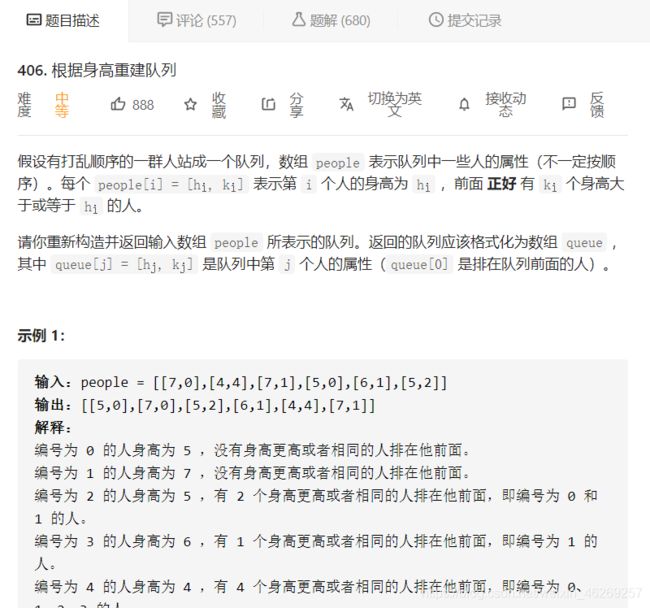
根据身高重建队列
思路
本题有两个维度,h和k,看到这种题目一定要想如何确定一个维度,然后在按照另一个维度重新排列。
其实如果大家认真做了贪心算法:分发糖果,就会发现和此题有点点的像。
在贪心算法:分发糖果的时候说过遇到两个维度权衡的时候,一定要先确定一个维度,再确定另一个维度。
「如果两个维度一起考虑一定会顾此失彼」。
对于本题令人困惑的点是先确定k还是先确定h呢,也就是究竟先按h排序呢,还先按照k排序呢?
如果按照k来从小到大排序,排完之后,会发现k的排列并不符合条件,身高也不符合条件,两个维度哪一个都没确定下来。
那么按照身高h来排序呢,身高一定是从大到小排(身高相同的话则k小的站前面),让高个子在前面。
「此时我们可以确定一个维度了,就是身高,前面的节点一定都比本节点高!」
那么只需要按照k为下标重新插入队列就可以了,为什么呢?
以图中{5,2} 为例:

按照身高排序之后,优先按身高高的people的k来插入,后序插入节点也不会影响前面已经插入的节点,最终按照k的规则完成了队列。
所以在按照身高从大到小排序后:
「局部最优:优先按身高高的people的k来插入。插入操作过后的people满足队列属性」
「全局最优:最后都做完插入操作,整个队列满足题目队列属性」
局部最优可推出全局最优,找不出反例,那就试试贪心。
回归本题,整个插入过程如下:
排序完的people:
[[7,0], [7,1], [6,1], [5,0], [5,2],[4,4]]
插入的过程:插入[7,0]:[[7,0]]
插入[7,1]:[[7,0],[7,1]]
插入[6,1]:[[7,0],[6,1],[7,1]]
插入[5,0]:[[5,0],[7,0],[6,1],[7,1]]
插入[5,2]:[[5,0],[7,0],[5,2],[6,1],[7,1]]
插入[4,4]:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
此时就按照题目的要求完成了重新排列。
时间复杂度O(nlogn + n^3)
空间复杂度O(n)
class Solution {
public:
static bool cmp(vector<int> a,vector<int> b){
if(a[0]==b[0]) return a[1]<b[1]; //身高相同的,返回下标小的,升序排列
else return a[0]>b[0];//否则按身高降序排列
//要点看比较符号<表明要升序排列,>表示要降序排列
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort(people.begin(),people.end(),cmp);
vector<vector<int>> que;
for(int ii=0;ii<people.size();ii++){
int position=people[ii][1];
que.insert(que.begin()+position,people[ii]);
}
return que;
}
};
n^3 是怎么来的?
数组中插入元素和删除元素都是O(n^2)的复杂度。
我们就是要模拟一个插入队列的行为,所以不应该使用数组,而是要使用链表!
链表的插入操作复杂度是O(n):寻找插入元素位置O(n),插入元素O(1)。
可以看出使用链表的插入效率要比普通数组高出一个数量级!
// 版本二
时间复杂度O(nlogn + n^2)
空间复杂度O(n)
class Solution {
public:
// 身高从大到小排(身高相同k小的站前面)
static bool cmp(const vector<int> a, const vector<int> b) {
if (a[0] == b[0]) return a[1] < b[1];
return a[0] > b[0];
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort (people.begin(), people.end(), cmp);
list<vector<int>> que; // list底层是链表实现,插入效率比vector高的多
for (int i = 0; i < people.size(); i++) {
int position = people[i][1]; // 插入到下标为position的位置
std::list<vector<int>>::iterator it = que.begin();
while (position--) { // 寻找在插入位置
it++;
}
que.insert(it, people[i]);
}
return vector<vector<int>>(que.begin(), que.end());
}
};
总结
关于出现两个维度一起考虑的情况,我们已经做过两道题目了,另一道就是贪心算法:分发糖果。
「其技巧都是确定一边然后贪心另一边,两边一起考虑,就会顾此失彼」。
这道题目可以说比贪心算法:分发糖果难不少,其贪心的策略也是比较巧妙。
最后我给出了两个版本的代码,可以明显看是使用C++中的list(底层链表实现)比vector(数组)效率高得多。
「对使用某一种语言容器的使用,特性的选择都会不同程度上影响效率」。