Kafka 3.0 源码笔记(10)-Kafka 服务端消息数据的主从同步源码分析
文章目录
- 前言
- 1. 消息数据主从同步的流程
- 2. 消息数据主从同步源码分析
-
-
- 2.1 元数据变动的发布
- 2.2 变动元数据的消费应用
- 2.3 主从副本的消息数据同步
-
前言
Kafka 3.0 源码笔记(9)-Kafka 服务端元数据的主从同步 中笔者在文章的末尾提到了元数据主从同步完成后,元数据的变动被 broker 模块监听处理后才能对集群产生影响,本文实际上就是以创建 Topic 功能为引子,从消息数据分区副本主从同步的场景来分析这个过程。结合 Kafka 的整体设计实现来看,创建 Topic 后,整个消息生产消费功能的完整流程如下图所示:

1. 消息数据主从同步的流程
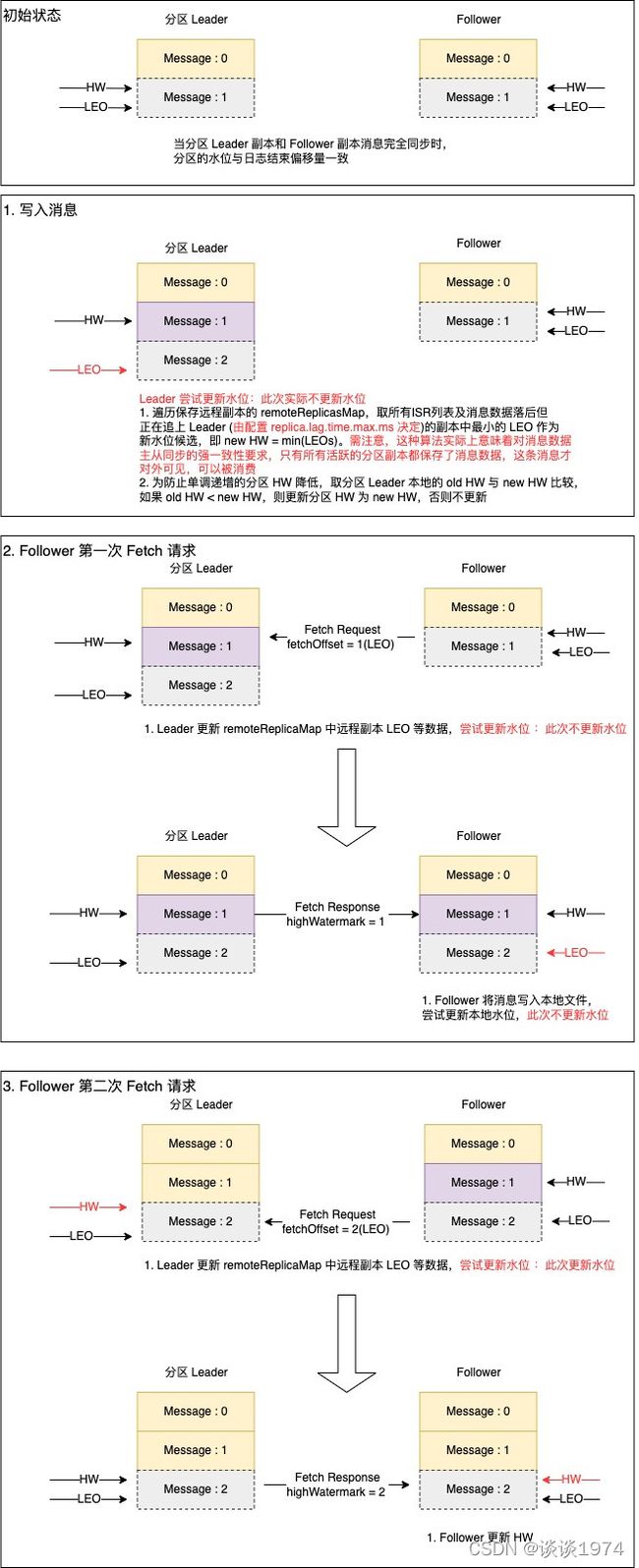
上图展示了消息写入后 Follower 副本通过 Fetch 请求完成消息数据及 HW 同步的过程,大致分为 4 个阶段:
初始状态
当某个分区的 Leader 副本和所有 Follower 副本保存的消息都一致时,HW 与 LEO 指向同一个位置。在以上示例图中,Leader 副本和 Follower 副本都保存了 Offset=0 的数据,HW 和 LEO 都指向还未写入的 Offset=1 的位置消息写入
Leader 副本所在节点接收生产消息请求,会将消息写入到本地的分区副本,此时 Leader 副本 LEO 指向 Offset=2 的位置。与此同时, Leader 副本还会尝试更新本地日志的 HW 水位,不过在当前阶段实际不会更新 HW 水位。 HW 更新具体算法如下,下文提及的尝试更新本地日志HW皆指代以下过程:
- 遍历分区内保存远程副本的 remoteReplicasMap,取所有ISR列表及消息数据落后但正在追上 Leader (由配置 replica.lag.time.max.ms 决定)的副本中最小的 LEO 作为新水位候选,即 new HW = min(LEOs)。需注意,这种算法实际上意味着对消息数据主从同步的强一致性要求,只有所有活跃的分区副本都保存了消息数据,这条消息才对外可见,可以被消费
- 为防止单调递增的分区 HW 降低,取分区 Leader 本地的 old HW 与 new HW 比较,如果 old HW < new HW,则更新分区 HW 为 new HW,否则不更新
第一次 Fetch 请求的交互
Follower 副本节点会通过 Fetcher 线程定时发送 Fetch 请求到 Leader 副本同步消息,发起的请求中会携带本地分区副本的 LEO=1。 Leader 副本所在节点接收到请求后,更新目标分区 remoteReplicasMap 中保存的该 Follower 副本状态,尝试更新本地日志HW。此时只要当前 Follower 副本不是最后一个来同步消息的,Leader 副本就不会更新本地 HW,仅仅返回消息记录。Follower 副本节点在处理 Fetch 响应时,仅会将消息追加到本地日志,并将 LEO 指向 Offset=2 的位置第二次 Fetch 请求的交互
与第一次 Fetch 请求交互类似,只不过这时 Fetcher 线程发起的请求中会携带本地分区副本的 LEO=2。假设此时已经有所有 Follower 副本都保存了新消息,那么 Leader 副本节点在尝试更新本地日志HW时会成功更新本地 HW 指向 Offset=2 的位置,并在 Fetch 响应中将当前 HW 返回给 Follower。Follower 依据 Leader 的 HW 更新本地副本 HW 指向 Offset=2 的位置,最终完成 HW 同步
2. 消息数据主从同步源码分析
新增 Topic 后,要最终实现消息数据在主从副本之间的同步,整个过程大致分为以下几个阶段:
- 元数据变动的发布
- 变动元数据的消费应用
- 主从副本的消息数据同步

2.1 元数据变动的发布
-
BrokerServer 启动过程中会调用
KafkaRaftManager.scala#register()方法将BrokerMetadataListener注册到KafkaRaftClient中,当元数据分区 HW 更新后将回调BrokerMetadataListener.scala#handleCommit()方法通知监听器。这个方法源码如下,关键处理显而易见:- 新建封装元数据消息的异步事件
HandleCommitsEvent对象,事件被处理时该对象HandleCommitsEvent#run()方法将被执行 - 调用
KafkaEventQueue.java#append()方法将事件投入到异步队列,关于这个事件队列的运作机制读者可参考Kafka 3.0 源码笔记(8)-Kafka 服务端集群 Leader 对 CreateTopics 请求的处理,笔者不再赘述
override def handleCommit(reader: BatchReader[ApiMessageAndVersion]): Unit = eventQueue.append(new HandleCommitsEvent(reader)) - 新建封装元数据消息的异步事件
-
HandleCommitsEvent#run()方法比较简练,核心逻辑如下:- 调用
BrokerMetadataListener.scala#loadBatches()解析元数据消息记录,将其重放出来载入到数据结构MetadataDelta - 调用
BrokerMetadataListener.scala#publish()方法使用元数据发布器发布元数据
class HandleCommitsEvent(reader: BatchReader[ApiMessageAndVersion]) extends EventQueue.FailureLoggingEvent(log) { override def run(): Unit = { val results = try { val loadResults = loadBatches(_delta, reader) if (isDebugEnabled) { debug(s"Loaded new commits: ${loadResults}") } loadResults } finally { reader.close() } _publisher.foreach(publish(_, results.highestMetadataOffset)) snapshotter.foreach { snapshotter => _bytesSinceLastSnapshot = _bytesSinceLastSnapshot + results.numBytes if (shouldSnapshot()) { if (snapshotter.maybeStartSnapshot(results.highestMetadataOffset, _highestEpoch, _highestTimestamp, _delta.apply())) { _bytesSinceLastSnapshot = 0L } } } } } - 调用
-
BrokerMetadataListener.scala#loadBatches()内部逻辑比较简单,可以看到就是遍历元数据消息列表,调用MetadataDelta.java#replay()方法将其载入private def loadBatches(delta: MetadataDelta, iterator: util.Iterator[Batch[ApiMessageAndVersion]]): BatchLoadResults = { val startTimeNs = time.nanoseconds() var numBatches = 0 var numRecords = 0 var batch: Batch[ApiMessageAndVersion] = null var numBytes = 0L while (iterator.hasNext()) { batch = iterator.next() var index = 0 batch.records().forEach { messageAndVersion => if (isTraceEnabled) { trace("Metadata batch %d: processing [%d/%d]: %s.".format(batch.lastOffset, index + 1, batch.records().size(), messageAndVersion.message().toString())) } delta.replay(messageAndVersion.message()) numRecords += 1 index += 1 } numBytes = numBytes + batch.sizeInBytes() metadataBatchSizeHist.update(batch.records().size()) numBatches = numBatches + 1 } val newHighestMetadataOffset = if (batch == null) { _highestMetadataOffset } else { _highestMetadataOffset = batch.lastOffset() _highestEpoch = batch.epoch() _highestTimestamp = batch.appendTimestamp() batch.lastOffset() } val endTimeNs = time.nanoseconds() val elapsedUs = TimeUnit.MICROSECONDS.convert(endTimeNs - startTimeNs, TimeUnit.NANOSECONDS) batchProcessingTimeHist.update(elapsedUs) BatchLoadResults(numBatches, numRecords, elapsedUs, numBytes, newHighestMetadataOffset) } -
MetadataDelta.java#replay()方法将根据元数据记录的类型进行处理分发,新增 Topic 生成的元数据记录类型为TOPIC_RECORD,则将触发MetadataDelta.java#replay()重载方法执行public void replay(ApiMessage record) { MetadataRecordType type = MetadataRecordType.fromId(record.apiKey()); switch (type) { case REGISTER_BROKER_RECORD: replay((RegisterBrokerRecord) record); break; case UNREGISTER_BROKER_RECORD: replay((UnregisterBrokerRecord) record); break; case TOPIC_RECORD: replay((TopicRecord) record); break; case PARTITION_RECORD: replay((PartitionRecord) record); break; case CONFIG_RECORD: replay((ConfigRecord) record); break; case PARTITION_CHANGE_RECORD: replay((PartitionChangeRecord) record); break; case FENCE_BROKER_RECORD: replay((FenceBrokerRecord) record); break; case UNFENCE_BROKER_RECORD: replay((UnfenceBrokerRecord) record); break; case REMOVE_TOPIC_RECORD: replay((RemoveTopicRecord) record); break; case FEATURE_LEVEL_RECORD: replay((FeatureLevelRecord) record); break; case CLIENT_QUOTA_RECORD: replay((ClientQuotaRecord) record); break; case PRODUCER_IDS_RECORD: // Nothing to do. break; case REMOVE_FEATURE_LEVEL_RECORD: replay((RemoveFeatureLevelRecord) record); break; case BROKER_REGISTRATION_CHANGE_RECORD: replay((BrokerRegistrationChangeRecord) record); break; default: throw new RuntimeException("Unknown metadata record type " + type); } } -
