apache griffin 本地部署及源码分析
Griffin
功能作用:
是一个开源的大数据数据质量解决方案,它支持批处理和流模式两种数据质量检测方式,可以从不同维度(比如离线任务执行完毕后检查源端和目标端的数据数量是否一致、源表的数据空值数量等)度量数据资产,从而提升数据的准确度、可信度。
通俗来讲 就是监控数据质量 :
我们可以通过UI界面来初步了解其功能:
核心概念:
measure
创建测测量指标一个数据源和测量的基准

创建Measures时候分以下四个数据质量模型:
1.Accuracy 精确度 ,指对比两个数据集source/target,指定对比规则如大于,小于,等于,指定对比的区间。最后通过job调起的spark计算得到结果集。
2.Data Profiling 数据分析,定义一个源数据集,求得n个字段的最大,最小,count值等等
3.Publish 发布,用户如果通过配置文件而不是界面方式创建了Measure,并且spark运行了该质量模型,结果集会写入到 ES中,通过publish 定义一个同名的Mesaure,就会在界面的仪表盘中显示结果集。
4.json/yaml Mesaure用户自定义的Measure,配置文件也可以通过这个位置定义
job
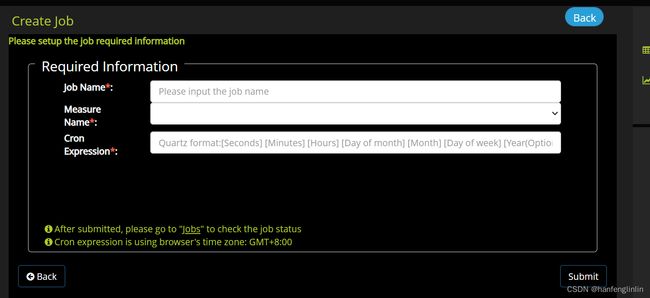
说明:
job Name: 设置Job的名字
Measure Name: 要执行的measure的名称,这个是从前面创建的Measure的名字中选择。
Cron Expression: cron 表达式。 For example: 0 0/4 * * * ?
Begin: 数据段开始时间与触发时间的比较
End: 数据段结束时间与触发时间比较。
提交作业后,Apache Griffin将在后台安排作业,计算完成后,您可以监视仪表板以在UI上查看结果
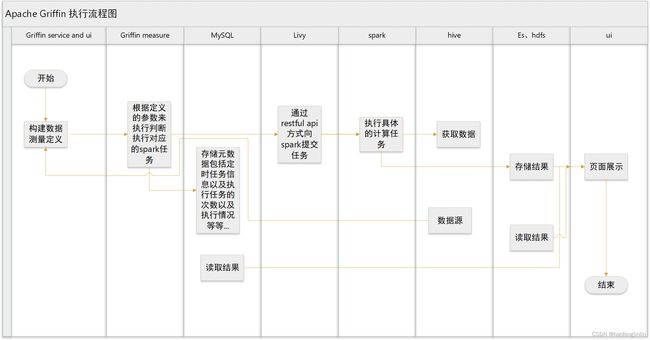
原理解析:
Griffin主要是做数据质量,其每个组件的作用:
Apache Hadoop:批量数据源,存储指标数据
Apache Hive: Hive Metastore
Apache Spark: 计算批量、实时指标
Apache Livy: 为服务提供 RESTful API 调用 Apache Spark
MySQL: 服务元数据
ElasticSearch:存储指标数据
官方架构图:

在Griffin的架构中,主要分为Define、Measure和Analyze三个部分:
各部分的职责如下:
Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等)
Measure:主要负责执行统计任务,生成统计结果
Analyze:主要负责保存与展示统计结果
执行流程:
源码解析和编译:
源码每个模块的作用:

griffin-doc :管理文档
measure :执行统计任务,通过 Livy 提交任务到 Spark。模型定义。
service: 服务层,提供管理接口
ui :内置的展示层
编译:
1.配置MySQL
因为Griffin使用了 Quartz 进行任务的调度,因此需要在MySQL中创建Quartz 调度器用到的库。并进行初始化
在MySQL服务器中执行命令,创建一个 quartz 库。执行src/main/resources/Init_quartz_mysql_innodb.sql文件
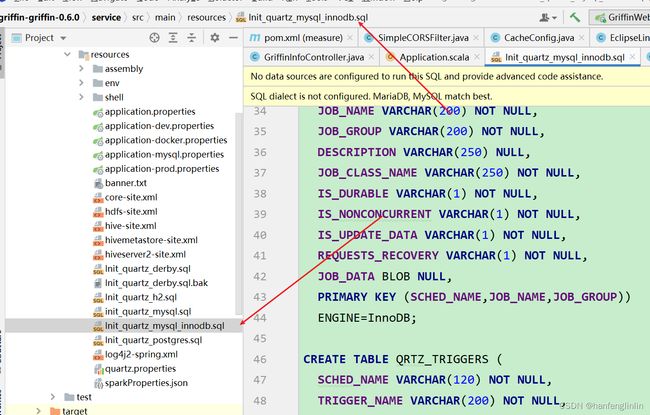
1.1放开pom文件的mysql注释,并注释掉 postgre:
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>${mysql.java.version}version>
dependency>
1.2.同时 profile 处也需要打开
<profile>
<id>mysqlid>
<activation>
<property>
<name>mysqlname>
property>
activation>
profile>
1.3修改quartz.properties 主要是切换 driverDelegateClass
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
2.1配置 Griffin 的 application.properties
#Apache Griffin应用名称
#spring.application.name=griffin_service
# Apache Griffin server port (default 8080)
#server.port = 8081
spring.datasource.url=jdbc:mysql://localhost:3306/quartz?autoReconnect=true&useSSL=false
spring.datasource.username=root
spring.datasource.password=
spring.jpa.generate-ddl=true
