基于LSTM的文本情感分析(Keras版)
一、前言
文本情感分析是自然语言处理中非常基本的任务,我们生活中有很多都是属于这一任务。比如购物网站的好评、差评,垃圾邮件过滤、垃圾短信过滤等。文本情感分析的实现方法也是多种多样的,可以使用传统的朴素贝叶斯、决策树,也可以使用基于深度学习的CNN、RNN等。本文使用IMDB电影评论数据集,基于RNN网络来实现文本情感分析。
二、数据处理
2.1 数据预览
首先需要下载对应的数据:http://ai.stanford.edu/~amaas/data/sentiment/。点击下图位置:
数据解压后得到下面的目录结构:
- aclImdb
- test
- neg
- pos
- labeledBow.feat
- urls_neg.txt
- urls_pos.txt
- train
- neg
- pos
这是一个电影影评数据集,neg中包含的评论是评分较低的评论,而pos中包含的是评分较高的评论。我们需要的数据分别是test里面的neg和pos,以及train里面的neg和pos(neg表示negative,pos表示positive)。下面我们开始处理。
2.2 导入模块
在开始写代码之前需要先导入相关模块:
import os
import re
import string
import numpy as np
from tensorflow.keras import layers
from tensorflow.keras.models import Model
我的环境是tensorflow2.7,部分版本的tensorflow导入方式如下:
from keras import layers
from keras.models import Model
可以根据自己环境自行替换。
2.3 数据读取
这里定义一个函数读取评论文件:
def load_data(data_dir=r'/home/zack/Files/datasets/aclImdb/train'):
"""
data_dir:train的目录或test的目录
输出:
X:评论的字符串列表
y:标签列表(0,1)
"""
classes = ['pos', 'neg']
X, y = [], []
for idx, cls in enumerate(classes):
# 拼接某个类别的目录
cls_path = os.path.join(data_dir, cls)
for file in os.listdir(cls_path):
# 拼接单个文件的目录
file_path = os.path.join(cls_path, file)
with open(file_path, encoding='utf-8') as f:
X.append(f.read().strip())
y.append(idx)
return X, np.array(y)
上述函数会得到两个列表,便于我们后面处理。
2.4 构建词表
在我们获取评论文本后,我们需要构建词表。即统计所有出现的词,给每个词一个编号(也可以统计一部分,多余的用unk表示)。这一步会得到一个词到id的映射和id到词的映射,具体代码如下:
def build_vocabulary(sentences):
"""
sentences:文本列表
输出:
word2idx:词到id的映射
idx2word:id到词的映射
"""
word2idx = {}
idx2word = {}
# 获取标点符号及空字符
punctuations = string.punctuation + "\t\n "
for sentence in sentences:
# 分词
words = re.split(f'[{punctuations}]', sentence.lower())
for word in words:
# 如果是新词
if word not in word2idx:
word2idx[word] = len(word2idx)
idx2word[len(word2idx) - 1] = word
return word2idx, idx2word
有了上面的两个映射后,我们就可以将句子转换成id序列,也可以把id序列转换成句子,在本案例中只需要前者。
2.5 单词标记化(tokenize)
因为我们模型需要固定长度的数据,因此在标记化时我们对句子长度进行限制:
def tokenize(sentences, max_len=300):
"""
sentences:文本列表
tokens:标记化后的id矩阵,形状为(句子数量, 句子长度)
"""
# 生产一个形状为(句子数量, 句子长度)的矩阵,默认用空字符的id填充,类型必须为int
tokens = np.full((len(sentences), max_len),
fill_value=word2idx[''], dtype=np.int32)
punctuations = string.punctuation + "\t\n "
for row, sentence in enumerate(sentences):
# 分词
words = re.split(f'[{punctuations}]', sentence.lower())
for col, word in enumerate(words):
if col >= max_len:
break
# 把第row个句子的第col个词转成id
tokens[row, col] = word2idx.get(word, word2idx[''])
return tokens
使用该函数就可以将句子列表转换成ndarray了。
三、构建模型并训练
3.1 构建模型
这里使用RNN来实现,模型结构如下图:
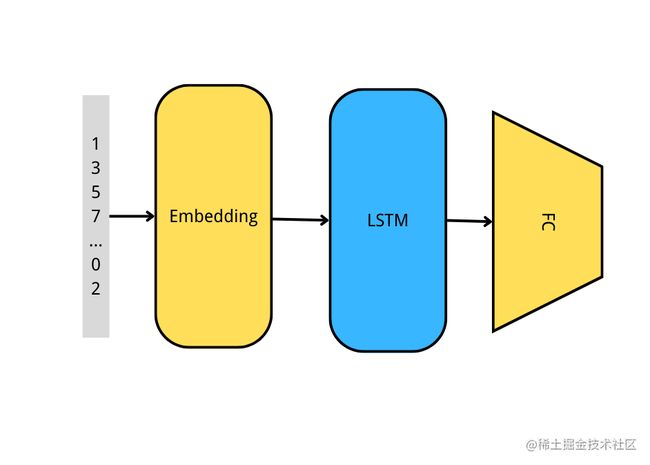
下面我们用程序实现这个模型:
def build_model():
vocab_size = len(word2idx)
# 构建模型
inputs = layers.Input(shape=max_len)
x = layers.Embedding(vocab_size, embedding_dim)(inputs)
x = layers.LSTM(64)(x)
outputs = layers.Dense(1, activation='sigmoid')(x)
model = Model(inputs, outputs)
return model
这里需要注意下面几个地方:
- Embedding层的输入是(batch_size,max_len),输出是(batch_size,max_len,embedding_dim)
- LSTM层的输入是(batch_size,max_len,embedding_dim),输出是(batch_size,units),units就是LSTM创建时传入的值。
3.2 训练模型
下面就可以使用前面实现好的几个方法开始训练模型了,代码如下:
# 超参数
max_len = 200
batch_size = 64
embedding_dim = 256
# 加载数据
X_train, y_train = load_data()
X_test, y_test = load_data('/home/zack/Files/datasets/aclImdb/test')
X = X_train + X_test
word2idx, idx2word = build_vocabulary(X)
X_train = tokenize(X_train, max_len=max_len)
X_test = tokenize(X_test, max_len=max_len)
# 构建模型
model = build_model()
model.summary()
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(
X_train, y_train,
batch_size=batch_size,
epochs=20,
validation_data=[X_test, y_test],
)
经过20个epoch的训练后,训练集准确率可以达到99%,而验证集准确率在80%左右,模型有一定程度的过拟合,可以通过修改模型结构或调节超参数来进行优化。
比如修改max_len的大小、使用预训练的词嵌入、修改RNN中units的大小、修改embedding_dim的大小等。还可以添加BatchNormalization、Dropout层。
四、使用模型
模型训练好后,可以用predict来预测,predict的输入和embedding层的输入是一样的:
while True:
sentence = input("请输入句子:")
tokenized = tokenize([sentence], max_len)
output = model.predict(tokenized)
print('消极' if output[0][0] >= 0.5 else '积极')
下面是一些测试结果:
请输入句子:this is a bad movie
消极
请输入句子:this is a good movie
积极
请输入句子:i like this movie very much
积极
请输入句子:i hate this movie very much
积极
请输入句子:i will never see this movie again
积极
效果不是特别理想,因为训练样本通常为长文本,而现在测试的是短文本。