MetadataDelta.java#replay()处理TOPIC_RECORD消息类型的重载方法如下,可以看到核心处理是调用TopicsDelta.java#replay()方法public void replay(TopicRecord record) { if (topicsDelta == null) topicsDelta = new TopicsDelta(image.topics()); topicsDelta.replay(record); } -
TopicsDelta.java#replay()方法此处只是暂存消息中的 Topic 元数据,实际使用将在后文进行public void replay(TopicRecord record) { TopicDelta delta = new TopicDelta( new TopicImage(record.name(), record.topicId(), Collections.emptyMap())); changedTopics.put(record.topicId(), delta); } -
此时回到本节步骤2第2步,
BrokerMetadataListener.scala#publish()方法通过元数据发布器将元数据发布出来,触发BrokerMetadataPublisher.scala#publish()方法执行,至此元数据变动的发布基本结束private def publish(publisher: MetadataPublisher, newHighestMetadataOffset: Long): Unit = { val delta = _delta _image = _delta.apply() _delta = new MetadataDelta(_image) publisher.publish(newHighestMetadataOffset, delta, _image) }
2.2 变动元数据的消费应用
-
BrokerMetadataPublisher.scala#publish()方法实现如下,关键处理如下:- 如果是第一次发布元数据变更,需要调用
BrokerMetadataPublisher.scala#initializeManagers()方法进行初始化操作。这一步大多是定时任务的启动,包括日志文件相关的定期刷盘、异常恢复检测,副本管理相关的 ISR 列表过期收缩,以及消费者组协调器删除过期消费者组信息等 - 开始计算元数据的变动,进行相应处理,本文以 Topic 变动触发
ReplicaManager.scala#applyDelta()方法执行为例
override def publish(newHighestMetadataOffset: Long, delta: MetadataDelta, newImage: MetadataImage): Unit = { try { // Publish the new metadata image to the metadata cache. metadataCache.setImage(newImage) if (_firstPublish) { info(s"Publishing initial metadata at offset ${newHighestMetadataOffset}.") // If this is the first metadata update we are applying, initialize the managers // first (but after setting up the metadata cache). initializeManagers() } else if (isDebugEnabled) { debug(s"Publishing metadata at offset ${newHighestMetadataOffset}.") } // Apply feature deltas. Option(delta.featuresDelta()).foreach { featuresDelta => featureCache.update(featuresDelta, newHighestMetadataOffset) } // Apply topic deltas. Option(delta.topicsDelta()).foreach { topicsDelta => // Notify the replica manager about changes to topics. replicaManager.applyDelta(newImage, topicsDelta) // Handle the case where the old consumer offsets topic was deleted. if (topicsDelta.topicWasDeleted(Topic.GROUP_METADATA_TOPIC_NAME)) { topicsDelta.image().getTopic(Topic.GROUP_METADATA_TOPIC_NAME).partitions().entrySet().forEach { entry => if (entry.getValue().leader == brokerId) { groupCoordinator.onResignation(entry.getKey(), Some(entry.getValue().leaderEpoch)) } } } // Handle the case where we have new local leaders or followers for the consumer // offsets topic. getTopicDelta(Topic.GROUP_METADATA_TOPIC_NAME, newImage, delta).foreach { topicDelta => val changes = topicDelta.localChanges(brokerId) changes.deletes.forEach { topicPartition => groupCoordinator.onResignation(topicPartition.partition, None) } changes.leaders.forEach { (topicPartition, partitionInfo) => groupCoordinator.onElection(topicPartition.partition, partitionInfo.partition.leaderEpoch) } changes.followers.forEach { (topicPartition, partitionInfo) => groupCoordinator.onResignation(topicPartition.partition, Some(partitionInfo.partition.leaderEpoch)) } } // Handle the case where the old transaction state topic was deleted. if (topicsDelta.topicWasDeleted(Topic.TRANSACTION_STATE_TOPIC_NAME)) { topicsDelta.image().getTopic(Topic.TRANSACTION_STATE_TOPIC_NAME).partitions().entrySet().forEach { entry => if (entry.getValue().leader == brokerId) { txnCoordinator.onResignation(entry.getKey(), Some(entry.getValue().leaderEpoch)) } } } // If the transaction state topic changed in a way that's relevant to this broker, // notify the transaction coordinator. getTopicDelta(Topic.TRANSACTION_STATE_TOPIC_NAME, newImage, delta).foreach { topicDelta => val changes = topicDelta.localChanges(brokerId) changes.deletes.forEach { topicPartition => txnCoordinator.onResignation(topicPartition.partition, None) } changes.leaders.forEach { (topicPartition, partitionInfo) => txnCoordinator.onElection(topicPartition.partition, partitionInfo.partition.leaderEpoch) } changes.followers.forEach { (topicPartition, partitionInfo) => txnCoordinator.onResignation(topicPartition.partition, Some(partitionInfo.partition.leaderEpoch)) } } // Notify the group coordinator about deleted topics. val deletedTopicPartitions = new mutable.ArrayBuffer[TopicPartition]() topicsDelta.deletedTopicIds().forEach { id => val topicImage = topicsDelta.image().getTopic(id) topicImage.partitions().keySet().forEach { id => deletedTopicPartitions += new TopicPartition(topicImage.name(), id) } } if (deletedTopicPartitions.nonEmpty) { groupCoordinator.handleDeletedPartitions(deletedTopicPartitions, RequestLocal.NoCaching) } } // Apply configuration deltas. Option(delta.configsDelta()).foreach { configsDelta => configsDelta.changes().keySet().forEach { configResource => val tag = configResource.`type`() match { case ConfigResource.Type.TOPIC => Some(ConfigType.Topic) case ConfigResource.Type.BROKER => Some(ConfigType.Broker) case _ => None } tag.foreach { t => val newProperties = newImage.configs().configProperties(configResource) val maybeDefaultName = configResource.name() match { case "" => ConfigEntityName.Default case k => k } dynamicConfigHandlers(t).processConfigChanges(maybeDefaultName, newProperties) } } } // Apply client quotas delta. Option(delta.clientQuotasDelta()).foreach { clientQuotasDelta => clientQuotaMetadataManager.update(clientQuotasDelta) } if (_firstPublish) { finishInitializingReplicaManager(newImage) } } catch { case t: Throwable => error(s"Error publishing broker metadata at ${newHighestMetadataOffset}", t) throw t } finally { _firstPublish = false } } - 如果是第一次发布元数据变更,需要调用
-
ReplicaManager.scala#applyDelta()方法源码如下,关键处理分为如下几步:- 首先调用