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=update
# Hive metastore
hive.metastore.uris=thrift://192.168.182.10:9083
hive.metastore.dbname=default
hive.hmshandler.retry.attempts=15
hive.hmshandler.retry.interval=2000ms
#Hive jdbc
hive.jdbc.className=org.apache.hive.jdbc.HiveDriver
hive.jdbc.url=jdbc:hive2://192.168.182.10:10000/
hive.need.kerberos=false
[email protected]
hive.keytab.path=/path/to/keytab/file
# Hive cache time
cache.evict.hive.fixedRate.in.milliseconds=900000
# Kafka schema registry
kafka.schema.registry.url=http://localhost:8081
# Update job instance state at regular intervals
jobInstance.fixedDelay.in.milliseconds=60000
# Expired time of job instance which is 7 days that is 604800000 milliseconds.Time unit only supports milliseconds
jobInstance.expired.milliseconds=604800000
# schedule predicate job every 5 minutes and repeat 12 times at most
#interval time unit s:second m:minute h:hour d:day,only support these four units
predicate.job.interval=5m
predicate.job.repeat.count=12
# external properties directory location
external.config.location=
# external BATCH or STREAMING env
external.env.location=
# login strategy ("default" or "ldap")
login.strategy=default
# ldap
ldap.url=ldap://hostname:port
[email protected]
ldap.searchBase=DC=org,DC=example
ldap.searchPattern=(sAMAccountName={0})
# hdfs default name
fs.defaultFS=192.168.182.10:9000
# elasticsearch
elasticsearch.host=192.168.182.10
elasticsearch.port=9200
elasticsearch.scheme=http
# elasticsearch.user = user
# elasticsearch.password = password
# livy
livy.uri=http://192.168.182.10:8998/batches
livy.need.queue=false
livy.task.max.concurrent.count=20
livy.task.submit.interval.second=3
livy.task.appId.retry.count=3
livy.need.kerberos=false
livy.server.auth.kerberos.principal=livy/kerberos.principal
livy.server.auth.kerberos.keytab=/path/to/livy/keytab/file
# yarn url
yarn.uri=http://192.168.182.10:8088
# griffin event listener
internal.event.listeners=GriffinJobEventHook
logging.file=logs/griffin-service.log
2.2配置 Griffin 的 sparkProperties.json
{
"file": "hdfs://192.168.182.10:9000/griffin/griffin-measure.jar",
"className": "org.apache.griffin.measure.Application",
"queue": "default",
"numExecutors": 2,
"executorCores": 1,
"driverMemory": "1g",
