AWS云计算技术架构探索系列之四-存储
一、前言
目前主流的三种数据存储类型,包括文件存储,对象存储以及块存储。
文件存储,是最常用的存储类型,以文件的形式存放数据,能将所有的目录、文件形成一个有层次的树形结构来管理。存储协议主要是NFS、CIFS等,能够支持成百上千的用户进行访问并上传下载文件,共享非常方便。一般用于视频,影像等文件的存储,以及大数据的HDFS存储等。AWS的EFS就是文件存储服务。
块存储,通常是裸盘(未格式化的硬盘)的形式,逻辑硬盘上有很多固定大小的数据分区,按照字节来存储和访问。块存储是“高度结构化的”,因为每个数据块都排列在结构化的固定块中,其存储于效率非常高。无论文件存储还是对象存储,最终都是通过底层的块存储实现存储。快存储虽然高效,但是成本高,无法直接数据共享,磁盘,磁盘阵列都是典型的块存储设备。AWS的EBS就是分布式块存储服务。
对象存储,与文件存储的有层次的树型结构不同,对象存储是平面化的。对象数据包括元数据以及对象本身,通过对象ID实现对象本身数据的索引和访问,这种方式具有极高的可伸缩性和可靠性。对象(Object)放置在桶(Bucket),桶就是百宝箱,万花筒,可以支持文件,视频,图片等不同类型的对象,且对象的大小理论上没有限制。大名鼎鼎的AWS S3就是对象存储服务。
接下来,我们来介绍AWS的三种存储。
二、EFS
EFS(Amazon Elastic File System)是 基于 Linux 的工作负载提供简单、可扩展的弹性文件系统,可与 AWS 云服务和本地资源配合使用。具有以下几个特点:
- 文件存储,支持网络文件系统版本 4(NFSv4.1 和 NFSv4.0)协议,可以在数千个计算实例之间共享文件。
- 扩展性,可以自动将数据容量从GB级扩展到PB级,而无需预置容量。
- 可用性,对于标准型存储类,数据在多个可用区中冗余;对于单个区域存储类,数据在单个可用区冗余。
- 吞吐量,吞吐量随着文件系统规模的扩大而增加,并具备突增功能,以支持短时间内需要较高的吞吐量场景。其基准为每 TB 50MB/s,所有文件系统(无论大小)均可以突增至 100MB/s。
- 安全性,使用 VPC 安全组来控制进出文件系统的网络流量,使用IAM策略控制哪些 EC2 实例可以访问您的文件系统。同时,使用KMS加密对EFS的静态数据加密,同时TLS可以确保数据传输的过程中安全。
1、EFS的创建
EFS文件系统的创建分为文件系统设置,网络访问,文件系统策略,审核等步骤。我们对其中重要设置进行介绍。
(1)存储类
EFS分为标准和单区存储类,标准存储类是在多个可用区中冗余数据,单区存储类是在单个可用区冗余数据,可用性方面对比标准存储类要差些,但是价格要便宜47%。用户可以根据文件的使用场景,选择合适的存储类。
对于以上两种类型,又可以进一步分为标准以及标准不频繁,单区以及单区不频繁四种类型。所谓不频繁类型,即访问频率比较低,对于一些冷数据特征比较明显的文件,可以使用该类型,降低存储成本。
(2)生命周期
可以自定义生命周期策略,实现标准型与标准不频繁型之间的切换,比如定义30天不访问,就移动到不频繁型存储,当需要访问时,再从不频繁型存储移动到标准 型,实现智能分层,在满足访问要求情况下,实现存储成本的最优。
