Java企业微信会话存档开发(从跳坑到爬坑)
Java企业微信会话存档开发(从跳坑到爬坑)
本文仅作为方便首次开发企业微信使用
文章目录
- Java企业微信会话存档开发(从跳坑到爬坑)
- 前言
- 一、开发准备
-
- 1.企业微信后台配置
- 2.sdk下载
- 3.开发环境说明
- 4.jar包引入
- 二、开发
-
- 1.关于原生开发和SpringBoot开发的说明(此处是大坑)
- 2.sdk的初始化
- 3.获取加密的数据
- 4.会话解密(这块是巨坑)
- 5.多类型的会话消息存储
- 三、部署
-
- 1.windows服务器
- 2.linux服务器
- 总结
前言
趁着刚开发完还没忘,写一写企业微信会话存档开发跳坑的“血泪史”。
官方虽然给了sdk的开发文档,但是并不是很细致,对刚接手的程序员并不是很友好。出bug后找客服回复也很慢,得到的有效回答也少。而且现在还基本都是机器回复去社区找,但是社区里也大部分都是跳了坑后面没写解决方案的。
总之,要摸索的地方很多很多,坑也很多很多,所以我认真想了想,还是应该写这篇文章。
一、开发准备
1.企业微信后台配置
大致流程如下:
1、进入企业微信后台管理
2、进入管理工具,选择会话内容存档
3、配置开启范围(决定是否能接收到会话)
4、配置可信IP地址(可以配置为开发电脑的ip,也可以不配置,不配制的时候是所有ip都可以使用,开发时建议不配置)
5、配置消息加密公钥,生成部分具体配置如图,红框位置必须选择RSA密钥对,2048位(bit),PKCS#1,然后把生成的公钥复制粘贴进去,私钥复制下来留在本地备用
(在这里提供一个秘钥生成的网址:http://web.chacuo.net/netrsakeypair)
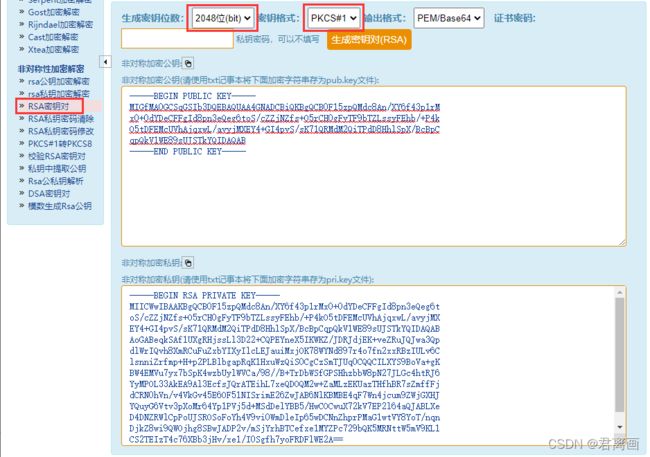
6、获取Secret,留存在本地备用
7、确认服务已开启,不然无法获得消息(此处是第一个坑,申请服务后会有一段时间的延迟,审批过后才可以点击开启服务,服务开启之前无法使用sdk)
2.sdk下载
这里没什么特别重要的,开发用哪个环境就下哪个,如果开发是windows,服务器是linux的情况需要两个都下载
3.开发环境说明
myeclipse、eclipse和idea均可
官方的原装包用的是eclipse,直接导入idea会乱码,建议eclipse导入打开后复制粘贴进idea
4.jar包引入
解密部分需要使用的jar包如下:
(附Maven库连接:https://mvnrepository.com/)

maven依赖:
<dependency>
<groupId>org.bouncycastlegroupId>
<artifactId>bcpg-jdk16artifactId>
<version>1.46version>
dependency>
<dependency>
<groupId>org.bouncycastlegroupId>
<artifactId>bcpkix-jdk15onartifactId>
<version>1.64version>
dependency>
<dependency>
<groupId>org.bouncycastlegroupId>
<artifactId>bcprov-jdk15onartifactId>
<version>1.64version>
dependency>
二、开发
1.关于原生开发和SpringBoot开发的说明(此处是大坑)
原生开发:
原生的Java开发可以直接将sdk放到项目的根目录下,直接使用,但是完成后打包无法将sdk的.dll文件打包进去,但是因为可以直接使用,开发时较为方便,但是如果要部署……(这坑暂时还没跳过,估计也挺折腾)
SpringBoot开发:
使用SpringBoot开发时,直接将sdk放入项目根目录仍会导致无法找到sdk文件,在这里我也尝试过各种将文件加入路径、将sdk打成jar包使用等操作,但是在打包和部署的时候均会产生问题。
建议不要将sdk的.dll文件直接放入项目。
最后的解决方法是:
如果使用Windows系统,则将sdk中的.dll文件直接放入C:\Windows\System32目录下,然后在环境变量的Path中添加该目录。
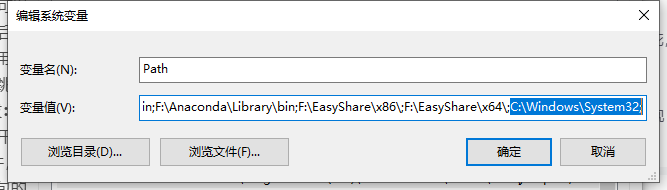
如果使用Linux系统,则需要配置LD_LIBRARY_PATH,具体配置方法会在部署章编写
此处是大坑
sdk中的Finace.java文件必须放入项目的com.tencent.wework目录下!!!!!!