"executorMemory": "1g",
"conf": {
"spark.yarn.dist.files": "hdfs://192.168.182.10:9000/home/spark_conf/hive-site.xml"
},
"files": [
]
}
2.3 配置 Griffin service的 env_batch.json 配置 Griffin 的measure的env-batch.json
{
"spark": {
"log.level": "WARN"
},
"sinks": [
{
"name": "console",
"type": "CONSOLE",
"config": {
"max.log.lines": 10
}
},
{
"name": "hdfs",
"type": "HDFS",
"config": {
"path": "hdfs://192.168.182.10:9000/griffin/persist",
"max.persist.lines": 10000,
"max.lines.per.file": 10000
}
},
{
"name": "elasticsearch",
"type": "ELASTICSEARCH",
"config": {
"method": "post",
"api": "http://192.168.182.10:9200/griffin/accuracy",
"connection.timeout": "1m",
"retry": 10
}
}
],
"griffin.checkpoint": []
}
2.4 Elasticsearch设置
这里提前在Elasticsearch设置索引,以便将分片数,副本数和其他设置配置为所需的值:
# curl -k -H "Content-Type: application/json" -X PUT http://cdh04:9200/griffin?pretty \
-d '{
"aliases": {},
"mappings": {
"accuracy": {
"properties": {
"name": {
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
},
"type": "text"
},
"tmst": {
"type": "date"
}
}
}
},
"settings": {
"index": {
"number_of_replicas": "2",
"number_of_shards": "5"
}
}
}'
如果报错无法识别类型 是es版本问题:
尝试使用一下命令:
curl -H "Content-Type: application/json" -XPUT http://localhost:9200/griffin/accuracy -d '
{
"aliases": {},
"mappings": {
"properties": {
"name": {
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
},
"type": "text"
},
"tmst": {
"type": "date"
}
}
},
"settings": {
"index": {
"number_of_replicas": "2",
"number_of_shards": "5"
}
}
}
'
原因:ElasticSearch7.X之后的版本默认不在支持指定索引类型,
默认索引类型是_doc(隐含:include_type_name=false),所以在mappings节点后面,直接跟properties就可以了。创建索引成功返回:
{"acknowledged":true,"shards_acknowledged":true,"index":"griffin"}
3,修改ui配置
修改ui模块下的angular下的environment.ts
export const environment = {
production: false,
BACKEND_SERVER: 'http://localhost:8080', #后端ip地址和端口
};
4,编译项目
mvn clean install -Dmaven.test.skip=true
这里可能会卡在ui模块一直在下载,编译报错,试过更改镜像源,但是并没有作用
可以注释掉ui模块单独打包:
service
measure
然后再执行编译 另外两个模块是可以通过编译的:
另外:measure模块是再spark中执行的 并通过livy来进行通信 目前我们并没有 实际的环境所以关于hive,spark,livy,Hadoop的修改并不体现
5.1单独编译ui
进入该项目的ui/angular目录下 cmd命令行执行
npm install
下载完成后 进入ui\angular\node_modules的.bin目录下执行:
ng serve --port 8081 #这里的8081 是web 访问端口
执行成功后命令行显示:
webpack: Compiled successfully.