(3)吞吐模式
吞吐模式有突发和预置两种,对于突发模式,其吞吐量随文件规模的扩大而增加,能承受短时间的负载的突增,基准的性能为每TB 50MB/s,可以突增到100MB/s,文件系统存储超过1TB可以突增至每TB 100MB/s。对于预置模式,其吞吐量与存储文件的大小无关,可以根据实际需求,配置固定的吞吐量。
(4)挂载目标
文件系统最终是要挂载到EC2上使用的,对于VPC,EFS可以在每个可用区创建一个挂载一个目标,并设置该目标的ip和安全组。
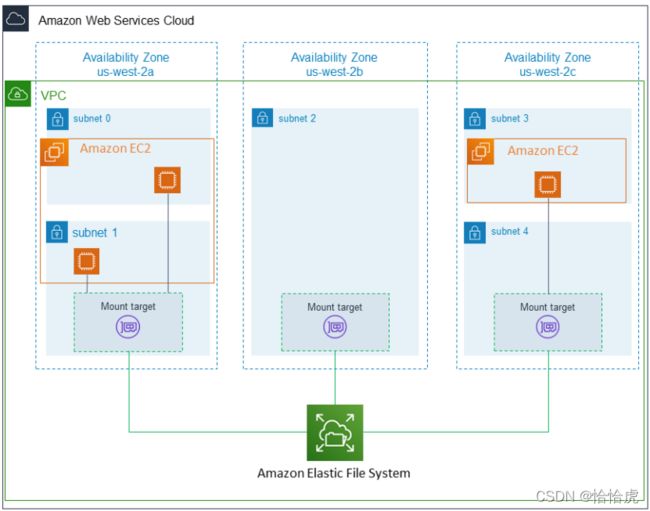
如图所示,EFS在每个可用区创建一个挂载目标(需要注意的是,即使一个可用区有多个子网,也只能创建一个挂载目标),EC2通过挂载本可用区的挂载目标,就可以访问EFS文件系统。
(5)文件系统策略
EFS支持基于身份的策略,以及基于资源的策略。本章安全性部分我们将详细介绍。
2、可用性
对于EFS的两种存储类型,标准存储类的文件系统,每个EFS文件系统对象均会在多个可用区冗余存储;单区存储类文件系统,数据将会在单个可用区中冗余。Amazon EFS 可以快速检测和修复任何丢失冗余,从而抵御同时发生的设备故障。
除了上述的数据冗余,还可以对EFS数据进行跨区域复制,以及备份。
(1)复制
EFS复制支持将文件系统数据复制到同一或者其他区域。启动复制后,EFS会自动在目标区域创建新的文件系统,开始时进行全量复制,一旦初始化复制完成,将更改为增量复制。
文件系统复制后,可以将灾难的恢复时间(RTO)降低到分钟级别。同时对于复制的文件系统可以设置独立的生命周期策略,挂载目标等,目标区域的ECS可以实现对这些只读副本的就近访问,降低跨区域访问的带来的网络延迟。
(2)备份
EFS创建时,默认启动自动备份,AWS的最佳实践建议使用AWS Backup进行有效的,定期测试的备份。
与复制类似,在初始备份期间,将创建整个文件系统的副本。在该文件系统的后续备份期间,只复制已更改、已添加或已删除的文件和目录,进行增量备份。
需要注意的是,有了复制,为何还需要备份呢?备份除了保护数据的安全,还可以指定恢复点进行还原,这是备份的优势所在。
3、安全性
对于存储系统来说,如何保护数据安全非常重要,EFS提供了完整的数据安全方案。总的来说,分为访问控制,以及数据加密两部分。
(1)访问控制
访问控制就是设置哪些服务可以访问和使用EFS的文件系统资源。前面介绍过,EFS支持基于身份的策略(IAM)以及基于资源的策略。
在AWS云计算技术架构探索系列之二-身份账户体系中我们详细介绍过这两种策略,通过策略的定义,就可以显示的描述谁(委托人)对于资源(文件系统)的特定权限(拒绝 or 允许)执行何种操作(读取,写入等),例如EC2实例对于特定的文件系统资源的只读访问。
除了文件系统的策略设置外,还可以为挂载目标指定安全组,定义流量规则,控制进出文件系统的网络流量。
(2)数据加密
EFS提供了静态加密和动态加密能力。
数据在静态时以透明的方式加密,在读取时以透明的方式解密,密钥由KMS托管。
动态数据是指数据在客户端与EFS文件之间之间数据传输时,使用行业标准传输层安全协议 (TLS) 1.2 来加密。
