【计算机视觉】Vision Transformer (ViT)详细解析
【计算机视觉】Vision Transformer (ViT)详细解析
文章目录
- 【计算机视觉】Vision Transformer (ViT)详细解析
-
- 1. 介绍
- 2. VIT 模型
-
- 2.1 图像分块处理 (make patches)
- 2.2 图像块嵌入与位置编码
-
- 2.2.1 图像块嵌入 (patch embedding)
- 2.2.2 位置编码 (position encoding)
- 2.3 Transformer Encoder(编码器)
- 2.4 MLP Head(全连接头)
- 2.5 全过程维度变化
- 3. ViT 模型结构细节图
-
- 3.1 ViT-B/16
- 3.2 ViT--Hybrid 模型
- 4. 实验
-
- 4.1 ViT 训练
- 4.2 ViT 实验 1—预训练数据集 和 大模型
- 4.3 ViT 实验 2—Hybrid 和 纯 ViT
- 参考
1. 介绍
论文地址:An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
code地址:github.com/google-research/vision_transformer
Transformer 最早提出是针对NLP领域的,并且在NLP领域引起了强烈的轰动。
- 提出ViT模型的这篇文章题名为 《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》,发表于2020年10月份;
- 虽然相较于一些Transformer的视觉任务应用模型 (如DETR) 提出要晚了一些,但作为一个纯Transformer结构的视觉分类网络,其工作还是有较大的开创性意义的。
- 关于Transformer的部分理论之前的博文中有讲 Transformer 结构细节理论解析。
- 这篇文章实验中,给出的最佳 vit 模型(先在Google的JFT数据集上进行了预训练)然后在ImageNet1K(finetune)上能够达到88.55%的准确率,说明Transformer在CV领域确实是有效的,而且效果还挺惊人。

2. VIT 模型
ViT的核心流程包括:
- 图像分块处理 (make patches)
- 图像块嵌入 (patch embedding)与位置编码、
- Transformer编码器
- MLP分类处理等4个主要部分。
下面分别从这四个流程部分来阐述ViT的基本设计。
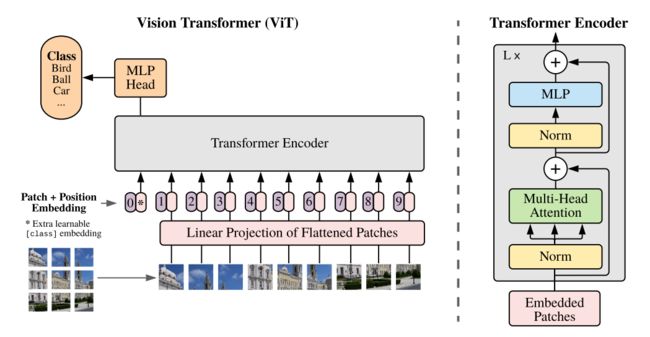
2.1 图像分块处理 (make patches)
第一步可以看作是一个图像预处理步骤。
- 在CNN中,直接对图像进行二维卷积处理即可,不需要特殊的预处理流程。
- 但Transformer结构不能直接处理图像,在此之前需要对其进行分块处理。(序列化)
假设一个图像 I ∈ H × W × C I∈H×W×C I∈H×W×C,
- 现在将其分成大小为 P × P × C 的 p a t c h e s P×P×C 的patches P×P×C的patches,那么就会有 N = H W P 2 N= \frac{HW}{P^2} N=P2HW 个patches,全部patches的维度就可以写为 N × P × P × C N×P×P×C N×P×P×C。
- 然后将每个patch进行展平,相应的数据维度就可以写为 N × ( P 2 × C ) N×(P^2×C) N×(P2×C),也就是shape变成了( N , P 2 × C N, P^2×C N,P2×C)。
这里 N N N 可以理解为输入到Transformer的序列长度, C C C 为输入图像的通道数, P P P 为图像patch的大小。(这样也就符合了transformer的输入)
2.2 图像块嵌入与位置编码
2.2.1 图像块嵌入 (patch embedding)
2.1 中的图像分块仅仅是一道预处理流程,要将 N × ( P 2 × C ) N×(P^2×C) N×(P2×C) 的向量维度,转化为N×D大小的二维输入,还需要做一个图像块嵌入的操作。
- 类似NLP中的词嵌入,块嵌入也是一种将高维向量转化为低维向量的方式。
所谓图像块嵌入,其实就是对每一个展平后的 patch 向量做一个线性变换,即全连接层,降维后的维度为D。
![]()
上式中的 E E E 即为块嵌入的全连接层,其输入大小为 P 2 × C P^2×C P2×C(一维),输出大小为D(也是一维)。
- 值得注意的是,上式中给长度为 N N N 的向量还追加了一个分类向量,用于Transformer训练过程中的类别信息学习。
- 假设将图像分为 9个patch,即 N=9,输入到Transformer编码器中就有9个向量,但对于这9个向量而言,该取哪一个向量做分类预测呢?取哪一个都不合适。
- 一个合理的做法就是人为添加一个类别向量,该向量是可学习的嵌入向量,与其他9个patch嵌入向量一起输入到Transformer编码器中,最后取第一个向量作为类别预测结果。
- 所以,这个追加的向量可以理解为其他9个图像patch寻找的类别信息。
2.2.2 位置编码 (position encoding)
为了保持输入图像patch之间的空间位置信息,还需要对图像块嵌入中添加一个位置编码向量,如上式中的 E p o s E_{pos} Epos 所示。
- ViT的位置编码没有使用更新的2D位置嵌入方法,而是直接用的一维可学习的位置嵌入变量,
- 原因是论文作者发现实际使用时2D并没有展现出比1D更好的效果。