则启动成功
5.2启动webservice
直接运行service模块下的GriffinWebApplication这个类便可
访问localhost:8081 .后台默认是没有用户名和密码的,直接点击登陆就能够了
源码分析:
kafka数据源参考链接:Apache Griffin+Flink+Kafka实现流式数据质量监控实战_9918699的技术博客_51CTO博客
粗略流程图:
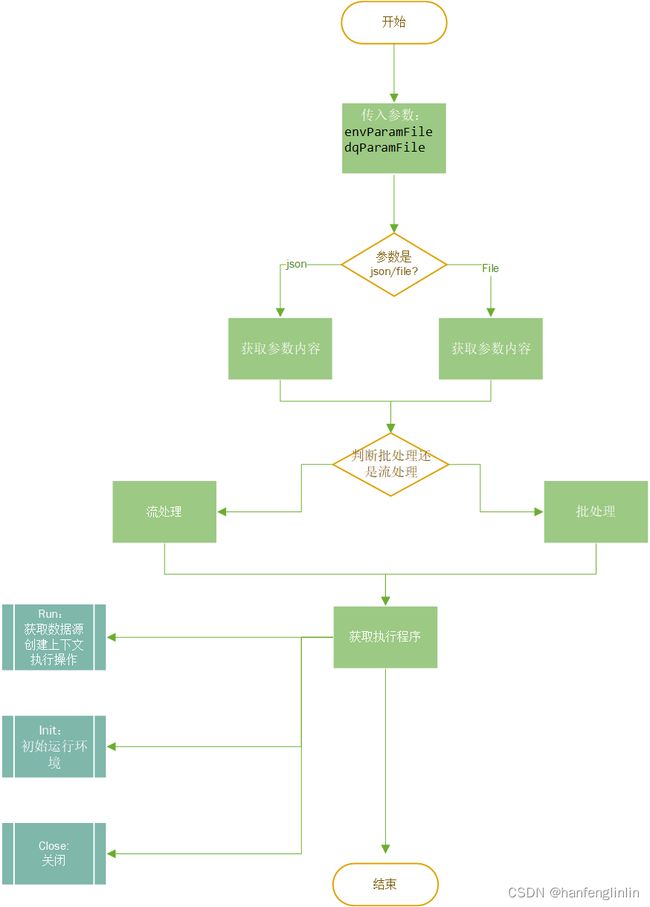
代码参数解析:
//当前类继承了loggerble特质info为日志输出
//检验参数
info(args.toString)
if (args.length < 2) {
error("Usage: class " )
sys.exit(-1)
}
val envParamFile = args(0)
val dqParamFile = args(1)
info(envParamFile)
info(dqParamFile)
// read param files
val envParam = readParamFile[EnvConfig](envParamFile) match {
case Success(p) => p
case Failure(ex) =>
error(ex.getMessage, ex)
sys.exit(-2)
}
val dqParam = readParamFile[DQConfig](dqParamFile) match {
case Success(p) => p
case Failure(ex) =>
error(ex.getMessage, ex)
sys.exit(-2)
}
val allParam: GriffinConfig = GriffinConfig(envParam, dqParam)
envParamFile:表⽰对应环境配置信息,包括对应的spark的⽇志级别,数据源的输出⽬的地。
dbParamFile:表⽰对应的执⾏任务的数据配置,包括对应的数据源的配置,计算规则信息
通过使用ParamReaderFactory.getParamReader来获取hdfs配置和json 解析
def readParamFile[T <: Param](file: String)(implicit m: ClassTag[T]): Try[T] = {
val paramReader = ParamReaderFactory.getParamReader(file)
paramReader.readConfig[T]
}
2.判断程序类型为批处理还是流处理:
//获取程序类型并进行比较是否批或流
val procType = ProcessType.withNameWithDefault(allParam.getDqConfig.getProcType)
//判断是哪种类型 并创建执行对象
val dqApp: DQApp = procType match {
case BatchProcessType => BatchDQApp(allParam)
case StreamingProcessType => StreamingDQApp(allParam)
case _ =>
error(s"$procType is unsupported process type!")