sdk中的Finace.java文件必须放入项目的com.tencent.wework目录下!!!!!!
sdk中的Finace.java文件必须放入项目的com.tencent.wework目录下!!!!!!
重要的话说三遍!
这个坑无论是原生开发还是SpringBoot都需要注意!
2.sdk的初始化
初始化之前需要修改Finace方法,在其中添加一个静态变量
static {
System.loadLibrary("WeWorkFinanceSdk");
}
代码块添加后可以动态从环境变量中获取到sdk
sdk中的初始化方法:
/**
* 初始化函数
* Return值=0表示该API调用成功
*
* @param [in] sdk NewSdk返回的sdk指针
* @param [in] corpid 调用企业的企业id,例如:wwd08c8exxxx5ab44d,可以在企业微信管理端--我的企业--企业信息查看
* @param [in] secret 聊天内容存档的Secret,可以在企业微信管理端--管理工具--聊天内容存档查看
*
* @return 返回是否初始化成功
* 0 - 成功
* !=0 - 失败
*/
public native static int Init(long sdk, String corpid, String secret);
调用(corpid, secret两个参数根据方法的提示填写):
long sdk = Finance.NewSdk();
int reqInit = Finance.Init(sdk, corpid, secret);
if(reqInit != 0){
System.out.println("初始化错误,代码:"+reqInit);
return 0;
}else{
return sdk;
}
此处初始化的sdk需保存下来,后续需要一直使用,多线程操作的话每一个线程需要单独初始化一个sdk
3.获取加密的数据
需要将sdk以及当前已存档消息最大的seq传入sdk,如还未进行存储,则seq可以为0
//接收传回数据
long reqgetchatdata = 0;
//从指定的seq开始拉取消息,注意的是返回的消息从seq+1开始返回,seq为之前接口返回的最大seq值。首次使用请使用seq:0
int seq = (int) nowSeq;
//设置拉取数量
int limit = 100;
//设置结构体
long slice = Finance.NewSlice();
//调取接口获取基础数据
reqgetchatdata = Finance.GetChatData(sdk, seq, limit, null, null, 10, slice);
if (reqgetchatdata != 0) {
System.out.println("获取会话记录数据错误,代码:" + reqgetchatdata);
return null;
} else {
//提取拉取到的信息
String getChatData = Finance.GetContentFromSlice(slice);
}
4.会话解密(这块是巨坑)
在这块找过很多解密的方法,也看过很多别人的开发文档,出现过解密之后乱码的问题,最后找到能解决所有问题的是定义类RSAEncrypt做加解密处理,代码如下(此处转载参考原文:https://blog.csdn.net/qq_42851002/article/details/119460215)
package com.tencent.wework;
import org.apache.commons.codec.binary.Base64;
import org.bouncycastle.openssl.PEMKeyPair;
import org.bouncycastle.openssl.PEMParser;
import org.bouncycastle.openssl.jcajce.JcaPEMKeyConverter;
import javax.crypto.Cipher;
import java.io.Reader;
import java.io.StringReader;
import java.security.*;
public class RSAEncrypt {
public static String decryptRSA(String str, String privateKey) throws Exception {
Security.addProvider(new org.bouncycastle.jce.provider.BouncyCastleProvider());
//此处的"RSA/ECB/PKCS1Padding", "BC"不可以改变,改变会导致解密乱码
Cipher rsa = Cipher.getInstance("RSA/ECB/PKCS1Padding", "BC");
rsa.init(Cipher.DECRYPT_MODE, getPrivateKey(privateKey));
byte[] utf8 = rsa.doFinal(Base64.decodeBase64(str));
String result = new String(utf8,"UTF-8");
return result;
}
public static PrivateKey getPrivateKey (String privateKey) throws Exception {
Reader privateKeyReader = new StringReader(privateKey);
PEMParser privatePemParser = new PEMParser(privateKeyReader);
Object privateObject = privatePemParser.readObject();
if (privateObject instanceof PEMKeyPair) {
PEMKeyPair pemKeyPair = (PEMKeyPair) privateObject;
JcaPEMKeyConverter converter = new JcaPEMKeyConverter().setProvider("BC");
PrivateKey privKey = converter.getPrivateKey(pemKeyPair.getPrivateKeyInfo());
return privKey;
}
return null;
}
}
————————————————
版权声明:本文为CSDN博主「Lrfun_com」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_42851002/article/details/119460215
解密中,decryptRSA方法中的Cipher rsa = Cipher.getInstance(“RSA/ECB/PKCS1Padding”, “BC”);语句中括号部分一定不能替换,替换会导致解密乱码。