2.3 Transformer Encoder(编码器)
Vit中所使用的Transformer 编码器结构和原文《Attention is all you need》中的一致,理论细节可以参考Transformer 详解。
- 主要还是使用了多头注意力机制;
- 另外,不像nlp领域中的翻译任务,vit 没有利用解码器的结构。
Transformer Encoder 其实就是重复堆叠 Encoder Block L次,下图是绘制的Encoder Block,主要由以下几部分组成:
- Layer Norm,这种Normalization方法主要是针对NLP领域提出的,这里是对每个token进行Norm处理,之前也有讲过Layer Norm不懂的可以参考LRN,BN,LN, IN, GN, FRN, WN, BRN, CBN, CmBN 详解
- Multi-Head Attention,这个结构之前在讲Transformer中很详细的讲过,不在赘述,不了解的可以参考 Transformer 详解。
- Dropout/DropPath,在原论文的代码中是直接使用的Dropout层,在但rwightman实现的代码中使用的是DropPath(stochastic depth),可能后者会更好一点。
- MLP Block,如右图所示,就是全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]。

2.4 MLP Head(全连接头)
上面通过Transformer Encoder 后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。
- 注意,在Transformer Encoder后其实还有一个Layer Norm没有画出来,后面有细画的 ViT 的模型可以看到详细结构。
- 这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出 [class]token(也就是添加的分类向量) 对应的[1, 768]。
- 接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。
- 但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
2.5 全过程维度变化
为了更加清晰的展示ViT模型结构和训练过程中的向量变化,下图给出了ViT的向量维度变化图(图来自于极市平台)。

3. ViT 模型结构细节图
3.1 ViT-B/16
为了方便大家理解,太阳花的小绿豆 根据源代码画了张更详细的图 (以ViT-B/16为例):

3.2 ViT–Hybrid 模型
在论文4.1章节的Model Variants中有比较详细的讲到 Hybrid混合模型,
- 就是将传统CNN特征提取和Transformer进行结合。
下图 太阳花的小绿豆 绘制的是以ResNet50作为特征提取器的混合模型,但这里的Resnet与之前讲的Resnet有些不同。
- 首先这里的R50的卷积层采用的StdConv2d不是传统的Conv2d,然后将所有的BatchNorm层替换成GroupNorm层。
- 在原Resnet50网络中,stage1重复堆叠3次,stage2重复堆叠4次,stage3重复堆叠6次,stage4重复堆叠3次,但在这里的R50中,把stage4中的3个Block移至stage3中,所以stage3中共重复堆叠9次。
通过R50 Backbone进行特征提取后,得到的特征矩阵shape是[14, 14, 1024],接着再输入Patch Embedding层,注意Patch Embedding中卷积层Conv2d的kernel_size和stride都变成了1,只是用来调整channel。后面的部分和前面ViT中讲的完全一样,就不在赘述。