sys.exit(-4)
}
//开始执行标记 方法并没有实际意义
startup()
3.初始化griffin 执行环境
//init方法主要是初始话
dqApp.init match {
case Success(_) =>
info("process init success")
case Failure(ex) =>
error(s"process init error: ${ex.getMessage}", ex)
shutdown()
sys.exit(-5)
}
init()主要是初始话spark环境和griffin 自定义的udf:
其中sparkParam为上文env参数所带的spark参数
通过GriffinUDFs注册了基础的udf函数,index_of,matches,reg_replace
def init: Try[_] = Try {
// build spark 2.0+ application context
val conf = new SparkConf().setAppName(metricName)
conf.setAll(sparkParam.getConfig)
conf.set("spark.sql.crossJoin.enabled", "true")
sparkSession = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()
val logLevel = getGriffinLogLevel
sparkSession.sparkContext.setLogLevel(sparkParam.getLogLevel)
griffinLogger.setLevel(logLevel)
// 注册udf函数
GriffinUDFAgent.register(sparkSession)
}
注册源码以及三个函数的具体功能:
object GriffinUDFs {
def register(sparkSession: SparkSession): Unit = {
sparkSession.udf.register("index_of", indexOf _)
sparkSession.udf.register("matches", matches _)
sparkSession.udf.register("reg_replace", regReplace _)
}
//返回下标
private def indexOf(arr: Seq[String], v: String) = {
arr.indexOf(v)
}
//匹配
private def matches(s: String, regex: String) = {
s.matches(regex)
}
//替换
private def regReplace(s: String, regex: String, replacement: String) = {
s.replaceAll(regex, replacement)
}
}
然后,进⼊到执⾏对应的定时任务作业 ,spark核心代码:
// dq app run
//程序执行
val success = dqApp.run match {
case Success(result) =>
info("process run result: " + (if (result) "success" else "failed"))
result
case Failure(ex) =>
error(s"process run error: ${ex.getMessage}", ex)
if (dqApp.retryable) {
throw ex
} else {
shutdown()
sys.exit(-5)
}
}
run⽅法中,主要的⼏⼤功能:
def run: Try[Boolean] = {
val result = CommonUtils.timeThis({
val measureTime = getMeasureTime
val contextId = ContextId(measureTime)
// get data sources
//根据对应的配置args(1)获取数据源,即args(1)DQConfig配置中的data.sources配置
val dataSources =
DataSourceFactory.getDataSources(sparkSession, null, dqParam.getDataSources)
//数据源的初始化
dataSources.foreach(_.init())
// create dq context
//,创建Girffin执⾏的上下⽂
dqContext =
DQContext(contextId, metricName, dataSources, sinkParams, BatchProcessType)(sparkSession)
// start id
val applicationId = sparkSession.sparkContext.applicationId
//根据对应的sink配置,输出结果到console和elasticsearch中(配置中)
dqContext.getSinks.foreach(_.open(applicationId))
// build job
//创建数据检测对应的job信息
val dqJob = DQJobBuilder.buildDQJob(dqContext, dqParam.getEvaluateRule)
// dq job execute
//执⾏任务作业
dqJob.execute(dqContext)
}, TimeUnit.MILLISECONDS)
// clean context
dqContext.clean()
// finish
dqContext.getSinks.foreach(_.close())
result
}
getDataSource()⽅法中:
def getDataSources(
sparkSession: SparkSession,
ssc: StreamingContext,
dataSources: Seq[DataSourceParam]): Seq[DataSource] = {
dataSources.zipWithIndex.flatMap { pair =>
val (param, index) = pair
getDataSource(sparkSession, ssc, param, index)
}
}
其中这个方法内的 getDataSource(),第⼀个参数是对应的SparkSession,第⼆个参数是StreamingContext(这⾥是null),第三个参数是数据源配置,第四个参数是index,其方法内主要是对数据源进行初始化和验证。其中重要的步骤为调用DataConnectorFactory.getDataConnector函数获取对应的DataConnector对象:
def getDataConnector(
sparkSession: SparkSession,
ssc: StreamingContext,
dcParam: DataConnectorParam,
tmstCache: TimestampStorage,
streamingCacheClientOpt: Option[StreamingCacheClient]): Try[DataConnector] = {
val conType = dcParam.getType
Try {
conType match {
case HiveRegex() => HiveBatchDataConnector(sparkSession, dcParam, tmstCache)
case AvroRegex() => AvroBatchDataConnector(sparkSession, dcParam, tmstCache)
case FileRegex() => FileBasedDataConnector(sparkSession, dcParam, tmstCache)
case TextDirRegex() => TextDirBatchDataConnector(sparkSession, dcParam, tmstCache)
case ElasticSearchRegex() => ElasticSearchDataConnector(sparkSession, dcParam, tmstCache)
case CustomRegex() =>
getCustomConnector(sparkSession, ssc, dcParam, tmstCache, streamingCacheClientOpt)
case KafkaRegex() =>
getStreamingDataConnector(
sparkSession,
ssc,
dcParam,
tmstCache,
streamingCacheClientOpt)
case JDBCRegex() => JDBCBasedDataConnector(sparkSession, dcParam, tmstCache)
case _ => throw new Exception("connector creation error!")