4、数据访问和传输
在混合云场景,经常需要从本地的服务器访问云上的EFS文件系统,以及本地和云上数据之间的移动。
对于本地访问,本地数据中心和 Amazon VPC 之间建立AWS Direct Connect 或 AWS VPN连接,使用标准 Linux 挂载命令将 Amazon EFS 文件系统挂载到您的本地 Linux 服务器。如下图所示。
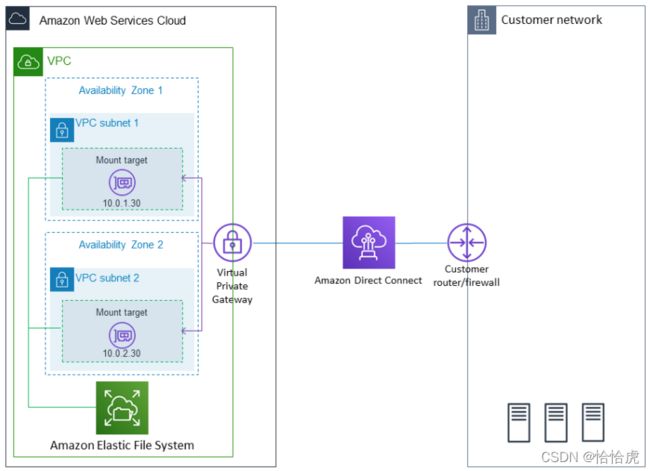
对于数据传输,AWS提供了DataSync在线传输服务,可以更快更简单地在本地存储与 Amazon EFS 之间移动数据。
三、EBS
EBS(Amazon Elastic Block Store)是AWS提供的块存储产品服务,AWS云计算技术架构探索系列之三-计算
中,也曾讲过EBS,它类似笔记本的外接硬盘或者U盘,挂载到EC2实例上,可以作为EC2的数据卷和引导卷,提供弹性存储能力。今天我们就一起来了解下EBS。
1、EBS的卷类型
我们知道硬盘可以分为SSD(固态硬盘)和HDD(机械硬盘)两种,EBS其实质就是硬盘,所以也有这两种类型,不过EBS又根据性能和吞吐量,进一步细分为七种卷类型,分别为:预置 IOPS SSD(io2 Block Express、io2 和 io1)、通用型 SSD(gp3 和 gp2)、吞吐量优化型 HDD (st1) 和 Cold HDD (sc1)。
关于卷类型的详情参数可以参考官网。这里我们总结下:
- 预置IOPS SSD的性能最强(IOPS,吞吐量,卷大小),又以io2 Block Express最优,当然价格也最贵,一般用于I/O 密集型关键业务数据库工作负载。
- 通用性SSD,性能次之,一般用于低延迟交互式应用程序的存储介质。
- 吞吐量优化型 HDD (st1) ,对于顺序写入的吞吐密集型的场景非常适合,价格也低于SSD,一般用于大数据,数仓,日志等。
- Cold HDD (sc1),适用于访问频率较低的场景,价格也是最低,一般用于冷数据或者归档数据的存储。
总体上,SSD类型的性能要优于HDD类型,但是价格更贵。另外需要注意一点,卷类型的选择和性能与其挂载的实例有很大的关系,比如io2 Block Express仅支持 R5b 实例。
2、快照
快照技术广泛应用于存储块的数据备份和恢复,类比在某一个时刻按下了快门,对卷上的数据打上了标记,根据这个标记进行数据的备份和回溯。
- 快照创建
EBS根据时间点,创建某个时刻的快照,然后将数据备份到S3中,当然也可以通过EBS的生命周期管理,创建快照的计划和策略,实现自动化快照。
快照的创建是可以在EBS的卷工作期间进行的,但是需要注意的,对于写入缓存还未flush到EBS卷的数据是无法捕获到的。所以,如果对于快照数据一致性要求高,建议先停止写入,或者断开卷与实例的连接,再进行快照,然后继续写入或者连接上。
创建快照,仅打个标记,与当前卷的数据量大小没有关系,但是对于快照存储的时间是有影响的。EBS的快照存储是增量模式,初始时是全量的,后续仅存储变化的增量数据。
- 快照共享