4. 实验
4.1 ViT 训练
1)ViT的基本训练策略是:
- 在大数据集上先做预训练,
- 然后在小数据集上做迁移使用。
2)ViT做预训练使用到的大数据集包括:
- ILSVRC-2012 ImageNet dataset:1000 classes
- ImageNet-21k:21k classes
- JFT:18k High Resolution Images
其中JFT是一个谷歌的内部大规模图像数据集,约有300M图像18291个类别标注。
3)ViT预训练迁移到的数据集包括:
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
- VTAB
- ImageNet
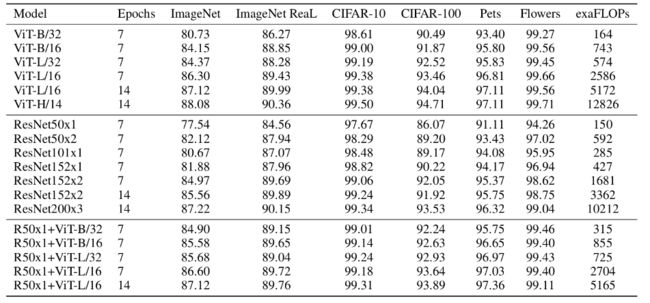
4)论文共设计了Base、Large和Huge三款不同大小的ViT模型,分别表示基础模型、大模型和超大模型,三款模型的各参数如下表所示。在源码中除了有Patch Size为16x16的外还有32x32的。
- 其中的 Layers就是Transformer Encoder中重复堆叠Encoder Block的次数,
- Hidden Size就是对应通过Embedding层后每个token的dim(向量的长度),
- MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的四倍),
- Heads代表Transformer中Multi-Head Attention的heads数。

注:若为ViT-B/16 就表示patch size为16的 ViT-Base模型。
4.2 ViT 实验 1—预训练数据集 和 大模型
ViT最核心的实验就是将前述的训练方法进行实现,
- 即在大规模数据集上预训练后迁移到小数据集上看模型效果。
为了比对CNN模型,
- 论文特地用了Big Transfer (BiT),该模型使用大的ResNet进行监督迁移学习,是2020 ECCV上提出的一个大CNN模型。
- 另外一个比对CNN模型是2020年CVPR上的Noisy Student模型,是一个半监督的大型CNN模型。
ViT、BiT 和 Nosiy Student 模型经三大数据集预训练后在各小数据集上的准确率如下表所示。

从表中可以看到,ViT经过大数据集的预训练后,
- 在各小数据集上的迁移后准确率超过了一些SOTA CNN模型的结果。
- 但要取得这种超越CNN的性能效果,需要大的预训练数据集和大模型的结合。
问题:所以接下来的问题就是 ViT 对预训练数据集规模到底有怎样的要求?
论文针对此问题做了一个对比实验。分别在ImageNet、ImageNet-21k和JFT-300M进行预训练,三个数据集规模分别为小数据集、中等规模数据集和超大数据集,预训练效果如下图所示。

从图中可以看到,
- 在最小的数据集ImageNet上进行预训练时,尽管作者加了大量的正则化操作,ViT-Large模型性能不如ViT-base模型,更远不如BiT的性能。
- 在中等规模的ImageNet-21k数据集上,大家的表现都差不多,
- 只有到了JFT-30M这样的超大数据集上,ViT模型才能发挥出它的优势和效果。
总之,大的预训练数据集加上大模型,是ViT取得SOTA性能的关键因素。
4.3 ViT 实验 2—Hybrid 和 纯 ViT
下表是论文用来对比ViT,Resnet(和刚刚讲的一样,使用的卷积层和Norm层都进行了修改)以及Hybrid模型的效果。通过对比发现,在训练epoch较少时Hybrid优于ViT,但当epoch增大后ViT优于Hybrid。
参考
【1】https://blog.csdn.net/weixin_37737254/article/details/117639395
【2】https://blog.csdn.net/qq_37541097/article/details/118242600