TopicsDelta.java#localChanges()方法计算元数据中的 topic 变动点 - 计算出 topic 的变动点后,如果当前节点被分配了充当某些分区的 Leader 副本,那么调用
ReplicaManager.scala#applyLocalLeadersDelta()方法进行相应处理;如果当前节点还被分配负责某些分区的 Follower 副本,则调用ReplicaManager.scala#applyLocalFollowersDelta()进行处理
def applyDelta(newImage: MetadataImage, delta: TopicsDelta): Unit = { // Before taking the lock, compute the local changes val localChanges = delta.localChanges(config.nodeId) replicaStateChangeLock.synchronized { // Handle deleted partitions. We need to do this first because we might subsequently // create new partitions with the same names as the ones we are deleting here. if (!localChanges.deletes.isEmpty) { val deletes = localChanges.deletes.asScala.map(tp => (tp, true)).toMap stateChangeLogger.info(s"Deleting ${deletes.size} partition(s).") stopPartitions(deletes).foreach { case (topicPartition, e) => if (e.isInstanceOf[KafkaStorageException]) { stateChangeLogger.error(s"Unable to delete replica ${topicPartition} because " + "the local replica for the partition is in an offline log directory") } else { stateChangeLogger.error(s"Unable to delete replica ${topicPartition} because " + s"we got an unexpected ${e.getClass.getName} exception: ${e.getMessage}") } } } // Handle partitions which we are now the leader or follower for. if (!localChanges.leaders.isEmpty || !localChanges.followers.isEmpty) { val lazyOffsetCheckpoints = new LazyOffsetCheckpoints(this.highWatermarkCheckpoints) val changedPartitions = new mutable.HashSet[Partition] if (!localChanges.leaders.isEmpty) { applyLocalLeadersDelta(changedPartitions, delta, lazyOffsetCheckpoints, localChanges.leaders.asScala) } if (!localChanges.followers.isEmpty) { applyLocalFollowersDelta(changedPartitions, newImage, delta, lazyOffsetCheckpoints, localChanges.followers.asScala) } maybeAddLogDirFetchers(changedPartitions, lazyOffsetCheckpoints, name => Option(newImage.topics().getTopic(name)).map(_.id())) def markPartitionOfflineIfNeeded(tp: TopicPartition): Unit = { /* * If there is offline log directory, a Partition object may have been created by getOrCreatePartition() * before getOrCreateReplica() failed to create local replica due to KafkaStorageException. * In this case ReplicaManager.allPartitions will map this topic-partition to an empty Partition object. * we need to map this topic-partition to OfflinePartition instead. */ if (localLog(tp).isEmpty) markPartitionOffline(tp) } localChanges.leaders.keySet.forEach(markPartitionOfflineIfNeeded) localChanges.followers.keySet.forEach(markPartitionOfflineIfNeeded) replicaFetcherManager.shutdownIdleFetcherThreads() replicaAlterLogDirsManager.shutdownIdleFetcherThreads() } } } - 首先调用
-
TopicsDelta.java#localChanges()方法如下,根据方法注释可以看到这里主要计算以下 3 种需要在本节点应用的所有 topic 变动,单个 topic 的变动计算逻辑由TopicDelta.java#localChanges()实现,本文不再赘述- 当前节点需要删除的本地副本
- 当前节点新增的需要维护的 Leader 副本
- 当前节点新增的需要维护的 Follower 副本
/** * Find the topic partitions that have change based on the replica given. * * The changes identified are: * 1. topic partitions for which the broker is not a replica anymore * 2. topic partitions for which the broker is now the leader * 3. topic partitions for which the broker is now a follower * * @param brokerId the broker id * @return the list of topic partitions which the broker should remove, become leader or become follower. */ public LocalReplicaChanges localChanges(int brokerId) { Set<TopicPartition> deletes = new HashSet<>(); Map<TopicPartition, LocalReplicaChanges.PartitionInfo> leaders = new HashMap<>(); Map<TopicPartition, LocalReplicaChanges.PartitionInfo> followers = new HashMap<>(); for (TopicDelta delta : changedTopics.values()) { LocalReplicaChanges changes = delta.localChanges(brokerId); deletes.addAll(changes.deletes()); leaders.putAll(changes.leaders()); followers.putAll(changes.followers()); } // Add all of the removed topic partitions to the set of locally removed partitions deletedTopicIds().forEach(topicId -> { TopicImage topicImage = image().getTopic(topicId); topicImage.partitions().forEach((partitionId, prevPartition) -> { if (Replicas.contains(prevPartition.replicas, brokerId)) { deletes.add(new TopicPartition(topicImage.name(), partitionId)); } }); }); return new LocalReplicaChanges(deletes, leaders, followers); } -
元数据变动计算完毕,回到本节步骤2第2步,如果当前节点有新增的需要维护的 Leader 副本,则
ReplicaManager.scala#applyLocalLeadersDelta()方法将被触发执行。这个方法的实现如下,可以看到核心处理比较简单:- 遍历新的 Leader 列表,调用
ReplicaManager.scala#getOrCreatePartition()方法为其创建本地分区 Partition 对象 - 调用
Partition.scala#makeLeader()将新建的 Partition 对象设置为分区副本 Leader
private def applyLocalLeadersDelta( changedPartitions: mutable.Set[Partition], delta: TopicsDelta, offsetCheckpoints: OffsetCheckpoints, newLocalLeaders: mutable.Map[TopicPartition, LocalReplicaChanges.PartitionInfo] ): Unit = { stateChangeLogger.info(s"Transitioning ${newLocalLeaders.size} partition(s) to " + "local leaders.") replicaFetcherManager.removeFetcherForPartitions(newLocalLeaders.keySet) newLocalLeaders.forKeyValue { case (tp, info) => getOrCreatePartition(tp, delta, info.topicId).foreach { case (partition, isNew) => try { val state = info.partition.toLeaderAndIsrPartitionState(tp, isNew) if (!partition.makeLeader(state, offsetCheckpoints, Some(info.topicId))) { stateChangeLogger.info("Skipped the become-leader state change for " + s"${tp} with topic id ${info.topicId} because this partition is " + "already a local leader.") } changedPartitions.add(partition) } catch { case e: KafkaStorageException => stateChangeLogger.info(s"Skipped the become-leader state change for ${tp} " + s"with topic id ${info.topicId} due to disk error ${e}") val dirOpt = getLogDir(tp) error(s"Error while making broker the leader for partition ${tp} in dir " + s"${dirOpt}", e) } } } } - 遍历新的 Leader 列表,调用
