目标检测算法——YOLOv5/YOLOv7改进之结合Criss-Cross Attention

(一)前沿介绍
论文题目:CCNet: Criss-Cross Attention for Semantic Segmentation
论文地址:https://arxiv.org/pdf/1811.11721.pdf
代码地址:https://github.com/shanglianlm0525/CvPytorch

本文是ICCV2019的语义分割领域的文章,旨在解决long-range dependencies问题,提出了基于十字交叉注意力机制(Criss-Cross Attention)的模块,利用更少的内存,只需要11x less GPU内存,并且相比non-local block更高的计算效率,减少了85%的FLOPs。最后,该模型在Cityscaoes测试集达到了81.4%mIOU,在ADE20K验证集达到了45.22%mIOU。
作者提出一种十字交叉的网络CCNet更有效地获得重要的信息。具体来说,CCNet能够通过一个新的交叉注意模块获取其周围像素在十字交叉路径上的上下文信息。通过这样反复的操作,每个像素最终能够从所有的像素中捕获long-range依赖。总体上CCNet有以下贡献:
(1)节省GPU内存。与非局部模块non-local相比,循环十字交叉注意模块能够节省11倍的GPU内存占用;
(2)更高的计算性能。循环交叉注意力模块在计算Long-range依赖时能够减少85% non-local FLOPs;
(3)在语义分割数据集Cityscapes和ADE20K和实例分割数据集COCO上取得了先进性能。
1.Criss-Cross结构图
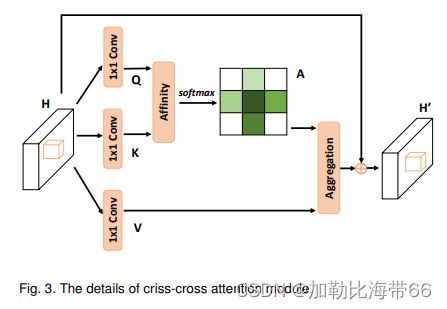
2.相关实验结果

(二)YOLOv5/YOLOv7改进之结合Criss-Cross Attention
改进方法和其他注意力机制一样,分三步走:
1.配置common.py文件
加入Criss-Cross代码。
#CrissCross——————————————————————————————————————————————————————————
def INF(B, H, W):
return -torch.diag(torch.tensor(float("inf")).repeat(H), 0).unsqueeze(0).repeat(B*W, 1, 1)
class CrissCross(nn.Module):
def __init__(self, in_dim):
super(CrissCross, self).__init__()
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x)
proj_query_H = proj_query.permute(0, 3, 1, 2).contiguous().view(m_batchsize*width, -1, height).permute(0, 2, 1)
proj_query_W = proj_query.permute(0, 2, 1, 3).contiguous().view(m_batchsize*height, -1, width).permute(0, 2, 1)
proj_key = self.key_conv(x)
proj_key_H = proj_key.permute(0, 3, 1, 2).contiguous().view(m_batchsize*width, -1, height)
proj_key_W = proj_key.permute(0, 2, 1, 3).contiguous().view(m_batchsize*height, -1, width)
proj_value = self.value_conv(x)
proj_value_H = proj_value.permute(0, 3, 1, 2).contiguous().view(m_batchsize*width, -1, height)
proj_value_W = proj_value.permute(0, 2, 1, 3).contiguous().view(m_batchsize*height, -1, width)
energy_H = (torch.bmm(proj_query_H, proj_key_H)+self.INF(m_batchsize, height, width)).view(m_batchsize, width, height, height).permute(0, 2, 1, 3)
energy_W = (torch.bmm(proj_query_W, proj_key_W)).view(m_batchsize, height, width, width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:,:,:,0:height].permute(0, 2, 1, 3).contiguous().view(m_batchsize*width, height, height)
att_W = concate[:,:,:,height:height+width].contiguous().view(m_batchsize*height, width, width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize, width, -1, height).permute(0, 2, 3, 1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize, height, -1, width).permute(0, 2, 1, 3)
return self.gamma*(out_H + out_W) + x2.配置yolo.py文件
加入Criss-Cross模块。
#CrissCross
elif m is CrissCross:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, *args[1:]]3.配置yolov5_CrissCross.yaml文件
添加方法灵活多变,Backbone或者Neck都可。示例如下:
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
[-1, 1, CrissCross, [1024]], #10
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 6], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 8], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]