大坑:在开发过程中也出现过用这个解密方式依然出现乱码,联系客服后莫名其妙的好了,而我方代码并没有进行过修改,这个怀疑一下是他们的bug。
这里是第一重解密,解密后需要使用decryptRSA返回的初步解密内容,再次调用sdk获取明文数据
long msg = Finance.NewSlice();
//调用方法解密
String message = RSAEncrypt.decryptRSA(encryptRandomKey, DataStatic.priKey);
//调用sdk获取明文数据
Finance.DecryptData(sdk, message, encryptChatMsg, msg);
//提取获得的msg部分,plaintext为获取到的明文数据
String plaintext = Finance.GetContentFromSlice(msg);
System.out.println("获取明文数据:" + plaintext);
//释放FreeSlice
Finance.FreeSlice(msg);
此处传入sdk获取数据中的encryptChatMsg为之前加密数据中的encryptChatMsg,如果分服务编写代码需要注意传参
5.多类型的会话消息存储
获取到的明文消息中,提取msgtype可获得消息类别,可分为文本消息和其他消息(媒体消息)进行分类处理
文本消息–判定语句为:“text”.equals(msgType)
文本消息存储较为简单,直接进行拆分消息存储即可
我的处理方法是建立了一个对应的实体类,传入mapper层存储数据
Text text = new Text();
JSONObject plaintextJson = new JSONObject(plaintext);
//消息发送人的特殊处理
String msgFromId = plaintextJson.getString("from");
String msgFrom = null;
if (msgFromId.indexOf("wm") == 0) {
msgFrom = FindName.FindNameFromClient(msgFromId);
} else if (msgFromId.indexOf("wo") == 0 ) {
msgFrom = msgFromId;
} else{
msgFrom = FindName.FindNameFromIside(msgFromId);
}
try{
String roomId = plaintextJson.getString("roomid");
if(roomId.length() > 1){
//消息来自群(存储)
text.setMsgGroup(FindName.FindGroup(roomId));
}
}catch(Exception e){
e.printStackTrace();
}
//消息唯一id(存储)
text.setSeq(reqSeq);
//消息来源userid(存储)
text.setMsgId(plaintextJson.getString("msgid"));
//消息发送人(存储)
text.setMsgFrom(msgFrom);
//消息接收人(存储)
text.setMsgTo(MsgGet.MsgToName(plaintext));
//消息时间戳(存储)
text.setMsgTime(plaintextJson.getLong("msgtime"));
//消息文本内容(存储)
text.setMsgText(MsgGet.MsgGetContent(plaintext));
//拉入存储
weChatMapper.insertText(text);
媒体消息–直接写了else
存储部分和文本一致,有区别的是在消息拉取,具体代码如下:
如有错误可以参考文档:https://blog.csdn.net/qq_42851002/article/details/119460215
private String pullMediaFiles(long sdk, String msgtype, JSONObject plaintextJson) {
String[] msgtypeStr = {"image", "voice", "video", "emotion", "file"};
List<String> msgtypeList = Arrays.asList(msgtypeStr);
if (msgtypeList.contains(msgtype)) {
String savefileName = "";
JSONObject file = new JSONObject();
if (!plaintextJson.isNull("msgid")) {
file = plaintextJson.getJSONObject(msgtype);
savefileName = plaintextJson.getString("msgid");
} else {
// 混合消息
file = plaintextJson;
savefileName = file.getString("md5sum");
}
System.out.println("媒体文件信息:" + file);
/* ============ 文件存储目录及文件名 Start ============ */
String suffix = "";
switch (msgtype) {
case "image" : suffix = ".jpg"; break;
case "voice" : suffix = ".amr"; break;
case "video" : suffix = ".mp4"; break;
case "emotion" :
int type = (int) file.get("type");
if (type == 1){
suffix = ".gif";
}else if (type == 2) {
suffix = ".png";
}
break;
case "file" :
suffix = "." + file.getString("fileext");
break;
}
savefileName += suffix;
String path = "../resources/media/";
String savefile = path + savefileName;
File targetFile = new File(savefile);
if (!targetFile.getParentFile().exists()) {
//创建父级文件路径
targetFile.getParentFile().mkdirs();
}
/* ============ 文件存储目录及文件名 End ============ */
/* ============ 拉去文件 Start ============ */
int i = 0; boolean isSave = true;