-
Partition.scala#makeLeader()处理流程还算清晰,关键的处理如下:- 执行
Partition.scala#updateAssignmentAndIsr()方法更新当前分区 Leader 副本的 ISR 列表及内部的远程副本列表 remoteReplicasMap - 调用
Partition.scala#createLogIfNotExists()方法为当前分区 Leader 副本创建本地日志文件,如果文件已经存在则不创建 - 调用
Log.scala#maybeAssignEpochStartOffset()方法更新当前分区的 Leader 版本等信息,后续将用于异常恢复,感兴趣的读者可参考 Kafka 3.0 源码笔记(12)-Kafka 服务端分区异常恢复机制的源码分析 - 调用
Partition.scala#maybeIncrementLeaderHW()方法尝试更新当前分区的水位 HW
def makeLeader(partitionState: LeaderAndIsrPartitionState, highWatermarkCheckpoints: OffsetCheckpoints, topicId: Option[Uuid]): Boolean = { val (leaderHWIncremented, isNewLeader) = inWriteLock(leaderIsrUpdateLock) { // record the epoch of the controller that made the leadership decision. This is useful while updating the isr // to maintain the decision maker controller's epoch in the zookeeper path controllerEpoch = partitionState.controllerEpoch val isr = partitionState.isr.asScala.map(_.toInt).toSet val addingReplicas = partitionState.addingReplicas.asScala.map(_.toInt) val removingReplicas = partitionState.removingReplicas.asScala.map(_.toInt) updateAssignmentAndIsr( assignment = partitionState.replicas.asScala.map(_.toInt), isr = isr, addingReplicas = addingReplicas, removingReplicas = removingReplicas ) try { createLogIfNotExists(partitionState.isNew, isFutureReplica = false, highWatermarkCheckpoints, topicId) } catch { case e: ZooKeeperClientException => stateChangeLogger.error(s"A ZooKeeper client exception has occurred and makeLeader will be skipping the " + s"state change for the partition $topicPartition with leader epoch: $leaderEpoch ", e) return false } val leaderLog = localLogOrException val leaderEpochStartOffset = leaderLog.logEndOffset stateChangeLogger.info(s"Leader $topicPartition starts at leader epoch ${partitionState.leaderEpoch} from " + s"offset $leaderEpochStartOffset with high watermark ${leaderLog.highWatermark} " + s"ISR ${isr.mkString("[", ",", "]")} addingReplicas ${addingReplicas.mkString("[", ",", "]")} " + s"removingReplicas ${removingReplicas.mkString("[", ",", "]")}. Previous leader epoch was $leaderEpoch.") //We cache the leader epoch here, persisting it only if it's local (hence having a log dir) leaderEpoch = partitionState.leaderEpoch leaderEpochStartOffsetOpt = Some(leaderEpochStartOffset) zkVersion = partitionState.zkVersion // In the case of successive leader elections in a short time period, a follower may have // entries in its log from a later epoch than any entry in the new leader's log. In order // to ensure that these followers can truncate to the right offset, we must cache the new // leader epoch and the start offset since it should be larger than any epoch that a follower // would try to query. leaderLog.maybeAssignEpochStartOffset(leaderEpoch, leaderEpochStartOffset) val isNewLeader = !isLeader val curTimeMs = time.milliseconds // initialize lastCaughtUpTime of replicas as well as their lastFetchTimeMs and lastFetchLeaderLogEndOffset. remoteReplicas.foreach { replica => val lastCaughtUpTimeMs = if (isrState.isr.contains(replica.brokerId)) curTimeMs else 0L replica.resetLastCaughtUpTime(leaderEpochStartOffset, curTimeMs, lastCaughtUpTimeMs) } if (isNewLeader) { // mark local replica as the leader after converting hw leaderReplicaIdOpt = Some(localBrokerId) // reset log end offset for remote replicas remoteReplicas.foreach { replica => replica.updateFetchState( followerFetchOffsetMetadata = LogOffsetMetadata.UnknownOffsetMetadata, followerStartOffset = Log.UnknownOffset, followerFetchTimeMs = 0L, leaderEndOffset = Log.UnknownOffset) } } // we may need to increment high watermark since ISR could be down to 1 (maybeIncrementLeaderHW(leaderLog), isNewLeader) } // some delayed operations may be unblocked after HW changed if (leaderHWIncremented) tryCompleteDelayedRequests() isNewLeader } - 执行
-
Partition.scala#maybeIncrementLeaderHW()方法的实现如下所示,具体算法在上文第1节-消息数据主从同步的流程有提及,此处不再赘述private def maybeIncrementLeaderHW(leaderLog: Log, curTime: Long = time.milliseconds): Boolean = { // maybeIncrementLeaderHW is in the hot path, the following code is written to // avoid unnecessary collection generation var newHighWatermark = leaderLog.logEndOffsetMetadata remoteReplicasMap.values.foreach { replica => // Note here we are using the "maximal", see explanation above if (replica.logEndOffsetMetadata.messageOffset < newHighWatermark.messageOffset && (curTime - replica.lastCaughtUpTimeMs <= replicaLagTimeMaxMs || isrState.maximalIsr.contains(replica.brokerId))) { newHighWatermark = replica.logEndOffsetMetadata } } leaderLog.maybeIncrementHighWatermark(newHighWatermark) match { case Some(oldHighWatermark) => debug(s"High watermark updated from $oldHighWatermark to $newHighWatermark") true case None => def logEndOffsetString: ((Int, LogOffsetMetadata)) => String = { case (brokerId, logEndOffsetMetadata) => s"replica $brokerId: $logEndOffsetMetadata" } if (isTraceEnabled) { val replicaInfo = remoteReplicas.map(replica => (replica.brokerId, replica.logEndOffsetMetadata)).toSet val localLogInfo = (localBrokerId, localLogOrException.logEndOffsetMetadata) trace(s"Skipping update high watermark since new hw $newHighWatermark is not larger than old value. " + s"All current LEOs are ${(replicaInfo + localLogInfo).map(logEndOffsetString)}") } false } } -
此时回到本节步骤2第2步,如果当前节点有新增的需要维护的 Follower 副本,则
ReplicaManager.scala#applyLocalFollowersDelta()方法将被触发执行。这个方法的实现如下,关键步骤分为以下几步:- 调用
ReplicaManager.scala#getOrCreatePartition()方法创建本地分区 Partition 对象 - 调用
Partition.scala#makeFollower()将新建的 Partition 对象设置为分区副本 Follower - 调用
ReplicaFetcherManager.scala#addFetcherForPartitions()方法为分区 Follower 副本设置 Fetcher 线程,该线程用于从分区Leader 副本处同步消息数据