快照创建完成后,可以通过修改快照的权限,实现与公共账号或者其他的私有账号实现共享。需要注意的是,如果快照的数据是加密的,那么密钥也是要共享的,
- 快照还原
快照作为数据备份,其目的是数据出现故障或问题时,能进行数据复原。EBS可以指定快照数据进行还原,同时提供了快速快照功能(FSR),降低从快照还原到卷时数据访问的延迟,从而避免性能的下降。
3、数据安全
EBS卷创建时,选择了加密,那么在挂载到实例后,就会对其数据进行加密,包括:
- 卷中的静态数据
-
在卷和实例之间移动的所有数据
-
从卷创建的所有快照
-
从这些快照创建的所有卷
也就是说,从数据传输,数据静态存储,数据的快照,以及快照创建的卷都会加密。
由KMS托管默认密码或者用户自定义密钥,EC2与KMS结合,实现EBS数据的加密和解密。
四、S3
S3是AWS的最重要的产品之一,它以低成本,高扩展性,几乎可以存储任何数据,以及互联网直接访问的特性,获得了广泛的使用,S3也成为对象存储的事实标准。
在实际开发中,经常会遇到非结构化数据的存储和访问,比如用户头像,如没有使用S3,业务服务端一般是提供上传接口,将头像文件保存到文件系统,再提供访问接口,实现客户端的访问。采用S3对象存储后,头像的上传和访问都可以由S3搞定,业务服务端仅保存头像的S3对象链接地址即可。
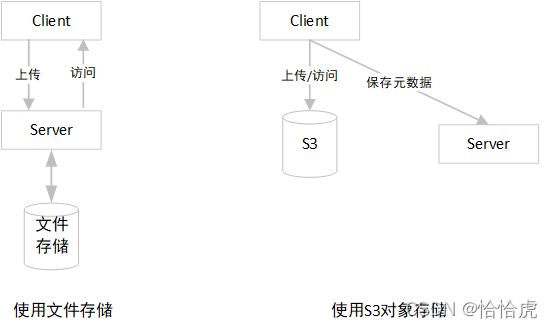
1、S3对象存储原理
S3存储首先有一个容器,称之为"桶"(bucket),然后就可以往这个桶里放置"对象"(Object),对象包含三个部分:key,Data,Metedata。
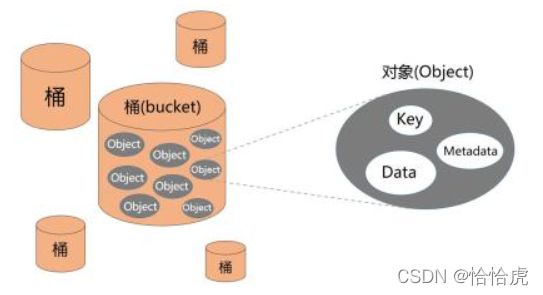
- Key
Key是存储桶中对象的唯一标识,存储桶内的每个对象都只能有一个键。存储桶、对象密钥和可选版本 ID 的组合(如果为存储桶启用了 S3 版本控制)唯一标识每个数据元。
将 Web 服务终端节点、存储段名、密钥和版本(可选)组合在一起,可唯一地寻址 Amazon S3 中的每个数据元。比如:

这个看上去类似url地址,如果访问权限设置为"公开"后,就可以使用该url访问对象了。
- Data
即对象的本体数据,没啥好说的。
- MeteData
对象的元数据,是由一组键值对,用来描述对象的相关信息,这些键值包括系统默认的元数据,如(如上次修改日期)和标准 HTTP 元数据(如 Content-Type),还支持用户自定义。
再来看下对象的存储架构:
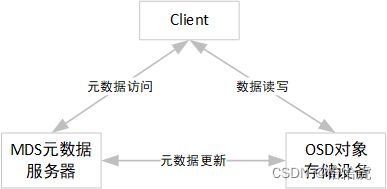
- MDS元数据服务器
主要控制Client和OSD的交互,还会管理着限额控制、目录和文件的创建与删除,以及访问控制权限。
- OSD对象存储设备
对象存储的核心,具有自己的CPU、内存、网络和磁盘系统。除了主要的存储数据功能,它还会利用自己的算力,优化数据分布,并且支持数据预读取,提升磁盘性能。
- Client客户端
提供文件系统接口,通常为POSIX文件系统接口,允许应用程序像执行标准的文件系统操作一样。
2、存储类
与EFS类似,S3也提供了多个存储类型,用户可以根据数据特点和场景,并综合成本,选择适合的类型。