}
}
}
最终,我们能看到griffin的meauser默认的数据源配置有以下⼏种,hive,avro,textDir,kafka等
HiveBatchDataConnector(sparkSession, dcParam, tmstCache):
case class HiveBatchDataConnector(
@transient sparkSession: SparkSession,
dcParam: DataConnectorParam,
timestampStorage: TimestampStorage)
extends BatchDataConnector {
val config: Map[String, Any] = dcParam.getConfig
val Database = "database"
val TableName = "table.name"
val Where = "where"
val database: String = config.getString(Database, "default")
val tableName: String = config.getString(TableName, "")
val whereString: String = config.getString(Where, "")
val concreteTableName = s"$database.$tableName"
val wheres: Array[String] = whereString.split(",").map(_.trim).filter(_.nonEmpty)
//继承自父类执行sql获取dataFrame,其中preProcess为父类方法执负责执行语句 返回
def data(ms: Long): (Option[DataFrame], TimeRange) = {
val dfOpt = {
val dtSql = dataSql()
info(dtSql)
val df = sparkSession.sql(dtSql)
val dfOpt = Some(df)
val preDfOpt = preProcess(dfOpt, ms)
preDfOpt
}
val tmsts = readTmst(ms)
(dfOpt, TimeRange(ms, tmsts))
}
private def dataSql(): String = {
val tableClause = s"SELECT * FROM $concreteTableName"
if (wheres.length > 0) {
val clauses = wheres.map { w =>
s"$tableClause WHERE $w"
}
clauses.mkString(" UNION ALL ")
} else tableClause
}
}
继承了HiveBatchDataConnector对象⾸先是继承了BatchDataConnnector,并且BatchDataConnector继承了DataConnector对象,其中,HiveBatchDataConnector实现了DataConnector对象中的data⽅法,及创建了spark任务执行了方法。获取数据。
def preProcess(dfOpt: Option[DataFrame], ms: Long): Option[DataFrame] = {
// new context
//内部有初始化数据源和加载数据的方法
val context = createContext(ms)
val timestamp = context.contextId.timestamp
val suffix = context.contextId.id
val dcDfName = dcParam.getDataFrameName("this")
try {
saveTmst(timestamp) // save timestamp
dfOpt.flatMap { df =>
val (preProcRules, thisTable) =
//获取规则,和数据信息
PreProcParamMaker.makePreProcRules(dcParam.getPreProcRules, suffix, dcDfName)
// init data
context.compileTableRegister.registerTable(thisTable)
context.runTimeTableRegister.registerTable(thisTable, df)
// build job
val preprocJob = DQJobBuilder.buildDQJob(context, preProcRules)
// job execute
preprocJob.execute(context)
// out data
val outDf = context.sparkSession.table(s"`$thisTable`")
// add tmst column
val withTmstDf = outDf.withColumn(ConstantColumns.tmst, lit(timestamp))
// clean context
context.clean()
Some(withTmstDf)
}
} catch {
case e: Throwable =>
error(s"pre-process of data connector [$id] error: ${e.getMessage}", e)
None
}
}
}
context加载数据:
加载数据:
def loadDataSources(): Map[String, TimeRange] = {
dataSources.map { ds =>
(ds.name, ds.loadData(this))
}.toMap
}
DQJobBuilder.buildDQJob(context, preProcRules)构建任务对象
以上内容仅供学习参考,如有错误或者理解不到位欢迎指正