Flink简述
- 简单介绍一下Flink?相比较传统的Spark Streaming 区别?
1、简单介绍一下Flink?
Flink是一个框架和分布式处理引擎,用于处理有界和无界的数据流进行有状态计算,flink还提供了数据分布、容错机制和资源管理等核心功能。
- Flink VS Spark
数据处理架构:
Spark是批处理,即使是处理实时数据,在Spark中的说法的微批处理。
Flink 是流处理,处理批数据声明为有界数据流,流处理是处理无界数据流。
运行时架构:
Spark是批计算,将DAG划分成不同的stage,一个完成之后才能计算下一个。
Flink是标准的流执行模式,一个事件在一个节点处理后直接发往下一个节点进行处理
时间机制:
Spark只支持处理时间。
Flink支持事件时间、处理时间、注入时间,同时也支持watermark机制来处理滞后的数据。
- Flink的组件栈有哪些?各自的作用?公司的flink集群规模多大?
Flink分层架构,从上到下一次层:API&Libraries、RunTime核心层和物理部署层
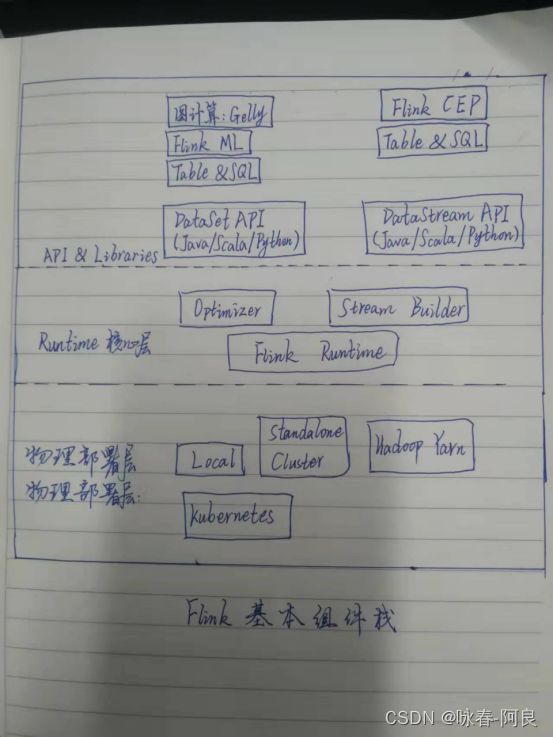
Deploy 层:该层主要涉及了Flink的部署模式,在上图中我们可以看出,Flink 支持包括local、Standalone、Cluster、Cloud等多种部署模式。
Runtime 层:Runtime层提供了支持 Flink 计算的核心实现,比如:支持分布式 Stream 处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
API层:API 层主要实现了面向流(Stream)处理和批(Batch)处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API,后续版本,Flink有计划将DataStream和DataSet API进行统一。
Libraries层:该层称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)。
Flink集群有哪些角色?各自有什么作用?
Flink集群一共有三个角色:JobManager,TaskManager,Client
- JobManager:扮演着集群中的管理者Master的角色,它是整个集群的协调者,主要作用有以下几点:负责接收Flink Job,调度Job协调checkpoint Failover(挂掉、失败)故障恢复 管理Flink集群中从结点TaskManager,与TaskManager通信。
- TaskManager:是实际负责执行计算的Worker,在其上执行Flink Job 的一组Task,每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源状态向JobManager汇报。
- Client:是Flink程序提交的客户端,当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所有Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。
简述Flink watermark机制 又称为水位线
Watermark本质就是一个时间戳。 实际上就是原有窗口的结束时间上在多等待一个最大允许的数据延迟时间或者是乱序时间,一旦有事件时间在这个多等待的时间刻度线后的消息时间到达就会立刻触发窗口计算。
理解:设置的水位线(watermark)其实就是时间戳,watermark的时间语义是:事件时间(是每个事件在产生它的设备上发生的时间),用来处理迟到数据
SingleOutputStreamOperatorwatermarks = shop.assignTimestampsAndWatermarks(WatermarkStrategy . forMonotonousTimestamps().withTimestampAssigner( new SerializableTimestampAssigner () { @Override public long extractTimestamp(DWD_Cart shopping, long l) { return shopping.getAddTime(); } }));
TopN案列
package com.cart_zhibiao;
import com.alibaba.fastjson.JSON;
import com.base.MQBaseETL;
import com.utils.KafkaUtil;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.Comparator;
// TODO: 每个省商品的top3
public class TopNCart {
public static void main(String[] args) throws Exception {
// TODO: 准备环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO: 设置并行度为1
environment.setParallelism( 1 );
// TODO: 设置检察点
// environment.enableCheckpointing(5000L);
// environment.setStateBackend(new FsStateBackend("hdfs://hadoop101:8020/checkpoint/baselogApp"));
// TODO: 从kafka中获取数据
MQBaseETL baseEtl = new MQBaseETL();
DataStream addsource = baseEtl.KafkaConsummer("dwd_cart", environment);
// TODO: 转换格式
// SingleOutputStreamOperator shop1 = addsource.map(new MapFunction() {
// @Override
// public DWD_Cart map(String s) throws Exception {
// DWD_Cart shopping = JSON.parseObject(s, DWD_Cart.class);
// return shopping;
// }
// });
// shop1.print();
//数据过滤
SingleOutputStreamOperator shop = addsource.flatMap( new FlatMapFunction() {
@Override
public void flatMap(String s, Collector collector) throws Exception {
DWD_Cart shopping = JSON.parseObject(s, DWD_Cart.class);
if (shopping.getClientProvince() != null && !shopping.getClientProvince().equals("")) {
collector.collect(shopping);
}
}
});
// TODO: 设置水位线
//TODO: 设置生成watermark的时间间隔,系统默认为200毫秒,一般使用系统默认即可
SingleOutputStreamOperator watermarks = shop.assignTimestampsAndWatermarks(WatermarkStrategy
.forMonotonousTimestamps().withTimestampAssigner( new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(DWD_Cart shopping, long l) {
return shopping.getAddTime();
}
}));
// TODO: 3分钟内每个省购买每个商品总销量的Top3
SingleOutputStreamOperator> map = watermarks.map(new MapFunction>() {
@Override
public Tuple2 map(DWD_Cart shopping) throws Exception {
return new Tuple2<>(shopping.getClientProvince() + "," + shopping.getGoodsName(), shopping.getCount());
}
});
SingleOutputStreamOperator process = map.keyBy(0).sum(1).keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(60 * 3)))
//todo 调用process 处理函数
.process(new ProcessWindowFunction, String, Tuple, TimeWindow>() {
@Override
public void process(Tuple tuple, Context context, Iterable> iterable, Collector collector) throws Exception {
ArrayList> list = new ArrayList<>();
for (Tuple2 stringIntegerTuple2 : iterable) {
list.add(stringIntegerTuple2);
}
//todo sort排序
list.sort(new Comparator>() {
@Override
public int compare(Tuple2 o1, Tuple2 o2) {
return o2.f1 - o1.f1;
}
});
//todo for循环输出top3
for (int i = 0; i < 3 && i < list.size(); i++) {
Tuple2 stringIntegerTuple2 = list.get(i);
collector.collect(stringIntegerTuple2.toString());
}
}
});
process.print("每个省商品的top3>>>");
//todo 存入kfk
process.addSink(
new FlinkKafkaProducer( "top3",new SimpleStringSchema(), KafkaUtil.kafkaProps )
);
//todo 存入hbase
// process.addSink( new SinkHBaseUtil( "top3" ) );
environment.execute();
}
}