存储类型的详细介绍可以参考AWS存储类
| 类型 | 描述 | 使用场景 |
| S3标准 | 主要针对频繁访问数据,较低的延迟和较高的吞吐量性能 | 一般用于云应用程序、动态网站、内容分配等场景 |
| S3智能分层(S3 Intelligent-Tiering) | 可以监控数据的使用频率,自动将数据移植到最经济实惠的访问层,分为频繁、不频繁和归档三个访问层。在满足访问频率的要求下,最大程度降低存储成本 | 一般用于数据湖、数据分析等场景 |
| S3标准,不频繁访问(S3 标准 - Infrequent Access(IA)) | 用于不常访问、但在需要时要求快速访问的数据 | 一般用于灾难恢复的数据存储 |
| S3单区,不频繁访问(S3 One Zone-IA) | 与S3-IA不同是,单区不频繁中数据仅保存在一个AZ,而前一个会保存到3个AZ,所以存储成本更低 | 一般用于数据的辅助副本 |
| S3 Glacier(现为S3 Glacier Flexible Retrieval) | 针对访问频率较低,不需要立即访问数据但需要灵活地免费检索大量数据的归档数据,其存储成本较低。一般适合每年访问1-2次,检索时间允许从数分钟到数小时不等的场景 | 一般备份或灾难恢复数据 |
| S3 Glacier即时检索( S3 Glacier Instant Retrieval) | 也是一种低成本的归档类存储,很少访问,但是需要能快速的检索,可达到毫秒级 | 一般适合于需要立即访问的归档数据,例如医学图像、新闻媒体资产 |
| S3深度归档(S3 Glacier Deep Archive) | 成本最低的存储类,支持每年可能访问一两次的数据的长期保留,其检索时间达到12小时内 | 一般用于金融服务、医疗保健和公共部门为满足监管要求,需要长期保留的数据(7-10年) |
3、数据安全
S3的对象可以开放互联网访问,所以数据安全是非常重要。与EFS类似,S3的数据安全也分为访问控制和数据加密。
(1)访问控制
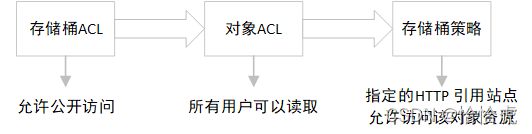
S3具有负载的访问控制策略,主要有IAM,ACL(存储桶以及对象),存储桶策略。其访问控制判断的顺序如下:

如上图所示,S3访问时,依次进行权限判断。
- IAM
IAM策略在AWS云计算技术架构探索系列之二-身份账户体系中介绍过,通过对IAM用户授权策略,可以对用户访问的存储桶以及对象做精细的权限控制。
- 存储桶ACL
存储桶ACL主要是设置存储桶的公开访问权限,默认情况下禁止所有的公开访问,如果该存储桶下的对象需要被互联网访问(即every one),那么这个需要放开限制。
- 对象ACL
针对存储桶下具体对象设置访问权限,只有对象的拥有者(AWS账户)具备该对象的读取权限,其他的账户必须通过授权才可以访问该对象。
- 存储桶策略
ACL主要还是针对用户维度做访问控制,存储桶策略是基于资源的策略,可以对于存储桶访问做更精细化的控制,比如指定访问的IP,特定 HTTP 引用站点,强制使用MFA功能等等。
存储桶的策略的示例可以参考:存储桶策略示例
访问一个S3对象,有这么多层判断,那策略冲突的情况下怎么办?
