三剑客--awk
awk介绍
AWK是一个强大的文本分析工具。它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描、过滤、统计汇总工作;数据可以来自标准输入也可以是管道或文件
工作原理
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令
awk执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符"&&“表示"与”、“|表示"或”、"!“表示非” ;还可以进行简单的数学运算,如+、一、*、/、号、^分别表示加、减、乘、除、取余和乘方。
awk命令格式
awk 选项 模式或条件{操作} 文件1 文件2...
awk -f 脚本文件 文件1 文件2 ..
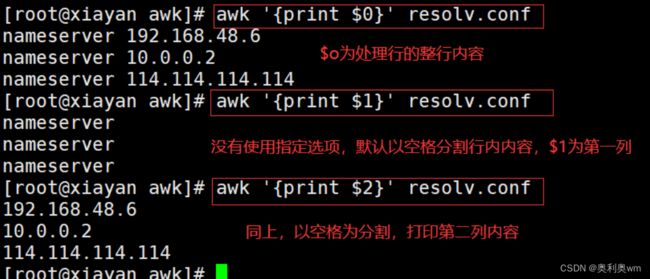
awk常规用法
指定分隔符
常用命令操作:awk -F +分隔符 ‘{print 参数位置}’ +文件名

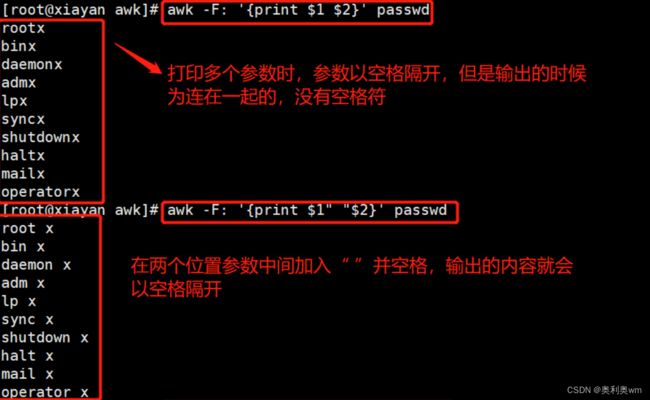
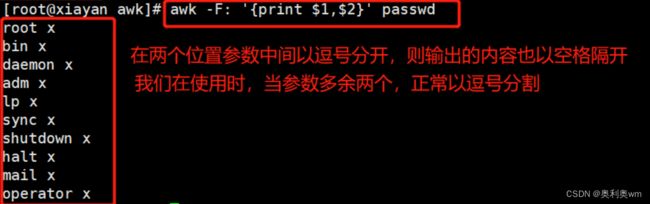
指定多个分隔符
-F指定分隔符,那么有的时候 我们需要指定多个分隔符
awk -F[abc] '{print 位置参数}' +文件 #中括号内可以指定多个分隔符、
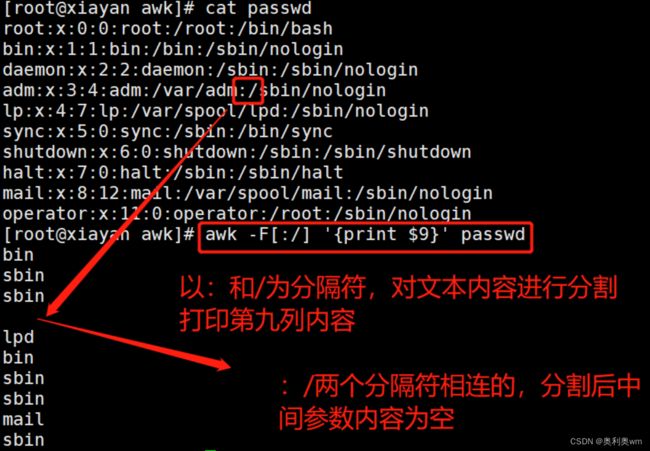
awk常用位置变量
$1:代表第一列
$2:代表第二列以此类推
$0:代表整行
NF:一行的列数
NR:行
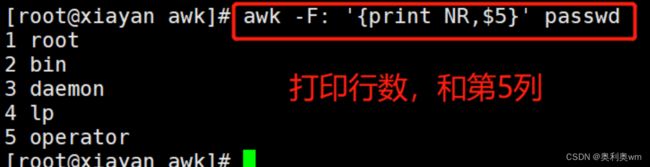

