可以根据已有常识库中的自然语言内容自动生成丰富多样的常识描述,在 Atomic 和 ConcepNet 两个经典常识图谱上都取得了接近人类表现的高精度,证明了此类方法在常识知识图谱自动构建和补全方面替代传统方法的可行性。
难点
数据治理困难
数据治理为知识图谱输送数据源,是知识图谱构建的前置环节与基础性工程。完备良好的数据治理不仅能确保知识图谱在搭建过程中获取真实可靠的数据原料,而且能从源头上改善信息质量,提升知识的准确度,建立符合人类认知体系的数据资源池。
但是,数据治理在知识图谱建设卡点中是一个老生常谈的问题。知识图谱应用始终要围绕数据标签、数据清洗、数据归一、数据销毁等数据治理环节展开,应用开发人员往往需要在前期的数据治理工作中投入大量时间和人力,以确保数据源的真实性、可靠性、可用性、正确性。
当前,数据标准不统一、数据噪声大、领域数据集缺失、数据可信度异常等数据治理难题依然困扰着知识图谱研发者,持续进行数据治理工程是业内参与者艰巨的使命与职责。
专家缺乏
目前知识图谱行业整体处于开发资源待完善的局面,行业与技术专家资源稀缺属于其中的一部分情况。
一方面,缺少具备深厚行业经验的专家。由于行业知识图谱与行业的关联度高,开发人员需要迅速了解业务与客户需求,在行业专家的指导下完成 Schema 构建,若涉及到文本抽取工作还需要行业专家进行数据标注,而各行各业中的行业专家往往仅有极少数。对此,供给方企业需要锁定行业业务的强项领域、提前招募培养行业专家、进行内外协作,以完成行业专家储备。
另一方面,缺少技术复合型专家。整个知识图谱应用生产流程不仅涉及知识图谱算法,生产流程的靠前环节还涉及到底层的图数据存储与数据治理、NLP 文本抽取和语义转换,同时各环节都渗透着机器学习这一底层人工智能技术。这意味着整个生产流程需要多个技术领域的工程师协同合作,而对整套技术均有了解的技术专家数量稀缺。
底层存储
由于知识图谱是二维链接的图结构而非行或列的表结构,其需以图数据的形式描述并存储,该方式能直接反应知识图谱的内部结构,有利于知识查询,结合图计算算法进行知识的深度挖掘与推理。
满足这一存储要求的数据库为近几年兴起的图数据库。相比于传统的关系型数据库,图数据库的数据模型以节点和边来体现,可大大缩短关联关系的查询执行时间,支持半结构化数据存储,展示多维度的关联关系。高效便捷的新技术往往意味着更高的研发门槛。
流程与算法
在知识图谱的搭建过程中,仍然面临着各类算法难点,主要难点可归结为生产流程中的算法难点和算法性能上的难点。前者体现为知识获取受数据集限制、知识融合干扰因素较多、知识计算的数据集与算力不足等问题。
而后者体现为算法泛化能力不足、鲁棒性不足、缺乏统一测评指标等问题。算法上的难点有赖于供需双方、学术界、政府持续攻坚,而非一方努力即可收获成功。
Neo4j 实战
我们上面介绍了关于知识图谱的一些基本理论知识,俗话说的好,光说不练假把式。
下面将通过下面几个主要模块,构建自然界中实体间的联系,实现知识图谱描述:
-
图数据库 Neo4j 安装
-
简单 CQL 入门
-
Spring Boot 整合 Neo4j
-
文本 SPO 抽取
-
动态构建知识图谱
Neo4j 安装
知识图谱的底层依赖于关键的图数据库,在这里我们选择 Neo4j,它是一款高性能的 nosql 图形数据库,能够将结构化的数据存储在图而不是表中。
首先进行安装,打开官网下载 Neo4j 的安装包,下载免费的 community 社区版就可以,地址放在下面:
https://Neo4j.com/download/other-releases/

需要注意的是,Neo4j 4.x 以上的版本都需要依赖 jdk11 环境,所以如果运行环境是 jdk8 的话,那么还是老老实实下载 3.x 版本就行,下载解压完成后,在bin目录下通过命令启动:
Neo4j console
启动后在浏览器访问安装服务器的 7474 端口,就可以打开 Neo4j 的控制台页面:

通过左侧的导航栏,我们依次可以查看存储的数据、一些基础查询的示例以及一些帮助说明。
而顶部带有$符号的输入框,可以用来输入 Neo4j 特有的 CQL 查询语句并执行,具体的语法我们放在下面介绍。
简单 CQL 入门
就像我们平常使用关系型数据库中的 SQL 语句一样,Neo4j 中可以使用 Cypher 查询语言(CQL)进行图形数据库的查询,我们简单来看一下增删改查的用法。
添加节点
在 CQL 中,可以通过CREATE命令去创建一个节点,创建不含有属性节点的语法如下:
CREATE (:)
在CREATE语句中,包含两个基础元素,节点名称node-name和标签名称lable-name。标签名称相当于关系型数据库中的表名,而节点名称则代指这一条数据。
以下面的CREATE语句为例,就相当于在Person这张表中创建一条没有属性的空数据。
CREATE (索尔:Person)
而创建包含属性的节点时,可以在标签名称后面追加一个描绘属性的json字符串:
CREATE (
:
{
:,
…
:
}
)
用下面的语句创建一个包含属性的节点:
CREATE (洛基:Person {name:"洛基",title:"诡计之神"})
查询节点
在创建完节点后,我们就可以使用MATCH匹配命令查询已存在的节点及属性的数据,命令的格式如下:
MATCH (:)
通常,MATCH命令在后面配合RETURN、DELETE等命令使用,执行具体的返回或删除等操作。
执行下面的命令:
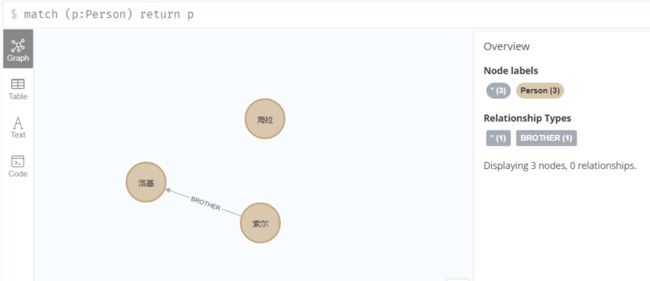
MATCH (p:Person) RETURN p
查看可视化的显示结果:

可以看到上面添加的两个节点,分别是不包含属性的空节点和包含属性的节点,并且所有节点会有一个默认生成的id作为唯一标识。
删除节点
接下来,我们删除之前创建的不包含属性的无用节点,上面提到过,需要使用MATCH配合DELETE进行删除。
MATCH (p:Person) WHERE id(p)=100
DELETE p
在这条删除语句中,额外使用了WHERE过滤条件,它与 SQL 中的WHERE非常相似,命令中通过节点的id进行了过滤。
删除完成后,再次执行查询操作,可以看到只保留了洛基这一个节点:

添加关联
在 Neo4j 图数据库中,遵循属性图模型来存储和管理数据,也就是说我们可以维护节点之间的关系。
在上面,我们创建过一个节点,所以还需要再创建一个节点作为关系的两端:
CREATE (p:Person {name:"索尔",title:"雷神"})
创建关系的基本语法如下:
CREATE (:)
- [:]
-> (:)
当然,也可以利用已经存在的节点创建关系,下面我们借助MATCH先进行查询,再将结果进行关联,创建两个节点之间的关联关系:
MATCH (m:Person),(n:Person)
WHERE m.name='索尔' and n.name='洛基'
CREATE (m)-[r:BROTHER {relation:"无血缘兄弟"}]->(n)
RETURN r
添加完成后,可以通过关系查询符合条件的节点及关系:
MATCH (m:Person)-[re:BROTHER]->(n:Person)
RETURN m,re,n
可以看到两者之间已经添加了关联:

需要注意的是,如果节点被添加了关联关系后,单纯删除节点的话会报错,:
Neo.ClientError.Schema.ConstraintValidationFailed
Cannot delete node<85>, because it still has relationships. To delete this node, you must first delete its relationships.
这时,需要在删除节点时同时删除关联关系:
MATCH (m:Person)-[r:BROTHER]->(n:Person)
DELETE m,r
执行上面的语句,就会在删除节点的同时,删除它所包含的关联关系了。
那么,简单的 cql 语句入门到此为止,它已经基本能够满足我们的简单业务场景了,下面我们开始在 springboot 中整合 Neo4j。
SpringBoot 整合 Neo4j
创建一个 springboot 项目,这里使用的是2.3.4版本,引入 Neo4j 的依赖坐标:
org.springframework.boot
spring-boot-starter-data-Neo4j
在application.yml中配置 Neo4j 连接信息:
spring:
data:
Neo4j:
uri: bolt://127.0.0.1:7687
username: Neo4j
password: 123456
大家如果对jpa的应用非常熟练的话,那么接下来的过程可以说是轻车熟路,因为它们基本上是一个模式,同样是构建 model 层、repository 层,然后在此基础上操作自定义或模板方法就可以了。
节点实体
我们可以使用基于注解的实体映射来描述图中的节点,通过在实体类上添加@NodeEntity表明它是图中的一个节点实体,在属性上添加@Property代表它是节点中的具体属性。
@Data
@NodeEntity(label = "Person")
public class Node {
@Id
@GeneratedValue
private Long id;
@Property(name = "name")
private String name;
@Property(name = "title")
private String title;
}
这样一个实体类,就代表它创建的实例节点的Person,并且每个节点拥有name和title两个属性。
Repository 持久层
对上面的实体构建持久层接口,继承Neo4jRepository接口,并在接口上添加@Repository注解即可。
@Repository
public interface NodeRepository extends Neo4jRepository {
@Query("MATCH p=(n:Person) RETURN p")
List selectAll();
@Query("MATCH(p:Person{name:{name}}) return p")
Node findByName(String name);
}
在接口中添加了个两个方法,供后面测试使用,selectAll()用于返回全部数据,findByName()用于根据name查询特定的节点。
接下来,在 service 层中调用 repository 层的模板方法:
@Service
@AllArgsConstructor
public class NodeServiceImpl implements NodeService {
private final NodeRepository nodeRepository;
@Override
public Node save(Node node) {
Node save = nodeRepository.save(node);
return save;
}
}
前端调用save()接口,添加一个节点后,再到控制台用查询语句进行查询,可以看到新的节点已经通过接口方式被添加到了图中:
在 service 中再添加一个方法,用于查询全部节点,直接调用我们在NodeRepository中定义的selectAll()方法:
@Override
public List getAll() {
List nodes = nodeRepository.selectAll();
nodes.forEach(System.out::println);
return nodes;
}
在控制台打印了查询结果:

图片
对节点的操作我们就介绍到这里,接下来开始构建节点间的关联关系。
关联关系
在 Neo4j 中,关联关系其实也可以看做一种特殊的实体,所以可以用实体类来对其进行描述。与节点不同,需要在类上添加@RelationshipEntity注解,并通过@StartNode和@EndNode指定关联关系的开始和结束节点。
@Data
@RelationshipEntity(type = "Relation")
public class Relation {
@Id
@GeneratedValue
private Long id;
@StartNode
private Node startNode;
@EndNode
private Node endNode;
@Property
private String relation;
}
同样,接下来也为它创建一个持久层的接口:
@Repository
public interface RelationRepository extends Neo4jRepository {
@Query("MATCH p=(n:Person)-[r:Relation]->(m:Person) " +
"WHERE id(n)={startNode} and id(m)={endNode} and r.relation={relation}" +
"RETURN p")
List findRelation(@Param("startNode") Node startNode,
@Param("endNode") Node endNode,
@Param("relation") String relation);
}
在接口中自定义了一个根据起始节点、结束节点以及关联内容查询关联关系的方法,我们会在后面用到。
创建关联
在 service 层中,创建提供一个根据节点名称构建关联关系的方法:
@Override
public void bind(String name1, String name2, String relationName) {
Node start = nodeRepository.findByName(name1);
Node end = nodeRepository.findByName(name2);
Relation relation =new Relation();
relation.setStartNode(start);
relation.setEndNode(end);
relation.setRelation(relationName);
relationRepository.save(relation);
}
通过接口调用这个方法,绑定海拉和索尔之间的关系后,查询结果:

文本 SPO 抽取
在项目中构建知识图谱时,很大一部分场景是基于非结构化的数据,而不是由我们手动输入确定图谱中的节点或关系。因此,我们需要基于文本进行知识抽取的能力,简单来说就是要在一段文本中抽取出 SPO 主谓宾三元组,来构成图谱中的点和边。
这里我们借助 Git 上一个现成的工具类,来进行文本的语义分析和 SPO 三元组的抽取工作,项目地址:
https://github.com/hankcs/MainPartExtractor
这个项目虽然比较简单一共就两个类两个资源文件,但其中的工具类却能够有效帮助我们完成句子中的主谓宾的提取,使用它前需要先引入依赖的坐标:
com.hankcs
hanlp
portable-1.2.4
edu.stanford.nlp
stanford-parser
3.3.1
然后把这个项目中com.hankcs.nlp.lex包下的两个类拷到我们的项目中,把resources下的models目录拷贝到我们的resources下。
完成上面的步骤后,调用MainPartExtractor工具类中的方法,进行一下简单的文本 SPO 抽取测试:
public void mpTest(){
String[] testCaseArray = {
"我一直很喜欢你",
"你被我喜欢",
"美丽又善良的你被卑微的我深深的喜欢着……",
"小米公司主要生产智能手机",
"他送给了我一份礼物",
"这类算法在有限的一段时间内终止",
"如果大海能够带走我的哀愁",
"天青色等烟雨,而我在等你",
"我昨天看见了一个非常可爱的小孩"
};
for (String testCase : testCaseArray) {
MainPart mp = MainPartExtractor.getMainPart(testCase);
System.out.printf("%s %s %s \n",
GraphUtil.getNodeValue(mp.getSubject()),
GraphUtil.getNodeValue(mp.getPredicate()),
GraphUtil.getNodeValue(mp.getObject()));
}
}
在处理结果MainPart中,比较重要的是其中的subject、predicate和object三个属性,它们的类型是TreeGraphNode,封装了句子的主谓宾语成分。下面我们看一下测试结果:

可以看到,如果句子中有明确的主谓宾语,那么则会进行抽取。如果某一项为空,则该项为null,其余句子结构也能够正常抽取。
动态构建知识图谱
在上面的基础上,我们就可以在项目中动态构建知识图谱了,新建一个TextAnalysisServiceImpl,其中实现两个关键方法。
首先是根据句子中抽取的主语或宾语在 Neo4j 中创建节点的方法,这里根据节点的name判断是否为已存在的节点,如果存在则直接返回,不存在则添加:
private Node addNode(TreeGraphNode treeGraphNode){
String nodeName = GraphUtil.getNodeValue(treeGraphNode);
Node existNode = nodeRepository.findByName(nodeName);
if (Objects.nonNull(existNode))
return existNode;
Node node =new Node();
node.setName(nodeName);
return nodeRepository.save(node);
}
然后是核心方法,说白了也很简单,参数传进来一个句子作为文本先进行 spo 的抽取,对实体进行Node的保存,再查看是否已经存在同名的关系,如果不存在则创建关联关系,存在的话则不重复创建。下面是关键代码:
@Override
public List parseAndBind(String sentence) {
MainPart mp = MainPartExtractor.getMainPart(sentence);
TreeGraphNode subject = mp.getSubject(); //主语
TreeGraphNode predicate = mp.getPredicate();//谓语
TreeGraphNode object = mp.getObject(); //宾语
if (Objects.isNull(subject) || Objects.isNull(object))
return null;
Node startNode = addNode(subject);
Node endNode = addNode(object);
String relationName = GraphUtil.getNodeValue(predicate);//关系词
List oldRelation = relationRepository
.findRelation(startNode, endNode,relationName);
if (!oldRelation.isEmpty())
return oldRelation;
Relation botRelation=new Relation();
botRelation.setStartNode(startNode);
botRelation.setEndNode(endNode);
botRelation.setRelation(relationName);
Relation relation = relationRepository.save(botRelation);
return Arrays.asList(relation);
}
创建一个简单的 controller 接口,用于接收文本:
@GetMapping("parse")
public List parse(String sentence) {
return textAnalysisService.parseAndBind(sentence);
}
接下来,我们从前端传入下面几个句子文本进行测试:
海拉又被称为死亡女神
死亡女神捏碎了雷神之锤
雷神之锤属于索尔
调用完成后,我们再来看看 Neo4j 中的图形关系,可以看到海拉、死亡女神、索尔、锤这些实体被关联在了一起:

到这里,一个简单的文本处理和图谱创建的流程就被完整的串了起来,但是这个流程还是比较粗糙,之后还需要在下面几个方面继续优化:
-
当前使用的还是单一类型的节点和关联关系,后续可以在代码中丰富更多类型的节点和关联关系实体类
-
文中使用的文本 spo 抽取效果一般,如果应用于企业项目,那么建议基于更精确的 nlp 算法去做语义分析
-
当前抽取的节点只包含了实体的名称,不包含具体的属性,后续需要继续完善补充实体的属性
-
完善知识融合,主要是添加实体的指代消解以及属性的融合功能
总之,需要完善的部分还有不少,项目代码我也传到 git 上了,大家如果有兴趣可以看看,后续如果有时间的话我也会基于这个版本继续改进。