private def applyLocalFollowersDelta( changedPartitions: mutable.Set[Partition], newImage: MetadataImage, delta: TopicsDelta, offsetCheckpoints: OffsetCheckpoints, newLocalFollowers: mutable.Map[TopicPartition, LocalReplicaChanges.PartitionInfo] ): Unit = { stateChangeLogger.info(s"Transitioning ${newLocalFollowers.size} partition(s) to " + "local followers.") val shuttingDown = isShuttingDown.get() val partitionsToMakeFollower = new mutable.HashMap[TopicPartition, Partition] val newFollowerTopicSet = new mutable.HashSet[String] newLocalFollowers.forKeyValue { case (tp, info) => getOrCreatePartition(tp, delta, info.topicId).foreach { case (partition, isNew) => try { newFollowerTopicSet.add(tp.topic) if (shuttingDown) { stateChangeLogger.trace(s"Unable to start fetching ${tp} with topic " + s"ID ${info.topicId} because the replica manager is shutting down.") } else { val leader = info.partition.leader if (newImage.cluster.broker(leader) == null) { stateChangeLogger.trace(s"Unable to start fetching $tp with topic ID ${info.topicId} " + s"from leader $leader because it is not alive.") // Create the local replica even if the leader is unavailable. This is required // to ensure that we include the partition's high watermark in the checkpoint // file (see KAFKA-1647). partition.createLogIfNotExists(isNew, false, offsetCheckpoints, Some(info.topicId)) } else { val state = info.partition.toLeaderAndIsrPartitionState(tp, isNew) if (partition.makeFollower(state, offsetCheckpoints, Some(info.topicId))) { partitionsToMakeFollower.put(tp, partition) } else { stateChangeLogger.info("Skipped the become-follower state change after marking its " + s"partition as follower for partition $tp with id ${info.topicId} and partition state $state.") } } } changedPartitions.add(partition) } catch { case e: Throwable => stateChangeLogger.error(s"Unable to start fetching ${tp} " + s"with topic ID ${info.topicId} due to ${e.getClass.getSimpleName}", e) replicaFetcherManager.addFailedPartition(tp) } } } // Stopping the fetchers must be done first in order to initialize the fetch // position correctly. replicaFetcherManager.removeFetcherForPartitions(partitionsToMakeFollower.keySet) stateChangeLogger.info(s"Stopped fetchers as part of become-follower for ${partitionsToMakeFollower.size} partitions") val listenerName = config.interBrokerListenerName.value val partitionAndOffsets = new mutable.HashMap[TopicPartition, InitialFetchState] partitionsToMakeFollower.forKeyValue { (topicPartition, partition) => val node = partition.leaderReplicaIdOpt .flatMap(leaderId => Option(newImage.cluster.broker(leaderId))) .flatMap(_.node(listenerName).asScala) .getOrElse(Node.noNode) val log = partition.localLogOrException partitionAndOffsets.put(topicPartition, InitialFetchState( new BrokerEndPoint(node.id, node.host, node.port), partition.getLeaderEpoch, initialFetchOffset(log) )) } replicaFetcherManager.addFetcherForPartitions(partitionAndOffsets) stateChangeLogger.info(s"Started fetchers as part of become-follower for ${partitionsToMakeFollower.size} partitions") partitionsToMakeFollower.keySet.foreach(completeDelayedFetchOrProduceRequests) updateLeaderAndFollowerMetrics(newFollowerTopicSet) } - 调用
-
Partition.scala#makeFollower()的处理比较简单,是Partition.scala#makeLeader()的精简版本,此处不再赘述def makeFollower(partitionState: LeaderAndIsrPartitionState, highWatermarkCheckpoints: OffsetCheckpoints, topicId: Option[Uuid]): Boolean = { inWriteLock(leaderIsrUpdateLock) { val newLeaderBrokerId = partitionState.leader val oldLeaderEpoch = leaderEpoch // record the epoch of the controller that made the leadership decision. This is useful while updating the isr // to maintain the decision maker controller's epoch in the zookeeper path controllerEpoch = partitionState.controllerEpoch updateAssignmentAndIsr( assignment = partitionState.replicas.asScala.iterator.map(_.toInt).toSeq, isr = Set.empty[Int], addingReplicas = partitionState.addingReplicas.asScala.map(_.toInt), removingReplicas = partitionState.removingReplicas.asScala.map(_.toInt) ) try { createLogIfNotExists(partitionState.isNew, isFutureReplica = false, highWatermarkCheckpoints, topicId) } catch { case e: ZooKeeperClientException => stateChangeLogger.error(s"A ZooKeeper client exception has occurred. makeFollower will be skipping the " + s"state change for the partition $topicPartition with leader epoch: $leaderEpoch.", e) return false } val followerLog = localLogOrException val leaderEpochEndOffset = followerLog.logEndOffset stateChangeLogger.info(s"Follower $topicPartition starts at leader epoch ${partitionState.leaderEpoch} from " + s"offset $leaderEpochEndOffset with high watermark ${followerLog.highWatermark}. " + s"Previous leader epoch was $leaderEpoch.") leaderEpoch = partitionState.leaderEpoch leaderEpochStartOffsetOpt = None zkVersion = partitionState.zkVersion if (leaderReplicaIdOpt.contains(newLeaderBrokerId) && leaderEpoch == oldLeaderEpoch) { false } else { leaderReplicaIdOpt = Some(newLeaderBrokerId) true } } } -
ReplicaFetcherManager.scala#addFetcherForPartitions()实际由其父类AbstractFetcherManager.scala#addFetcherForPartitions()实现,