awk指定行
当我们使用awk时,可能我们只需要文本中的某一行内的一个字段,该如何索取?
awk -F: 'NR==2{print $n}' +文件 #指定处理第二行内容并输出第N列
或
awk -F: '/关键词/{print $n}' +文件 #指定包含关键词的行,并输出第N列、
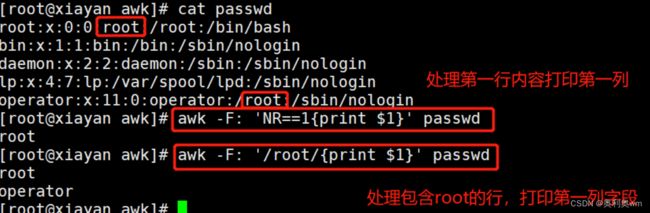
使用awk获取本机IP地址,有时awk比使用grep更加方便
ifconfig ens33|awk '/netmask/{print $2}'
ifconfig ens33|grep netmask |awk '{print $2}'
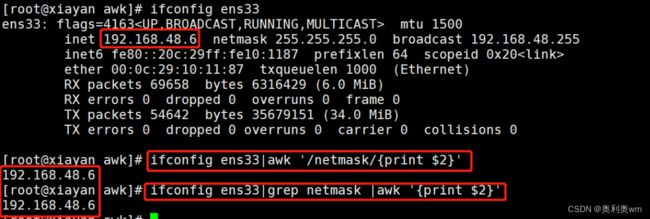
使用awk获取网卡流量信息
ifconfig ens33|awk '/RX packets/{print $5}'
![]()
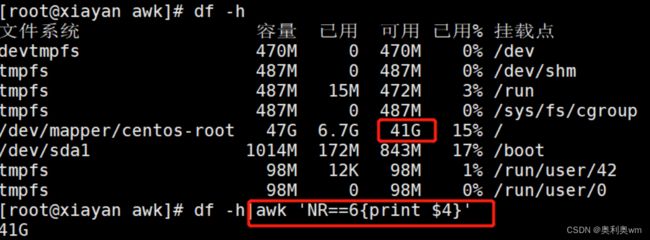
使用awk获取硬盘使用情况
df -h|awk 'NR==6{print $4}'
模糊匹配
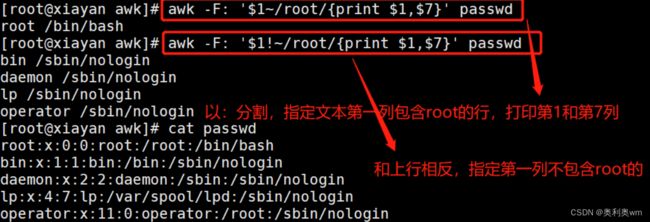
awk -F: '$1~/root/' passwd #$1~/关键词/第一列包含关键词
awk -F: '$1!~/root/' passwd #!取反,第一列不包含关键词的行
awk内的运算符
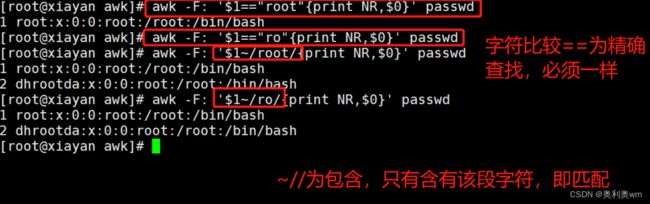
数值比较
== 等于
!= 不等于
<= 小于或等于
>= 大于或等于
> 大于
< 小于
awk中的内置变量NR表示行数