在AWS云计算技术架构探索系列之二-身份账户体系中介绍IAM策略时,提到最小权限原则,这里也是采用该原则,该原则的具体规则是:
- 如果某条规则显示拒绝,那么最终就是拒绝。
- 如果所有的规则测试完成,有规则显示允许,最终是允许的
- 即没有规则显示允许,也没有显示拒绝,那么最终是拒绝。
下面我们来举个例子说明下
我们的网站(www.myabc.com)引用了存储在S3的图片对象资源(abc.jpg),为了防止其他网站盗用这个图片资源,需要做防盗链控制。
- 存储桶ACL,图片对象资源所在的存储桶设置为允许公开访问。
- 对象ACL,图片对象资源设置为所有用户可以读取该对象。
- 存储桶策略,配置指定的HTTP 引用站点允许访问该对象资源,即www.myabc.com。
(2)数据加密
S3的数据加密可以分为服务端加密和客户端加密。
- 服务端加密
针对对象的加密和解密过程,都是在服务端进行。根据密钥的托管方式不同,又分为:
SSE-S3,密钥由S3托管,每个对象均使用唯一密钥加密。
SSE-KMS,密钥由KMS托管,可以通过KMS对密钥进行授权。
SSE-C,客户自己提供密钥。
- 客户端加密
使用客户端加密库,在客户端侧实现加密和解密,这样在互联网上传输的数据都是已经进过加密的了,对于密钥,可以客户端自己提供,也可以使用KMS托管。
4、复制
S3的数据默认会在单个AZ或者多个AZ冗余,实现高可用的持久化。S3也提供复制功能,业务可以根据场景进行选择。
跨区域复制(CRR),跨区域之间的复制,我们知道S3的对象是可以被互联网直接访问的,有时为了实现就近访问,减少延迟,可以将对象复制到多个区域,达到这一效果。
同区域复制(SRR),可在同一 AWS 区域内的存储桶之间自动复制数据,可以实现数据的备份,并且可以修改复制数据的账户所有权,以防数据意外删除。
主要注意的是,无论哪种复制,都需要开启版本控制。
S3在静态网站,日志分析,应用程序等存储方面有着广泛的应用,是AWS最核心的产品。
五、总结
本篇主要介绍了AWS的三种存储服务,文件存储EFS,块存储EBS,以及对象存储S3。下面我们用总结下三种存储的特点。
| S3 | EFS | EBS | |
| 存储类型 | 对象存储 | 文件存储 | 块存储 |
| 存储大小 | 没有限制 | 没有限制 | 16TB,64TB(io2 Block Express) |
| 单位文件大小限制 | 5TB | 最大52TB | 无限制 |
| IO吞吐量 | 支持multipart上传 如果使用single object upload,单个文件大小限制为5GB |
每 TB 50MB/s,可突增。也可以自定义预置吞吐量 | SDD类型要高于HDD类型,gp sdd能达到1,000 MiB/s,吞吐量优化型HDD500 MiB/s |
| 可用性 | 最大11个9 | 最大11个9 | 最大5个9 |
| 访问 | 互联网访问 | 可以被上千个EC2实例同时访问(通过挂载目标) | 只能被单个EC2实例访问 |
| 访问速度 | 慢 | 快 | 很快 |
| 价格 | 便宜 | 较贵 | 最贵 |
| 场景 | 任意格式和数量的数据,用于数据湖、网站、移动应用程序、备份和恢复、存档、企业应用程序、IoT 设备和大数据分析 | 大数据和分析、媒体处理工作流、内容管理、Web 服务和主目录 | 作为实例的引导卷和存储,卷适用于文件系统和数据库的主存储。 |
附件:
AWS云计算技术架构探索系列之一-开篇
AWS云计算技术架构探索系列之二-身份账户体系(IAM)
AWS云计算技术架构探索系列之三-计算
AWS云计算技术架构探索系列之四-存储
AWS云计算技术架构探索系列之五-网络
AWS云计算技术架构探索系列之六-数据库
AWS云计算技术架构探索系列之七-DevOps