可以看到这里关键处理是调用内部addAndStartFetcherThread()方法执行子类ReplicaFetcherManager.scala#createFetcherThread()方法创建 Fetcher 线程,并将其启动def addFetcherForPartitions(partitionAndOffsets: Map[TopicPartition, InitialFetchState]): Unit = { lock synchronized { val partitionsPerFetcher = partitionAndOffsets.groupBy { case (topicPartition, brokerAndInitialFetchOffset) => BrokerAndFetcherId(brokerAndInitialFetchOffset.leader, getFetcherId(topicPartition)) } def addAndStartFetcherThread(brokerAndFetcherId: BrokerAndFetcherId, brokerIdAndFetcherId: BrokerIdAndFetcherId): T = { val fetcherThread = createFetcherThread(brokerAndFetcherId.fetcherId, brokerAndFetcherId.broker) fetcherThreadMap.put(brokerIdAndFetcherId, fetcherThread) fetcherThread.start() fetcherThread } for ((brokerAndFetcherId, initialFetchOffsets) <- partitionsPerFetcher) { val brokerIdAndFetcherId = BrokerIdAndFetcherId(brokerAndFetcherId.broker.id, brokerAndFetcherId.fetcherId) val fetcherThread = fetcherThreadMap.get(brokerIdAndFetcherId) match { case Some(currentFetcherThread) if currentFetcherThread.sourceBroker == brokerAndFetcherId.broker => // reuse the fetcher thread currentFetcherThread case Some(f) => f.shutdown() addAndStartFetcherThread(brokerAndFetcherId, brokerIdAndFetcherId) case None => addAndStartFetcherThread(brokerAndFetcherId, brokerIdAndFetcherId) } addPartitionsToFetcherThread(fetcherThread, initialFetchOffsets) } } } -
ReplicaFetcherManager.scala#createFetcherThread()方法将创建ReplicaFetcherThread对象作为 Fetcher 线程实例,至此 Topic 元数据变动的消费应用告一段落override def createFetcherThread(fetcherId: Int, sourceBroker: BrokerEndPoint): ReplicaFetcherThread = { val prefix = threadNamePrefix.map(tp => s"$tp:").getOrElse("") val threadName = s"${prefix}ReplicaFetcherThread-$fetcherId-${sourceBroker.id}" new ReplicaFetcherThread(threadName, fetcherId, sourceBroker, brokerConfig, failedPartitions, replicaManager, metrics, time, quotaManager) }
2.3 主从副本的消息数据同步
-
在上一节中,
ReplicaFetcherThread线程对象被创建后会立即启动,触发ReplicaFetcherThread.scala#run()方法执行,不过这个方法实际是由其父类ShutdownableThread.scala#run()方法实现,可以看到核心逻辑就是在 while 循环中不断执行子类实现的AbstractFetcherThread.scala#doWork()方法override def run(): Unit = { isStarted = true info("Starting") try { while (isRunning) doWork() } catch { case e: FatalExitError => shutdownInitiated.countDown() shutdownComplete.countDown() info("Stopped") Exit.exit(e.statusCode()) case e: Throwable => if (isRunning) error("Error due to", e) } finally { shutdownComplete.countDown() } info("Stopped") } -
AbstractFetcherThread.scala#doWork()方法内部只有两个方法调用,其中AbstractFetcherThread.scala#maybeTruncate()方法是在异常恢复时处理日志截断的,本文暂不分析。AbstractFetcherThread.scala#maybeFetch()方法则通过以下几步实际完成 Fetch 请求同步消息数据的功能:- 调用子类实现
ReplicaFetcherThread.scala#buildFetch()方法构建 Fetch 请求 - 调用
AbstractFetcherThread.scala#processFetchRequest()方法发起 Fetch 请求并处理响应数据
override def doWork(): Unit = { maybeTruncate() maybeFetch() } private def maybeFetch(): Unit = { val fetchRequestOpt = inLock(partitionMapLock) { val ResultWithPartitions(fetchRequestOpt, partitionsWithError) = buildFetch(partitionStates.partitionStateMap.asScala) handlePartitionsWithErrors(partitionsWithError, "maybeFetch") if (fetchRequestOpt.isEmpty) { trace(s"There are no active partitions. Back off for $fetchBackOffMs ms before sending a fetch request") partitionMapCond.await(fetchBackOffMs, TimeUnit.MILLISECONDS) } fetchRequestOpt } fetchRequestOpt.foreach { case ReplicaFetch(sessionPartitions, fetchRequest) => processFetchRequest(sessionPartitions, fetchRequest) } } - 调用子类实现
-
ReplicaFetcherThread.scala#buildFetch()方法其实比较简单,需要注意的是 Fetch 请求中会线程初始化时设置进来的本地日志的 LEO 填充到 fetchOffset 参数override def buildFetch(partitionMap: Map[TopicPartition, PartitionFetchState]): ResultWithPartitions[Option[ReplicaFetch]] = { val partitionsWithError = mutable.Set[TopicPartition]() val builder = fetchSessionHandler.newBuilder(partitionMap.size, false) partitionMap.forKeyValue { (topicPartition, fetchState) => // We will not include a replica in the fetch request if it should be throttled. if (fetchState.isReadyForFetch && !shouldFollowerThrottle(quota, fetchState, topicPartition)) { try { val logStartOffset = this.logStartOffset(topicPartition) val lastFetchedEpoch = if (isTruncationOnFetchSupported) fetchState.lastFetchedEpoch.map(_.asInstanceOf[Integer]).asJava else Optional.empty[Integer] builder.add(topicPartition, new FetchRequest.PartitionData( fetchState.fetchOffset, logStartOffset, fetchSize, Optional.of(fetchState.currentLeaderEpoch), lastFetchedEpoch)) } catch { case _: KafkaStorageException => // The replica has already been marked offline due to log directory failure and the original failure should have already been logged. // This partition should be removed from ReplicaFetcherThread soon by ReplicaManager.handleLogDirFailure() partitionsWithError += topicPartition } } } val fetchData = builder.build() val fetchRequestOpt = if (fetchData.sessionPartitions.isEmpty && fetchData.toForget.isEmpty) { None } else { val requestBuilder = FetchRequest.Builder .forReplica(fetchRequestVersion, replicaId, maxWait, minBytes, fetchData.toSend) .setMaxBytes(maxBytes) .toForget(fetchData.toForget) .metadata(fetchData.metadata) Some(ReplicaFetch(fetchData.sessionPartitions(), requestBuilder)) } ResultWithPartitions(fetchRequestOpt, partitionsWithError) } -
AbstractFetcherThread.scala#processFetchRequest()方法关键处理如下:- 首先调用子类
ReplicaFetcherThread.scala#fetchFromLeader()实现向分区副本 Leader 发起 Fetch 请求,这部分往下分析涉及到底层网络组件NetworkClient,读者如有兴趣可参考消费者组协调器定位了解其工作机制,本文不再赘述 - 如果 Fetch 响应中有消息数据,则调用子类实现方法
ReplicaFetcherThread.scala#processPartitionData()将消息追加到本地日志 - 如果当前服务端版本支持在 Fetch 时进行日志截断操作,那么处理 Fetch 响应时会同步收集其携带的版本分歧信息。因为分区主从副本的版本不一致通常是发生了故障恢复,分区 Follower 副本可能需要进行日志截断以保持和 Leader 副本数据一致,这部分最后由
AbstractFetcherThread.scala#truncateOnFetchResponse()方法处理,此处暂不深入分析
