tf.data.Dataset.interleave() 最通俗易懂的使用详解(有图有真相)
最近学习tensorflow,对于这个函数tf.data.Dataset.interleave()始终有点晕乎,即使搞明白了,用不了多久又忘了,在网上查了查,发现很少有人能把这个函数讲清楚。趁着现在还明白,记录下来——备忘+助友。
interleave()是Dataset的类方法,所以interleave是作用在一个Dataset上的。
语法:
interleave(
map_func,
cycle_length=AUTOTUNE,
block_length=1,
num_parallel_calls=None
)
解释:
- 假定我们现在有一个Dataset——A
- 从该A中取出cycle_length个element,然后对这些element apply map_func,得到cycle_length个新的Dataset对象。
- 然后从这些新生成的Dataset对象中取数据,取数逻辑为轮流从每个对象里面取数据,每次取block_length个数据
- 当这些新生成的某个Dataset的对象取尽时,从原Dataset中再取cycle_length个element,,然后apply
map_func,以此类推。
举例:
a = tf.data.Dataset.range(1, 6) # ==> [ 1, 2, 3, 4, 5 ]
# NOTE: New lines indicate "block" boundaries.
b=a.interleave(lambda x: tf.data.Dataset.from_tensors(x).repeat(6),
cycle_length=2, block_length=4)
for item in b:
print(item.numpy(),end=', ')
输出结果:
1, 1, 1, 1, 2, 2, 2, 2, 1, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 3, 3, 4, 4, 5, 5, 5, 5, 5, 5,
上面程序的图示,看示意图可能更清晰:
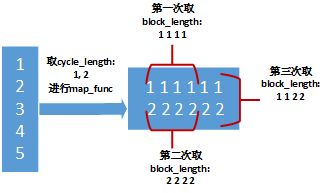
其中map_func在这里是重复6次-repeat(6)。
常见case:
dataset里面存储文件名, 将所有文件读取出来,产生一个大数据集
更详细内容可以参考官方文档