String indexbuf = "", sdkfileid = file.getString("sdkfileid");
while (true) {
long mediaData = Finance.NewMediaData();
int ret = Finance.GetMediaData(sdk, indexbuf, sdkfileid, null, null, 3, mediaData);
if (ret != 0) {
System.out.println("getmediadata ret:" + ret);
Finance.FreeMediaData(mediaData);
return null;
}
try {
// 大于512k的文件会分片拉取,此处需要使用追加写,避免后面的分片覆盖之前的数据。
FileOutputStream outputStream = new FileOutputStream(new File(savefile), true);
outputStream.write(Finance.GetData(mediaData));
outputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
if (Finance.IsMediaDataFinish(mediaData) == 1) {
// 已经拉取完成最后一个分片
Finance.FreeMediaData(mediaData);
break;
} else {
// 获取下次拉取需要使用的indexbuf
indexbuf = Finance.GetOutIndexBuf(mediaData);
Finance.FreeMediaData(mediaData);
}
// 若文件大于50M则不保存
// if (++i > 100) {
// isSave = false;
// break;
// }
}
/* ============ 拉去文件 End ============ */
if (isSave) {
file.put("sdkfileid", savefile);
}
}
}
此处仍然有坑……消息接收人、发送人会出现wm和wo开头的编号,其中wm开头的可以调用企业客户接口获取,wo开头用户为其他企业的企业微信用户,若未加好有则无法调取信息,需要单独进行判定
企业客户调用例子:
String req = HttpClientToInterface.doGet("https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=这里填写自己公司的corpid&corpsecret=这里填写客户联系的api秘钥", "UTF-8");
JSONObject jo = JSON.parseObject(req);
//提取传回Json中的chatdata中内容
String access_token = jo.getString("access_token");
String req2 = HttpClientToInterface.doGet("https://qyapi.weixin.qq.com/cgi-bin/externalcontact/get?access_token=" +access_token+"&external_userid="+ userid, "UTF-8");
JSONObject jo2 = JSON.parseObject(req2);
if((jo2.getInteger("errcode")).equals(0)){
String jsonname = jo2.getString("external_contact");
JSONObject jo3 = JSON.parseObject(jsonname);
String clientname = jo3.getString("name");
return clientname;
}else{
return userid;
}
企业内部用户(员工)调取方法相同,只是corpsecret需要修改为内部联系的api秘钥,第二次get请求更换为https://qyapi.weixin.qq.com/cgi-bin/user/get?access_token=,后面不变。
群名称同理,区分内部群和外部群,调用方法一致,在此不过多赘述。
api部分具体可以参考api文档,虽然说sdk一言难尽吧,但是api还是可以用的,主要就是注意api秘钥的权限,这个可以根据调试反馈的错误代码和提供的网址进行查找修改。
接口文档https://developer.work.weixin.qq.com/document/path/91774
到此,开发的坑基本都跳完了
感动吗,接下来是部署坑了
三、部署
1.windows服务器
sdk摆放方法和开发时相同,这里就不重复写了,疑惑的话就去看看前面,其他部署方式和正常项目一样,你甚至可以直接迁移开发环境上去用,这里基本没坑,就如果要求是只能使用这台服务器读取消息的话,在后台里设置一下ip白名单就好了。
2.linux服务器
同windows,把包放在项目中会出现打包不进去的问题,或部署后无法调用sdk包的问题,在这里仍然推荐单独部署sdk。
先将 libWeWorkFinanceSdk_Java.so文件上传到服务器上自己创建的lib目录下,也可以使用系统的lib,但是不推荐(容易找不着),然后再linux环境启动项目时增加启动命令:
-Djava.library.path=这里填写文件保存的目录
(如果配置到全局环境变量中也可以不增加启动命令)
这种办法可以参考链接https://www.pudn.com/news/625e86708cbeb85d5722c955.html
也可以直接配置LD_LIBRARY_PATH环境变量
export LD_LIBRARY_PATH=这里填写文件保存的目录 :$LD_LIBRARY_PATH
export LIBRARY_PATH=这里填写文件保存的目录 :$LIBRARY_PATH
可以参考链接https://blog.csdn.net/jc15988821760/article/details/104991468/
总结
到此基本是写完了,如果有发现后续的其他问题会再次更新。
最后吧……希望某厂能优化一下sdk的开发文档及各种bug的解决方法,希望客服能不要每次都在打太极、说废话,我要是真解决了我是不会找客服的,真的。
以下是开发时参考过的各个文档:
https://blog.csdn.net/qq_42851002/article/details/119460215
https://blog.csdn.net/weixin_42932323/article/details/118326236
https://blog.csdn.net/u011056339/article/details/105704995
https://www.pudn.com/news/625e86708cbeb85d5722c955.html
https://blog.csdn.net/jc15988821760/article/details/104991468