private def processFetchRequest(sessionPartitions: util.Map[TopicPartition, FetchRequest.PartitionData], fetchRequest: FetchRequest.Builder): Unit = { val partitionsWithError = mutable.Set[TopicPartition]() val divergingEndOffsets = mutable.Map.empty[TopicPartition, EpochEndOffset] var responseData: Map[TopicPartition, FetchData] = Map.empty try { trace(s"Sending fetch request $fetchRequest") responseData = fetchFromLeader(fetchRequest) } catch { case t: Throwable => if (isRunning) { warn(s"Error in response for fetch request $fetchRequest", t) inLock(partitionMapLock) { partitionsWithError ++= partitionStates.partitionSet.asScala // there is an error occurred while fetching partitions, sleep a while // note that `AbstractFetcherThread.handlePartitionsWithError` will also introduce the same delay for every // partition with error effectively doubling the delay. It would be good to improve this. partitionMapCond.await(fetchBackOffMs, TimeUnit.MILLISECONDS) } } } fetcherStats.requestRate.mark() if (responseData.nonEmpty) { // process fetched data inLock(partitionMapLock) { responseData.forKeyValue { (topicPartition, partitionData) => Option(partitionStates.stateValue(topicPartition)).foreach { currentFetchState => // It's possible that a partition is removed and re-added or truncated when there is a pending fetch request. // In this case, we only want to process the fetch response if the partition state is ready for fetch and // the current offset is the same as the offset requested. val fetchPartitionData = sessionPartitions.get(topicPartition) if (fetchPartitionData != null && fetchPartitionData.fetchOffset == currentFetchState.fetchOffset && currentFetchState.isReadyForFetch) { Errors.forCode(partitionData.errorCode) match { case Errors.NONE => try { // Once we hand off the partition data to the subclass, we can't mess with it any more in this thread val logAppendInfoOpt = processPartitionData(topicPartition, currentFetchState.fetchOffset, partitionData) logAppendInfoOpt.foreach { logAppendInfo => val validBytes = logAppendInfo.validBytes val nextOffset = if (validBytes > 0) logAppendInfo.lastOffset + 1 else currentFetchState.fetchOffset val lag = Math.max(0L, partitionData.highWatermark - nextOffset) fetcherLagStats.getAndMaybePut(topicPartition).lag = lag // ReplicaDirAlterThread may have removed topicPartition from the partitionStates after processing the partition data if (validBytes > 0 && partitionStates.contains(topicPartition)) { // Update partitionStates only if there is no exception during processPartitionData val newFetchState = PartitionFetchState(nextOffset, Some(lag), currentFetchState.currentLeaderEpoch, state = Fetching, logAppendInfo.lastLeaderEpoch) partitionStates.updateAndMoveToEnd(topicPartition, newFetchState) fetcherStats.byteRate.mark(validBytes) } } if (isTruncationOnFetchSupported) { FetchResponse.divergingEpoch(partitionData).ifPresent { divergingEpoch => divergingEndOffsets += topicPartition -> new EpochEndOffset() .setPartition(topicPartition.partition) .setErrorCode(Errors.NONE.code) .setLeaderEpoch(divergingEpoch.epoch) .setEndOffset(divergingEpoch.endOffset) } } } catch { case ime@( _: CorruptRecordException | _: InvalidRecordException) => // we log the error and continue. This ensures two things // 1. If there is a corrupt message in a topic partition, it does not bring the fetcher thread // down and cause other topic partition to also lag // 2. If the message is corrupt due to a transient state in the log (truncation, partial writes // can cause this), we simply continue and should get fixed in the subsequent fetches error(s"Found invalid messages during fetch for partition $topicPartition " + s"offset ${currentFetchState.fetchOffset}", ime) partitionsWithError += topicPartition case e: KafkaStorageException => error(s"Error while processing data for partition $topicPartition " + s"at offset ${currentFetchState.fetchOffset}", e) markPartitionFailed(topicPartition) case t: Throwable => // stop monitoring this partition and add it to the set of failed partitions error(s"Unexpected error occurred while processing data for partition $topicPartition " + s"at offset ${currentFetchState.fetchOffset}", t) markPartitionFailed(topicPartition) } case Errors.OFFSET_OUT_OF_RANGE => if (handleOutOfRangeError(topicPartition, currentFetchState, fetchPartitionData.currentLeaderEpoch)) partitionsWithError += topicPartition case Errors.UNKNOWN_LEADER_EPOCH => debug(s"Remote broker has a smaller leader epoch for partition $topicPartition than " + s"this replica's current leader epoch of ${currentFetchState.currentLeaderEpoch}.") partitionsWithError += topicPartition case Errors.FENCED_LEADER_EPOCH => if (onPartitionFenced(topicPartition, fetchPartitionData.currentLeaderEpoch)) partitionsWithError += topicPartition case Errors.NOT_LEADER_OR_FOLLOWER => debug(s"Remote broker is not the leader for partition $topicPartition, which could indicate " + "that the partition is being moved") partitionsWithError += topicPartition case Errors.UNKNOWN_TOPIC_OR_PARTITION => warn(s"Received ${Errors.UNKNOWN_TOPIC_OR_PARTITION} from the leader for partition $topicPartition. " + "This error may be returned transiently when the partition is being created or deleted, but it is not " + "expected to persist.") partitionsWithError += topicPartition case partitionError => error(s"Error for partition $topicPartition at offset ${currentFetchState.fetchOffset}", partitionError.exception) partitionsWithError += topicPartition } } } } } } if (divergingEndOffsets.nonEmpty) truncateOnFetchResponse(divergingEndOffsets) if (partitionsWithError.nonEmpty) { handlePartitionsWithErrors(partitionsWithError, "processFetchRequest") } } - 首先调用子类
-
ReplicaFetcherThread.scala#processPartitionData()的重点处理简单明了:- 调用
Partition.scala#appendRecordsToFollowerOrFutureReplica()方法将消息数据追加到本地,这部分主要是日志文件的写操作,读者如有兴趣可参考Kafka 3.0 源码笔记(7)-Kafka 服务端对客户端的 Produce 请求处理,至此就完成了主从副本消息数据的同步 - 消息写入完成后,需要把 Fetch 响应中的 HW 取出来,尝试更新本地日志的 HW,这部分由调用
Log.scala#updateHighWatermark()方法实现