字符比较

字符比较与模糊匹配不同
逻辑运算
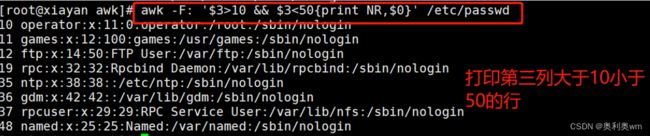
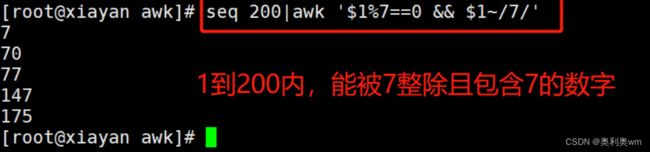
awk命令支持逻辑操作符" &&“表示"与”、“||表示"或”、"!“表示非”

BEGIN与END
BEGIN和END的作用是给程序赋予初始状态和在程序结束之后执行一些扫尾的工作。
任何在BEGIN之后列出的操作(在{}内)将在awk开始扫描输入之前执行,而END之后列出的操作将在扫描完全部的输入之后执行。因此,通常使用BEGIN来显示变量和预置(初始化)变量,使用END来输出最终结果。
awk命令执行流程:
常用内置变量:
FS:输入字段的分隔符,默认是空格
OFS:输出字段的分隔符,默认是空格
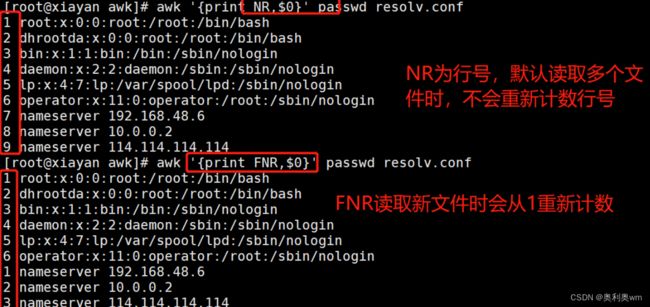
FNR:读取文件的行号,从1开始,新的文件也重1开始计数
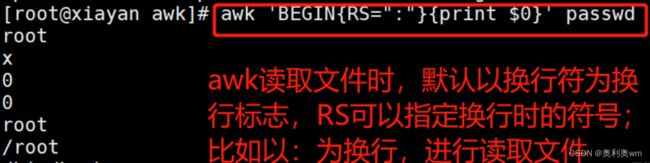
RS:输入行分隔符,默认为换行符
ORS:输出行分隔符,默认也是为换行符
BEGIN
FS=“”指定分隔符,与-F 选项相同
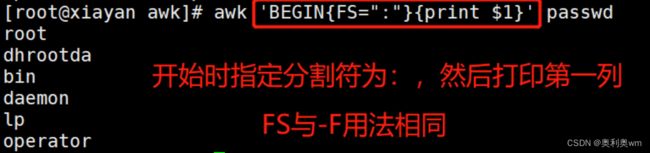
OFS=“”输出字段时,相邻字段以什么做分割

FNR读取文件时的行号,当读取多个文件时,将重新计数
RS:输入时指定以什么为换行符
ORS:把打进的内容合并成一行,输出时以指定的分割符为分割两行的内容

END
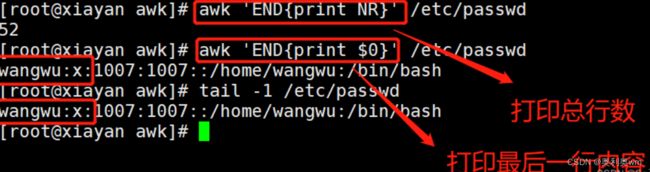
END一般用来做汇总操作,仅在读取完数据记录之后执行一次
总结
1.相比grep与sed,awk的功能明显更加的强大,我们可以获取文本中我们所想要的相关内容
2.awk支持数值运算符,逻辑操作
3.awk的内置变量,通过BEGIN模块,在分析文本数据时更加的方便
4.注意在使用print打印多个字段时,建议使用逗号分割,awk后的命令使用’'单分号