override def processPartitionData(topicPartition: TopicPartition, fetchOffset: Long, partitionData: FetchData): Option[LogAppendInfo] = { val logTrace = isTraceEnabled val partition = replicaMgr.getPartitionOrException(topicPartition) val log = partition.localLogOrException val records = toMemoryRecords(FetchResponse.recordsOrFail(partitionData)) maybeWarnIfOversizedRecords(records, topicPartition) if (fetchOffset != log.logEndOffset) throw new IllegalStateException("Offset mismatch for partition %s: fetched offset = %d, log end offset = %d.".format( topicPartition, fetchOffset, log.logEndOffset)) if (logTrace) trace("Follower has replica log end offset %d for partition %s. Received %d messages and leader hw %d" .format(log.logEndOffset, topicPartition, records.sizeInBytes, partitionData.highWatermark)) // Append the leader's messages to the log val logAppendInfo = partition.appendRecordsToFollowerOrFutureReplica(records, isFuture = false) if (logTrace) trace("Follower has replica log end offset %d after appending %d bytes of messages for partition %s" .format(log.logEndOffset, records.sizeInBytes, topicPartition)) val leaderLogStartOffset = partitionData.logStartOffset // For the follower replica, we do not need to keep its segment base offset and physical position. // These values will be computed upon becoming leader or handling a preferred read replica fetch. val followerHighWatermark = log.updateHighWatermark(partitionData.highWatermark) log.maybeIncrementLogStartOffset(leaderLogStartOffset, LeaderOffsetIncremented) if (logTrace) trace(s"Follower set replica high watermark for partition $topicPartition to $followerHighWatermark") // Traffic from both in-sync and out of sync replicas are accounted for in replication quota to ensure total replication // traffic doesn't exceed quota. if (quota.isThrottled(topicPartition)) quota.record(records.sizeInBytes) if (partition.isReassigning && partition.isAddingLocalReplica) brokerTopicStats.updateReassignmentBytesIn(records.sizeInBytes) brokerTopicStats.updateReplicationBytesIn(records.sizeInBytes) logAppendInfo } - 调用
-
至于分区 Leader 副本对来自 Follower 的 Fetch 请求的处理,读者可参考 Kafka 3.0 源码笔记(4)-Kafka 服务端对客户端的 Fetch 请求处理 一节第3步,此时将会触发
ReplicaManager.scala#updateFollowerFetchState()方法执行,核心处理执行Partition.scala#updateFollowerFetchState()方法以便更新 Leader 副本保存的远程副本列表中的 LEOprivate def updateFollowerFetchState(followerId: Int, readResults: Seq[(TopicPartition, LogReadResult)]): Seq[(TopicPartition, LogReadResult)] = { readResults.map { case (topicPartition, readResult) => val updatedReadResult = if (readResult.error != Errors.NONE) { debug(s"Skipping update of fetch state for follower $followerId since the " + s"log read returned error ${readResult.error}") readResult } else if (readResult.divergingEpoch.nonEmpty) { debug(s"Skipping update of fetch state for follower $followerId since the " + s"log read returned diverging epoch ${readResult.divergingEpoch}") readResult } else { onlinePartition(topicPartition) match { case Some(partition) => if (partition.updateFollowerFetchState(followerId, followerFetchOffsetMetadata = readResult.info.fetchOffsetMetadata, followerStartOffset = readResult.followerLogStartOffset, followerFetchTimeMs = readResult.fetchTimeMs, leaderEndOffset = readResult.leaderLogEndOffset)) { readResult } else { warn(s"Leader $localBrokerId failed to record follower $followerId's position " + s"${readResult.info.fetchOffsetMetadata.messageOffset}, and last sent HW since the replica " + s"is not recognized to be one of the assigned replicas ${partition.assignmentState.replicas.mkString(",")} " + s"for partition $topicPartition. Empty records will be returned for this partition.") readResult.withEmptyFetchInfo } case None => warn(s"While recording the replica LEO, the partition $topicPartition hasn't been created.") readResult } } topicPartition -> updatedReadResult } } -
Partition.scala#updateFollowerFetchState()没有复杂逻辑,可以看到核心处理分为两步,至此本文全部分析基本结束- 更新发出 Fetch 请求的 Follower 副本的 LEO 等信息
- 调用上文2.2节步骤6提到的
Partition.scala#maybeIncrementLeaderHW()方法在处理 Follower 端 Fetch 请求时尝试更新分区 HW,只有 HW 更新后新消息才算是 committed 状态,可以被消费者消费
def updateFollowerFetchState(followerId: Int, followerFetchOffsetMetadata: LogOffsetMetadata, followerStartOffset: Long, followerFetchTimeMs: Long, leaderEndOffset: Long): Boolean = { getReplica(followerId) match { case Some(followerReplica) => // No need to calculate low watermark if there is no delayed DeleteRecordsRequest val oldLeaderLW = if (delayedOperations.numDelayedDelete > 0) lowWatermarkIfLeader else -1L val prevFollowerEndOffset = followerReplica.logEndOffset followerReplica.updateFetchState( followerFetchOffsetMetadata, followerStartOffset, followerFetchTimeMs, leaderEndOffset) val newLeaderLW = if (delayedOperations.numDelayedDelete > 0) lowWatermarkIfLeader else -1L // check if the LW of the partition has incremented // since the replica's logStartOffset may have incremented val leaderLWIncremented = newLeaderLW > oldLeaderLW // Check if this in-sync replica needs to be added to the ISR. maybeExpandIsr(followerReplica, followerFetchTimeMs) // check if the HW of the partition can now be incremented // since the replica may already be in the ISR and its LEO has just incremented val leaderHWIncremented = if (prevFollowerEndOffset != followerReplica.logEndOffset) { // the leader log may be updated by ReplicaAlterLogDirsThread so the following method must be in lock of // leaderIsrUpdateLock to prevent adding new hw to invalid log. inReadLock(leaderIsrUpdateLock) { leaderLogIfLocal.exists(leaderLog => maybeIncrementLeaderHW(leaderLog, followerFetchTimeMs)) } } else { false } // some delayed operations may be unblocked after HW or LW changed if (leaderLWIncremented || leaderHWIncremented) tryCompleteDelayedRequests() debug(s"Recorded replica $followerId log end offset (LEO) position " + s"${followerFetchOffsetMetadata.messageOffset} and log start offset $followerStartOffset.") true case None => false } }